
 值得注意的是,该项目的论文和代码均已开源。
值得注意的是,该项目的论文和代码均已开源。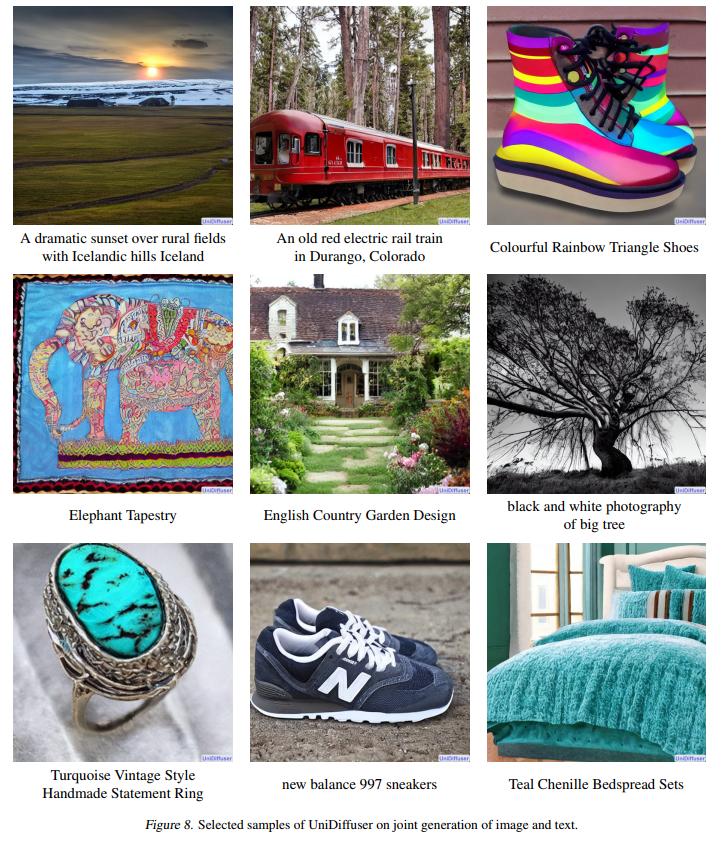 如下的图 9 展示了 UniDiffuser 在文到图上的效果:
如下的图 9 展示了 UniDiffuser 在文到图上的效果: 如下的图 10 展示了 UniDiffuser 在图到文上的效果:
如下的图 10 展示了 UniDiffuser 在图到文上的效果: 如下的图 11 展示了 UniDiffuser 在无条件图像生成上的效果:
如下的图 11 展示了 UniDiffuser 在无条件图像生成上的效果: 如下的图 12 展示了 UniDiffuser 在图像改写上的效果:
如下的图 12 展示了 UniDiffuser 在图像改写上的效果: 如下的图 15 展示了 UniDiffuser 能够实现在图文两个模态之间的来回跳跃 :
如下的图 15 展示了 UniDiffuser 能够实现在图文两个模态之间的来回跳跃 : 如下图 16 展示了 UniDiffuser 能对真实的两张图像进行插值:
如下图 16 展示了 UniDiffuser 能对真实的两张图像进行插值: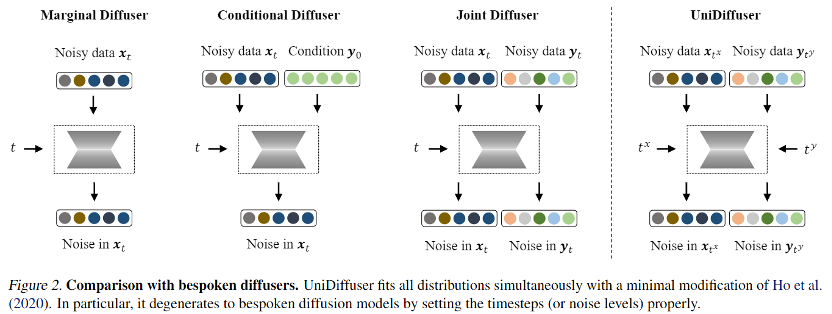 以双模态为例子,最终的训练目标函数如下所示:
以双模态为例子,最终的训练目标函数如下所示: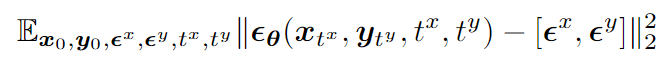 其中
其中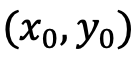 代表数据,
代表数据,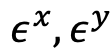 代表加入到两个模态中的标准高斯噪声,
代表加入到两个模态中的标准高斯噪声,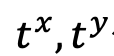 代表两个模态加入噪声的大小(即时间),两者独立的从 {1,2,…,T} 中采样,
代表两个模态加入噪声的大小(即时间),两者独立的从 {1,2,…,T} 中采样,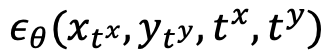 为噪声预测网络,同时预测两个模态上的噪声。在训练后,通过向噪声预测网络设置两个模态合适的时间,UniDiffuser 能够实现无条件、条件以及联合生成。例如将文本的时间设置为 0,可以实现文到图生成;将文本的时间设置为最大值,可以实现无条件图像生成;将图文时间设置为相同值,可以实现图文联合生成。下面罗列了 UniDiffuser 的训练和采样算法,可见这些算法相对原始的扩散模型均只做了微小的改动,易于实现。
为噪声预测网络,同时预测两个模态上的噪声。在训练后,通过向噪声预测网络设置两个模态合适的时间,UniDiffuser 能够实现无条件、条件以及联合生成。例如将文本的时间设置为 0,可以实现文到图生成;将文本的时间设置为最大值,可以实现无条件图像生成;将图文时间设置为相同值,可以实现图文联合生成。下面罗列了 UniDiffuser 的训练和采样算法,可见这些算法相对原始的扩散模型均只做了微小的改动,易于实现。 此外,由于 UniDiffuser 同时建模了条件分布和无条件分布,因此 UniDiffuser 天然地支持 classifier-free guidance。下面的图 3 展示了 UniDiffuser 的条件生成和联合生成在不同的 guidance scale 下的效果:
此外,由于 UniDiffuser 同时建模了条件分布和无条件分布,因此 UniDiffuser 天然地支持 classifier-free guidance。下面的图 3 展示了 UniDiffuser 的条件生成和联合生成在不同的 guidance scale 下的效果: 网络架构针对网络架构,研究团队提出使用基于 transformer 的架构来参数化噪声预测网络。具体地,研究团队采用了最近提出的 U-ViT 架构。U-ViT 将所有的输入都视作 token,并在 transformer 块之间加入了 U 型连接。研究团队也采用了 Stable Diffusion 的策略,将不同模态的数据都转换到了隐空间再进行扩散模型的建模。值得注意的是,U-ViT 架构同样来自该研究团队,并且已被开源在 https://github.com/baofff/U-ViT。
网络架构针对网络架构,研究团队提出使用基于 transformer 的架构来参数化噪声预测网络。具体地,研究团队采用了最近提出的 U-ViT 架构。U-ViT 将所有的输入都视作 token,并在 transformer 块之间加入了 U 型连接。研究团队也采用了 Stable Diffusion 的策略,将不同模态的数据都转换到了隐空间再进行扩散模型的建模。值得注意的是,U-ViT 架构同样来自该研究团队,并且已被开源在 https://github.com/baofff/U-ViT。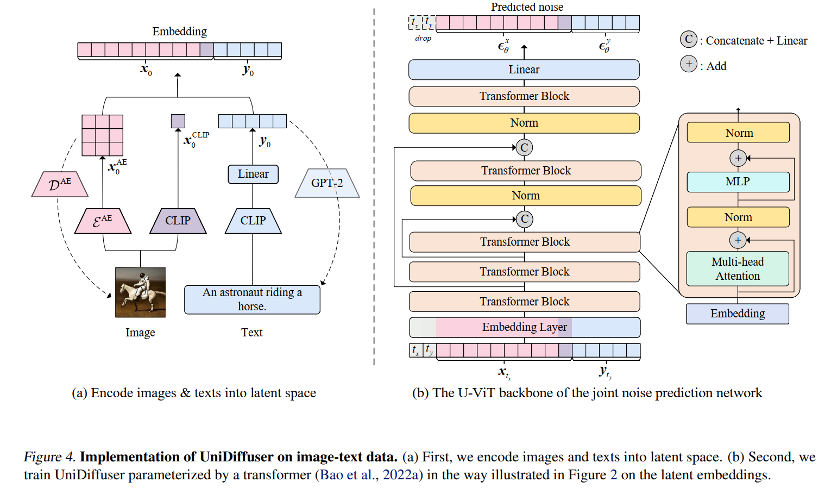
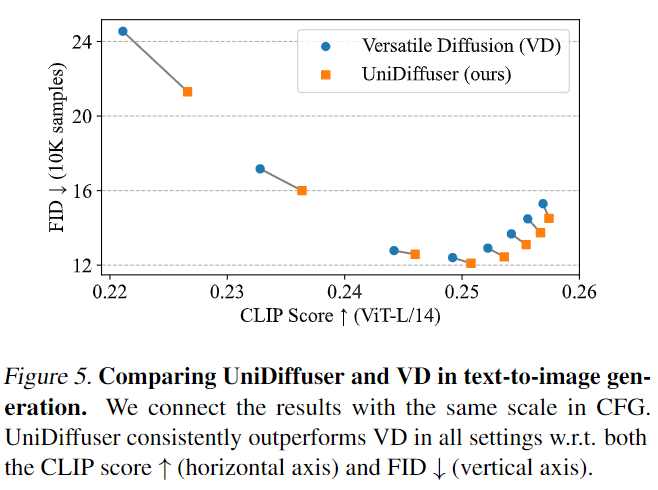 然后 UniDiffuser 和 Versatile Diffusion 进行了图到文上的效果比较。如下面的图 6 所示,UniDiffuser 在图到文上有更好的 CLIP Score。
然后 UniDiffuser 和 Versatile Diffusion 进行了图到文上的效果比较。如下面的图 6 所示,UniDiffuser 在图到文上有更好的 CLIP Score。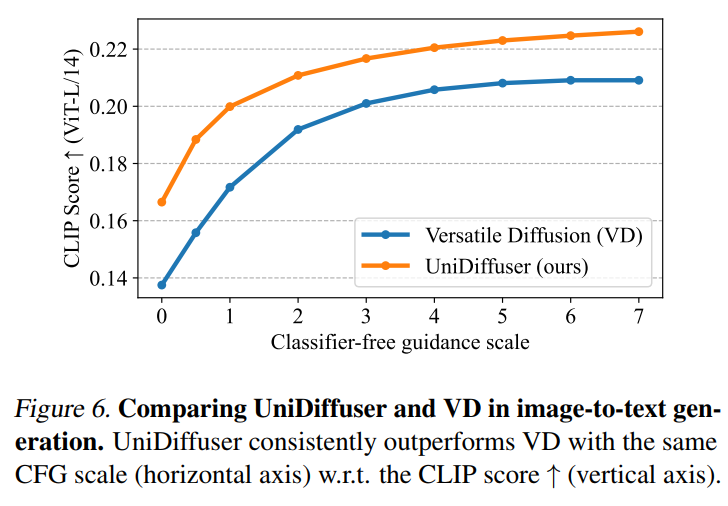 UniDiffuser 也和专用的文到图模型在 MS-COCO 上进行了 zero-shot FID 的比较。如下面的表 1 所示,UniDiffuser 可以和专用的文到图模型取得可比的效果。
UniDiffuser 也和专用的文到图模型在 MS-COCO 上进行了 zero-shot FID 的比较。如下面的表 1 所示,UniDiffuser 可以和专用的文到图模型取得可比的效果。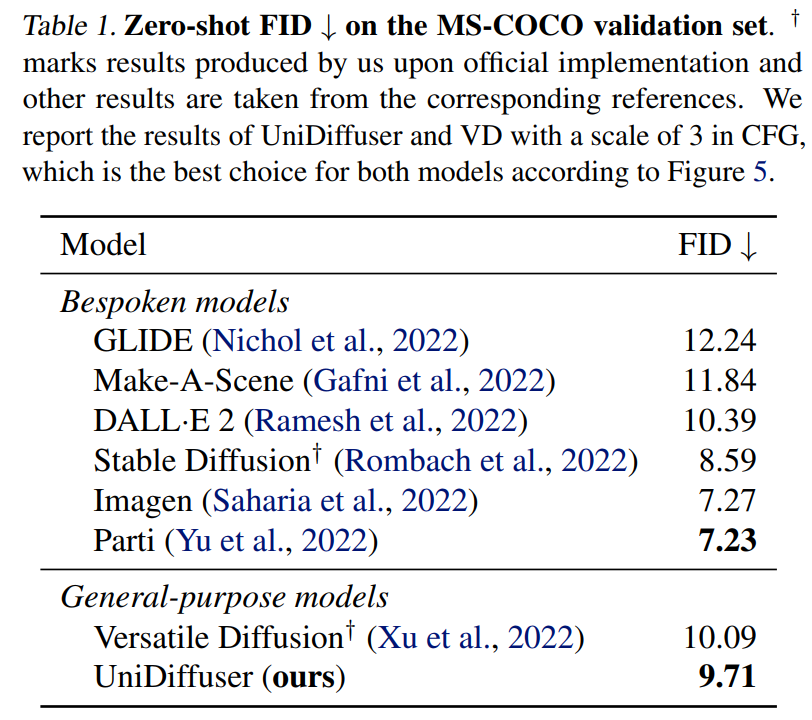
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我正在使用RABL输出Sunspot/SOLR结果集,搜索结果对象由多种模型类型组成。目前在rablView中我有:objectfalsechild@search.results=>:resultsdoattribute:id,:resource,:upccodeattribute:display_description=>:descriptioncode:start_datedo|r|r.utc_start_date.to_iendcode:end_datedo|r|r.utc_end_date.to_iendendchild@search=>:statsdoattribute:to
我有一个连接表create_table"combine_tags",force:truedo|t|t.integer"user_id"t.integer"habit_id"t.integer"valuation_id"t.integer"goal_id"t.integer"quantified_id"end其目的是让tag_cloud为多个模型工作。我把它放在application_controllerdeftag_cloud@tags=CombineTag.tag_counts_on(:tags)end我的tag_cloud看起来像这样:css_class%>#orthisdepen
这篇文章网络结构ESRT(EfficientSuper-ResolutionTransformer)还是蛮复杂的,是一个CNN和Transformer结合的结构。文章提出了一个高效SRTransformer结构,是一个轻量级的Transformer。作者考虑到图像超分中一张图像内相似的细节部分可以作为参考补充,(类似于基于参考图像Ref的超分),于是引入了Transformer,可以在图像中建模一种长期依赖关系。而ViT这些方法计算量太大,太占内存,于是提出了这个轻量版的Transformer结构(ET)ET只使用了transformer中的encoder,并且作者还使用了featurespi
首先让我确认这不是重复的(因为那里发布的答案没有解决我的问题)。Thispost本质上是我的确切问题:Capybara无法在Stripe模式中找到表单字段来填写它们。这是我的capybara规范:describe'checkout',type::feature,js:truedoit'checksoutcorrectly'dovisit'/'page.shouldhave_content'Amount:$20.00'page.find('#button-two').click_button'PaywithCard'Capybara.within_frame'stripe_checkou
用vit的时候读了一下transformer的思想,前几天面试结束之后发现对QKV又有点忘记了,写一篇文章来记录一下参考链接:哔哩哔哩:在线激情讲解transformer&Attention注意力机制(上)在线激情讲解transformer&Attention注意力机制(上)_哔哩哔哩_bilibiliAttentionisallyouneed介绍更具体的介绍可以去阅读论文在Attentionisallyouneed这篇文章中提出了著名的Transformer模型Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transform
我需要与用户操作交互的模态弹出窗口,如下图所示。但是这个模态弹出窗口应该是纯java脚本。严禁使用JQuery或JQuery插件。期待您的来信。提前致谢。 最佳答案 这里我分享一些插件,基本上都是用Jquery和Javascript创建的。无论您在纯JavaScript中寻找什么,都可以使用http://alpha.jspanel.de/media/demos/nojquery/index.php另一个是使用Jquery创建的。是https://lobianijs.com/site/lobipanel#examples使用第一个选项
我正在研究BootstrapPopUpModals。我有2个按钮,分别名为Button1和Button2。&我有2个模态框,分别名为Modal1和Modal2。Note:Button2isinsidetheModal1&Button1isontheWebPage.如果我点击Button1,Modal1应该是打开的&如果我点击Button2是在Modal里面,那么Modal1应该会自动隐藏并且应该显示Modal2。我正在使用jQueryYet做这件事并且它工作正常。$('#button1').click(function(){$('#modal1').modal('hide');$('#
这是我的代码:$(document).ready(function(){if($.cookie('msg')==0){$('#myModal').modal('show');$.cookie('msg',1);}});在页面加载时模型显示,但当我刷新时它一直显示它应该只显示一次。$.cookie来自https://github.com/carhartl/jquery-cookie更新:这有效:“隐藏”由于某种原因无效$(document).ready(function(){if($.cookie('msg')==null){$('#myModal').modal('show');$.c
{%csrf_token%}如何从以下位置获取EMAIL值:到:从这里开始:functionshowDialog(){$("#dialog-modal").dialog({});} 最佳答案 使用对话框打开时调用的对话框打开事件...所以替换那里的值..$("#dialog-modal").dialog({open:function(event,ui){varboxInput=$("#befor-box").find('input[name="email"]').val();//getthevalue..$("#dialog-mod