student表
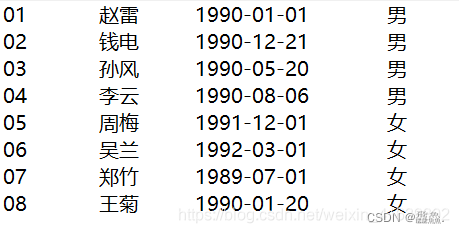
score表
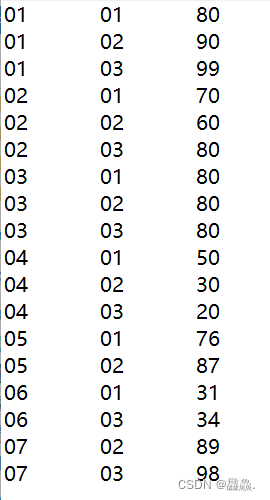
teacher表

course表

首先要先在hdfs上为每个数据建一个文件名相同的文件夹,以上的4张表都是txt格式的,放入hdfs相对应的文件夹后,使用以下语句建表(因为数据量不大,就直接建内部表)
create table if not exists student(
id int,
name string,
birthday string,
sex string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/data/myschool/student';
create table if not exists teacher(
tid int,
tname string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/data/myschool/teacher';
create table if not exists score(
sid int,
cid int,
scores int
)
row format delimited fields terminated by '\t'
stored as textfile
location '/data/myschool/score';
create table if not exists course(
cid int,
cname string,
tid int
)
row format delimited fields terminated by '\t'
stored as textfile
location '/data/myschool/course';
查询"01"课程比"02"课程成绩高的学生的信息及课程分数
select stu.*,sco1.scores 01scores,sco2.scores 02scores from
student stu join score sco1
on stu.id=sco1.sid and sco1.cid=1
left join score sco2
on stu.id=sco2.sid and sco2.cid=2
where sco1.scores>sco2.scores;
2.查询"01"课程比"02"课程成绩低的学生的信息及课程分数
select stu.*,sco1.scores 01scores,sco2.scores 02scores from
student stu join score sco1
on stu.id=sco1.sid and sco1.cid=1
left join score sco2
on stu.id=sco2.sid and sco2.cid=2
where sco1.scores<sco2.scores;
3.查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
select stu.id,stu.name,avg(sco.scores)
from student stu join score sco
on stu.id=sco.sid
group by stu.id,stu.name
having avg(sco.scores)>60;
4.查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩 – (包括有成绩的和无成绩的)
select stu.id,stu.name,round(avg(sco.scores),2) as avg_scores
from student stu join score sco
on stu.id=sco.sid
group by stu.id,stu.name
having avg(sco.scores)<60
union all
select stu1.id,stu1.name,0 as avg_scores
from student stu1
where stu1.id not in
(select distinct sid from score);
5.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
select stu.id,stu.name,count(cid),sum(scores)
from student stu left join score sco
on stu.id=sco.sid
group by stu.id,stu.name;
6.查询"李"姓老师的数量
select count(tid) as num,'姓李的老师' as teal
from teacher
where tname like '李%';
7.查询学过"张三"老师授课的同学的信息
select stu.*
from student stu join score sco on stu.id=sco.sid
join course cor on sco.cid=cor.cid
join teacher tea on tea.tid=cor.tid
where tea.tname='张三';
8.查询没学过"张三"老师授课的同学的信息
select s.* from student s
where s.id not in
(select stu.id
from student stu join score sco on stu.id=sco.sid
join course cor on sco.cid=cor.cid
join teacher tea on tea.tid=cor.tid
where tea.tname='张三');
9.查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
select stu.*
from student stu
join
(select sid as tmpid from score
where cid=1
union all
select sid as tmpid from score
where cid=2) ss on stu.id=ss.tmpid
group by stu.id,stu.name,stu.birthday,stu.sex,ss.tmpid
having count(ss.tmpid)=2;
10.查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
select stu.*
from student stu
join (select sid from score where cid=1) sco1
on stu.id=sco1.sid
left join (select sid from score where cid=2) sco2
on stu.id=sco2.sid
where sco2.sid is null;
11、查询没有学全所有课程的同学的信息
select student.* from student
left join(
select sid
from score
group by sid
having count(cid)=3)tmp
on student.id=tmp.sid
where tmp.sid is null;
12、查询至少有一门课与学号为"01"的同学所学相同的同学的信息
select stu.* from student stu
join (select cid from score where sid=1) tmp1
join (select sid,cid from score) tmp2
on tmp1.cid=tmp2.cid and stu.id=tmp2.sid
where stu.id not in (1)
group by stu.id,name,birthday,sex;
13、查询和"01"号的同学学习的课程完全相同的其他同学的信息
select stu.*,count(tmp2.cid) from student stu
join (select cid from score where sid=1) tmp1
join (select sid,cid from score) tmp2
on tmp1.cid=tmp2.cid and stu.id=tmp2.sid
where stu.id not in (1)
group by stu.id,name,birthday,sex
having count(tmp2.cid) in (select count(cid) from score where sid=1);
14、查询没学过"张三"老师讲授的任一门课程的学生姓名
select stu.id,stu.name from student stu
left join (select sid,cid from score) sco
left join (select cid,tid from course) cor
left join (select tid from teacher where tname='张三') tea
on stu.id=sco.sid and sco.cid=cor.cid and tea.tid=cor.tid
group by stu.id,name
having count(tea.tid)=0;
15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
select stu.*,tmp.savg from student stu
join (select sid,count(cid) noc,round(avg(scores),1) savg
from score where scores<60 group by sid having noc>=2) tmp
on tmp.sid=stu.id;
16、检索"01"课程分数小于60,按分数降序排列的学生信息
select stu.*,tmp.scores from student stu join
(select sid,scores from score where cid=1 and scores<60) tmp
on stu.id=tmp.sid
order by tmp.scores desc;
17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
select a.sid,tmp1.scores as c1,tmp2.scores as c2,tmp3.scores as c3,
round(avg (a.scores),2) as avgScore
from score a
left join (select sid,scores from score s1 where cid='01')tmp1 on tmp1.sid=a.sid
left join (select sid,scores from score s2 where cid='02')tmp2 on tmp2.sid=a.sid
left join (select sid,scores from score s3 where cid='03')tmp3 on tmp3.sid=a.sid
group by a.sid,tmp1.scores,tmp2.scores,tmp3.scores order by avgScore desc;
18.查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
select course.cid,course.cname,tmp.maxScore,tmp.minScore,tmp.avgScore,tmp.passRate,tmp.moderate,tmp.goodRate,tmp.excellentRates from course
join(select
cid,
max(scores) as maxScore,
min(scores) as minScore,
round(avg(scores),2) avgScore,
round(sum(case when scores>=60 then 1 else 0 end)/count(cid),2)passRate,
round(sum(case when scores>=60 and scores<70 then 1 else 0 end)/count(cid),2) moderate,
round(sum(case when scores>=70 and scores<80 then 1 else 0 end)/count(cid),2) goodRate,
round(sum(case when scores>=80 and scores<90 then 1 else 0 end)/count(cid),2) excellentRates
from score group by cid) tmp on tmp.cid=course.cid;
19、按各科成绩进行排序,并显示排名:– row_number() over()分组排序功能(mysql没有该方法)
select cid,sid,scores,row_number() over(partition by cid order by scores desc)
from score;
20、查询学生的总成绩并进行排名
select score.sid,student.name,sum(scores) sum_sco,row_number() over(order by sum(scores) desc) no
from score join student on score.sid=student.id
group by score.sid,student.name;
21、查询不同老师所教不同课程平均分从高到低显示
select score.cid,round(avg(scores),2) avg_scores,course.tid
from score join
course on score.cid=course.cid
group by score.cid,course.tid
order by avg_scores desc;
22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
select tmp.cid,stu.*,tmp.scores,tmp.cno from
student stu join
(select cid,sid,scores,row_number() over(partition by cid order by scores desc) cno
from score) tmp
on stu.id=tmp.sid
where tmp.cno between 2 and 3;
23、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
select
score.cid,
course.cname,
round(sum(case when score.scores>=85 and score.scores<=100 then 1 else 0 end)/count(score.scores),2) as 100and85,
round(sum(case when score.scores>=70 and score.scores<85 then 1 else 0 end)/count(score.scores),2) as 85and70,
round(sum(case when score.scores>=60 and score.scores<70 then 1 else 0 end)/count(score.scores),2) as 70and60,
round(sum(case when score.scores>=0 and score.scores<60 then 1 else 0 end)/count(score.scores),2) as 60and0
from score left join course
on score.cid = course.cid
group by score.cid,course.cname;
24、查询学生平均成绩及其名次
select sid,round(avg(scores),2) as avgs,row_number() over(order by avg(scores) desc)
from score
group by sid;
25、查询各科成绩前三名的记录
select tmp.cid,stu.*,tmp.scores,tmp.cno from
student stu join
(select cid,sid,scores,row_number() over(partition by cid order by scores desc) cno
from score) tmp
on stu.id=tmp.sid
where tmp.cno<=3;
26、查询每门课程被选修的学生数
select cid,count(scores) as cnum
from score
group by cid;
27、查询出只有两门课程的全部学生的学号和姓名
select sid,count(cid) as cnum
from score
group by sid
having count(cid)=2;
28、查询男生、女生人数
select sex,count(1) as pnum
from student
group by sex;
29、查询名字中含有"风"字的学生信息
select *
from student
where name like '%风%';
30、查询同名同性学生名单,并统计同名人数
select name,sex,count(id)
from student
group by name,sex;
31、查询1990年出生的学生名单
select *
from student
where year(birthday)=1990;
32、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
select cid,round(avg(scores),2) as avgs,row_number() over(order by round(avg(scores),2) desc,cid asc)
from score
group by cid;
33、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
select stu.id,stu.name,avg(scores) as avgs
from student stu join
score sco on stu.id=sco.sid
group by stu.id,stu.name
having avg(scores)>85;
34、查询课程名称为"数学",且分数低于60的学生姓名和分数
select stu.name,sco.scores
from student stu
join score sco
join course cor
on stu.id=sco.sid and sco.cid=cor.cid
where cor.cname='数学' and sco.scores<60;
35、查询所有学生的课程及分数情况
select stu.id,tmp.chinese,tmp.math,tmp.english
from student stu
left join
(select sco.sid id,
sum(case cor.cname when '语文' then sco.scores else 0 end) as chinese,
sum(case cor.cname when '数学' then sco.scores else 0 end) as math,
sum(case cor.cname when '英语' then sco.scores else 0 end) as english
from score sco
join course cor on sco.cid=cor.cid
group by sco.sid
) tmp on stu.id=tmp.id;
36、查询任何一门课程成绩在70分以上的学生姓名、课程名称和分数
select stu.name,cor.cname,sco.scores
from score sco
left join student stu on sco.sid=stu.id
join course cor on sco.cid=cor.cid
where sco.scores>70;
37、查询课程不及格的学生
select sid
from score
where scores<60
group by sid;
38、查询课程编号为01且课程成绩在80分以上的学生的学号和姓名
select sco.sid,stu.name
from score sco
join student stu
on sco.sid=stu.id
where cid=1 and scores>=80;
39、求每门课程的学生人数
select cid,count(sid)
from score
group by cid;
40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
select stu.*,sco.cid,max(sco.scores) max_score
from score sco
left join student stu
on stu.id=sco.sid
join course cor
on sco.cid=cor.cid
join teacher tea
on tea.tid=cor.tid
where tea.tname='张三'
group by sco.cid,stu.id,stu.name,stu.birthday,stu.sex
limit 1;
41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
select s1.sid,s1.cid,s1.scores
from score s1,score s2
where s1.cid<>s2.cid and s1.scores=s2.scores;
42、查询每门课程成绩最好的前三名
select tmp.cid,stu.*,tmp.scores,tmp.cno from
student stu join
(select cid,sid,scores,row_number() over(partition by cid order by scores desc) cno
from score) tmp
on stu.id=tmp.sid
where tmp.cno<=3;
43、统计每门课程的学生选修人数(超过5人的课程才统计):
–要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
select cid,count(sid) as num
from score
group by cid
having num>=5
order by num desc,cid asc;
44、检索至少选修两门课程的学生学号
select sid
from score
group by sid
having count(cid)>=2;
45、查询选修了全部课程的学生信息
select stu.*
from student stu
join
(select sid,count(cid) cnum from score group by sid) tmp
on stu.id=tmp.sid
where tmp.cnum=3;
46、查询各学生的年龄(周岁):
–按照出生日期来算,当前月日 < 出生年月的月日则,年龄减一
with tmp as
(select id,year(current_date())-year(birthday) as tage
from student)
select stu.id,sum(case month(current_date())>month(stu.birthday) when true then tmp.tage-1 else tmp.tage end) s_age
from student stu
join tmp
on stu.id=tmp.id
group by stu.id;
47、查询本周过生日的学生:
select *
from student
where weekofyear(concat(year(current_date()),'-',date_format(birthday,'MM-dd')))=
weekofyear(current_date())
48、查询下周过生日的学生:
select *
from student
where weekofyear(concat(year(current_date()),'-',date_format(birthday,'MM-dd')))=
weekofyear(current_date())+1;
49、查询本月过生日的学生:
select *
from student
where month(birthday)=month(current_date());
50、查询12月份过生日的学生:
select * from student where month(birthday)=12
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
我在一家express公司工作。我们目前通过“手动”解决了50多个位置路线。我一直在考虑使用GoogleMapsAPI来解决这个问题,但我读到有24分的限制。目前我们在服务器中使用Rails,所以我正在考虑使用ruby脚本来获取50多个位置的坐标并输出合理的解决方案。您会使用什么算法来解决这个问题?Ruby是解决这类问题的好编程语言吗?你知道任何现有的ruby脚本吗? 最佳答案 这可能是您正在寻找的:警告:此站点被firefox标记为攻击站点-但我似乎没有。其实我之前用过没问题[检查URL的修订历史]rubyquiz似乎已关
目录一.逻辑控制+方法1.java输入2.循环输入3.switch4.循环结构 5.三种输出6.java生成随机数7.java方法二.习题+方法21.返回二进制中1的个数2.获取一个二进制序列中的偶数位和奇数位,分别输出二进制序列3.JAVA比较字符串是否相同4.牛客网ACM书写格式5.方法的重载一.逻辑控制+方法1.java输入注意大小写!下面代码会出现什么问题??2.循环输入Ctrl+D结束循环输入3.switch面试问题:不能做switch()参数的类型有哪些?longfloatdoubleboolean(其他的都可以)4.循环结构 continue该程序运行的结果是什么??5.三种输出
我在第三个练习中停留在第四个RailsforZombies实验室。这是我的任务:创建将创建新僵尸的操作,然后重定向到创建的僵尸的显示页面。我有以下参数数组:params={:zombie=>{:name=>"Greg",:graveyard=>"TBA"}}我写了下面的代码作为解决方案:defcreate@zombie=Zombie.create@zombie.name=params[:zombie[:name]]@zombie.graveyard=params[:zombie[:graveyard]]@zombie.saveredirect_to(create_zombie_path
一、软件准备虚拟机(操作系统为Linux)中已有MySQL、已部署Hive。本地主机(操作系统为Windows)中下载navicat(我用的是navicatpremium15)。PS:其实用sqlyog也是可以连接虚拟机的Hive数据的。在决定用navicat还是sqlyog之前,可以思考这两个问题:①MySQL和hive的区别;②sqlyog和navicat的区别。对于第一个问题,我理解的最直接的区别是:MySQL的数据可以存储在本地,但是hive的数据一定是存储在分布式文件系统上的。尽管hive的操作数据的命令语法与MySQL非常接近,但hive不是MySQL。对于第二个问题,我理解的最直
虽然我在本地主机上工作正常,但我不确定为什么我的下面的代码不能处理我主机上任何大于50kb的文件。我测试了许多不同的文件大小,我很确定50kb是它的极限。如果文件大于50kb,则永远不会将其传递给process.php。如果一个文件小于50kb,它会被传递给process.phpok。有没有人可以帮我解决这个问题。我被这个问题困了几个小时。我确实在php.ini中将upload_max_filesize设置为5M。$(document).ready(function(){$('#img_uploader').on('change',function(){uploadFiles(this
一、知识框架二、练习题调节一个装瓶机使其对每个瓶子的灌装量均值为μ盎司,通过观察这台装瓶机对每个瓶子的灌装量服从标准差σ=1.0盎司的正态分布。随机抽取这台机器灌装的9个瓶子组成一个样本,并测定每个瓶子的灌装量。试确定样本均值偏离总体均值不超过0.3盎司的概率。解:设每个瓶子的灌装量为X,X为样本均值,样本容量为n。由于总体X服从正态分布,样本均值X也服从正态分布,且均值相同,标准差为所以三、简述题1什么是统计量?为什么要引进统计量?统计量中为什么不含任何未知参数?答:(1)统计量的定义:设X1,X2,…,Xn是从总体X中抽取的容量为n的一个样本,如果由此样本构造一个函数T(X1,X2,…,X
目录一、权限控制初体验二、Ranger授权模型一、权限控制初体验A、查看默认的访问策略此时只有rangerlookup用户拥有对所有库、表和函数的访问权限,故理论上其余用户是不能访问任何Hive资源的。B、验证使用fancy用户尝试进行认证,认证成功后,使用beeline客户端连接Hiveserver2使用fancy用户认证,并按照提示输入密码[fancy@hadoop102~]$kinitfancy登录beeline客户端[fancy@hadoop102~]$beeline-u"jdbc:hive2://hadoop102:10000/;principal=hive/hadoop102@EX