首先声明,本文参照(7条消息) 【中文】【吴恩达课后编程作业】Course 1 - 神经网络和深度学习 - 第三周作业_何宽的博客-CSDN博客_吴恩达课后编程作业(https://blog.csdn.net/u013733326/article/details/79702148)
本文所使用的资料已上传到百度网盘**【点击下载】**,提取码:qifu,请在开始之前下载好所需资料。当然还是需要将数据集放置在与代码同一层次。
加上自己的理解,方便自己以后的学习
我们需要准备一些软件包:
import numpy as np
import matplotlib.pyplot as plt
from testCases import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
np.random.seed(1) #设置一个固定的随机种子,以保证接下来的步骤中我们的结果是一致的(所取的随机值是一样的)。我们来看看我们将要使用的数据集, 下面的代码会将一个花的图案的2类数据集加载到变量X和Y中
X, Y = load_planar_dataset()plt.scatter(X[0, :], X[1, :], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral) #绘制散点图
plt.show()
数据看起来像一朵红色(y = 0)和一些蓝色(y = 1)的数据点的花朵的图案。 我们的目标是建立一个模型来适应这些数据。现在,我们已经有了以下的东西:
X:一个numpy的矩阵,包含了这些数据点的数值
Y:一个numpy的向量,对应着的是X的标签【0 | 1】(红色:0 , 蓝色 :1)
我们继续来仔细地看数据:
shape_X = X.shape
shape_Y = Y.shape
m = Y.shape[1] # 训练集里面的数量
print ("X的维度为: " + str(shape_X))
print ("Y的维度为: " + str(shape_Y))
print ("数据集里面的数据有:" + str(m) + " 个")X的维度为: (2, 400) Y的维度为: (1, 400) 数据集里面的数据有:400 个
在构建完整的神经网络之前,先让我们看看逻辑回归在这个问题上的表现如何,我们可以使用sklearn的内置函数来做到这一点, 运行下面的代码来训练数据集上的逻辑回归分类器。
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X.T,Y.T)会打印出这样一段字:
E:\anaconda\lib\site-packages\sklearn\utils\validation.py:993: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel(). y = column_or_1d(y, warn=True)
#原型plot_decision_boundary(modle,x,y)对x进行预测,大于0.5取红色,小于0.5取蓝色
plot_decision_boundary(lambda x: clf.predict(x), X, Y) #绘制决策边界
plt.title("Logistic Regression") #图标题
LR_predictions = clf.predict(X.T) #预测结果
#Y的取值只有(0,1)所以这里要用“+”
print ("逻辑回归的准确性: %d " % float((np.dot(Y, LR_predictions) +
np.dot(1 - Y,1 - LR_predictions)) / float(Y.size) * 100) +
"% " + "(正确标记的数据点所占的百分比)")逻辑回归的准确性: 47 % (正确标记的数据点所占的百分比)

准确性只有47%的原因是数据集不是线性可分的,所以逻辑回归表现不佳,现在我们正式开始构建神经网络。(跟没分类一样,50%是最不好的分类情况)
隐藏层我们采取的是tanh函数,其导数为1-(tanh)^2

对于x(i)而言
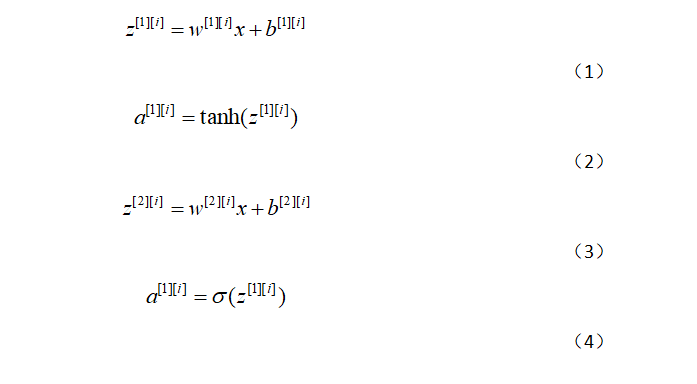
给出所有示例的预测结果,可以按如下方式计算成本J:

构建神经网络的一般方法是:
我们要它们合并到一个nn_model() 函数中,当我们构建好了nn_model()并学习了正确的参数,我们就可以预测新的数据。
def layer_sizes(X , Y):
"""
参数:
X - 输入数据集,维度为(输入的数量,训练/测试的数量)
Y - 标签,维度为(输出的数量,训练/测试数量)
返回:
n_x - 输入层的数量
n_h - 隐藏层的数量
n_y - 输出层的数量
"""
n_x = X.shape[0] #输入层
n_h = 4 #,隐藏层,硬编码为4
n_y = Y.shape[0] #输出层
return (n_x,n_h,n_y)接下来,我们测试一下
#测试layer_sizes
print("=========================测试layer_sizes=========================")
X_asses , Y_asses = layer_sizes_test_case()
(n_x,n_h,n_y) = layer_sizes(X_asses,Y_asses)
print("输入层的节点数量为: n_x = " + str(n_x))
print("隐藏层的节点数量为: n_h = " + str(n_h))
print("输出层的节点数量为: n_y = " + str(n_y))=========================测试layer_sizes========================= 输入层的节点数量为: n_x = 5 隐藏层的节点数量为: n_h = 4 输出层的节点数量为: n_y = 2
初始化模型的参数
在这里,我们要实现函数initialize_parameters()。我们要确保我们的参数大小合适,如果需要的话,请参考上面的神经网络图。
我们将会用随机值初始化权重矩阵。
将偏向量初始化为零。
这里做一下解释,为什么要乘以0.01
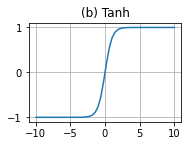
如图,乘以的数越大,增长的速率越慢,因此我们采用0.01.
我们继续走
def initialize_parameters( n_x , n_h ,n_y):
"""
参数:
n_x - 输入层节点的数量
n_h - 隐藏层节点的数量
n_y - 输出层节点的数量
返回:
parameters - 包含参数的字典:
W1 - 权重矩阵,维度为(n_h,n_x)
b1 - 偏向量,维度为(n_h,1)
W2 - 权重矩阵,维度为(n_y,n_h)
b2 - 偏向量,维度为(n_y,1)
"""
np.random.seed(2) #指定一个随机种子,以便你的输出与我们的一样。
W1 = np.random.randn(n_h,n_x) * 0.01
b1 = np.zeros(shape=(n_h, 1))
W2 = np.random.randn(n_y,n_h) * 0.01
b2 = np.zeros(shape=(n_y, 1))
#使用断言确保我的数据格式是正确的
assert(W1.shape == ( n_h , n_x ))
assert(b1.shape == ( n_h , 1 ))
assert(W2.shape == ( n_y , n_h ))
assert(b2.shape == ( n_y , 1 ))
parameters = {"W1" : W1,
"b1" : b1,
"W2" : W2,
"b2" : b2 }
return parameters我们来测试一下
#测试initialize_parameters
print("=========================测试initialize_parameters=========================")
n_x , n_h , n_y = initialize_parameters_test_case()
parameters = initialize_parameters(n_x , n_h , n_y)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))=========================测试initialize_parameters========================= W1 = [[-0.00416758 -0.00056267] [-0.02136196 0.01640271] [-0.01793436 -0.00841747] [ 0.00502881 -0.01245288]] b1 = [[0.] [0.] [0.] [0.]] W2 = [[-0.01057952 -0.00909008 0.00551454 0.02292208]] b2 = [[0.]]
我们现在要实现前向传播函数forward_propagation()。
我们可以使用sigmoid()函数,也可以使用np.tanh()函数。
步骤如下:
def forward_propagation( X , parameters ):
"""
参数:
X - 维度为(n_x,m)的输入数据。
parameters - 初始化函数(initialize_parameters)的输出
返回:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型变量
"""
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
#前向传播计算A2
Z1 = np.dot(W1 , X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2 , A1) + b2
A2 = sigmoid(Z2)
#使用断言确保我的数据格式是正确的
assert(A2.shape == (1,X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return (A2, cache)我们测试一下:
#测试forward_propagation
print("=========================测试forward_propagation=========================")
X_assess, parameters = forward_propagation_test_case()
A2, cache = forward_propagation(X_assess, parameters)
print(np.mean(cache["Z1"]), np.mean(cache["A1"]), np.mean(cache["Z2"]), np.mean(cache["A2"]))=========================测试forward_propagation========================= -0.0004997557777419902 -0.000496963353231779 0.00043818745095914653 0.500109546852431
def compute_cost(A2,Y,parameters):
"""
计算方程(5)中给出的交叉熵成本,
参数:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
Y - "True"标签向量,维度为(1,数量)
parameters - 一个包含W1,B1,W2和B2的字典类型的变量
返回:
成本 - 交叉熵成本给出方程(13)
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
#计算成本
logprobs = logprobs = np.multiply(np.log(A2), Y) + np.multiply((1 - Y), np.log(1 - A2))
cost = - np.sum(logprobs) / m
cost = float(np.squeeze(cost))
assert(isinstance(cost,float))
return cost测试一下我们的成本函数:
#测试compute_cost
print("=========================测试compute_cost=========================")
A2 , Y_assess , parameters = compute_cost_test_case()
print("cost = " + str(compute_cost(A2,Y_assess,parameters)))=========================测试compute_cost========================= cost = 0.6929198937761266
使用正向传播期间计算的cache,现在可以利用它实现反向传播。
现在我们要开始实现函数backward_propagation()。
向后传播
这里的公式还是比较复杂的,最好是自己推导一下,方便记忆
def backward_propagation(parameters,cache,X,Y):
"""
使用上述说明搭建反向传播函数。
参数:
parameters - 包含我们的参数的一个字典类型的变量。
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型的变量。
X - 输入数据,维度为(2,数量)
Y - “True”标签,维度为(1,数量)
返回:
grads - 包含W和b的导数一个字典类型的变量。
"""
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
dZ2= A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2 }
return grads测试一下反向传播函数:
#测试backward_propagation
print("=========================测试backward_propagation=========================")
parameters, cache, X_assess, Y_assess = backward_propagation_test_case()
grads = backward_propagation(parameters, cache, X_assess, Y_assess)
print ("dW1 = "+ str(grads["dW1"]))
print ("db1 = "+ str(grads["db1"]))
print ("dW2 = "+ str(grads["dW2"]))
print ("db2 = "+ str(grads["db2"]))=========================测试backward_propagation========================= dW1 = [[ 0.01018708 -0.00708701] [ 0.00873447 -0.0060768 ] [-0.00530847 0.00369379] [-0.02206365 0.01535126]] db1 = [[-0.00069728] [-0.00060606] [ 0.000364 ] [ 0.00151207]] dW2 = [[ 0.00363613 0.03153604 0.01162914 -0.01318316]] db2 = [[0.06589489]]
def update_parameters(parameters,grads,learning_rate=1.2):
"""
使用上面给出的梯度下降更新规则更新参数
参数:
parameters - 包含参数的字典类型的变量。
grads - 包含导数值的字典类型的变量。
learning_rate - 学习速率
返回:
parameters - 包含更新参数的字典类型的变量。
"""
W1,W2 = parameters["W1"],parameters["W2"]
b1,b2 = parameters["b1"],parameters["b2"]
dW1,dW2 = grads["dW1"],grads["dW2"]
db1,db2 = grads["db1"],grads["db2"]
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters我们测试一下update_parameters():
#测试update_parameters
print("=========================测试update_parameters=========================")
parameters, grads = update_parameters_test_case()
parameters = update_parameters(parameters, grads)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))=========================测试update_parameters========================= W1 = [[-0.00643025 0.01936718] [-0.02410458 0.03978052] [-0.01653973 -0.02096177] [ 0.01046864 -0.05990141]] b1 = [[-1.02420756e-06] [ 1.27373948e-05] [ 8.32996807e-07] [-3.20136836e-06]] W2 = [[-0.01041081 -0.04463285 0.01758031 0.04747113]] b2 = [[0.00010457]]
我们现在把上面的东西整合到nn_model()中,神经网络模型必须以正确的顺序使用先前的功能。
def nn_model(X,Y,n_h,num_iterations,print_cost=False):
"""
参数:
X - 数据集,维度为(2,示例数)
Y - 标签,维度为(1,示例数)
n_h - 隐藏层的数量
num_iterations - 梯度下降循环中的迭代次数
print_cost - 如果为True,则每1000次迭代打印一次成本数值
返回:
parameters - 模型学习的参数,它们可以用来进行预测。
"""
np.random.seed(3) #指定随机种子
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
parameters = initialize_parameters(n_x,n_h,n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
for i in range(num_iterations):
A2 , cache = forward_propagation(X,parameters)
cost = compute_cost(A2,Y,parameters)
grads = backward_propagation(parameters,cache,X,Y)
parameters = update_parameters(parameters,grads,learning_rate = 0.5)
if print_cost:
if i%1000 == 0:
print("第 ",i," 次循环,成本为:"+str(cost))
return parameters老规矩,测试nn_model():
#测试nn_model
print("=========================测试nn_model=========================")
X_assess, Y_assess = nn_model_test_case()
parameters = nn_model(X_assess, Y_assess, 4, num_iterations=10000, print_cost=False)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))=========================测试nn_model=========================
W1 = [[-3.89167767 4.77541602] [-6.77960338 1.20272585] [-3.88338966 4.78028666] [ 6.77958203 -1.20272574]] b1 = [[ 2.11530892] [ 3.41221357] [ 2.11585732] [-3.41221322]] W2 = [[-2512.9093032 -2502.70799785 -2512.01655969 2502.65264416]] b2 = [[-22.29071761]]
构建predict()来使用模型进行预测, 使用向前传播来预测结果。
def predict(parameters,X):
"""
使用学习的参数,为X中的每个示例预测一个类
参数:
parameters - 包含参数的字典类型的变量。
X - 输入数据(n_x,m)
返回
predictions - 我们模型预测的向量(红色:0 /蓝色:1)
"""
A2 , cache = forward_propagation(X,parameters)
predictions = np.round(A2)
return predictions测试一下predict:
#测试predict
print("=========================测试predict=========================")
parameters, X_assess = predict_test_case()
predictions = predict(parameters, X_assess)
print("预测的平均值 = " + str(np.mean(predictions)))=========================测试predict========================= 预测的平均值 = 0.6666666666666666
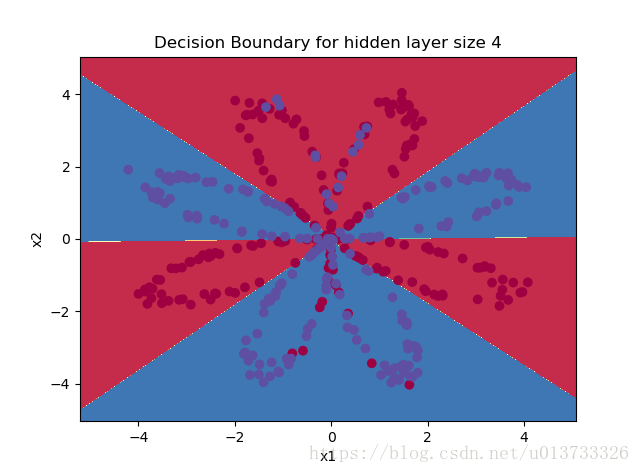
parameters = nn_model(X, Y, n_h = 4, num_iterations=10000, print_cost=True)
#绘制边界
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
predictions = predict(parameters, X)
print ('准确率: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')第 0 次循环,成本为:0.6930480201239823 第 1000 次循环,成本为:0.3098018601352803 第 2000 次循环,成本为:0.2924326333792646 第 3000 次循环,成本为:0.2833492852647412 第 4000 次循环,成本为:0.27678077562979253 第 5000 次循环,成本为:0.26347155088593144 第 6000 次循环,成本为:0.24204413129940763 第 7000 次循环,成本为:0.23552486626608762 第 8000 次循环,成本为:0.23140964509854278 第 9000 次循环,成本为:0.22846408048352365 准确率: 90%
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG