1. openGauss AI框架的特点
DB4AI这个方向中,数据库通过集成AI能力,在用户进行AI计算时就可以避免数据搬运的问题。不同于其他的DB4AI框架,本次openGauss开源的原生框架是通过添加AI算子的方式完成数据库中的AI计算。
那么除了避免了数据搬运所带来的问题这个普遍优势,openGauss的AI框架还具有以下的优势和特点:
1)极低的学习门槛
当前最主流的计算框架:Tensorflow、pytorch、keras等大多依托于python语言作为构建的脚本语言,虽然python已经足够的简单易学但还是需要一定的学习成本。而当前的框架,设计提供了CREATE MODEL和PREDICT BY两种语法用于完成AI的训练和推断任务。该语法相比较python更加趋近于自然语言,符合人们的用语直觉。
CREATE MODEL point_kmeans USING kmeans FEATURES position FROM kmeans_2d WITH num_centroids=3;SELECT id, PREDICT BY point_kmeans (FEATURES position) as pos FROM (select * from kmeans_2d_test limit 10)
2)极简的数据版本管理
本次DB4AI特性中还添加了snapshot功能。数据库通过快照的形式将数据集中的数据固定在某个时刻,同样也支持保存经过处理过滤的数据。功能分为全量保存和增量保存,其中因为增量保存每次仅存储数据变化,快照的空间占用大大的降低了。用户可以直接通过不同版本名称的快照直接获取相对应的数据。
3)极优的性能体验
相比于目前很多的AIinDB项目,openGauss的特性通过添加AI算子的方式将模型计算内置到数据库中。以算法训练为例,其中的数据的读取、模型的计算更新和最终的模型保存将在数据库的执行器中完成。这种方式将更加充分地利用和释放数据库的计算能力。深入内核的技术路线使得我们的特性在计算速度上优于其他更高层级调用的方法。
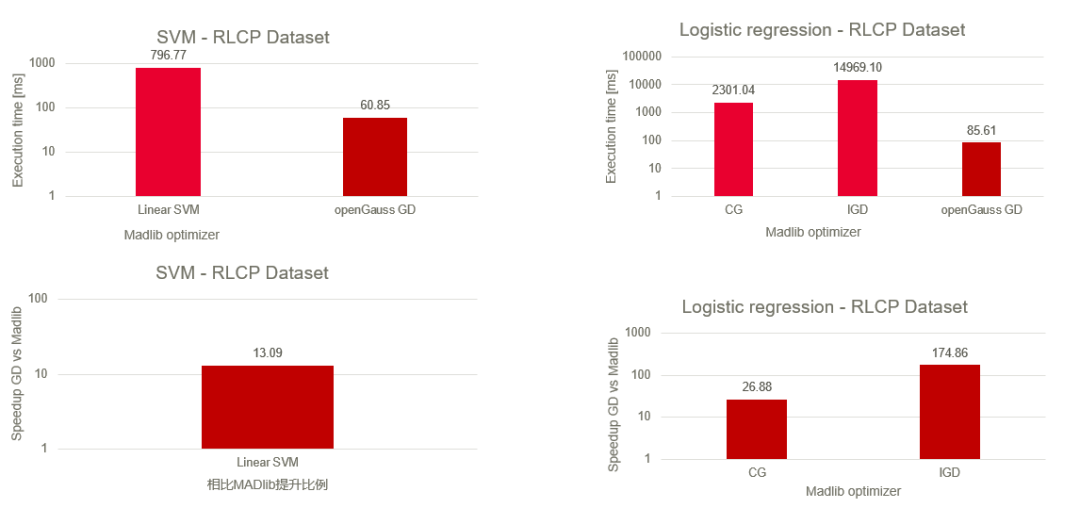
图1.与MADlib性能对比
2. 技术原理与优势
1)DB4AI-Snapshot
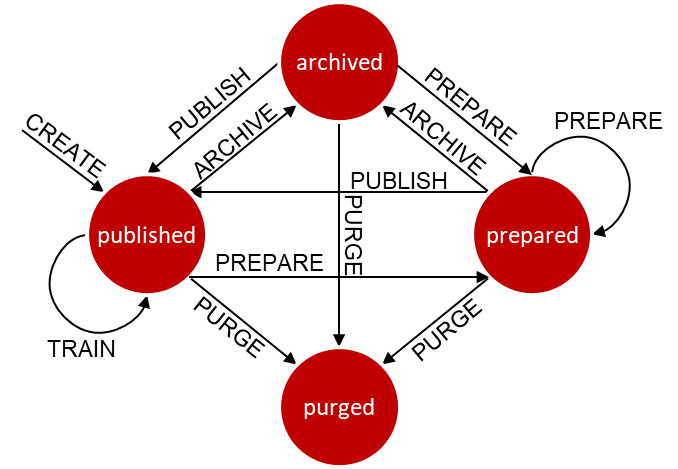
首先DB4AI.snapshot特性需要用户通过对操作数据存储的SQL查询指定哪些数据将填充新快照来创建快照。初始快照始终创建为操作数据的真实和可重用副本,使数据的特定状态不可变。因此,初始快照作为后续数据整理的起点,但它始终允许回溯到创建初始快照时原始数据的确切状态。
由于已创建的快照无法更改,因此在开始数据整理之前,必须“准备”快照。准备好的快照的数据可以进行协作修改,为模型训练做准备,特别是为数据管理做准备。此外,快照通过将每个操作作为元数据记录在DB4AI系统目录中,自动跟踪所有的更改,为数据提供完整的集成历史。
快照准备完成后,可以发布快照。发布的快照是不可变的,DB4AI系统强制只有发布的快照才能用于模型训练。保证训练任务
存档过时的快照以用于文档目的。在这种状态下,数据保持不变但不能用于训练新的模型。最后,清除快照,删除模式中的数据表以及视图、恢复存储空间。需要注意的是,快照管理为了实施严格的模型来源无法清除具有依赖的快照。
利用GUC参数,snapshot使用物化存储模式或者增量存储。在增量存储模式中,新快照对应的视图和数据表只保存相对父快照修改的内容,从而大大降低存储空间。
2)DB4AI-Query
原生AI框架深度内嵌于数据库内核中,通过查询优化和查询执行,构建包含AI算子的执行计划。计算完成后,框架的存储模块将负责保存模型相关信息。整个AI框架主题分成3部分,分别是:查询优化模块、计算执行模块和模型存储模块。
查询优化:
框架新增词法、语法规则CREATE MODEL、PREDICT BY作为AI计算入口。在查询优化中,模块负责简单的输入校验,包括:属性名合法性、算法当前是否支持、模型名称是否冲突等。校验完成后,该模块根据训练和推测任务生成对应的查询计划。
计算执行:
查询执行模块负责根据需求算法类型的不同添加相对应的AI算子到执行计划中,并执行运算其中包括数据读取和模型计算更新。各个算法之间高内聚低耦合,具有非常好的算法扩展性,对开发者之后添加算法友好。
模型存储:
当模型完成训练,执行器会把模型数据以tuple的形式传递给存储模块,最终将模型保存到系统表gs_model_warehouse中。
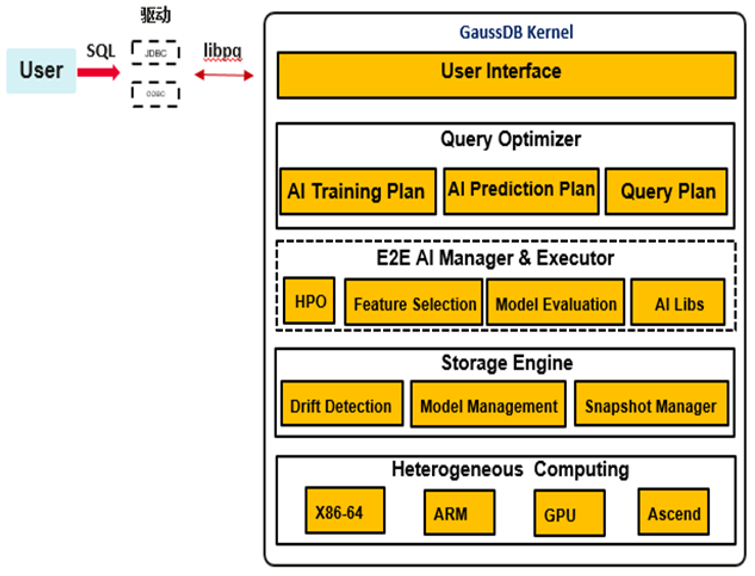
接下来我们以CREATE MODEL为例介绍用于训练模型的查询语句是如何实现的:
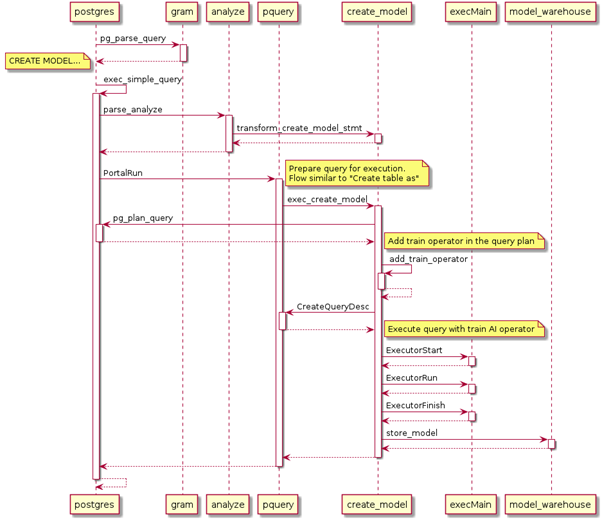
第一步 对Query进行词法分析、语法分析(Lex、Yacc)。通过识别模式类别和模式组合校对语句是否存在语法错误,生成分析树。
第二步 通过词法分析、语法分析(Lex、Yacc)后,数据库会对得到的每一个分析树进行语义分析和重写。在语义分析生成查询树的过程中,针对命令类型为createmodelStmt的情况,数据库首先会对算法类型进行检查判断算法属于监督学习还是非监督学习,根据这个判断结果继而进一步校验查询语句所输入的属性、超参、模型名称是否非法等。校验完成后,语义分析生成查询树,传递给数据库执行器。
第三步 在执行阶段根据算法类型的不同,执行器会添加不同的算法算子到执行计划中,将AI算子添加到扫描算子的上层。在算子执行计算的过程中,把扫描得到的数据输入到算法模型中进行计算和更新,最后根据超参设置的迭代条件结束算子执行。
第四步 计算完成后,执行器会将已训练完成的模型以元组的形式传递给存储引擎,接收到的元组转写模型结构体,经校验保存到系统表gs_model_warehouse中。用户可以通过查看系统表的方式查看模型的相关信息。
DB4AI作为openGauss原创的高级特性,凝结了openGauss在AI上的全新实践,通过DB4AI进一步拓展了openGauss数据库的应用领域。
利用openGauss提供的开箱即用的DB4AI功能,既有效解决数据仓库、数据湖场景中数据搬迁的问题,又提升了数据迁移过程中涉及的信息安全问题。未来,结合openGauss的多模、并行计算等领先优势,必将进一步地形成统一的数据管理平台,减少数据异构、碎片化存储带来的运维、使用困难。DB4AI特性的发布,是将openGauss进一步打造成一把锋利的瑞士军刀的关键一步!
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我想开始使用“Sinatra”框架进行编码,但我找不到该框架的“MVC”模式。是“MVC-Sinatra”模式或框架吗? 最佳答案 您可能想查看Padrino这是一个围绕Sinatra构建的框架,可为您的项目提供更“类似Rails”的感觉,但没有那么多隐藏的魔法。这是使用Sinatra可以做什么的一个很好的例子。虽然如果您需要开始使用这很好,但我个人建议您将它用作学习工具,以对您来说最有意义的方式使用Sinatra构建您自己的应用程序。写一些测试/期望,写一些代码,通过测试-重复:)至于ORM,你还应该结帐Sequel其中(imho
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。我一直在Rails上做两个项目,它们运行良好,但在这个过程中重新发明了轮子,自来水(和热水)和止痛药,正如我随后了解到的那样,这些已经存在于框架中。那么基本上,正确了解框架中所有智能部分的最佳方法是什么,这将节省时间而不是自己构建已经实现的功能?从第1页开始阅读文档?是否有公开所有内容的特定示例应用程序?一个特定的开源项目?所有的rails交通?还是完全
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭4年前。Improvethisquestion我希望能够将模板化的YARD文档样式注释插入到我现有的Rails遗留应用程序中。目前它的评论很少。我想要具有指定参数的类header和方法header(通过从我假定的方法签名中提取)和返回值的占位符。在PHP代码中,我有一些工具可以检查代码并在适当的位置创建插入到代码中的文档header注释。在带有Ducktyping等的Ruby中,我确信诸如@params等类型之类
我尝试用Ruby设计一个基于Web的应用程序。我开发了一个简单的核心应用程序,在没有框架和数据库的情况下在六边形架构中实现DCI范例。核心六边形中有小六边形和网络,数据库,日志等适配器。每个六边形都在没有数据库和框架的情况下自行运行。在这种方法中,我如何提供与数据库模型和实体类的关系作为独立于数据库的关系。我想在将来将框架从Rails更改为Sinatra或数据库。事实上,我如何在这个核心Hexagon中实现完全隔离的rails和mongodb的数据库适配器或框架适配器。有什么想法吗? 最佳答案 ROM呢?(Ruby对象映射器)。还有
据我了解,Python的扭曲框架为网络通信提供了更高级别的抽象(?)。我正在寻找在Rails应用程序中使用与twisted等效的Ruby。 最佳答案 看看EventMachine.它不像Twisted那样广泛,但它是围绕事件驱动网络编程的相同概念构建的。 关于python-Ruby是否有相当于Python的扭曲框架作为网络抽象层?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/9
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
我想使用比Rails(Sinatra/Ramaze/Camping)更轻的框架,但我担心这样做我将无法使用许多以插件形式为Rails定制的共享库.这是一个主要问题,还是这些插件中的大多数都可以跨不同的Ruby框架使用?使用Ruby框架而不是Rails是否还有其他潜在的缺点? 最佳答案 您仍然可以使用gems在你提到的所有框架中,很多东西都是可重用的。想要交换一个新的ORM,没问题。想要一个花哨的shmacy语法高亮,没问题。Rails一直在大力插入摆脱旧的插件模型,转而使用gems。如果其他框架之一符合您的需求,最好使用它。请记住,
我将以下代码放入RSpec测试中:it{shouldvalidate_format_of(:email).not_with('test@test')}并设置实际的类:validates:email,:presence=>true,:format=>/\b[A-Z0-9._%-]+@(?:[A-Z0-9-]+\.)+[A-Z]{2,4}\b/i当我运行测试时,我得到:失败:1)用户失败/错误:它{应该validate_format_of(:email).not_with('test@test')}当电子邮件设置为“test@test”时,预期错误包括“can'tbeblank”,得到错误