目录
分治法是一种将复杂问题分解为若干个相同或相似的子问题,然后递归地求解子问题,最后将子问题的解合并为原问题的解的算法设计思想。减治法是一种将复杂问题简化为规模较小的同类问题,然后递归地求解简化后的问题,最后得到原问题的解的算法设计思想。分治法和减治法都是利用递归技术实现的算法。
排序是计算机科学中最基本也最重要的问题之一,它的目的是将一组无序的数据按照某种规则排列成有序的数据。排序中有许多经典的分治法和减治法的应用,例如快速排序、归并排序、堆排序等。这些排序算法都有各自的优缺点,需要根据不同的场景和需求选择合适的算法。
本实验旨在通过排序中分治法的程序设计,掌握分治法和减治法在排序问题上的应用,了解不同排序算法的原理、步骤、性能和特点,能够使用高级语言实现和测试这些排序算法,并能够分析和比较它们之间的异同。
本文中使用的语言是C语言,使用的ide是devc++
给出一个初始序列,分别用归并法和快速排序两种分治法将所给序列变为有序序列,输出结果,输出是要有文字说明。请任选一种语言编写程序实现上述算法,并分析其算法复杂度
(1)掌握归并排序和快速排序的划分方法;
(2)掌握归并排序和快速排序的具体分治策略;
(3)在掌握的基础上编程两种排序方法的实现过程。
1、写出伪代码进行算法描述
2、使用c++编写程序完成上述算法
3、使用测试用例对算法进行测试
4、对算法的复杂度进行分析
归并排序和快速排序都是分治算法的经典代表。两种算法都通过递归来实现,过程非常相似。归并排序非常稳定,但不是原地排序;快速排序,是原地排序算法,应用得更加广泛。
归并排序:将序列分成两个子序列,对每个子序列进行递归排序,然后将两个排好序的子序列合并成一个有序序列。
快速排序:选取一个基准元素,将小于等于基准元素的元素放到左边,大于基准元素的元素放到右边,然后对左右两个子序列递归进行快速排序。
归并排序:
merge_sort(arr, p, r)
if p < r
q = (p + r) / 2
merge_sort(arr, p, q)
merge_sort(arr, q+1, r)
merge(arr, p, q, r)
merge(arr, p, q, r)
n1 = q - p + 1
n2 = r - q
let L[1..n1+1] and R[1..n2+1] be new arrays
for i = 1 to n1
L[i] = arr[p + i - 1]
for j = 1 to n2
R[j] = arr[q + j]
L[n1+1] = infinity
R[n2+1] = infinity
i = 1
j = 1
for k = p to r
if L[i] <= R[j]
arr[k] = L[i]
i = i + 1
else arr[k] = R[j]
j = j + 1
快速排序:
quick_sort(arr, low, high)
if low < high
pivot_location = partition(arr, low, high)
quick_sort(arr, low, pivot_location - 1)
quick_sort(arr, pivot_location + 1, high)
partition(arr, low, high)
pivot_item = arr[low]
left_mark = low + 1
right_mark = high
done = False
while not done
while left_mark <= right_mark and arr[left_mark] <= pivot_item
left_mark += 1
while right_mark >= left_mark and arr[right_mark] >= pivot_item
right_mark -= 1
if right_mark < left_mark
done = True
else swap arr[left_mark] with arr[right_mark]
swap arr[low] with arr[right_mark]
return right_mark#include <iostream>
using namespace std;
void merge(int arr[], int l, int m, int r) {
int i, j, k;
int n1 = m - l + 1;
int n2 = r - m;
int L[n1], R[n2];
for (i = 0; i < n1; i++)
L[i] = arr[l + i];
for (j = 0; j < n2; j++)
R[j] = arr[m + 1 + j];
i = 0;
j = 0;
k = l;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
}
else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
void mergeSort(int arr[], int l, int r) {
if (l >= r) {
return;
}
int m = l + (r - l) / 2;
mergeSort(arr, l, m);
mergeSort(arr, m + 1, r);
merge(arr, l, m, r);
}
int partition(int arr[], int low, int high) {
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j <= high - 1; j++) {
if (arr[j] < pivot) {
i++;
swap(arr[i], arr[j]);
}
}
swap(arr[i + 1], arr[high]);
return (i + 1);
}
void quickSort(int arr[], int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
int main() {
// 归并排序
cout << "归并排序" << endl;
cout << "请输入待排序序列长度:";
int n;
cin >> n;
cout << "请输入待排序序列:";
int a[n];
for (int i = 0; i < n; i++) {
cin >> a[i];
}
mergeSort(a, 0, n - 1);
cout << "排序后的序列为:";
for (int i = 0; i < n; i++) {
cout << a[i] << " ";
}
// 快速排序
cout << endl << endl << "快速排序" << endl;
cout << "请输入待排序序列长度:";
cin >> n;
cout << "请输入待排序序列:";
for (int i = 0; i < n; i++) {
cin >> a[i];
}
quickSort(a, 0, n - 1);
cout << "排序后的序列为:";
for (int i = 0; i < n; i++) {
cout << a[i] << " ";
}
return 0;
}上述代码实现使用C语言实现了归并排序和快速排序两种分治算法
归并排序是一种分治算法,它将待排序的序列分成两个子序列,对每个子序列进行递归排序,然后将两个排好序的子序列合并成一个有序序列。具体来说,mergeSort函数实现了归并排序。mergeSort函数的参数包括待排序数组arr、数组左端点l和右端点r。如果l>=r,则返回;否则,计算中间点m=(l+r)/2,对左半部分arr[l…m]进行递归排序,对右半部分arr[m+1…r]进行递归排序,最后将左右两个排好序的子序列合并成一个有序序列。
快速排序也是一种分治算法,它选取一个基准元素,将小于等于基准元素的元素放到左边,大于基准元素的元素放到右边,然后对左右两个子序列递归进行快速排序。具体来说,partition函数实现了快速排序。partition函数的参数包括待排序数组arr、数组左端点low和右端点high。首先选取基准元素pivot=arr[high],然后从low到high-1遍历数组arr。如果arr[j]<pivot,则将arr[i]和arr[j]交换,并将i加1。最后将arr[i+1]和arr[high]交换,并返回i+1
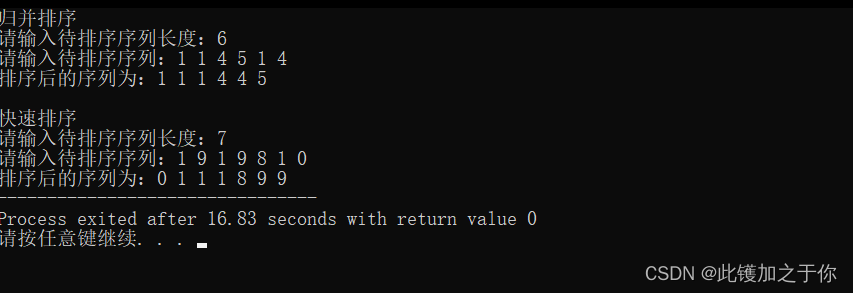
当n趋近于无穷大时,归并排序和快速排序的时间复杂度都是O(nlogn)。归并排序的时间复杂度始终都是O(nlogn),而快速排序虽然最坏情况下时间复杂度为O(n^2),但平均情况下时间复杂度为O(nlogn),最坏情况发生的概率也比较小,因此应用得更加广泛
这篇文章介绍了分治法和减治法的算法设计思想,以及它们在排序问题中的应用。文章提到了许多经典的分治法和减治法的应用,例如快速排序、归并排序、堆排序等。这些排序算法都有各自的优缺点,需要根据不同的场景和需求选择合适的算法。文章还介绍了本实验的目的和内容,即通过排序中分治法的程序设计,掌握分治法和减治法在排序问题上的应用,了解不同排序算法的原理、步骤、性能和特点,能够使用高级语言实现和测试这些排序算法,并能够分析和比较它们之间的异同。
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
我在RailsController操作中有下面的代码序列。在IF之前,params包含请求参数,正如预期的那样。在它之后,params为零。谁能解释一下这里发生了什么?iffalseparams={:user=>{:name=>"user",:comment=>'comment'}}end谢谢。 最佳答案 params其中包含请求参数实际上是一个方法调用,它返回包含参数的散列。你的params=行正在分配给一个名为params的局部变量.iffalse之后block,Ruby已经看到了本地params变量,所以当你引用params时
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我有一个对象如下:[{:id=>2,:fname=>"Ron",:lname=>"XXXXX",:photo=>"XXX"},{:id=>3,:fname=>"Dain",:lname=>"XXXX",:photo=>"XXXXXXX"},{:id=>1,:fname=>"Bob",:lname=>"XXXXXX",:photo=>"XXXX"}]我想按fname排序,不区分大小写,所以它会导致编号:1,3,2我该如何排序?我正在尝试:@people.sort!{|x,y|y[:fname]x[:fname]}但这没有任何效果。 最佳答案
有人可以告诉我如何根据自定义字符串对嵌套数组进行排序吗?比如有没有办法排序:[['Red','Blue'],['Green','Orange'],['Purple','Yellow']]“橙色”、“黄色”,然后是“蓝色”?最终结果如下所示:[['Green','Orange'],['Purple','Yellow'],['Red','Blue']]它不是按字母顺序排序的。我很想知道我是否可以定义要排序的值以实现上述目标。 最佳答案 sort_by对于这种排序总是非常方便:a=[['Red','Blue'],['Green','Ora
我有以下现有的Dog对象数组,它们按age属性排序:classDogattr_accessor:agedefinitialize(age)@age=ageendenddogs=[Dog.new(1),Dog.new(4),Dog.new(10)]我现在想插入一条新的狗记录,并将它放在数组中的正确位置。假设我想插入这个对象:another_dog=Dog.new(8)我想把它插入到数组中,让它成为数组中的第三项。这是一个人为的示例,旨在演示我特别想如何将一个项目插入到现有的有序数组中。我意识到我可以创建一个全新的数组并重新对所有对象进行排序,但这不是我的目标。谢谢!