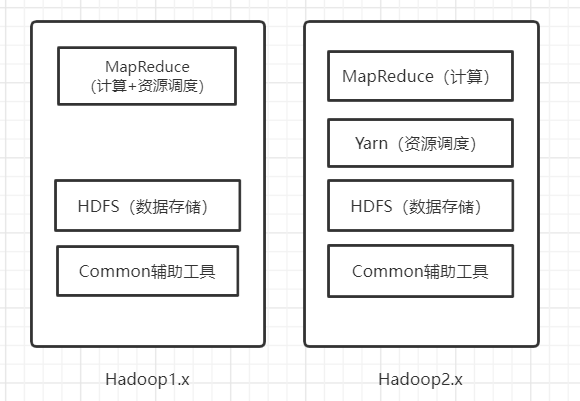
在Hadoop1.x时代,Hadoop中的MapReduce同时处理计算和资源调度,耦合性较大,
在Hadoop2.x时代,增加了Yarn,Yarn只负责资源的调度,MapReduce只负责运算。
HDFS是一个文件系统,用于存储文件,其次,它是分布式的,由很多服务器联合起来实现其功能。
优点
1)高容错,数据自动保存多个副本。它通过增加副本的形式,提高容错性。一个副本丢失之后,它自动恢复。
2)适合处理大数据。
3)可构建在廉价的机器上,通过多副本机制,提高可靠性。
缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。存储大量的小文件,会占用NameNode大量的内存来存储文件目录和块信息。
而且小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)不支持并发写入、文件随机修改。一个文件只能有一个写,不允许多个线程同时写。仅支持数据追加,不支持文件
的随机修改。
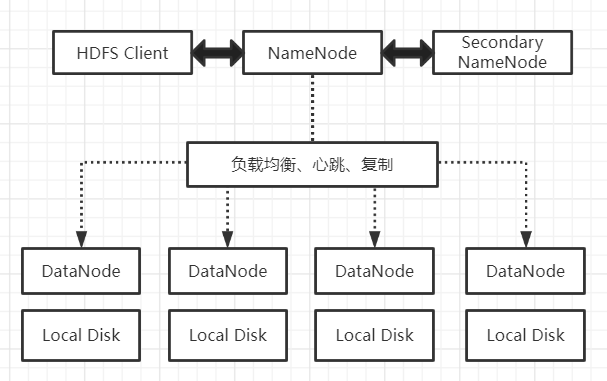
HDFS由四部分组成,HDFS Client、NameNode、DataNode和Secondary NameNode。HDFS是一个主/从体系结构,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据DataNode存储实际的数据。
HDFS Client:
1、提供一些命令来管理、访问 HDFS,比如启动或者关闭HDFS。
2、与 DataNode 交互,读取或者写入数据;读取时,要与 NameNode 交互,获取文件的位置信息;写入 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
NameNode:即Master,
1、管理 HDFS 的名称空间。
2、管理数据块(Block)映射信息
3、配置副本策略
4、处理客户端读写请求。
DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
1、存储实际的数据块。
2、执行数据块的读/写操作。
Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
1、辅助 NameNode,分担其工作量。
2、定期合并 fsimage和fsedits,并推送给NameNode。
3、在紧急情况下,可辅助恢复 NameNode。
YARN 是Hadoop分布式处理框架中的资源管理和作业调度技术。负责将系统资源分配给在 Hadoop 集群中运行的各种应用程序,并调度要在不同集群节点上执行的任务。
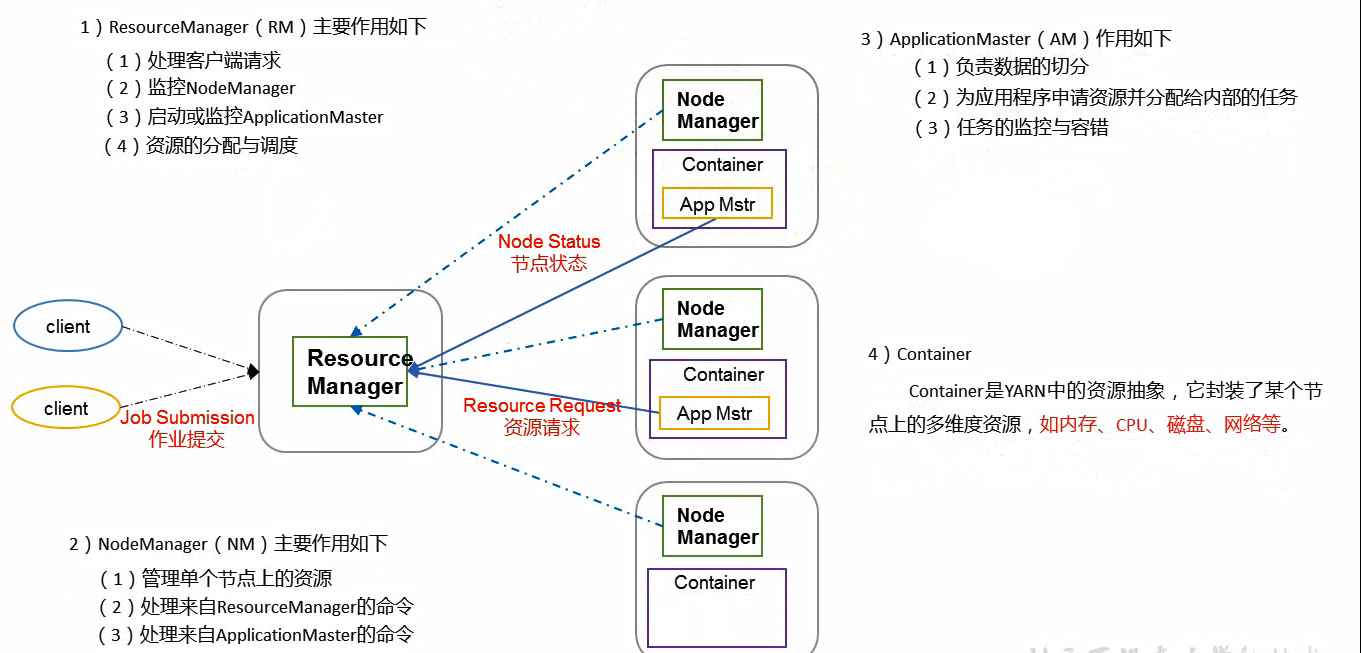
ResourceManager:
1.处理客户端请求。
2.监控NodeManager。
3.启动或监控ApplicationMaster。
4.资源的分配和调度。
NodeManager:
1.管理来自单个节点上的资源。
2.处理来自ResourceManager的命令。
3.处理来自ApplicationMaster的命令。
ApplicationMaster:
1.负责数据的切分。
2.为应用程序申请资源并分配给内部的任务。
3.任务的监控与容错。
Container:
Container的YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
MapReduce负责海量数据的计算。
工作方式简单来说就是我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
如thisanswer中所述,Array.new(size,object)创建一个数组,其中size引用相同的object。hash=Hash.newa=Array.new(2,hash)a[0]['cat']='feline'a#=>[{"cat"=>"feline"},{"cat"=>"feline"}]a[1]['cat']='Felix'a#=>[{"cat"=>"Felix"},{"cat"=>"Felix"}]为什么Ruby会这样做,而不是对object进行dup或clone? 最佳答案 因为那是thedocumenta
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
云计算实验中要求我们在Linux系统安装Hadoop,故来做一个简单的记录。· 注:我的操作系统环境是Ubuntu-20.04.3,安装的JDK版本为jdk1.8.0_301,安装的Hadoop版本为hadoop2.7.1。(不确定其他版本是否会出现版本兼容问题)Hadoop安装步骤如下: 一、更新apt和安装vim编辑器 二、配置本机无密码登录SSH 三、安装JAVA环境 四、下载安装Hadoop 五、伪分布式搭建一、更新apt和安装vim编辑器1、更新aptsudoapt-getupdate2、安装vim
一、设置免密登录1、系统偏好设置-----共享----勾选远程登录,所有用户2、打开终端,输入命令ssh-keygen-trsa,一直回车即可2.查看生成的公钥和私钥 cd~/.ssh ls会看到~/.ssh目录下有两个文件:①私钥:id_rsa②公钥:id_rsa.pub3.将公钥内容写入到~/.ssh/authorized_keys中 cat~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys4.测试在terminal终端输入 sshlocalhost如果出现以下询问输入yes,不需要输入密码就能登录,说明配置成功Areyousureyouw
最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理已参加机试人员的实战技巧文章目录使用说明本期题目:卡片组成的最大数字题目输入输出描述示例一输入输出示例二输入输出Code
假设我的CouchDB数据库中存储了两种类型的文档。第一个是属性类型设置为contact,第二个是phone。联系人类型文档有另一个名为名称的属性。电话类型有属性number和contact_id以便它可以引用联系人。这是一个简单的一对多场景,其中一个联系人可以有N个电话号码(我知道它们可以嵌入到单个联系人文档中,但我需要证明与不同文档的一对多关系)。原始示例数据,其中Scott有2个电话号码,Matt有1个电话号码:{_id:"fc93f785e6bd8c44f14468828b001109",_rev:"1-fdc8d121351b0f5c6d7e288399c7a5b6",typ
考虑这个数组:[["B","C","C","C","C","B","B","C","A","A"],["B","A","C","B","B","A","B","B","A","A"],["B","C","B","C","A","A","A","B","C","B"],["B","B","B","A","C","B","A","C","B","A"],["A","A","A","C","A","C","C","B","A","C"],["A","B","B","A","A","C","B","C","C","C"],["C","B","A","A","C","B","B","C","A"
因此,当我开始深入研究angular2时,我想我创建了一个列出人员的表。一个组件用于创建表格(person-list),另一个组件用于表格中的每个人(person-list-item)。很简单,对吧?通过以下输出,我意识到这并不容易。如您所见,表格行不遵循表格结构。通过在检查器中查看html,我们还可以看到毁了table。有没有办法解决这个问题,或者我应该只在中创建表格行?元素为了不让浏览器毁了表格?我想这是一个适用于多个组件会破坏某个DOM元素的其他情况的问题。app.componentimport{PersonListComponent}from'./person-list.com
博学之,审问之,慎思之,明辨之,笃行之🏂hiveonspark搭建好后,任务提交会有问题,因为通过hive会话提交的任务一直存在且不会结束(除非关掉这个hive会话),根本原因是这些任务提交到了Yarn的同一个队列中,前面的任务没有执行完毕后面的任务不会执行,所以解决办法是增加一个Yarn队列,指定任务提交的队列,这样就不会出现任务的阻塞。目录一、情景复现二、原因三、Yarn队列配置—增加队列1.情景复现:搭建好hiveonspark后,在命令行直接进入hive会话,提交任务后,在ResourceManager上jps查看进程可以看到有个进程ApplicationMaster一直存在,打开Re