✅作者简介:大家好,我是Philosophy7?让我们一起共同进步吧!🏆 📃个人主页:Philosophy7的csdn博客
🔥系列专栏:
👑哲学语录: 承认自己的无知,乃是开启智慧的大门
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博>主哦🤞


文章目录
HBase是一种构建在HDFS之上的分布式、面向列的存储系统。隶属于Apache基金组织的一个子项目,Apache HBase是基于Google BigTable开源实现的。也就意味着,HBase支持海量数据的存储,而且还是一种NoSQL的一种数据库。
RDBMS(Relational DataBase Management System)关系型数据库它的优点在于:
缺点:
NoSQL:非关系型数据库
优点:
缺点:
| id | name | age | sex |
|---|---|---|---|
| 1 | jack | 20 | 男 |
| 2 | tom | 29 | 男 |
| id | 1 | 2 | 3 |
|---|---|---|---|
| name | jack | tom | rose |
| age | 23 | 19 | 26 |
这两种存储的数据都是从上到下,从左到右排列的。
| 项目 | 行存储 | 列存储 |
|---|---|---|
| 优点 | 写入效率高,提供数据完整性保证 | 读取过程有冗余,适合数据定长的大数据计算 |
| 缺点 | 数据读取有冗余,影响计算速度 | 缺乏数据完整性保证,写入效率低 |
| 改进 | 优化的存储格式,保证在内存中快速删除冗余数据 | 多线程并行读写操作 |
| 应用场景 | 商业领域、互联网 | 互联网 |
逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个 multi-dimensional map多维映射
HBase是一种类似BigTable的分布式数据库,是一个稀疏的、长期存储的(存储在硬盘上)、多维度的、排序的映射表,表的索引是行键、列关键字和时间戳,HBase中的数据都是字符串。类似于一种Json格式的字符串
| 行键 | 时间戳 | 列族info | 列族info2 |
|---|---|---|---|
| 1001 | Timestamp | info1:name=“zhangsan” | info2:name=“lisi” |
| 1002 | xxxxxxxxx | info1:age=“23” | info2:age=“29” |
在物理存储方面,仍然是按照列来存储数据的。
| 行键 | 时间戳 | 列 | 单元格(Value) |
|---|---|---|---|
| 1001 | t1 | info1:name | zhangsan |
| 1001 | t2 | info1:age | 26 |
| 1002 | t1 | info1:name | lisi |
| 1002 | t2 | info1:age | 29 |
注意:在逻辑模型中有些列是空白的,这样的列实际不会被存储,当请求这些空白的单元格时会返回一个Null值。如果在查询的时候不提供时间戳,那么会返回距离现在最近的时间戳的版本数据,数据的存储按照时间戳来排序。
非关系型数据库从严格意义上来说并不是数据库,而是一种数据结构化存储方法的集合。HBase作为一个NoSQL数据库,仅支持单行事务,通过不断增加集群中的节点数据量来增加计算能力,具有以下特点:
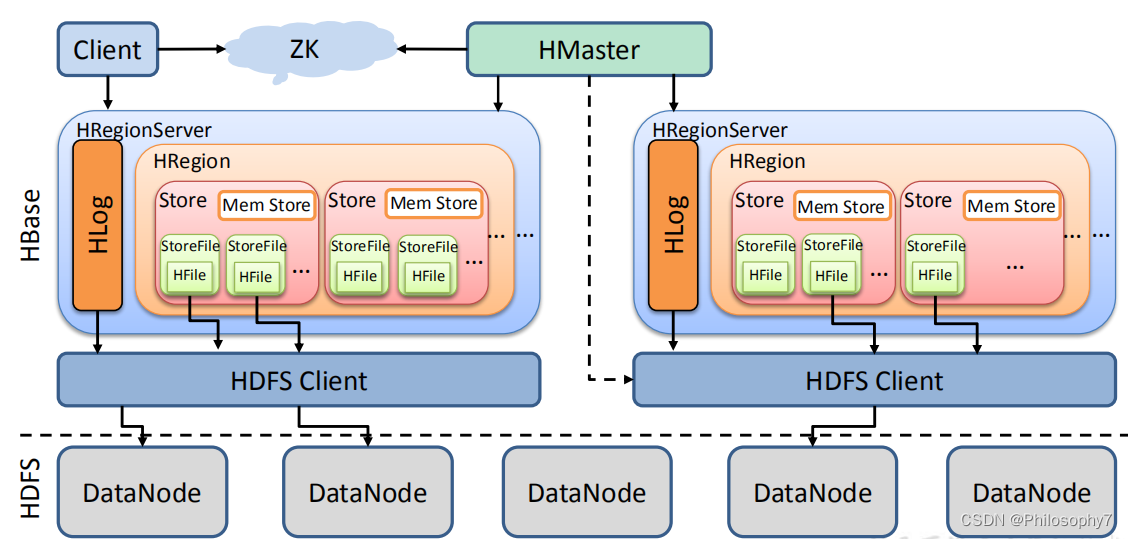
HBase属于以主从架构,隶属于Hadoop生态系统,由以下组件组成:Client、Zookeeper、HMaster、HRegionServer和HResion。
Client:
Zookeeper:
HMaster
HRegionServer
HRegion
在进入环境搭建的环节,我们首先认识一下HBase的运行环境:
属性设置为true`tar -zxvf hbase-1.3.1-bin.tar.gz -C /usr/local/
重命名hbase
mv hbase-1.3.1/ hbase
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed ZooKeeper
true: fully-distributed with unmanaged ZooKeeper Quorum (see hbase-env.sh)
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper-3.4.5/zkData</value>
<description>Property from ZooKeeper config zoo.cfg.
The directory where the snapshot is stored.
</description>
</property>
</configuration>
hbase-env.sh 文件中的以下行显示了如何设置JAVA_HOME环境变量(HBase 需要的)并将堆设置为 4 GB(而不是默认值 1 GB)。如果您复制并粘贴此示例,请务必调整JAVA_HOME以适合您的环境。

# The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/usr/local/jdk1.8.0_321
# Extra Java CLASSPATH elements. Optional.
# export HBASE_CLASSPATH=
# The maximum amount of heap to use. Default is left to JVM default. 默认是1G 设置为4G
export HBASE_HEAPSIZE=4G
在此文件中列出将运行 RegionServers 的节点,如果要配置本机名称,请将localhost注释掉
#localhost
master
slave1
slave2
scp -r /usr/local/hbase/ slave1:/usr/local/
scp -r /usr/local/hbase/ slave2:/usr/local/
cd $HADOOP_HOME
sbin/start-dfs.sh
sbin/start-yarn.sh
#配置环境变量 直接启动 集群都要启动
zkServer.sh start
bin/start-hbase.sh #启动
bin/stop-hbase.sh #关闭

启动成功后,http://master:16010访问HBase管理Web界面。
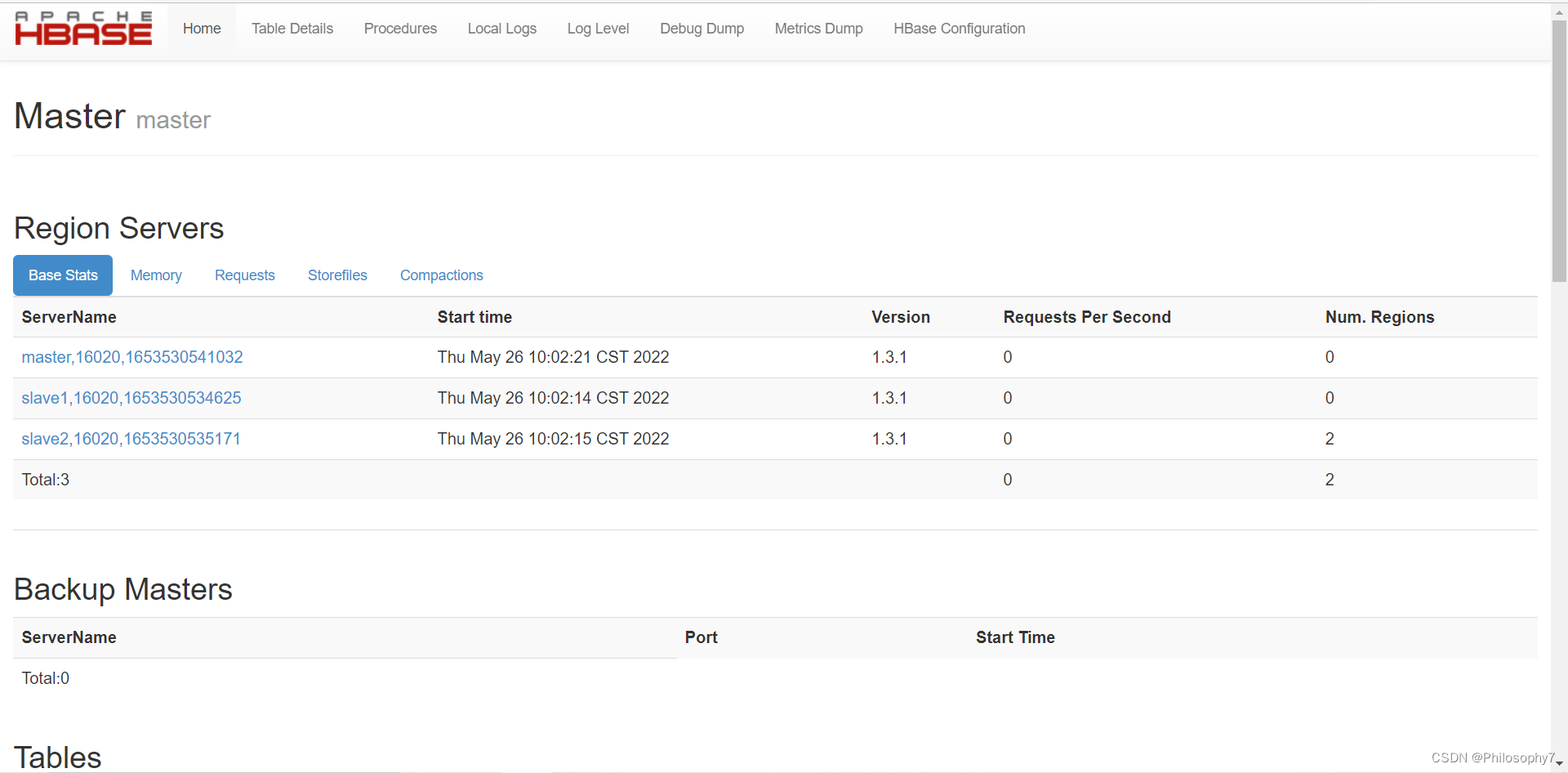
bin/hbase shell
#这里有一个恶心的点就是 光标停留在哪就删除哪 如果需要往前删除需要按住Ctrl键
创建表
#可以使用help帮助命令查看
create 'student','info' # 后面的info是列族 可以声明多个列族
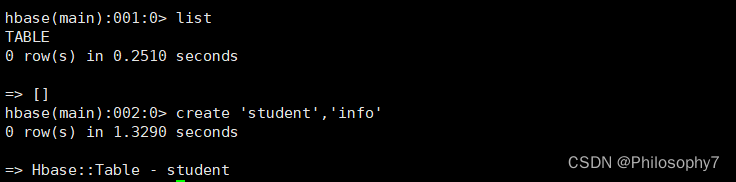
#插入数据
put 'student','1001','info:name','zhangsan'
put 'student','1001','info:age',29
#扫描全表查看数据
scan 'student'
#查看表详细信息
describe 'student'
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我试图在rails中了解rubygems是如何变得可以自动使用的,而不是在使用required的文件中gem? 最佳答案 这是通过bundler/setup完成的:http://bundler.io/v1.3/bundler_setup.html.它在您的config/boot.rb文件中是必需的。简而言之,它首先将环境变量设置为指向您的Gemfile:ENV['BUNDLE_GEMFILE']||=File.expand_path('../../Gemfile',__FILE__)然后它通过要求bundler/setup将所有ge
从一开始,我就是一个Windows高手。我从MS-DOS开始。我安装了Windows2.1以及此后的所有Windows。现在,我家里有10台不同的Windows机器在运行,从Windows7Ultimate到各种版本的WindowsServer。我还没有完成Windows8,也不想去那里。我在服务器和各种软件方面都有UNIX经验,但它并不是我的首选环境。但是,我想我正在转换。我试图假装使用Cygwin和MSYS在Windows下运行UNIX。我的目的是搭建一个开发环境。两者都让我失望了。我花了比开发更多的时间来解决一系列技术问题。这是NotAcceptable。到目前为止,我的Ruby
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
我给自己买了一个新的8gigUSBkey,我正在寻找一个合适的解决方案来拥有一个可移植RoR环境来学习。我在谷歌上搜索了一下,发现了一些可能性,但我很想听听一些现实生活中的经历和意见。谢谢! 最佳答案 我喜欢InstantRails,非常容易使用,无需安装程序,也不会修改您的系统环境。 关于ruby-on-rails-可移植RubyonRails环境,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/q
在我的双语Rails4应用程序中,我有一个像这样的LocalesController:classLocalesController用户可以通过此表单更改其语言环境:deflocale_switcherform_tagurl_for(:controller=>'locales',:action=>'change_locale'),:method=>'get',:id=>'locale_switcher'doselect_tag'set_locale',options_for_select(LANGUAGES,I18n.locale.to_s)end这有效。但是,目前用户无法通过URL更改
我在跑Fastlane(适用于iOS的持续构建工具)以执行用于解密文件的自定义shell脚本。这是命令。sh"./decrypt.shENV['ENCRYPTION_P12']"我想不出将环境变量传递给该脚本的方法。显然,如果我将密码硬编码到脚本中,它就可以正常工作。sh"./decrypt.shmypwd"有什么建议吗? 最佳答案 从直接Shell中扩展假设这里的sh是一个faSTLane命令,它以给定的参数作为脚本文本调用shell命令:#asafastlanedirectivesh'./decrypt.sh"$ENCRYPTI
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3