目录
1、/dev/hda, /dev/hdb, /dev/sda, /dev/sdb, 他们之间有什么区别?
一直对磁盘分区的概念没有太深入的理解,觉得有必要单独梳理下。
对于物理机和虚拟机有各自磁盘的概念,比如物理机上是真实的磁盘信息,什么叫真实?就是没有进行虚拟化的。
虚拟机上也是要虚拟化磁盘的,对于用户来说就像一台物理机一样。但是既然是虚拟机,那么磁盘可能是虚拟化后的,一般会有固定的名字,比如经过kvm虚拟化技术虚拟出来的磁盘,名称是vda,vdb等,表示虚拟磁盘。但是也有例外的,见过百度云那边经过kvm虚拟化出来的虚拟机,但是分区名称却叫sdb,而sdb一般是物理机上真实的磁盘分区名称。
一般概念上:vda,vdb叫虚拟磁盘,或者直接说磁盘也行,在linux上的设备文件为/dev/vda,/dev/vdb。
以上说的/dev/vdb是磁盘,磁盘需要再进行分区。比如分成/dev/vdb1,/dev/vdb2,/dev/vdb3等,每个分区可以指定大小。
如下可以看到/dev/vdb被分成了/dev/vdb1和/dev/vdb2两个分区。

我们可以再在/dev/vdb磁盘上加个分区吗?当然是可以的。
在vdb上再添加创建vdb3分区:
第一步:编辑分区。执行命令fdisk /dev/vdb:该命令意思是为/dev/vdb磁盘进行分区或者说叫编辑/dev/vdb磁盘。
第二步:新建分区。输入n,回车,n(new的缩写)表示新建分区
第三步:分区类型。继续根据提示输入p(默认就是p),表示分区类型为主分区(需要看下主分区与扩展分区的区别)。
第四步:分区号。Partition number输入3
第五步:柱面。起始的柱面选择(应该是磁盘的概念,研究下),直接enter选择默认
第六步:设置磁盘大小,大小用+size(K,M,G),如+100G,表示分区大小设置为100G,+1G表示分区大小是1G
第七步:保存分区并退出:wq

以下案例是创建/dev/vdb1分区。由于是第一次创建分区,因此Partition number默认是第一块


实践:

第三步创建好了分区,但是分区需要格式化才能挂载使用。
linux提供了几种不同的格式化方式,可mk,tab补齐查看
格式化方式不同在于铺文件系统时的索引和链接划分不同
如本例选择mkfs.ext2格式化方式
如果选择mkfs.ext4格式化方式,则输入命令:mkfs.ext4 /dev/vdb3
如果是xfs文件系统,则mkfs.xfs /dev/vdb3
ext2,ext4,xfs等文件系统请看第五点。
验证格式化是否成功:
通过 df -T命令查看(注意,要先把分区挂载到目录,否则df -T命令看不到):

centos7.0开始默认文件系统是xfs,centos6是ext4,centos5是ext3。
ext4是第四代扩展文件系统(英语:Fourth EXtended filesystem,缩写为ext4)是linux系统下的日志文件系统,是ext3文件系统的后继版本。
xfs是一种非常优秀的日志文件系统,它是SGI公司设计的。xfs被称为业界最先进的、最具可升级性的文件系统技术。
xfs在很多方面确实做的比ext4好,ext4受限制于磁盘结构和兼容问题,可扩展性和scalability确实不如xfs,另外xfs经过很多年发展,各种锁的细化做的也比较好
第四点对分区进行了格式化,那么我们要使用这个分区了!
怎么使用呢?当然是挂载到我们的目录使用啦!
所以步骤是:
第一步:创建目录,如mkdir -p /data
第二步:挂载。将/dev/vdb3分区挂载到/data上。即mount /dev/vdb3 /data
第六点讲了挂载,对应的还有卸载的命令。比如卸载/data,对应的命令为:umount /data。
我们可能会担心,数据丢失问题,这个其实不会。
因为卸载只是解除了/data目录与/dev/vdb3的绑定关系,之前的数据仍然存在/dev/vdb3分区中,并没有丢掉,所以我们只要重新挂载一下就行了。
第一步:卸载/data。umount /data。
第二步:创建新的挂载的目录。如mkdir -p /weiwei。
第三步:将/dev/vdb3挂载到/weiwei下。mount /dev/vdb3 /weiwei
我们进入到/weiwei会发现,原来/data中的数据文件都在/weiwei下了
Swap分区在系统的物理内存不够用的时候,把硬盘空间中的一部分空间释放出来,以供当前运行的程序使用。
free -m:查看内存的命令可顺便查看是否有swap分区。wap空间为0则代表系统并没有开启swap分区。
swap分区创建有两种方式:
方式一:新建磁盘分区作为swap分区。和创建普通的磁盘分区类似。
方式二:用文件作为swap分区 (操作更简单)
注意:两种方式都必须用root权限,操作过程应该小心谨慎。
1.创建要作为swap分区的文件:增加1GB大小的交换分区,则命令写法如下,其中的count等于想要的块的数量(bs*count=文件大小)。
2.格式化为交换分区文件:
3.启用交换分区文件:
4.使系统开机时自启用,在文件/etc/fstab中添加一行:
以上说的/dev/vdb是磁盘,/dev/vdb1,/dev/vdb2是表示分区,都是物理概念。
LVM是Linux环境下对磁盘分区进行管理的一种机制,LVM是建立在硬盘和 分区之上的一个逻辑层,来提高磁盘分区管理的灵活性。
通过LVM系统管理员可以轻松管理磁盘分区,如:将若干个磁盘分区连接为一个整块的卷组 (volumegroup),形成一个存储池。管理员可以在卷组上随意创建逻辑卷组(logicalvolumes),并进一步在逻辑卷组上创建文件系 统。管理员通过LVM可以方便的调整存储卷组的大小,并且可以对磁盘存储按照组的方式进行命名、管理和分配。
其实我们很容易联想到K8S中PV(PersistentVolume)与PVC(PersistentVolumeClaim)的概念。他们都属于逻辑卷范畴。
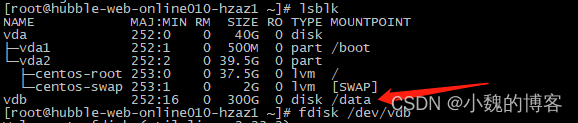
fdisk -l 查看服务器挂载了多少个磁盘,以及每个磁盘的分区情况。
如下可知虚机挂载了4块磁盘,其中/dev/vda磁盘创建了两个分区。

fdisk /dev/vdb:该命令意思是为/dev/vdb磁盘进行分区或者说叫编辑/dev/vdb磁盘。
mount -l 查看文件系统挂载情况
mount -a 依据配置文件/etc/fstab的内容,自动挂载。的意思是将/etc/fstab的所有内容重新加载。并自动挂载 /etc/fstab 里面的东西。
umount /data:是卸载/data目录之前挂载的分区。和mount意思正好相反。
df,全称:disk full,列出文件系统的整体磁盘使用量
df -h 查看文件系统挂载和资源使用情况
du,全称:disk used,检查磁盘空间使用量
如下:du -sh ./*

mkfs.ext4命令是用于对磁盘设备进行Ext4格式化的操作。
类似的还有mkfs.ext4 /dev/vdb3
如果是xfs文件系统,则mkfs.xfs /dev/vdb3
lsblk命令 的英文是“list block”,即用于列出所有可用块设备的信息,而且还能显示他们之间的依赖关系
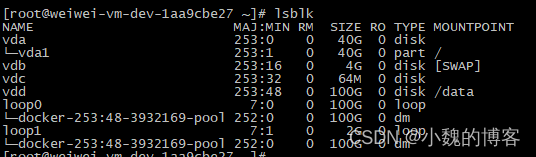
注意:TYPE为part表示NAME对应的是分区,TYPE为disk,表示NAME对应的是硬盘。

1、介绍
/etc/fstab是用来存放文件系统的静态信息的文件。当系统启动的时候,系统会自动地从这个文件读取信息,并且会自动将此文件中指定的文件系统挂载到指定的目录。
显示分区的基本信息:lsblk -f

2、案例介绍
通过内核名称编写:
# <file system> <dir> <type> <options> <dump> <pass>
tmpfs /tmp tmpfs nodev,nosuid 0 0
/dev/sda1 / ext4 defaults,noatime 0 1
/dev/sda2 none swap defaults 0 0
/dev/sda3 /home ext4 defaults,noatime 0 2ext2, ext3, ext4, reiserfs, xfs, jfs, smbfs, iso9660, vfat, ntfs, swap 及 auto。 设置成auto类型,mount 命令会猜测使用的文件系统类型,对 CDROM 和 DVD 等移动设备是非常有用的。auto - 在启动时或键入了 mount -a 命令时自动挂载。ro - 以只读模式挂载文件系统。rw - 以读写模式挂载文件系统。owner - 允许设备所有者挂载.sync - I/O 同步进行。async - I/O 异步进行。dev - 解析文件系统上的块特殊设备。nodev - 不解析文件系统上的块特殊设备。suid - 允许 suid 操作和设定 sgid 位。这一参数通常用于一些特殊任务,使一般用户运行程序时临时提升权限。defaults - 使用文件系统的默认挂载参数,例如 ext4 的默认参数为:rw, suid, dev, exec, auto, nouser, async.3、编写规范
在 /etc/fstab配置文件中你可以以三种不同的方法表示文件系统:内核名称(见案例介绍)、UUID 或者 label。使用 UUID 或是 label 的好处在于它们与磁盘顺序无关。如果你在 BIOS 中改变了你的存储设备顺序,或是重新拔插了存储设备,或是因为一些 BIOS 可能会随机地改变存储设备的顺序,那么用 UUID 或是 label 来表示将更有效。
UUID编写方式:

label编写方式:

hda一般是指IDE接口的硬盘,hda指第一块硬盘,hdb指第二块硬盘,等等;
sda一般是指SATA接口的硬盘,sda指第一块硬盘,sdb指第二块硬盘,等等。
一般来说,vda,vdb为虚拟磁盘;真机中第一块磁盘为sda,第二块为sdb;
实践机器:88那台测试机
针对/vdb盘进行分区,分别挂载到不同的/data目录,最终结果如下:
分区后:

过程中遇到的问题:
1、fdisk最后一步需要输入:wq,输入lsblk是看不出效果的,需要重启虚拟机:reboot;
2、一开始/data目录直接挂载在硬盘/vdb上,所以需要先卸载/data, 但是在卸载/data的时候遇到个问题,/data正在被占用,无法卸载,报错如下:意思是/data正在被占用,因此不能卸载,此时我们就需要将正在占用该磁盘数据的进程全都kill掉,就可以正常解除挂载了。最终通过fuser命令解决。
解决方式参考:umount target is busy挂载盘无法卸载的解决办法 - 灰信网(软件开发博客聚合)
卸载报错:

未分区前:
3、挂载前一定要mkfs格式化文件系统,否则会报错

参考:https://blog.csdn.net/qq_31319235/article/details/118784703
rpartition和partition有什么区别?我已经阅读了文档,但我认为它们是一样的。只是那些出现在后来的ruby版本中吗? 最佳答案 以下示例将有助于识别差异:"abccba".partition("b")#=>["a","b","ccba"]"abccba".rpartition("b")#=>["abcc","b","a"]所以区别在于rpartition搜索最右边的匹配项,而不是最左边的匹配项。 关于Rubyrpartition与分区?,我们在StackOverflow
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
文章目录一基础定义二创建逻辑卷2-1准备物理设备2-2创建物理卷2-3创建卷组2-4创建逻辑卷2-5创建文件系统并挂载文件三扩展卷组和缩减卷组3-1准备物理设备3-2创建物理卷3-3扩展卷组3-4查看卷组的详细信息以验证3-5缩减卷组四扩展逻辑卷4-1检查卷组是否有可用的空间4-2扩展逻辑卷4-3扩展文件系统五删除逻辑卷5-1备份数据5-2卸载文件系统5-3删除逻辑卷5-4删除卷组5-5删除物理卷六LVM逻辑卷缩容6-1缩容注意事项6-2标准缩容步骤一基础定义LVM,LogicalVolumeManger,逻辑卷管理,Linux磁盘分区管理的一种机制,建立在硬盘和分区上的一个逻辑层,提高磁盘分
我有以下python函数来递归查找集合的所有分区:defpartitions(set_):ifnotset_:yield[]returnforiinxrange(2**len(set_)/2):parts=[set(),set()]foriteminset_:parts[i&1].add(item)i>>=1forbinpartitions(parts[1]):yield[parts[0]]+bforpinpartitions(["a","b","c","d"]):print(p)有人可以帮我把它翻译成ruby吗?这是我目前所拥有的:defpartitions(set)ifnots
谁能告诉我如何在ruby中获取可用磁盘驱动器的列表?我正在创建一个打开的文件对话并且需要知道!提前致谢,嗯。 最佳答案 Brian给出的文章正确地陈述了以下代码:require'win32ole'file_system=WIN32OLE.new("Scripting.FileSystemObject")drives=file_system.Drivesdrives.eachdo|drive|puts"Availablespace:#{drive.AvailableSpace}"puts"Driveletter:#{drive.D
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺
VMware虚拟机与本地主机进行磁盘共享前提虚拟机版本为Windows10(专业版,不是可能有问题)本地主机为家庭版或学生版(此版本会有问题,但有替代方式)最好是专业版VMware操作1.关闭防火墙,全部关闭。2.打开电脑属性3.点击共享-》高级共享-》权限4.如果没有everyone,就添加权限选择完全控制,然后应用确定。5.打开cmd输入lusrmgr.msc(只有专业版可以打开)如果不是专业版,可以跳过这一步。点击用户-》administrator密码要复杂密码,否则不行。推荐admaiN@1234类型的密码。设置完密码,点击属性,将禁用解开。6.如果虚拟机的windows不是专业版,可
我正在寻找一种通过在ruby中使用索引来对数组进行分区的优雅方法例如:["a","b",3,"c",5].partition_with_index(2)=>[["a","b",3],["c",5]]到目前为止,我能想到的最好的方法是使用下面的["a","b",3,"c",5].partition.each_with_index{|val,index|index[["a","b",3],["c",5]]还有其他优雅的方法可以实现吗?谢谢! 最佳答案 你可以这样做:["a","b",3,"c",5].partition.with_i
我有这段代码,它将一个zip文件写入磁盘,读回,上传到s3,然后删除文件:compressed_file=some_temp_pathZip::ZipOutputStream.open(compressed_file)do|zos|some_file_list.eachdo|file|zos.put_next_entry(file.some_title)zos.printIO.read(file.path)endend#Writezipfiles3=Aws::S3.new(S3_KEY,S3_SECRET)bucket=Aws::S3::Bucket.create(s3,S3_BUCK
