文章目录
MongoEngine: 使用最为广泛的 ODM。http://mongoengine.org/
uMongo: 支持 sync/async 特性的 ODM。https://umongo.readthedocs.io/en/latest/
安装:
pip install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com mongoengine
连接 MongoDB 数据库:
# -*- coding: utf-8 -*-
# @Time : 2023-03-19 13:35
# @Author : AmoXiang
# @File : 1.连接.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680
from mongoengine import connect, disconnect
# 方式一:使用默认配置
# connect(db='test')
connect('test')
# 方式二: 指定主机地址和端口号
# connect('students', host='172.0.0.1', port=27017)
connect('students', host='mongodb://localhost/students', alias='students1')
# 连接到多个数据库 建立连接 使用alias指定别名
# connect(alias='db1', db='test')
# connect(alias='db2', db='test-temp')
# 断开连接
# disconnect(alias='db1')
MongoEngine ODM 模型,示例代码如下:

MongoEngine 常见数据模型,如下表所示:
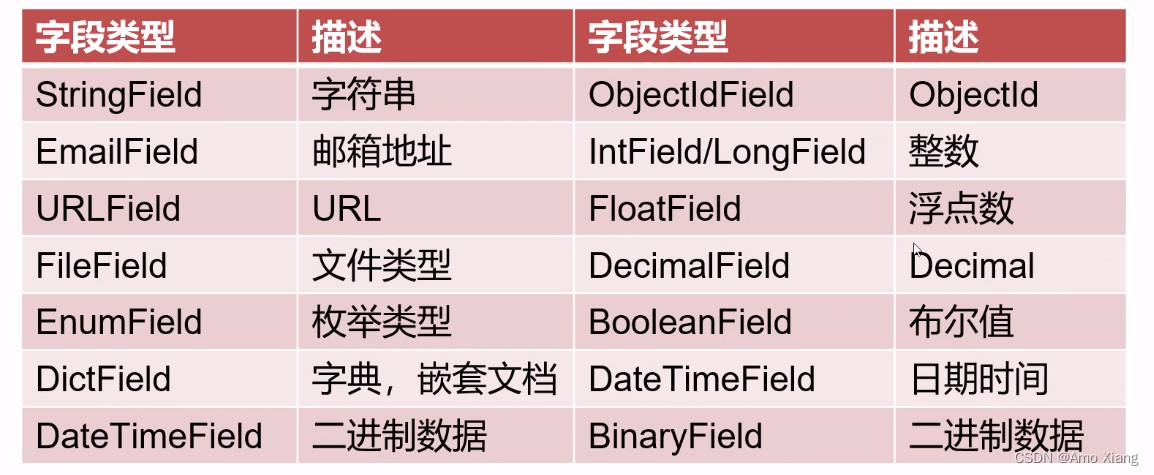
数据类型通用参数,参考如下:
db_field: 文档中的field/域/列名称
required: 是否为必填项
default: 默认值
unique: 唯一性约束
choices: 可选择的列表
primary_key: 是否为文档的主键,默认为Fasle
类属性 meta:类属性,其配置项为 python 的 dict(字典)。 示例代码:
class User(Document):
username = StringField()
meta = {}
# 类属性meta常见配置项
# 1.db_alias: 指定文档所在的数据库(逻辑库)
# 2.collection: 指定文档所在的集合
# 3.ordering: 指定文档的默认排序规则
# 4. indexes: 指定文档的索引规则
学生信息数据字典,如下表所示:
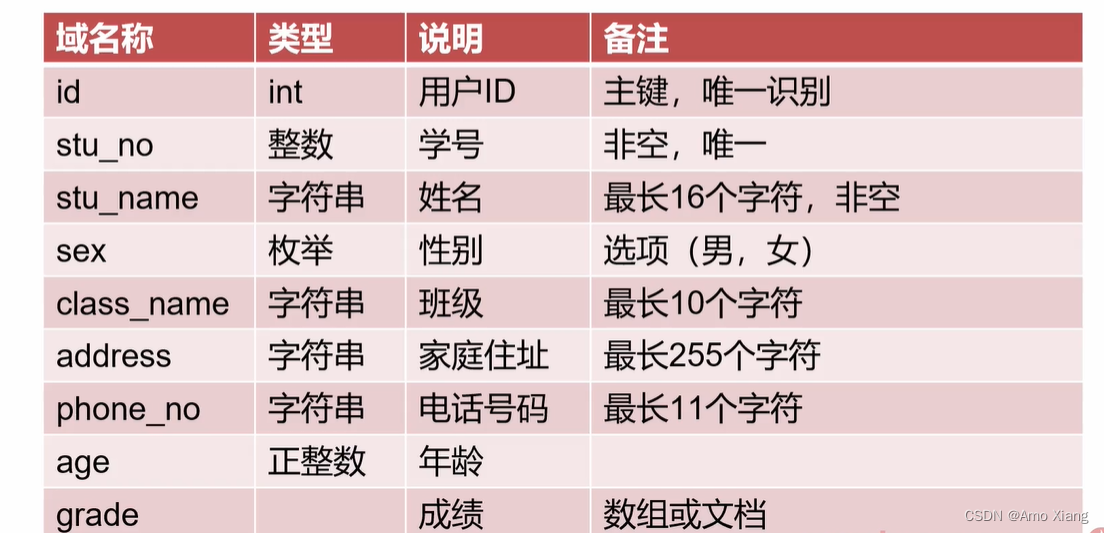
Python 代码实现,示例如下:
# -*- coding: utf-8 -*-
# @Time : 2023-03-19 13:58
# @Author : AmoXiang
# @File : 2.ODM模型.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680
from enum import Enum
from mongoengine import Document, connect
from mongoengine.fields import IntField, StringField, EnumField
# 连接到数据库
connect('test')
class SexChoices(Enum):
MEN = '男'
WOMEN = '女'
class Student(Document):
""" 学生信息 """
stu_no = IntField(required=True, unique=True, verbose_name='学号')
stu_name = StringField(required=True, max_length=16, verbose_name='姓名')
# sex = StringField(max_length=2, verbose_name='性别', choices=[SexChoices.MEN, SexChoices.WOMEN])
sex = EnumField(enum=SexChoices, verbose_name='性别')
class_name = StringField(max_length=10, verbose_name='班级')
address = StringField(max_length=255, verbose_name='家庭住址')
phone_no = StringField(max_length=11, verbose_name='电话号码')
age = IntField(min_value=0, max_value=150, verbose_name='年龄')
meta = {
# 指定集合
'collection': 'students',
'ordering': ['-age']
}
文档嵌套的场景:
// 情况一: 数组-简单数据类型
{"grades": [76, 51, 84]}
// 情况二: 数组-文档
{"grades": ["score": 76}, {"score": 51}]}
// 情况三: 单个文档
"grade": {"course_name": "语文", "score": 76]}
示例代码如下:
from enum import Enum
from mongoengine import Document, connect, EmbeddedDocument
from mongoengine.fields import IntField, StringField, EnumField, ListField, EmbeddedDocumentField
# 连接到数据库
connect('test')
class SexChoices(Enum):
MEN = '男'
WOMEN = '女'
class CourseGrade(EmbeddedDocument):
""" 成绩信息(科目 、老师、成绩) -被嵌套的文档 """
course_name = StringField(max_length=64, required=True, verbose_name='课程名称')
teacher = StringField(max_length=16, verbose_name='老师')
score = IntField(required=True, min_value=0, max_value=100, verbose_name='老师')
class Student(Document):
""" 学生信息 """
stu_no = IntField(required=True, unique=True, verbose_name='学号')
stu_name = StringField(required=True, max_length=16, verbose_name='姓名')
# sex = StringField(max_length=2, verbose_name='性别', choices=[SexChoices.MEN, SexChoices.WOMEN])
sex = EnumField(enum=SexChoices, verbose_name='性别')
class_name = StringField(max_length=10, verbose_name='班级')
address = StringField(max_length=255, verbose_name='家庭住址')
phone_no = StringField(max_length=11, verbose_name='电话号码')
age = IntField(min_value=0, max_value=150, verbose_name='年龄')
grades = ListField(EmbeddedDocumentField(CourseGrade), verbose_name='成绩列表')
meta = {
# 指定集合
'collection': 'students',
# 排序规则:年龄倒序
'ordering': ['-age']
}
class StudentGrade(Document):
""" 学生成绩 """
stu_no = IntField(required=True, unique=True, verbose_name='学号')
stu_name = StringField(required=True, max_length=16, verbose_name='姓名')
# sex = StringField(max_length=2, verbose_name='性别', choices=[SexChoices.MEN, SexChoices.WOMEN])
sex = EnumField(enum=SexChoices, verbose_name='性别')
class_name = StringField(max_length=10, verbose_name='班级')
address = StringField(max_length=255, verbose_name='家庭住址')
phone_no = StringField(max_length=11, verbose_name='电话号码')
age = IntField(min_value=0, max_value=150, verbose_name='年龄')
grade = EmbeddedDocumentField(CourseGrade, verbose_name='成绩列表')
meta = {
# 指定集合
'collection': 'grades',
# 排序规则:年龄倒序
'ordering': ['-age']
}
结果集,结果集 QuerySet 的获取:
User.objects
# 结果集上的常用方法:
# 1.all(): 查询所有的文档
# 2.filter(): 按照条件查询
# 3.count(): 满足条件的文档数
# 4.sum()/average(): 求和/求平均数
# 5.order_by(): 排序
# 6. .skip().limit(): 分页
....
单个文档查询:
# first(): 没有文档则返回 None
User.objects.first()
get(**kwargs):
# 1.多个文档时: 异常 MultipleObjectsReturned
# 2.没有文档时: 异常 DoesNotExist
# 3.仅有一个文档时: 返回 ODM 对象
查询条件的使用,在 MongoEngine 中使用 双下划线(__) 分割:
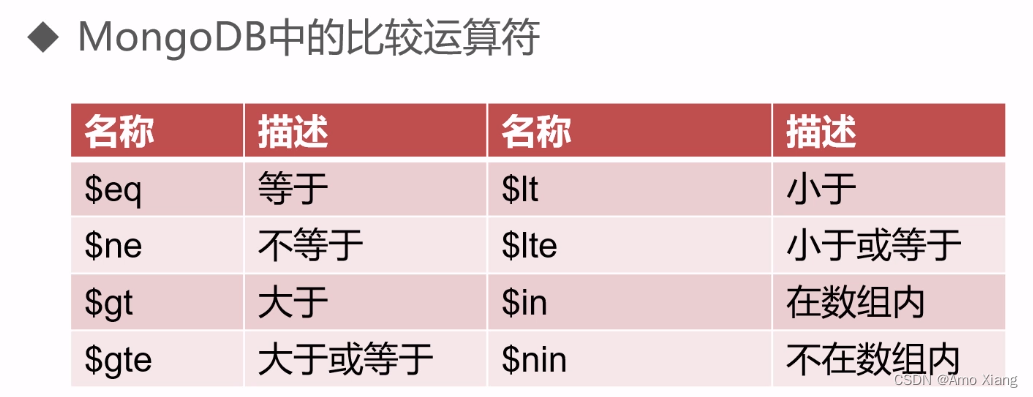
MongoEngine 中的字符串查询(i表示不区分大小写):
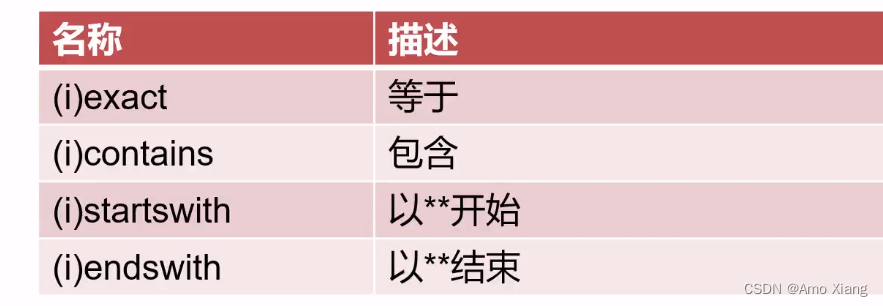
多个条件组合查询,Q函数的使用:
from mongoengine.queryset.visitor import Q
# 1.多个条件同时满足
Student.objects(Q(key1=value1) & Q(key2=value2))
# 2.多个条件部分满足
Student.objects(Q(key1=value1) | Q(key2=value2))
聚合统计:
# 1.满足条件的文档数
User.objects.count()
# 2.求和/求平均数
User.objects.filter().sum(field)
排序:
# 排序规则 -: 倒序排列 (+): 正序排列
# 示例代码
Students.objects().order_by('+field1', '-field2')
分页处理:
# 方式一: 切片方式
User.objects.all()[10:15]
# 方式二: .skip().limit()
User.objects.skip(10).limit(5)
参考代码如下:
# -*- coding: utf-8 -*-
# @Time : 2023-03-19 14:44
# @Author : AmoXiang
# @File : 4.查询文档.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680
from bson import ObjectId
# from mongoengine.queryset.visitor import Q
from mongoengine import Q
from school_models import Student, StudentGrade, SexChoices
class TestMongoEngine(object):
def get_one_student(self):
""" 查询一个学生信息 """
return Student.objects.first()
def get_student_by_pk(self, pk):
""" 根据学生的ID来查询 """
object_id = ObjectId(pk)
# return Student.objects.get(id=object_id)
return Student.objects.get(id=pk)
# return Student.objects.get(age=12)
def get_students_01(self):
# 查询所有的文档
# queryset = Student.objects()
# queryset = Student.objects.all()
# 12岁以上的学生信息
# queryset = Student.objects(age__gt=12)
queryset = Student.objects.filter(age__gt=12)
print(queryset)
for item in queryset:
print(item, type(item))
def get_grade_01(self):
# 及格的成绩信息
queryset = StudentGrade.objects.filter(grade__score__gte=60)
for item in queryset:
print(item.stu_name, item.grade.score)
def get_students_02(self):
# //查找所有姓“李”的学生信息
# //SELECT * FROM school_student_info WHERE stu_name LIKE '李%';
# //SELECT * FROM school_student_info WHERE stu_name LIKE "李%";
# db.students.find({stu_name: /^李/});
queryset = Student.objects.filter(stu_name__startswith='李')
for item in queryset:
print(item)
def get_students_03(self):
""" 查询年龄在9~12之间(含)的学生信息 """
# //查询年龄在9~12之间(含)的学生信息
# //SELECT * FROM school_student_info WHERE age BETWEEN 9 AND 12;
# db.students.find({age: {$gte: 9,$lte: 12}});
# queryset = Student.objects.filter(age__gte=9, age__lte=12)
queryset = Student.objects.filter(Q(age__gte=9) & Q(age__lte=12))
for item in queryset:
print(item)
def get_students_04(self):
""" 查询所有12岁以上的男生和9岁以下的女生 """
# //查询所有12岁以上的男生和9岁以下的女生
# //SELECT * FROM school_student_info WHERE (age > 12 AND sex ='男') OR (age < 9 AND sex ='女');
# db.students.find({
# $or: [
# {sex: "男", age: {$gt: 12}},
# {sex: "女", age: {$lt: 9}}
# ]
# });
queryset = Student.objects.filter(Q(age__gt=12, sex=SexChoices.MEN) | Q(age__lt=9, sex=SexChoices.WOMEN))
# 指定排序规则
queryset = queryset.order_by('age')
for item in queryset:
print(item)
print('学生人数:', queryset.count())
def get_students_05(self):
# //统计语文成绩的最高分/最低分/平均分
# //SELECT MAX(score), MIN(score),AVG(score) FROM school_student_grade WHERE course_id=1;
# db.grades.aggregate([
# //where
# {
# $match: {"grade.course_name": "语文"}
# },
# //group by
# {
# $group: {
# _id: null,
# maxScore: {$max: "$grade.score"},
# minScore: {$min: "$grade.score"},
# avgScore: {$avg: "$grade.score"},
# }
# }
# ]);
queryset = StudentGrade.objects.filter(grade__course_name='语文')
avg_score = queryset.average('grade.score')
print('全年级语文成绩平均分', avg_score)
# 张三的总分
# //统计学生张三的各科总分
# //SELECT * FROM school_student_info WHERE stu_name = '张三';
# //SELECT * FROM school_student_grade WHERE student_id=5;
# //SELECT SUM(score) FROM school_student_grade WHERE student_id=5;
# db.grades.aggregate([
# //where
# {
# $match: {"stu_name": "张三"}
# },
# //group by
# {
# $group: {
# _id: null,
# totalScore: {$sum: "$grade.score"}
# }
# }
# ]);
queryset = StudentGrade.objects.filter(stu_name='张三')
sum_score = queryset.sum('grade.score')
print('张三的总分', sum_score)
def paginate(self, page=1, page_size=5):
"""
分页函数
:param page: 当前第几页
:param page_size: 每页多少条数据
:return:
"""
# 切片分页
start = (page - 1) * page_size
end = page * page_size
queryset = Student.objects.all()[start: end]
for item in queryset:
print(item)
# skip limit
print('-----------------')
queryset = Student.objects().skip(start).limit(page_size)
for item in queryset:
print(item)
def main():
obj = TestMongoEngine()
# result = obj.get_one_student()
# print(result)
# result = obj.get_student_by_pk('64120cbce602000052002ec1')
# print(result)
# ID不存在
# result = obj.get_student_by_pk('60d376bff95e00004900257b')
# print(result.stu_no)
# print(result)
# obj.get_students_01()
# obj.get_grade_01()
# obj.get_students_02()
# obj.get_students_03()
# obj.get_students_04()
# obj.get_students_05()
# 分页
obj.paginate(3)
if __name__ == '__main__':
main()
使用 ODM 新增数据:
# 1.第一步,构造 ODM 模型类对象
user_obj = User(username="lili")
# 2.第二步,验证数据
user_obj.validate()
# 3.第三步,保存数据
user_obj.save()
模型中验证器:
# 内置的验证器 如: max_length, min_value
# 自定义的验证器
def phone_required(value):
pattern = r'^1[0-9]{10}$'
if not re.search(pattern, value):
raise ValidationError('请输入手机号码')
使用 create() 方法,参考代码:
User.objects.create(**kwargs)
示例代码:
# -*- coding: utf-8 -*-
# @Time : 2023-03-19 15:30
# @Author : AmoXiang
# @File : 5.新增文档.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680
from school_models import Student, StudentGrade, SexChoices, CourseGrade
class TestMongoEngine(object):
def add_one(self):
""" 数据的新增 """
# stu_obj = Student(stu_no=2003, stu_name='王二小2')
# stu_obj = Student(stu_no=2003, stu_name='王二小2', phone_no='abc123')
stu_obj = Student(stu_no=2003, stu_name='王二小2', phone_no='13500000000')
stu_obj.validate()
result = stu_obj.save()
print(result)
print(result.id)
def add_one_2(self):
""" 使用create方法新增数据 """
result = Student.objects.create(stu_no=2004, stu_name='王二小4', phone_no='13500000001')
print(result)
print(result.id)
def add_one_3(self):
""" 嵌套文档的插入 """
grade1 = CourseGrade(course_name='语文', score=100)
grade2 = CourseGrade(course_name='数学', score=100)
grade3 = CourseGrade(course_name='英语', score=100)
grades = [grade1, grade2, grade3]
stu_obj = Student(stu_no=2005, stu_name='王二小5', phone_no='13500000000')
stu_obj.grades = grades
stu_obj.validate()
result = stu_obj.save()
print(result)
print(result.id)
def main():
obj = TestMongoEngine()
# obj.add_one()
# obj.add_one_2()
obj.add_one_3()
if __name__ == '__main__':
main()
使用 ODM 修改数据,如下所示:

修改一条数据:
User.objects.update_one()
批量修改数据:
User.objects.update()
示例代码:
# -*- coding: utf-8 -*-
# @Time : 2023-03-19 15:37
# @Author : AmoXiang
# @File : 6.修改文档.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680
from school_models import Student, StudentGrade, SexChoices, CourseGrade
class TestMongoEngine(object):
def update_one(self):
""" 数据的修改 """
queryset = Student.objects.filter(stu_no=2001)
# result = queryset.update_one(stu_name='王二大', phone_no='13400000000')
result = queryset.update_one(stu_name='王二大', unset__phone_no=True)
print(result)
def update_one_2(self):
""" 数据的修改 -save() """
stu_obj = Student.objects.filter(stu_no=2001).first()
if stu_obj:
stu_obj.stu_name = '王三'
# stu_obj.phone_no = '王三'
result = stu_obj.save()
print(result)
def update_many(self):
""" 9岁的学生年龄+1 """
queryset = Student.objects.filter(age=9)
for item in queryset:
print(item)
queryset.update(inc__age=1)
print('------------------')
queryset = Student.objects.filter(age=10)
for item in queryset:
print(item)
def main():
obj = TestMongoEngine()
# obj.update_one()
# obj.update_one_2()
obj.update_many()
if __name__ == '__main__':
main()
使用 ODM 删除数据,示例代码:
User.objects.delete()
参考代码如下:
# -*- coding: utf-8 -*-
# @Time : 2023-03-19 15:38
# @Author : AmoXiang
# @File : 7.删除文档.py
# @Software: PyCharm
# @Blog : https://blog.csdn.net/xw1680
from school_models import Student, StudentGrade, SexChoices, CourseGrade
class TestMongoEngine(object):
def delete_data(self):
""" 删除数据练习 """
# 删除学号> 2000的学生信息
queryset = Student.objects(stu_no__gt=2000)
print('学生人数', queryset.count())
result = queryset.delete()
print('删除的结果', result)
def main():
obj = TestMongoEngine()
obj.delete_data()
if __name__ == '__main__':
main()
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习数据库的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam
有没有办法快速将表格格式的ruby哈希打印到文件中?如:keyAkeyBkeyC...1232343451253474456...其中散列的值是不同大小的数组。还是使用双循环是唯一的方法?谢谢 最佳答案 试试我写的这个gem(在表中打印散列、ruby对象、ActiveRecord对象):http://github.com/arches/table_print 关于ruby-如何以表格格式快速打印Ruby哈希值?,我们在StackOverflow上找到一个类似的问题:
电脑启动出现显示器黑屏是一个相当常见的问题。如果您遇到了这个问题,不要惊慌,因为它有很多可能的原因,可以采取一些简单的措施来解决它。在本文中,小编将介绍下面4种常见的电脑启动后显示器黑屏的原因,排查这些原因,快速解决! 演示机型:联想Ideapad700-15ISK-ISE系统版本:Windows10一、显示器问题如果出现电脑启动后显示器黑屏的情况。那么首先您需要检查一下显示器是否正常工作。您可以通过更换另一个显示器或将当前显示器连接到另一台计算机来检查显示器是否存在问题。如果问题仍然存在,那么您可以排除显示器故障的可能性。 二、显卡问题如果您的电脑配备了独立显卡,那么显卡故障也可能是导致电脑
1、接口请求基本操作1.1例子tips在view的选项可以zoomin调整窗口字帖大小。1、创建一个测试的workspace,并命名为test2、test后面新增一个addrequest3、选择发送GET,URL为一个开源的https://api.apiopen.top/api/sentences获取每日一句4、点击send查看内容Tips:如果提示出现Error:tunnelingsocketcouldnotbeestablished,statusCode=407错误,参照以下解决办法)关于tunnelingsocketcouldnotbeestablished,cause=getaddri
Linux操作系统——网络配置与SSH远程安装完VMware与系统后,需要进行网络配置。第一个目标为进行SSH连接,可以从本机到VMware进行文件传送,首先需要进行网络配置。1.下载远程软件首先需要先下载安装一款远程软件:FinalShell或者xhell7FinalShellxhell7FinalShell下载:Windows下载http://www.hostbuf.com/downloads/finalshell_install.exemacOS下载http://www.hostbuf.com/downloads/finalshell_install.pkg2.配置CentOS网络安装好
Ruby语言是否可以用于创建全新的移动操作系统或桌面操作系统,即是否可以用于系统编程? 最佳答案 嗯,现在有一些操作系统使用比C更高级的语言。基本上,ruby解释器本身需要用一些低级的东西来编写,并且需要一些引导加载代码将功能齐全的ruby解释器作为独立内核加载到内存中。一旦ruby解释器被引导并以内核模式(或innerrings之一)运行,就没有什么可以阻止您在其上构建整个操作系统。不幸的是,它可能会很慢。每个操作系统功能的垃圾收集可能会相当引人注目。ruby解释器将负责任务调度和网络堆栈等基本事情,使用垃圾收集框架会大大