本篇关键词:内核重定位、MMU、SVC栈、热启动、内核映射表
内核汇编相关篇为:
这应该是系列篇最难写的一篇,全是汇编代码,需大量的底层知识,涉及协处理器,内核镜像重定位,创建内核映射表,初始化 CPU 模式栈,热启动,到最后熟悉的 main() 。
在链接文件 liteos.ld 中可知内核的入口地址为 ENTRY(reset_vector) , 分别出现在reset_vector_mp.S (多核启动) 和 reset_vector_up.S(单核启动),系列篇研究多核启动的情况。代码可结合 (协处理器篇) 看更容易懂。
reset_vector: //鸿蒙开机代码
/* clear register TPIDRPRW */
mov r0, #0 //r0 = 0
mcr p15, 0, r0, c13, c0, 4 //复位线程标识符寄存器TPIDRPRW , 不复位将导致系统不能启动
/* do some early cpu setup: i/d cache disable, mmu disabled */
mrc p15, 0, r0, c1, c0, 0 //System Control Register-SCTLR | 读取系统控制寄存器内容
bic r0, #(1<<12) //禁用指令缓存功能
bic r0, #(1<<2 | 1<<0) //禁用数据和TLB的缓存功能(bit2) | mmu功能(bit0)
mcr p15, 0, r0, c1, c0, 0 //写系统控制寄存器
/* enable fpu+neon 一些系统寄存器的操作
| 使能浮点运算(floating point unit)和 NEON就是一种基于SIMD思想的ARM技术,相比于ARMv6或之前的架构,
NEON结合了64-bit和128-bit的SIMD指令集,提供128-bit宽的向量运算(vector operations)*/
#ifndef LOSCFG_TEE_ENABLE //Trusted Execution Environment 可信执行环境
MRC p15, 0, r0, c1, c1, 2 //非安全模式访问寄存器 (Non-Secure Access Control Register - NSACR)
ORR r0, r0, #0xC00 //使能安全和非安全访问协处理器10和11(Coprocessor 10和11)
BIC r0, r0, #0xC000 //设置bit15为0,不会影响修改CPACR.ASEDIS寄存器位(控制Advanced SIMD功能)| bit14 reserved
MCR p15, 0, r0, c1, c1, 2
LDR r0, =(0xF << 20) //允许在EL0和EL1下,访问协处理器10和11(控制Floating-point和Advanced SIMD特性)
MCR p15, 0, r0, c1, c0, 2
ISB
#endif
MOV r3, #0x40000000 //EN, bit[30] 设置FPEXC的EN位来使能FPU
VMSR FPEXC, r3 //浮点异常控制寄存器 (Floating-Point Exception Control register | B4.1.57)
/* r11: delta of physical address and virtual address | 计算虚拟地址和物理地址之间的差值,目的是为了建立映射关系表 */
adr r11, pa_va_offset //获取pa_va_offset变量物理地址,由于这时候mmu已经被关闭,所以这个值就表示pa_va_offset变量的物理地址。
/*adr 是一条小范围的地址读取伪指令,它将基于PC的相对偏移的地址值读到目标寄存器中。
*编译源程序时,汇编器首先计算当前PC值(当前指令位置)到exper的距离,然后用一条ADD或者SUB指令替换这条伪指令,
*例如:ADD register,PC,#offset_to_exper 注意,标号exper与指令必须在同一代码段
*/
ldr r0, [r11] //r0 = *r11 获取pa_va_offset变量虚拟地址
sub r11, r11, r0 //物理地址-虚拟地址 = 映射偏移量 放入r11
mrc p15, 0, r12, c0, c0, 5 /* Multiprocessor Affinity Register-MPIDR */
and r12, r12, #MPIDR_CPUID_MASK //掩码过滤
cmp r12, #0 //主控核0判断
bne secondary_cpu_init //初始化CPU次核
/*
* adr是小范围的地址读取伪指令,它将基于PC寄存器相对偏移的地址值读取到寄存器中,
* 例如: 0x00000004 : adr r4, __exception_handlers
* 则此时PC寄存器的值为: 0x00000004 + 8(在三级流水线时,PC和执行地址相差8),
* adr指令和标识__exception_handlers的地址相对固定,二者偏移量若为offset,
* 最后r4 = (0x00000004 + 8) + offset
*/
/* if we need to relocate to proper location or not | 如果需要重新安装到合适的位置*/
adr r4, __exception_handlers /* r4: base of load address | 加载基址*/
ldr r5, =SYS_MEM_BASE /* r5: base of physical address | 物理基址*/
subs r12, r4, r5 /* r12: delta of load address and physical address | 二者偏移量*/
beq reloc_img_to_bottom_done /* if we load image at the bottom of physical address | 不相等就需要重定位 */
/* we need to relocate image at the bottom of physical address | 需要知道拷贝的大小*/
ldr r7, =__exception_handlers /* r7: base of linked address (or vm address) | 链接地址基地址*/
ldr r6, =__bss_start /* r6: end of linked address (or vm address),由于目前阶段有用的数据是中断向量表+代码段+只读数据段+数据段,
所以只需复制[__exception_handlers,__bss_start]这段数据到内存基址处 */
sub r6, r7 /* r6: delta of linked address (or vm address) | 内核镜像大小 */
add r6, r4 /* r6: end of load address | 说明需拷贝[ r4,r4+r6 ] 区间内容到 [ r5,r5+r6 ]*/
reloc_img_to_bottom_loop://重定位镜像到内核物理内存基地址,将内核从加载地址拷贝到内存基址处
ldr r7, [r4], #4 // 类似C语言 *r5 = *r4 , r4++ , r5++
str r7, [r5], #4 // #4 代表32位的指令长度,此时在拷贝内核代码区内容
cmp r4, r6 /* 拷贝完成条件. r4++ 直到等于r6 (加载结束地址) 完成拷贝动作 */
bne reloc_img_to_bottom_loop
sub pc, r12 /* 重新校准pc寄存器, 无缝跳到了拷贝后的指令地址处执行 r12是重定位镜像前内核加载基地址和内核物理内存基地址的差值 */
nop // 注意执行完成sub pc, r12后,新的PC寄存器也指向了 nop ,nop是伪汇编指令,等同于 mov r0 r0 通常用于控制时序的目的,强制内存对齐,防止流水线灾难,占据分支指令延迟
sub r11, r11, r12 /* r11: eventual address offset | 最终地址映射偏移量, 用于构建MMU页表 */
//内核总大小 __bss_start - __exception_handlers
reloc_img_to_bottom_done:
#ifdef LOSCFG_KERNEL_MMU
ldr r4, =g_firstPageTable /* r4: physical address of translation table and clear it
内核页表是用数组g_firstPageTable存储 见于los_arch_mmu.c */
add r4, r4, r11 //计算g_firstPageTable页表物理地址
mov r0, r4 //因为默认r0 将作为memset_optimized的第一个参数
mov r1, #0 //第二个参数,清0
mov r2, #MMU_DESCRIPTOR_L1_SMALL_ENTRY_NUMBERS //第三个参数是L1表的长度
bl memset_optimized /* optimized memset since r0 is 64-byte aligned | 将内核页表空间清零*/
ldr r5, =g_archMmuInitMapping //记录映射关系表
add r5, r5, r11 //获取g_archMmuInitMapping的物理地址
init_mmu_loop: //初始化内核页表
ldmia r5!, {r6-r10} /* r6 = phys, r7 = virt, r8 = size, r9 = mmu_flags, r10 = name | 传参: 物理地址、虚拟地址、映射大小、映射属性、名称*/
cmp r8, 0 /* if size = 0, the mmu init done | 完成条件 */
beq init_mmu_done //标志寄存器中Z标志位等于零时跳转到 init_mmu_done处执行
bl page_table_build //创建页表
b init_mmu_loop //循环继续
init_mmu_done:
orr r8, r4, #MMU_TTBRx_FLAGS /* r8 = r4 and set cacheable attributes on translation walk | 设置缓存*/
ldr r4, =g_mmuJumpPageTable /* r4: jump pagetable vaddr | 页表虚拟地址*/
add r4, r4, r11
ldr r4, [r4]
add r4, r4, r11 /* r4: jump pagetable paddr | 页表物理地址*/
/* build 1M section mapping, in order to jump va during turing on mmu:pa == pa, va == pa */
/* 从当前PC开始建立1MB空间的段映射,分别建立物理地址和虚拟地址方式的段映射页表项
* 内核临时页表在系统 使能mmu -> 切换到虚拟地址运行 这段时间使用
*/
mov r6, pc
mov r7, r6 /* r7: pa (MB aligned)*/
lsr r6, r6, #20 /* r6: pa l1 index */
ldr r10, =MMU_DESCRIPTOR_KERNEL_L1_PTE_FLAGS
add r12, r10, r6, lsl #20 /* r12: pa |flags */
str r12, [r4, r7, lsr #(20 - 2)] /* jumpTable[paIndex] = pt entry */
rsb r7, r11, r6, lsl #20 /* r7: va */
str r12, [r4, r7, lsr #(20 - 2)] /* jumpTable[vaIndex] = pt entry */
bl mmu_setup /* set up the mmu | 内核映射表已经创建好了,此时可以启动MMU工作了*/
#endif
/* clear out the interrupt and exception stack and set magic num to check the overflow
|exc_stack|地址高位
|svc_stack|地址低位
清除中断和异常堆栈并设置magic num检查溢出 */
ldr r0, =__svc_stack //stack_init的第一个参数 __svc_stack表示栈顶
ldr r1, =__exc_stack_top //stack_init的第二个参数 __exc_stack_top表示栈底, 这里会有点绕, top表高地址位
bl stack_init //初始化各个cpu不同模式下的栈空间
//设置各个栈顶魔法数字
STACK_MAGIC_SET __svc_stack, #OS_EXC_SVC_STACK_SIZE, OS_STACK_MAGIC_WORD //中断栈底设成"烫烫烫烫烫烫"
STACK_MAGIC_SET __exc_stack, #OS_EXC_STACK_SIZE, OS_STACK_MAGIC_WORD //异常栈底设成"烫烫烫烫烫烫"
warm_reset: //热启动 Warm Reset, warm reboot, soft reboot, 在不关闭电源的情况,由软件控制重启计算机
/* initialize CPSR (machine state register) */
mov r0, #(CPSR_IRQ_DISABLE|CPSR_FIQ_DISABLE|CPSR_SVC_MODE) /* 禁止IRQ中断 | 禁止FIQ中断 | 管理模式-操作系统使用的保护模式 */
msr cpsr, r0 //设置CPSR寄存器
/* Note: some functions in LIBGCC1 will cause a "restore from SPSR"!! */
msr spsr, r0 //设置SPSR寄存器
/* get cpuid and keep it in r12 */
mrc p15, 0, r12, c0, c0, 5 //R12保存CPUID
and r12, r12, #MPIDR_CPUID_MASK //掩码操作获取当前cpu id
/* set svc stack, every cpu has OS_EXC_SVC_STACK_SIZE stack | 设置 SVC栈 */
ldr r0, =__svc_stack_top //注意这是栈底,高地址位
mov r2, #OS_EXC_SVC_STACK_SIZE //栈大小
mul r2, r2, r12
sub r0, r0, r2 /* 算出当前core的中断栈栈顶位置,写入所属core的sp */
mov sp, r0
LDR r0, =__exception_handlers
MCR p15, 0, r0, c12, c0, 0 /* Vector Base Address Register - VBAR */
cmp r12, #0 //CPU是否为主核
bne cpu_start //不相等就跳到从核处理分支
clear_bss: //主核处理.bss段清零
ldr r0, =__bss_start
ldr r2, =__bss_end
mov r1, #0
sub r2, r2, r0
bl memset
#if defined(LOSCFG_CC_STACKPROTECTOR_ALL) || \
defined(LOSCFG_CC_STACKPROTECTOR_STRONG) || \
defined(LOSCFG_CC_STACKPROTECTOR)
bl __stack_chk_guard_setup
#endif
#ifdef LOSCFG_GDB_DEBUG
/* GDB_START - generate a compiled_breadk,This function will get GDB stubs started, with a proper environment */
bl GDB_START
.word 0xe7ffdeff
#endif
bl main //带LR的子程序跳转, LR = pc - 4, 执行C层main函数
解读
第一步: 操作 CP15 协处理器 TPIDRPRW 寄存器,它被 ARM 设计保存当前运行线程的 ID值,在ARMv7 架构中才新出现,需PL1权限以上才能访问,而硬件不会从内部去改变它的值,也就是说这是一个直接暴露给工程师操作维护的一个寄存器,在鸿蒙内核中被用于记录线程结构体的开始地址,可以搜索 OsCurrTaskSet 来跟踪哪些地方会切换当前任务以便更好的理解内核。
第二步: 系统控制寄存器(SCTLR),B4.1.130 SCTLR, System Control Register 它提供了系统的最高级别控制,高到了玉皇大帝级别,代码中将 0、2、12位写 0。对应关闭 MMU 、数据缓存 、指令缓存 功能。
第三步: 对浮点运算FPU的设置,在安全模式下使用FPU,须定义NSACR、CPACR、FPEXC 三个寄存器
第四步: 计算虚拟地址和物理地址的偏移量,为何要计算它呢 ? 主要目的是为了建立虚拟地址和物理地址的映射关系,因为在 MMU启动之后,运行地址(PC寄存器指向的地址)将变成虚拟地址,使用虚拟地址就离不开映射表,所以两个地址的映射关系需要在MMU启动前就创建好,而有了偏移量就可以创建映射表。但需先搞清楚 链接地址 和 运行地址 两个概念。
两个地址往往不一样,而内核设计者希望它们是一样的,那有没有办法检测二者是否一样呢? 答案是 : 当然有的 ,通过一个变量在链接时将其链接地址变成变量的内容 ,无论中间怎么加载变量的内容是不会变的,而获取运行地址是很容易获取的,其实就是PC寄存器的地址,二者一减,加载偏了多少不就出来了
pa_va_offset:
.word . //定义一个4字节的pa_va_offset 变量, 链接器生成一个链接地址, . 表示 pa_va_offset = 链接地址 举例: 在地址 0x17321796 中保存了 0x17321796 值
adr r11, pa_va_offset //代码已执行至此,指令将获取 pa_va_offset 的运行地址(可能不是`0x17321796`) 给r11
ldr r0, [r11] // [r11]中存的是链接地址 `0x17321796`, 它不会随加载器变化的
sub r11, r11, r0 // 二者相减得到了偏移地址
第五步: 将内核代码从 __exception_handlers 处移到 SYS_MEM_BASE处,长度是 __bss_start - __exception_handlers , __exception_handlers是加载后的开始地址, 由加载器决定, 而SYS_MEM_BASE 是系统定义的内存地址, 可由系统集成商指定配置, 他们希望内核从这里运行。 下图为内核镜像布局
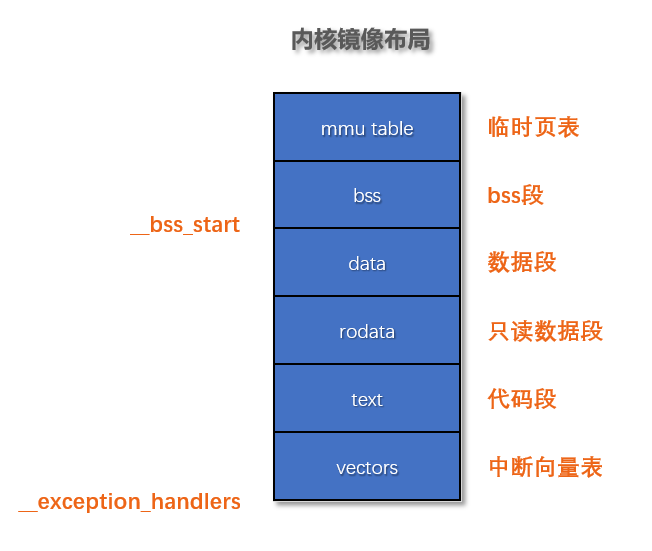
具体代码如下:
/* if we need to relocate to proper location or not | 如果需要重新安装到合适的位置*/
adr r4, __exception_handlers /* r4: base of load address | 加载基址*/
ldr r5, =SYS_MEM_BASE /* r5: base of physical address | 物理基址*/
subs r12, r4, r5 /* r12: delta of load address and physical address | 二者偏移量*/
beq reloc_img_to_bottom_done /* if we load image at the bottom of physical address | 不相等就需要重定位 */
/* we need to relocate image at the bottom of physical address | 需要知道拷贝的大小*/
ldr r7, =__exception_handlers /* r7: base of linked address (or vm address) | 链接地址基地址*/
ldr r6, =__bss_start /* r6: end of linked address (or vm address),由于目前阶段有用的数据是中断向量表+代码段+只读数据段+数据段,
所以只需复制[__exception_handlers,__bss_start]这段数据到内存基址处 */
sub r6, r7 /* r6: delta of linked address (or vm address) | 内核镜像大小 */
add r6, r4 /* r6: end of load address | 说明需拷贝[ r4,r4+r6 ] 区间内容到 [ r5,r5+r6 ]*/
reloc_img_to_bottom_loop://重定位镜像到内核物理内存基地址,将内核从加载地址拷贝到内存基址处
ldr r7, [r4], #4 // 类似C语言 *r5 = *r4 , r4++ , r5++
str r7, [r5], #4 // #4 代表32位的指令长度,此时在拷贝内核代码区内容
cmp r4, r6 /* 拷贝完成条件. r4++ 直到等于r6 (加载结束地址) 完成拷贝动作 */
bne reloc_img_to_bottom_loop
sub pc, r12 /* 重新校准pc寄存器, 无缝跳到了拷贝后的指令地址处执行 r12是重定位镜像前内核加载基地址和内核物理内存基地址的差值 */
nop // 注意执行完成sub pc, r12后,新的PC寄存器也指向了 nop ,nop是伪汇编指令,等同于 mov r0 r0 通常用于控制时序的目的,强制内存对齐,防止流水线灾难,占据分支指令延迟
sub r11, r11, r12 /* r11: eventual address offset | 最终地址偏移量 */
第六步: 在打开MMU必须要做好虚拟地址和物理地址的映射关系 , 需构建页表 , 关于页表可翻看 虚实映射篇, 具体代码如下
#ifdef LOSCFG_KERNEL_MMU
ldr r4, =g_firstPageTable /* r4: physical address of translation table and clear it
内核页表是用数组g_firstPageTable存储 见于los_arch_mmu.c */
add r4, r4, r11 //计算g_firstPageTable页表物理地址
mov r0, r4 //因为默认r0 将作为memset_optimized的第一个参数
mov r1, #0 //第二个参数,清0
mov r2, #MMU_DESCRIPTOR_L1_SMALL_ENTRY_NUMBERS //第三个参数是L1表的长度
bl memset_optimized /* optimized memset since r0 is 64-byte aligned | 将内核页表空间清零*/
ldr r5, =g_archMmuInitMapping //记录映射关系表
add r5, r5, r11 //获取g_archMmuInitMapping的物理地址
init_mmu_loop: //初始化内核页表
ldmia r5!, {r6-r10} /* r6 = phys, r7 = virt, r8 = size, r9 = mmu_flags, r10 = name | 物理地址、虚拟地址、映射大小、映射属性、名称*/
cmp r8, 0 /* if size = 0, the mmu init done */
beq init_mmu_done //标志寄存器中Z标志位等于零时跳转到 init_mmu_done处执行
bl page_table_build //创建页表
b init_mmu_loop //循环继续
init_mmu_done:
orr r8, r4, #MMU_TTBRx_FLAGS /* r8 = r4 and set cacheable attributes on translation walk | 设置缓存*/
ldr r4, =g_mmuJumpPageTable /* r4: jump pagetable vaddr | 页表虚拟地址*/
add r4, r4, r11
ldr r4, [r4]
add r4, r4, r11 /* r4: jump pagetable paddr | 页表物理地址*/
/* build 1M section mapping, in order to jump va during turing on mmu:pa == pa, va == pa */
/* 从当前PC开始建立1MB空间的段映射,分别建立物理地址和虚拟地址方式的段映射页表项
* 内核临时页表在系统 使能mmu -> 切换到虚拟地址运行 这段时间使用
*/
mov r6, pc
mov r7, r6 /* r7: pa (MB aligned)*/
lsr r6, r6, #20 /* r6: pa l1 index */
ldr r10, =MMU_DESCRIPTOR_KERNEL_L1_PTE_FLAGS
add r12, r10, r6, lsl #20 /* r12: pa |flags */
str r12, [r4, r7, lsr #(20 - 2)] /* jumpTable[paIndex] = pt entry */
rsb r7, r11, r6, lsl #20 /* r7: va */
str r12, [r4, r7, lsr #(20 - 2)] /* jumpTable[vaIndex] = pt entry */
bl mmu_setup /* set up the mmu | 内核映射表已经创建好了,此时可以启动MMU工作了*/
#endif
第七步: 使能MMU, 有了页表就可以使用虚拟地址了
mmu_setup: //启动MMU工作
mov r12, #0 /* TLB Invalidate All entries - TLBIALL */
mcr p15, 0, r12, c8, c7, 0 /* Set c8 to control the TLB and set the mapping to invalid */
isb
mcr p15, 0, r12, c2, c0, 2 /* Translation Table Base Control Register(TTBCR) = 0x0
[31] :0 - Use the 32-bit translation system(虚拟地址是32位)
[5:4]:0 - use TTBR0和TTBR1
[2:0]:0 - TTBCR.N为0;
例如:TTBCR.N为0,TTBR0[31:14-0] | VA[31-0:20] | descriptor-type[1:0]组成32位页表描述符的地址,
VA[31:20]可以覆盖4GB的地址空间,所以TTBR0页表是16KB,不使用TTBR1;
例如:TTBCR.N为1,TTBR0[31:14-1] | VA[31-1:20] | descriptor-type[1:0]组成32位页表描述符的地址,
VA[30:20]可以覆盖2GB的地址空间,所以TTBR0页表是8KB,TTBR1页表是8KB(页表地址必须16KB对齐);
*/
isb
orr r12, r4, #MMU_TTBRx_FLAGS //将临时页表属性[6:0]和基地址[31:14]放到r12
mcr p15, 0, r12, c2, c0, 0 /* Set attributes and set temp page table */
isb
mov r12, #0x7 /* 0b0111 */
mcr p15, 0, r12, c3, c0, 0 /* Set DACR with 0b0111, client and manager domian */
isb
mrc p15, 0, r12, c1, c0, 1 /* ACTLR, Auxlliary Control Register */
orr r12, r12, #(1 << 6) /* SMP, Enables coherent requests to the processor. */
orr r12, r12, #(1 << 2) /* Enable D-side prefetch */
orr r12, r12, #(1 << 11) /* Global BP Enable bit */
mcr p15, 0, r12, c1, c0, 1 /* ACTLR, Auxlliary Control Register */
dsb
/*
* 开始使能MMU,使用的是内核临时页表,这时cpu访问内存不管是取指令还是访问数据都是需要经过mmu来翻译,
* 但是在mmu使能之前cpu使用的都是内核的物理地址,即使现在使能了mmu,cpu访问的地址值还是内核的物理地址值(这里仅仅从数值上来看),
* 而又由于mmu使能了,所以cpu会把这个值当做虚拟地址的值到页表中去找其对应的物理地址来访问。
* 所以现在明白了为什么要在内核临时页表里建立一个内核物理地址和虚拟地址一一映射的页表项了吧,因为建立了一一映射,
* cpu访问的地址经过mmu翻译得到的还是和原来一样的值,这样在cpu真正使用虚拟地址之前也能正常运行。
*/
mrc p15, 0, r12, c1, c0, 0
bic r12, #(1 << 29 | 1 << 28) /* disable access flag[bit29],ap[0]是访问权限位,支持全部的访问权限类型
disable TEX remap[bit28],使用TEX[2:0]与C Bbit控制memory region属性 */
orr r12, #(1 << 0) /* mmu enable */
bic r12, #(1 << 1)
orr r12, #(1 << 2) /* D cache enable */
orr r12, #(1 << 12) /* I cache enable */
mcr p15, 0, r12, c1, c0, 0 /* Set SCTLR with r12: Turn on the MMU, I/D cache Disable TRE/AFE */
isb
ldr pc, =1f /* Convert to VA | 1表示标号,f表示forward(往下) - pc值取往下标识符“1”的虚拟地址(跳转到标识符“1”处)
因为之前已经在内核临时页表中建立了内核虚拟地址和物理地址的映射关系,所以接下来cpu切换到虚拟地址空间 */
1:
mcr p15, 0, r8, c2, c0, 0 /* Go to the base address saved in C2: Jump to the page table */
isb //r8中保存的是内核L1页表基地址和flags,r8写入到TTBR0实现临时页表和内核页表的切换
mov r12, #0
mcr p15, 0, r12, c8, c7, 0 /* TLB Invalidate All entries - TLBIALL(Invalidate all EL1&0 regime stage 1 and 2 TLB entries) */
isb
sub lr, r11 /* adjust lr with delta of physical address and virtual address |
lr中保存的是mmu使能之前返回地址的物理地址值,这时需要转换为虚拟地址,转换算法也很简单,虚拟地址 = 物理地址 - r11 */
bx lr //返回
第八步: 设置异常和中断栈 ,初始化栈内值和栈顶值
//初始化栈内值
ldr r0, =__svc_stack //stack_init的第一个参数 __svc_stack表示栈顶
ldr r1, =__exc_stack_top //stack_init的第二个参数 __exc_stack_top表示栈底, 这里会有点绕, top表高地址位
bl stack_init //初始化各个cpu不同模式下的栈空间
//设置各个栈顶魔法数字
STACK_MAGIC_SET __svc_stack, #OS_EXC_SVC_STACK_SIZE, OS_STACK_MAGIC_WORD //中断栈底设成"烫烫烫烫烫烫"
STACK_MAGIC_SET __exc_stack, #OS_EXC_STACK_SIZE, OS_STACK_MAGIC_WORD //异常栈底设成"烫烫烫烫烫烫"
stack_init:
ldr r2, =OS_STACK_INIT //0xCACACACA
ldr r3, =OS_STACK_INIT
/* Main loop sets 32 bytes at a time. | 主循环一次设置 32 个字节*/
stack_init_loop:
.irp offset, #0, #8, #16, #24
strd r2, r3, [r0, \offset] /* 等价于strd r2, r3, [r0, 0], strd r2, r3, [r0, 8], ... , strd r2, r3, [r0, 24] */
.endr
add r0, #32 //加跳32个字节,说明在地址范围上 r1 > r0 ==> __exc_stack_top > __svc_stack
cmp r0, r1 //是否到栈底
blt stack_init_loop
bx lr
//初始化栈顶值
excstack_magic:
mov r3, #0 //r3 = 0
excstack_magic_loop:
str r2, [r0] //栈顶设置魔法数字
add r0, r0, r1 //定位到栈底
add r3, r3, #1 //r3++
cmp r3, #CORE_NUM //栈空间等分成core_num个空间,所以每个core的栈顶需要magic num
blt excstack_magic_loop
bx lr
/* param0 is stack top, param1 is stack size, param2 is magic num */
.macro STACK_MAGIC_SET param0, param1, param2
ldr r0, =\param0
mov r1, \param1
ldr r2, =\param2
bl excstack_magic
.endm
STACK_MAGIC_SET __svc_stack, #OS_EXC_SVC_STACK_SIZE, OS_STACK_MAGIC_WORD //中断栈底设成"烫烫烫烫烫烫"
STACK_MAGIC_SET __exc_stack, #OS_EXC_STACK_SIZE, OS_STACK_MAGIC_WORD //异常栈底设成"烫烫烫烫烫烫"
第九步: 热启动
warm_reset: //热启动 Warm Reset, warm reboot, soft reboot, 在不关闭电源的情况,由软件控制重启计算机
/* initialize CPSR (machine state register) */
mov r0, #(CPSR_IRQ_DISABLE|CPSR_FIQ_DISABLE|CPSR_SVC_MODE) /* 禁止IRQ中断 | 禁止FIQ中断 | 管理模式-操作系统使用的保护模式 */
msr cpsr, r0
/* Note: some functions in LIBGCC1 will cause a "restore from SPSR"!! */
msr spsr, r0
/* get cpuid and keep it in r12 */
mrc p15, 0, r12, c0, c0, 5 //R12保存CPUID
and r12, r12, #MPIDR_CPUID_MASK //掩码操作获取当前cpu id
/* set svc stack, every cpu has OS_EXC_SVC_STACK_SIZE stack */
ldr r0, =__svc_stack_top
mov r2, #OS_EXC_SVC_STACK_SIZE
mul r2, r2, r12
sub r0, r0, r2 /* 算出当前core的中断栈栈顶位置,写入所属core的sp */
mov sp, r0
LDR r0, =__exception_handlers
MCR p15, 0, r0, c12, c0, 0 /* Vector Base Address Register - VBAR */
cmp r12, #0
bne cpu_start //从核处理分支
第十步: 进入 C 语言的 main()
bl main //带LR的子程序跳转, LR = pc - 4, 执行C层main函数
LITE_OS_SEC_TEXT_INIT INT32 main(VOID)//由主CPU执行,默认0号CPU 为主CPU
{
UINT32 ret = OsMain();
if (ret != LOS_OK) {
return (INT32)LOS_NOK;
}
CPU_MAP_SET(0, OsHwIDGet());//设置CPU映射,参数0 代表0号CPU
OsSchedStart();//调度开始
while (1) {
__asm volatile("wfi");//WFI: wait for Interrupt 等待中断,即下一次中断发生前都在此hold住不干活
}
}
debug一样,文章内容会存在不少错漏之处,请多包涵,但会反复修正,持续更新,v**.xx 代表文章序号和修改的次数,精雕细琢,言简意赅,力求打造精品内容。
按功能模块:
百万汉字注解内核目的是要看清楚其毛细血管,细胞结构,等于在拿放大镜看内核。内核并不神秘,带着问题去源码中找答案是很容易上瘾的,你会发现很多文章对一些问题的解读是错误的,或者说不深刻难以自圆其说,你会慢慢形成自己新的解读,而新的解读又会碰到新的问题,如此层层递进,滚滚向前,拿着放大镜根本不愿意放手。
< gitee | github | coding | gitcode > 四大码仓推送 | 同步官方源码,鸿蒙研究站 | weharmonyos 中回复 百万 可方便阅读。

据说喜欢点赞分享的,后来都成了大神。?
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
在Ruby(1.8.X)中为什么Object既继承了内核又包含了内核?仅仅继承还不够吗?irb(main):006:0>Object.ancestors=>[Object,Kernel]irb(main):005:0>Object.included_modules=>[Kernel]irb(main):011:0>Object.superclass=>nil请注意,在Ruby1.9中情况类似(但更简洁):irb(main):001:0>Object.ancestors=>[Object,Kernel,BasicObject]irb(main):002:0>Object.included
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
参考文章搭建文章gitte源码在线体验可以注册两个号来测试演示图:一.整体介绍 介绍SignalR一种通讯模型Hub(中心模型,或者叫集线器模型),调用这个模型写好的方法,去发送消息。 内容有: ①:Hub模型的方法介绍 ②:服务器端代码介绍 ③:前端vue3安装并调用后端方法 ④:聊天室样例整体流程:1、进入网站->调用连接SignalR的方法2、与好友发送消息->调用SignalR的自定义方法 前端通过,signalR内置方法.invoke() 去请求接口3、监听接受方法(渲染消息)通过new signalR.HubConnectionBuilder().on
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
目录一.大致如下常见问题:(1)找不到程序所依赖的Qt库version`Qt_5'notfound(requiredby(2)CouldnotLoadtheQtplatformplugin"xcb"in""eventhoughitwasfound(3)打包到在不同的linux系统下,或者打包到高版本的相同系统下,运行程序时,直接提示段错误即segmentationfault,或者Illegalinstruction(coredumped)非法指令(4)ldd应用程序或者库,查看运行所依赖的库时,直接报段错误二.问题逐个分析,得出解决方法:(1)找不到程序所依赖的Qt库version`Qt_5'
我想使用ruby-prof和JMeter分析Rails应用程序。我对分析特定Controller/操作/或模型方法的建议方法不感兴趣,我想分析完整堆栈,从上到下。所以我运行这样的东西:RAILS_ENV=productionruby-prof-fprof.outscript/server>/dev/null然后我在上面运行我的JMeter测试计划。然而,问题是使用CTRL+C或SIGKILL中断它也会在ruby-prof可以写入任何输出之前杀死它。如何在不中断ruby-prof的情况下停止mongrel服务器? 最佳答案
我尝试在IRB(v0.9.6,Ruby2.3.0)中使用Refinement:moduleFoorefineObjectdodeffoo()"foo"endendendusingFoo#=>RuntimeError:main.usingispermittedonlyattoplevel这基本上是theexactsetupfromthedocumentation(这会导致相同的错误)。出了什么问题?我该如何解决这个问题? 最佳答案 这可能是IRb的错误或功能不当。众所周知,由于IRb的实现方式非常骇人听闻,因此它无法在所有极端情况下正