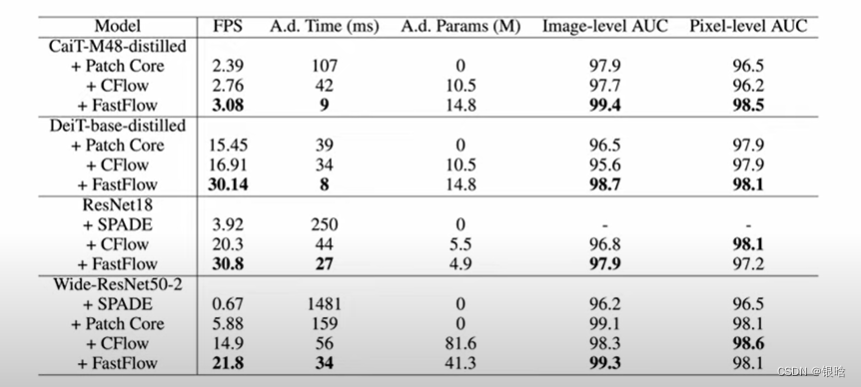
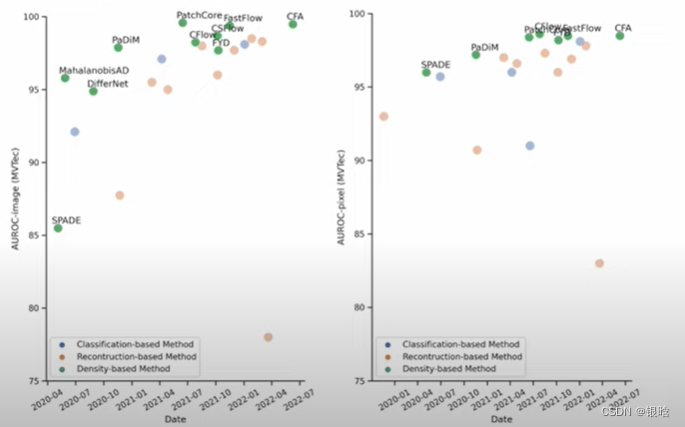
Patchcore是截至2022年在AD数据集上表现最好的缺陷检测模型
背景:
在工业图像的异常检测中,最大的问题就是冷启动的问题。
首先,在训练集中都是正常的图片,模型很容易捕获到正常图像的特征,但是很难捕获到异常缺陷的样本(这类样本很少,获取也难)
其次,分布漂移。正常图像和异常图像分布是不一样的,模型学习的是正常图像的数据分布,而异常图像的数据分布和正常图像不一样
AD数据集上的偏差:
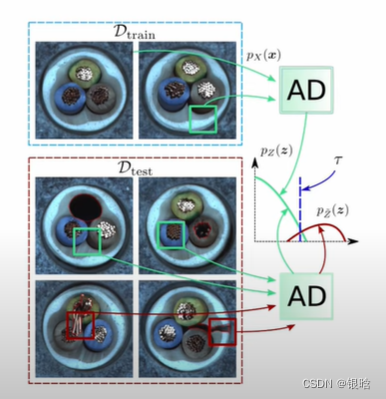
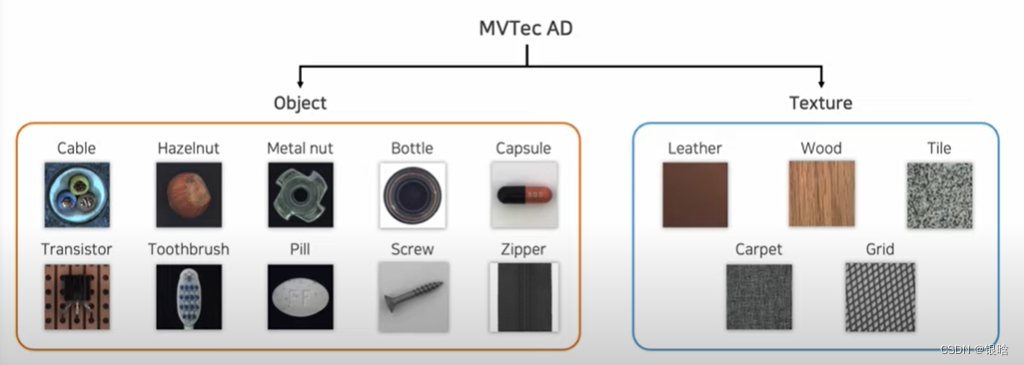
AD数据集介绍一下:
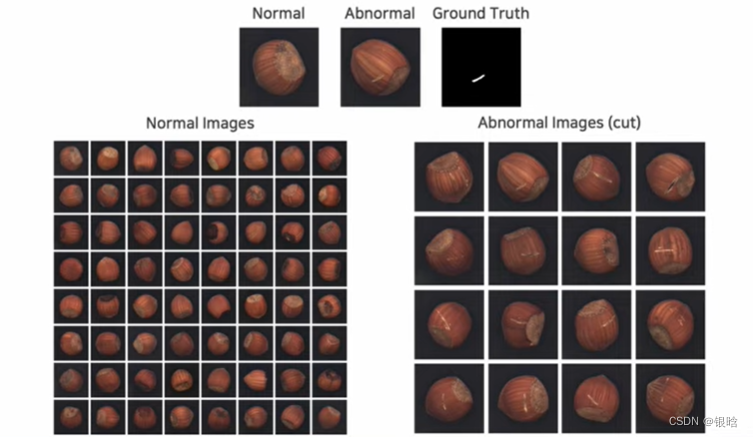
尝试解决:
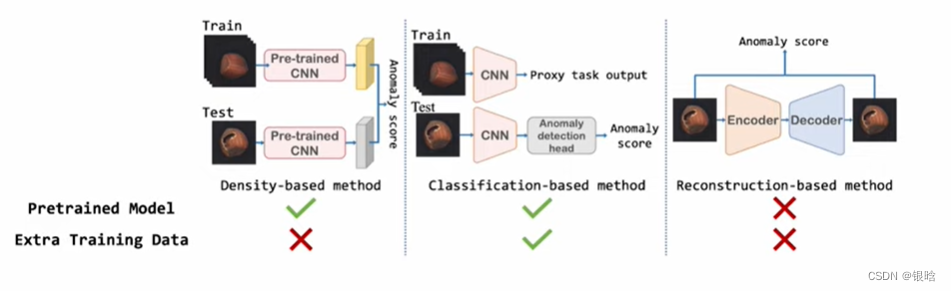
本篇文章采取的方法是基于密度的异常检测方法:
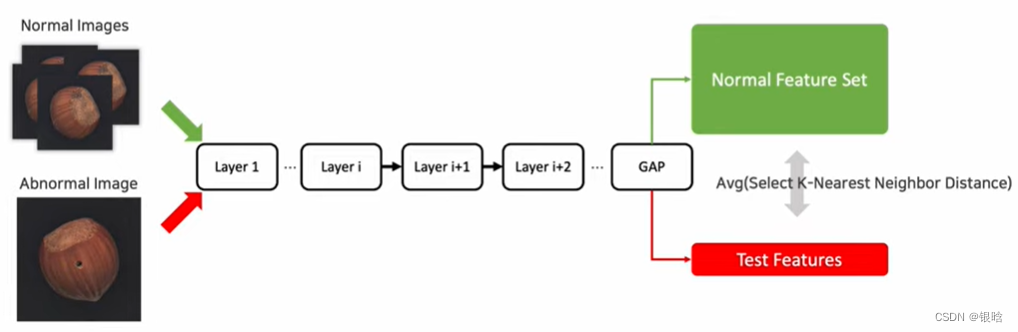
GAP:全局平均。
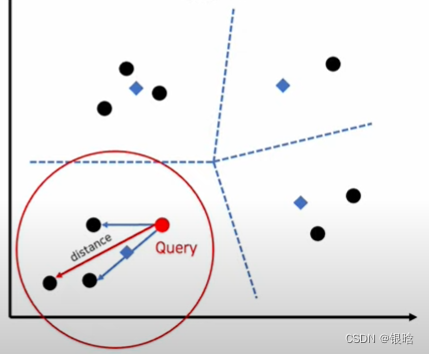
会定义一个anomaly score
就是你训练正常的数据,捕获正常图像的特征,然后有一个异常的数据进来,就会和正常数据产生一个差异,通过整个差异来判断是否是异常。
其实这篇文章也是站着巨人的肩膀上:
SPADE:
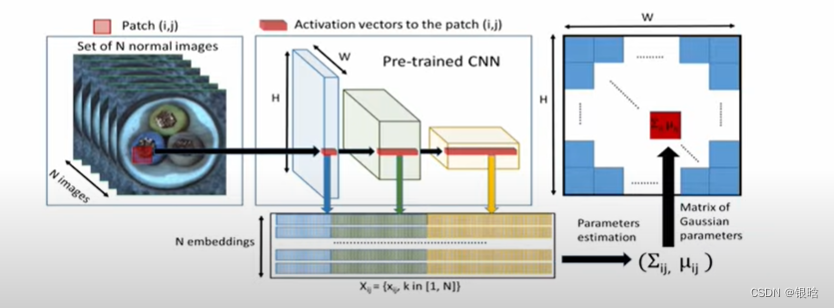
PaDim:
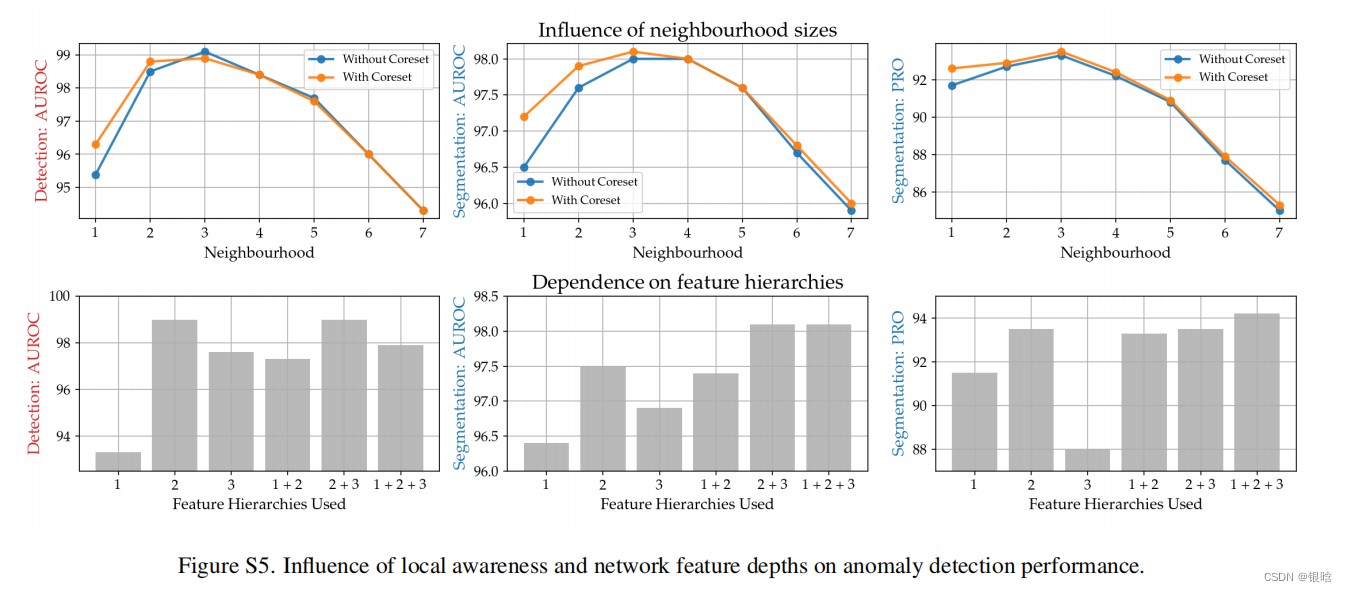
这篇文章提出3个方法:
总体流程:
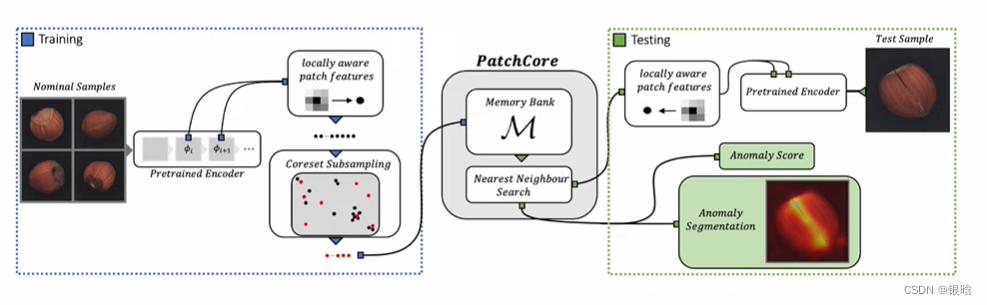
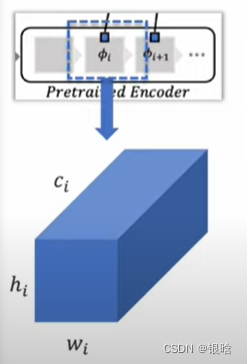
patchcore采用ImageNet的预训练模型
fi代表网络 ;
i
i
i代表样本 ;
j
j
j代表网络层级
一般来说,获取提取的特征是在ResNet最后一层获取,但是存在两个问题
解决:
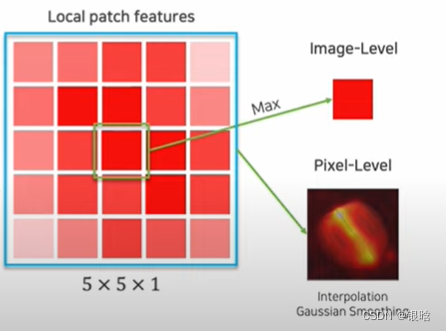
什么是中间特征:
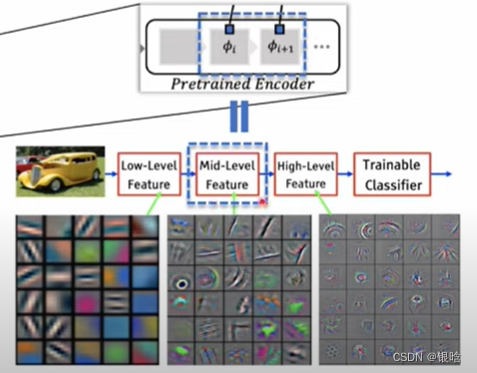
先放图片理解:
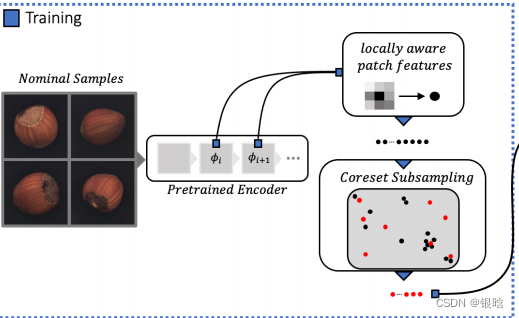
特征提取:
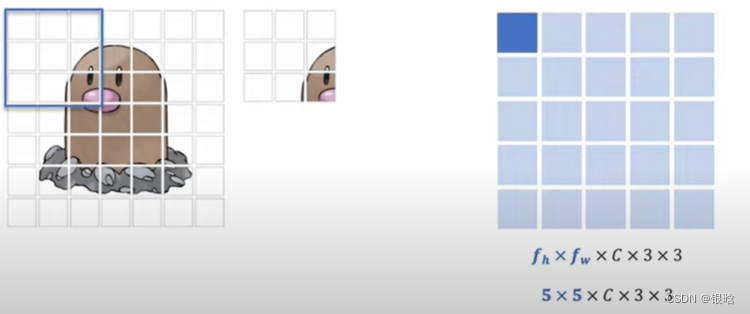
扫描所有的:
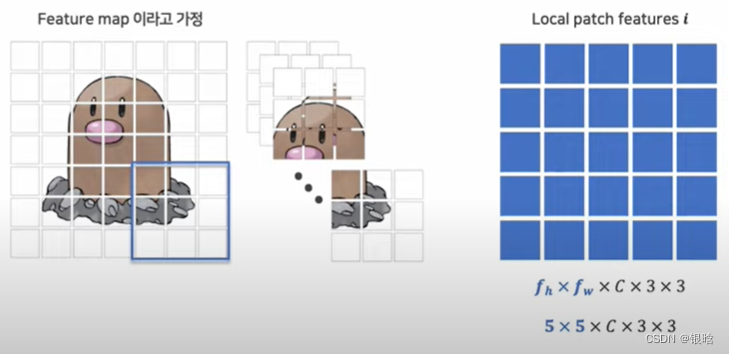
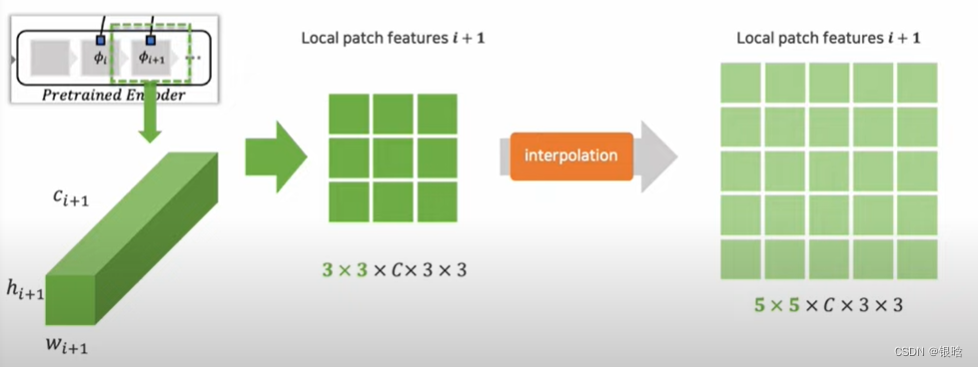
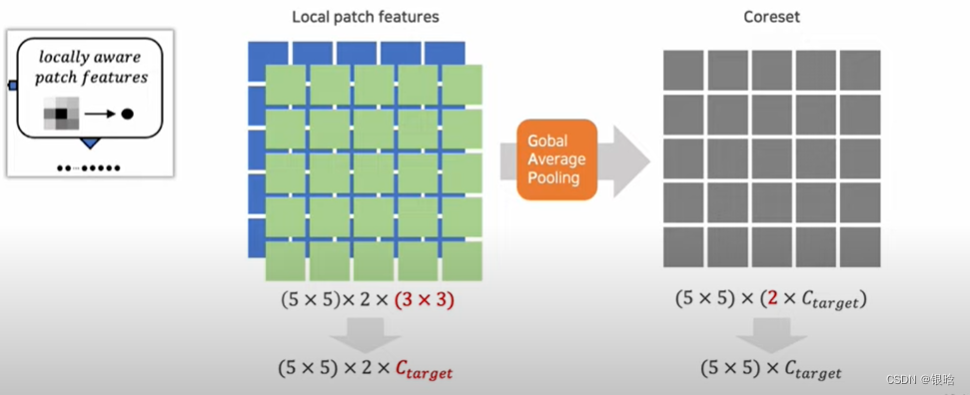
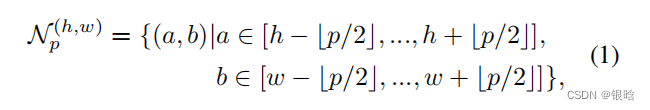
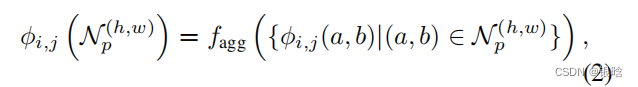
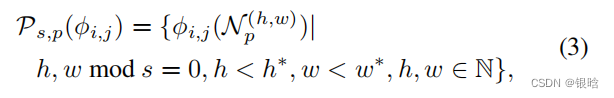
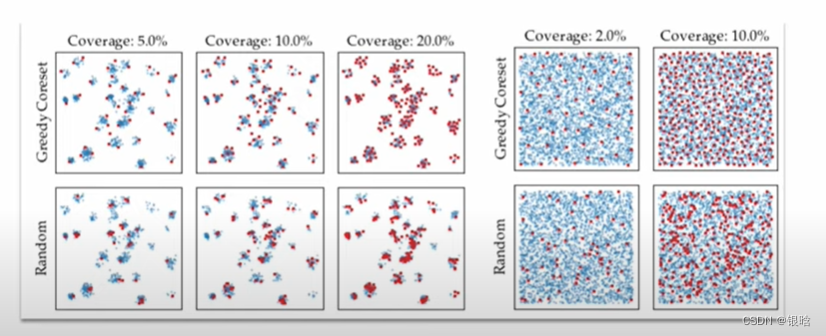
基于贪心策略的子采样方法:

流程解释:
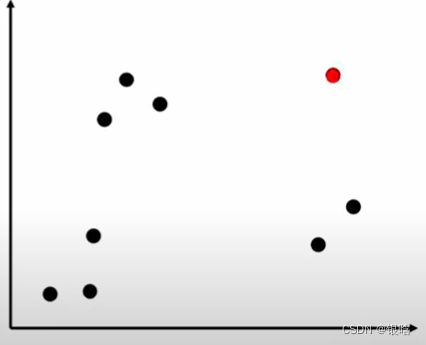
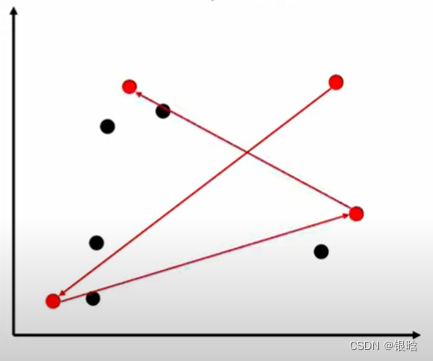
对比一波传说中的随机采样:
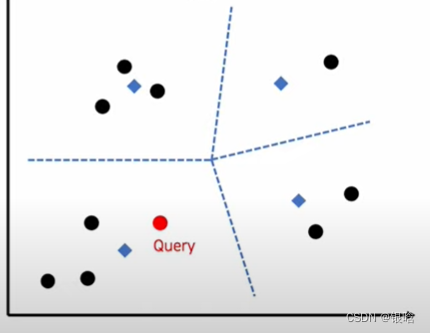
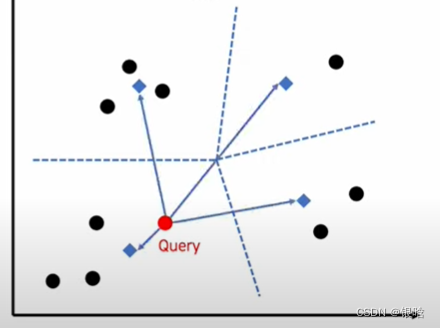
测试集的数据进来

每个query进来都要找最近的邻居,又是一波骚操作
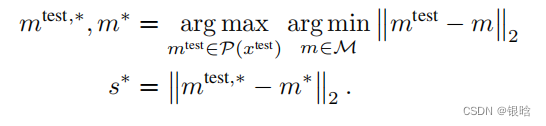
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
Two-StreamConvolutionalNetworksforActionRecognitioninVideos双流网络论文精读论文:Two-StreamConvolutionalNetworksforActionRecognitioninVideos链接:https://arxiv.org/abs/1406.2199本文是深度学习应用在视频分类领域的开山之作,双流网络的意思就是使用了两个卷积神经网络,一个是SpatialstreamConvNet,一个是TemporalstreamConvNet。此前的研究者在将卷积神经网络直接应用在视频分类中时,效果并不好。作者认为可能是因为卷积神经
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x
目录文章信息写在前面Background&MotivationMethodDCNV2DCNV3模型架构Experiment分类检测文章信息Title:InternImage:ExploringLarge-ScaleVisionFoundationModelswithDeformableConvolutionsPaperLink:https://arxiv.org/abs/2211.05778CodeLink:https://github.com/OpenGVLab/InternImage写在前面拿到文章之后先看了一眼在ImageNet1k上的结果,确实很高,超越了同等大小下的VAN、RepLK
ChatGPT是一款引人注目的产品,它的突破性功能在各个领域都创造了巨大的需求。仅在发布后的两个月内,就累计了超过1亿的用户。它最突出的功能是能够在几秒钟内完成各种文案创作,包括论文、歌曲、诗歌、睡前故事和散文等。与流行的观点相反,ChatGPT可以做的不仅仅是为你写一篇文章,更有用的是它如何帮助指导您的写作过程和写作方法。接下来手把手教你利用ChatGPT辅助完成写作的五种方法。1.使用ChatGPT生成论文的观点在开始写作之前,我们需要让ChatGPT帮我们充实想法,找到论文切入点。当老师布置论文时,通常会给予学生一个提示,让他们可以自由地表达和分析。这时,我们需要找到论文的角度和思路,然
目录 YOLO简介argpares模块detect模块导入部分主函数main()run()资源处理for循环输出结果 YOLO简介YOLO是目前最先进的目标检测模型之一,现在博客上常有的是如何使用YOLO模型训练自己的数据集,而鲜有对YOLO代码的精读。我认为只有对算法和代码实现有全面的了解,才能将YOLO使用的更加得心应手。这里的代码精读为YOLO v5,github版本为6.0。版本不同代码也会有所不同,请结合源码阅读本文。本文使用注释完成对每行代码的解读,文段来概括总结每个代码段。yolov5代码6.0版本github代码地址argpares模块在了解yolov5代码之前,首先要了解py
IV.SYSTEMIMPLEMENTATIONWeadoptmodulardesignfollowingtheintegrationofblockchain.Itbringsmoreflexibilitybyseparatingtheimplementationofdifferentfunctionalities,sowecouldleveragetheadvantagesoftheblockchain-basedsmartcontractwhilereducingoverhead.Figure3illustrateshowdifferentmodulesareinvolvedintheint
【前言】去年的这个时候,一边准备考研复试,一边撰写本科毕设论文,读了很多论文,惊叹于其美观的伪代码算法,所以在之前的教程中教大家使用Aurora在Word中插入伪代码,具体可以看使用Aurora在Word中插入算法伪代码教程!!!亲测有效!!!写论文必备https://blog.csdn.net/jucksu/article/details/116307244效果如图所示(附图是本科毕设当中的K-Means聚类算法伪代码),不算很差但不是很美观,包括一些下标,公式,语法,编辑器反应慢,编程体验差,相关参考资料少等方面的缺陷。研究生以来,接触了Latex,学习了overleaf,所以现在教大家使
目录一种简单上手的暴力论文分析方法——以区块链为例【含项目源码】太长不看版本:最终成果:情况说明论文推荐方面论文投稿方面以下是具体的实现,有其他研究方向想自行确定的请仔细阅读,授人以鱼不如授人以渔第一章、确定对象——研究热点的中国计算机研究生第二章、思路——基于爬虫结合关键字过滤暴力获取所需论文信息第一步:从CCF推荐目录中获取网址01、背景介绍02、数据预处理03、数据写入表格第二步:从中科院分区中获取期刊对应分区第三步:从期刊/会议对应网址中爬取到子网页并进入,获取到其中的标题、年份等信息第四步:针对获取到的表格数据进行分析和整理实际爬取数据量【其实就论文的标题+对应年份】
不同格式的符号命名规则符号latex表示意义x\mathcal{x}x$\mathcal{x}$标量x\bm{x}x$\bm{x}$向量x\mathbf{x}x$\mathbf{x}$变量集A\mathbf{A}A$\mathbf{A}$矩阵I\mathbf{I}I$\mathbf{I}$单位矩阵χ\chiχ$\mathbf{\chi}$样本空间或状态空间D\mathcal{D}D$\mathcal{D}$概率分布D\mathbf{D}D$\mathbf{D}$样本数据(数据集)H\mathcal{H}H$\mathcal{H}$假设空间H\mathbf{H}H$\mathbf{H}$假设集L