Hive由Facebook开发,用于解决海量结构化日志的数据统计,于2008年贡献给 Apache 基金会。
Hive是基于Hadoop的数据仓库工具,可以将结构化数据映射为一张表,提供类似SQL语句查询功能
本质:将Hive SQL转化成MapReduce程序。
项目 | Hive | 关系型数据库 |
数据存储 | HDFS | 磁盘 |
查询语言 | HQL | SQL |
处理数据规模 | 大 | 小 |
分区 | 支持 | 支持 |
扩展性 | 高 | 非常有限 |
数据写入 | 支持批量导入/单条写入 | 支持批量导入/单条写入 |
索引 | 0.7版本后添加了索引(不怎么使用) | 支持复杂索引 |
执行延迟 | 高 | 低 |
数据加载模式 | 读时模式(快) | 写时模式(慢) |
应用场景 | 海量数据查询 | 实时查询 |
PS:
读时模式: Hive 在加载数据到表中的时候不会校验.
写时模式: Mysql 数据库插入数据到表的时候会进行校验.Hive只适合用来做海量离线的数据统计分析,也就是数据仓库。
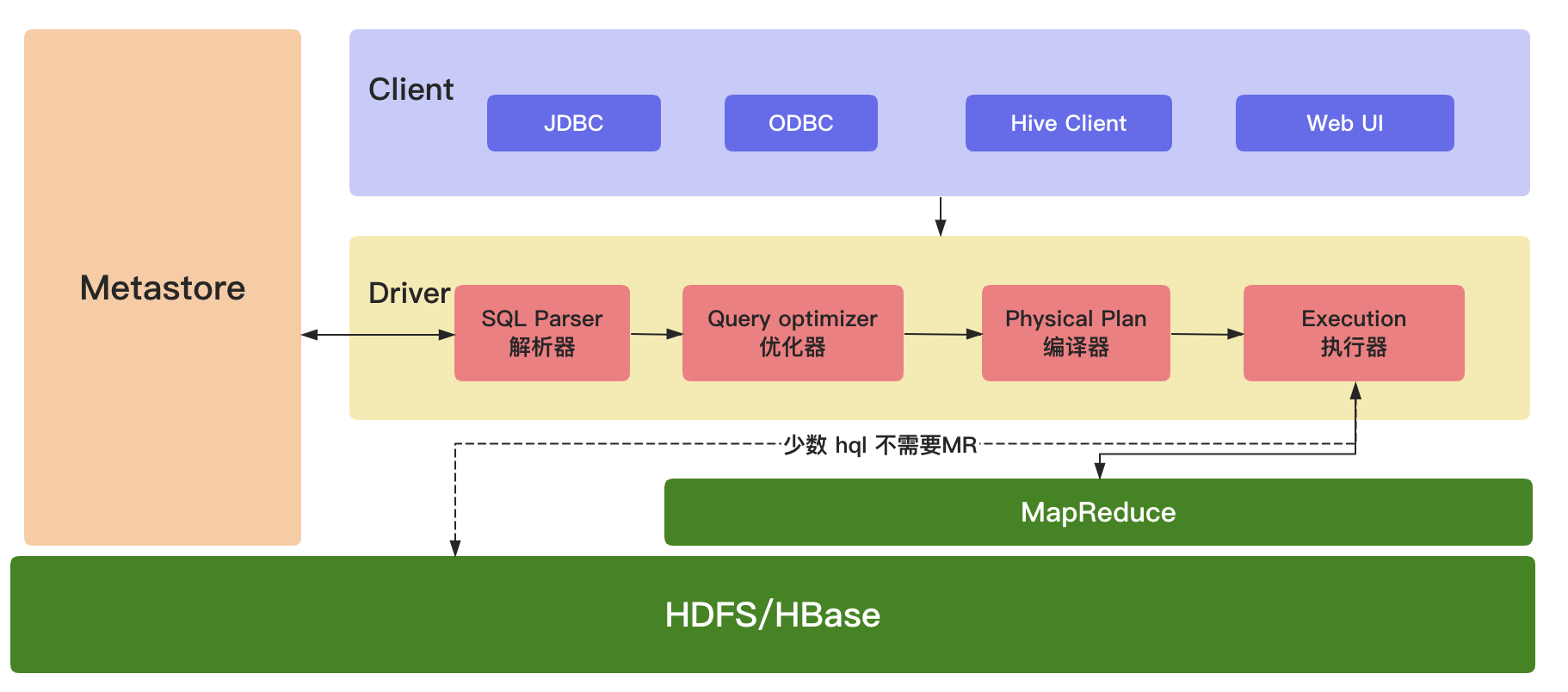
(1)Client(用户接口)
JDBC(java访问Hive);ODBC(Open Database Connectivity);Client(hive shell);WEBUI(浏览器访问Hive)
(2)元数据(MetaStore)
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段,标的类型(表是否为外部表)、表的数据所在目录。这是数据默认存储在Hive自带的derby数据库中,推荐使用MySQL数据库存储MetaStore。
(3)Hadoop/HBase集群
使用 HDFS 进行存储数据,使用 MapReduce 进行计算。
(4)Driver(驱动器)
解析器(SQL Parser):将SQL字符串换成抽象语法树AST,对AST进行语法分析,判断表是否存在、字段是否存在、SQL语义是否有误。
优化器(Query Optimizer):将逻辑计划进行优化。
编译器(Physical Plan):将AST编译成逻辑执行计划。
执行器(Execution):把执行计划转换成可以运行的物理计划。对于Hive来说默认就是Mapreduce任务。PS:从 hive-0.10.x开始,少数 Hql 不需要执行 MR,但是需要开启参数:
hive.fetch.task.conversion = more添参数后,简单的查询,如select,不带count,sum,group by的 SQL,都不走map/reduce,直接读取hdfs文件进行filter过滤。
Spark SQL主要用于结构型数据处理,它的前身为Shark,在Spark 1.3.0版本后才成长为正式版,可以彻底摆脱之前Shark必须依赖HIVE的局面。与过去的Shark相比,一方面Spark SQL提供了强大的DataFrame API,另一方面则是利用Catalyst优化器,并充分利用了Scala语言的模式匹配与quasiquotes,为Spark提供了更好的查询性能。
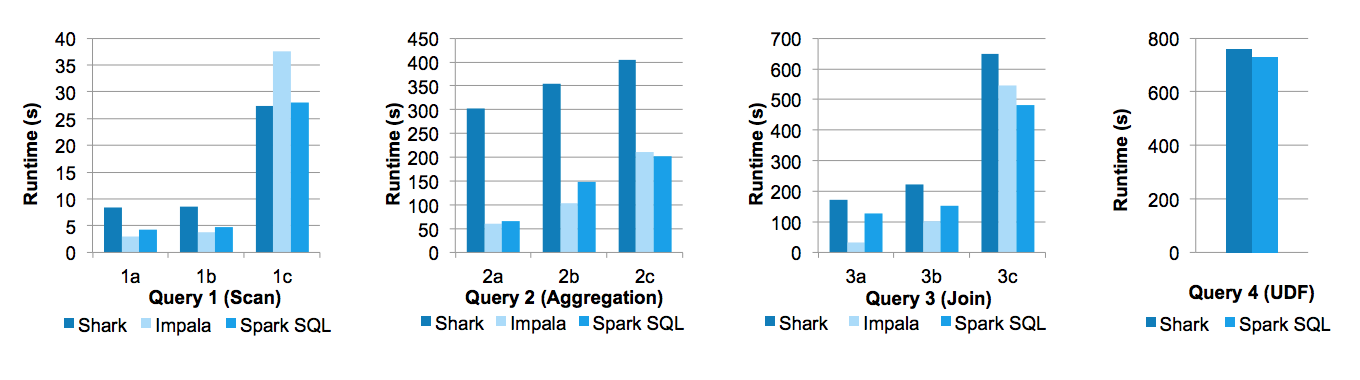
在Databricks工程师撰写的论文《Spark SQL: Relational Data Processing in Spark》中,给出了Spark SQL与Shark以及Impala三者间的性能对比,如下图所示:
Michael Armbrust、Yin Huai等人写的博客《Deep Dive into Spark SQL’s Catalyst Optimizer》简单介绍了Catalyst的优化机制。
Spark SQL 查询与 Spark 程序集成。Spark SQL 允许我们使用 SQL 或可在 Java、Scala、Python 和 R 中使用的 DataFrame API 查询 Spark 程序中的结构化数据。要运行流式计算,开发人员只需针对 DataFrame / Dataset API 编写批处理计算, Spark 会自动增加计算量,以流式方式运行它。这种强大的设计意味着开发人员不必手动管理状态、故障或保持应用程序与批处理作业同步。相反,流式作业总是在相同数据上给出与批处理作业相同的答案。
DataFrames 和 SQL 支持访问各种数据源的通用方法,如 Hive、Avro、Parquet、ORC、JSON 和 JDBC。这将连接这些来源的数据。这对于将所有现有用户容纳到 Spark SQL 中非常有帮助。
Spark SQL 对当前数据运行未经修改的 Hive 查询。它重写了 Hive 前端和元存储,允许与当前的 Hive 数据、查询和 UDF 完全兼容。
连接是通过 JDBC 或 ODBC 进行的。JDBC和 ODBC 是商业智能工具连接的行业规范。
Spark SQL 结合了基于成本的优化器、代码生成和列式存储,在使用 Spark 引擎计算数千个节点的同时使查询变得敏捷,提供完整的中间查询容错。Spark SQL 提供的接口为 Spark 提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL 使用这些额外信息来执行额外优化。Spark SQL 可以直接从多个来源(文件、HDFS、JSON/Parquet 文件、现有 RDD、Hive 等)读取。它确保现有 Hive 查询的快速执行。
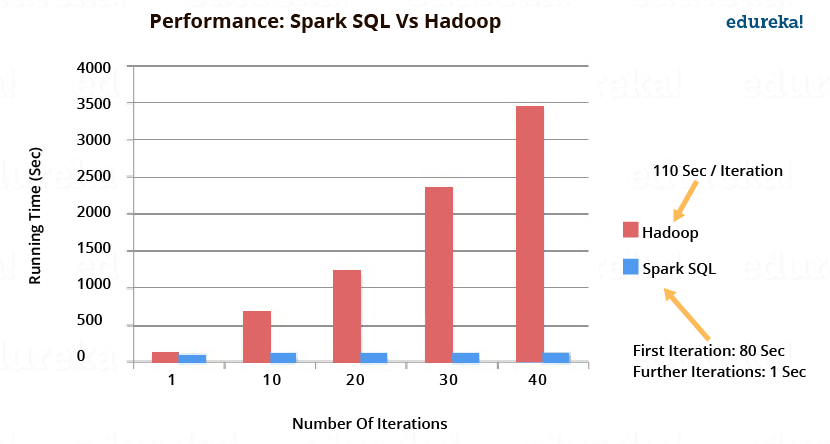
下图描述了 Spark SQL 与 Hadoop 相比的性能。Spark SQL 的执行速度比 Hadoop 快 100 倍。
实时计算 & 离线批量计算。
Hive on Spark是由Cloudera发起,由Intel、MapR等公司共同参与的开源项目,其目的是把Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算。
通过该项目,可以提高Hive查询的性能,同时为已经部署了Hive或者Spark的用户提供了更加灵活的选择,从而进一步提高Hive和Spark的普及率。参考:https://www.cnblogs.com/wcwen1990/p/7899530.html
参考:http://people.csail.mit.edu/matei/papers/2015/sigmod_spark_sql.pdf
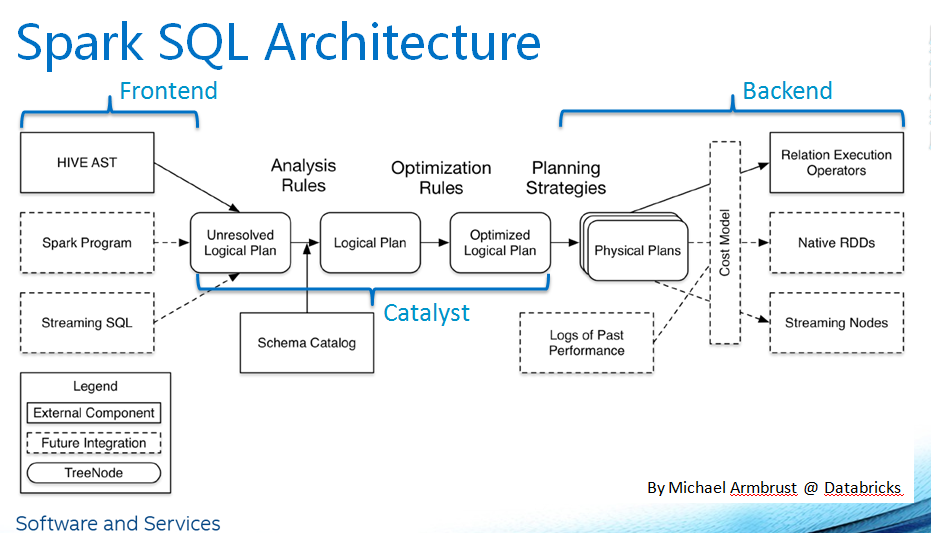
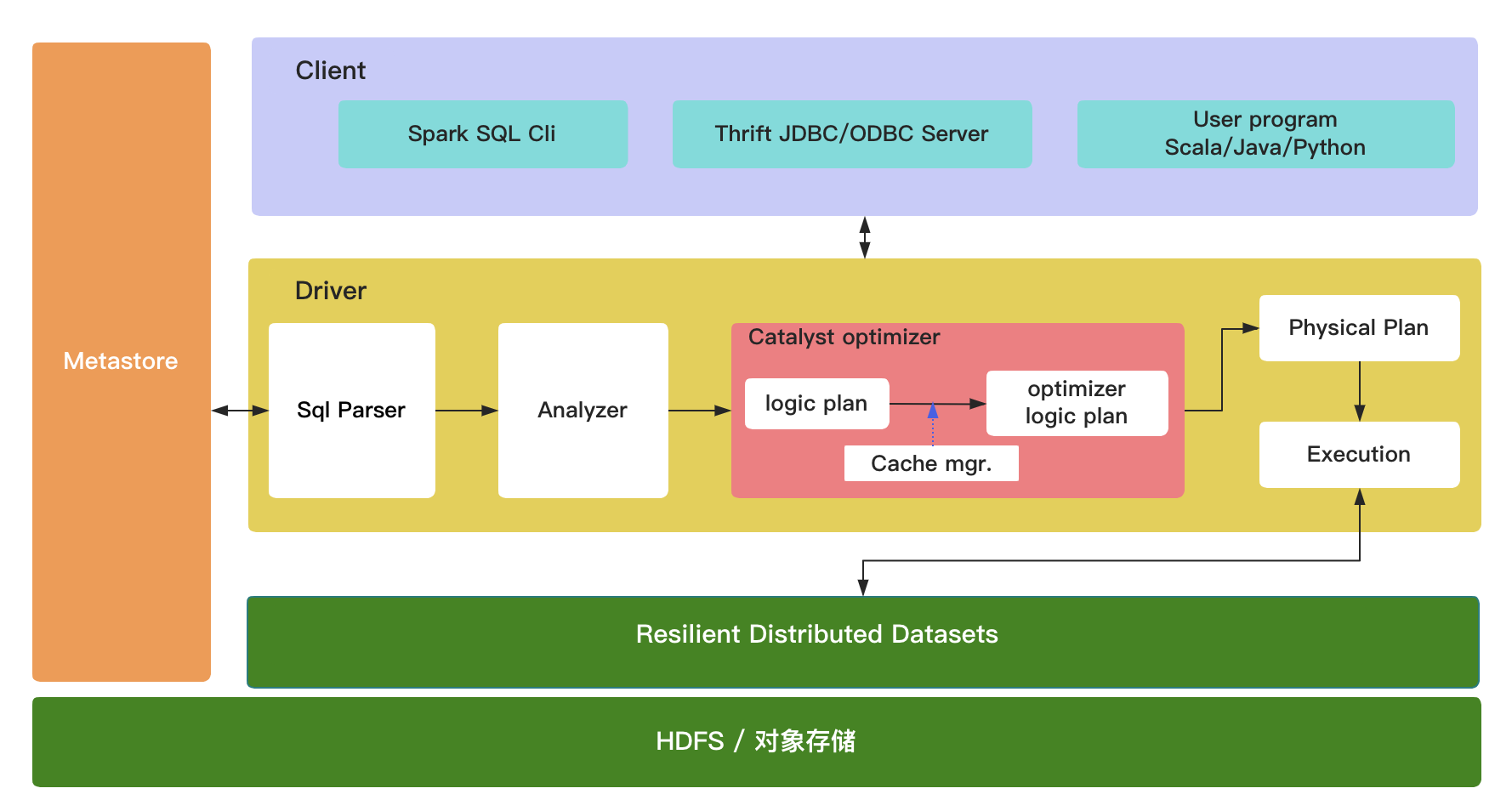
(1)Client
执行 bin/spark-sql 或者 bin/spark-shell 进入客户端
jdbc/odbc 的server
用户编程的 jar 包
(2)Metastore
元数据管理中心,即为 Hive 的metastore
(3)Driver
1)sql parser:基于antlr框架对 sql解析,生成抽象语法树
2)Analyzer:通过分析器,结合catalog,把logical plan和实际的数据绑定起来,将unresolve logical plan生成 logical plan
3)Catalyst optimizer
a.Logic plan:由 Analyzer 生成,称为 Unresolved Logical Plan
b.Cache Manager:缓存替换:替换有相同结果的 logical plan,在分析器之后,optimizer logic plan 之前发生
c.Optimizer logic plan:基于规则的优化;优化执行器 RuleExecutor 生成 spark plan
4)Physical plan:获取一个逻辑计划,并使用与 Spark执行引擎匹配的物理操作来生成一个或多个物理计划,然后使用CBO的模型在这个多个物理计划中选择最优的那个
5)Execution:使用 QueryExecution 执行物理计划,此时则调用 SparkPlan的execute() 方法,生成 RDD
(4)RDD
弹性分布式数据集,注意其5大特性:一个分区列表、func 作用于每个分区、宽窄依赖、就近原则、tuple
(5)HDFS/对象存储(如OSS、S3、COS、OBS 等)
HDFS: Hadoop Distributed File System -- Apache
OSS: Object Storage Service -- 阿里云
COS: CloudObjectStorage -- 腾讯云
OBS: Object Storage Service -- 华为云
S3: Simple Storage Service -- Amazon
都支持ThriftServer服务,为JDBC提供解决方案
都支持静态分区、动态分区
都支持多种文件存储格式:text、parquet、orc等
都支持 UDF 函数Spark SQL 是 Spark 的一个库文件
Spark SQL 中 schema 是自动推断的
Spark SQL 支持标准 SQL 语句,也支持 HQL 语句等(即支持SQL方式开发,也支持HQL开发,还支持函数式编程(DSL)实现SQL语句)
Spark SQL 支持 Spark Datasets 和 Spark DataFrames 的操作,而 Hive SQL 仅支持 Hive 表的操作。
Spark SQL 支持使用 Spark API 和 SQL 同时进行数据处理,而 Hive SQL 仅支持 SQL 操作。
Hive中必须有元数据,一般由 MySql 管理,必须开启 metastore 服务
Hive 中在建表时必须明确使用 DDL 声明 schema
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
大家好,我是辣条。现在短视频可谓是一骑绝尘,吃饭的时候、休息的时候、躺在床上都在刷短视频,今天给大家带来python爬虫进阶:美拍视频地址加密解析。短视频js逆向解析抓取目标工具使用重点学习内容项目思路解析抓取目标目标网址:美拍视频工具使用开发环境:win10、python3.7开发工具:pycharm、Chrome工具包:requests、xpath、base64重点学习内容爬虫采集数据的解析过程js代码调试技巧js逆向解析代码Python代码的转换项目思路解析进入到网站的首页挑选你感兴趣的分类根据首页地址获取到进入详情页面的超链接的跳转地址找到对应加密的视频播放地址数据这个数据是静态的网页
一、软件准备虚拟机(操作系统为Linux)中已有MySQL、已部署Hive。本地主机(操作系统为Windows)中下载navicat(我用的是navicatpremium15)。PS:其实用sqlyog也是可以连接虚拟机的Hive数据的。在决定用navicat还是sqlyog之前,可以思考这两个问题:①MySQL和hive的区别;②sqlyog和navicat的区别。对于第一个问题,我理解的最直接的区别是:MySQL的数据可以存储在本地,但是hive的数据一定是存储在分布式文件系统上的。尽管hive的操作数据的命令语法与MySQL非常接近,但hive不是MySQL。对于第二个问题,我理解的最直
目录一、权限控制初体验二、Ranger授权模型一、权限控制初体验A、查看默认的访问策略此时只有rangerlookup用户拥有对所有库、表和函数的访问权限,故理论上其余用户是不能访问任何Hive资源的。B、验证使用fancy用户尝试进行认证,认证成功后,使用beeline客户端连接Hiveserver2使用fancy用户认证,并按照提示输入密码[fancy@hadoop102~]$kinitfancy登录beeline客户端[fancy@hadoop102~]$beeline-u"jdbc:hive2://hadoop102:10000/;principal=hive/hadoop102@EX
文章目录前言一、Spring是什么?二、什么是容器?三、什么是IoC?3.1初始loC3.2举例解释loC3.3 SpringIoC思想的体现四、什么是DI?4.1DI的概念4.2 Ioc和DI的区别总结前言今天我们将进入到有关spring的认识当中,要使用它的前提就是要认识并熟悉它,上一节我们介绍了有关maven的配置,必须要配置完成后,才能完成我们后面的学习工作,让我们进入到今天的学习当中吧!!!!!!!!!一、Spring是什么?概念:我们通常所说的Spring指的是SpringFramework(Spring框架),它是⼀个开源框架,有着活跃⽽庞⼤的社区,这就是它之所以能⻓久不衰的原因
目录🍊前言🍊:🍈一、宏与函数🍈: 1.宏与函数对比: 2.宏与函数的命名约定:🍓二、预处理操作符🍓: 1.预处理操作符"#": 2.预处理操作符"##":🥝三、条件编译🥝: 1.简述条件编译指令: 2.常见条件编译指令:🍒总结🍒:🛰️博客主页:✈️銮同学的干货分享基地🛰️欢迎关注:👍点赞🙌收藏✍️留言🛰️系列专栏:💐【进阶】C语言学习 🧧 C语言学习🛰️代码仓库:🎉VS2022_C语言仓库 家人们更新不易,你们的👍点赞👍和⭐关注⭐真的对我真重要,各位路过的友友麻烦多多点赞关注,欢迎你们的私信提问,感谢你们的转发!
目录一、get_json_object使用二、使用案例三、源码分析四、总结大家好,我是老六。在数据开发中,我们有大量解析json串的需求,我们选用的UDF函数无非就是:get_json_object和json_tuple。但是在使用get_json_object函数过程中,老六发现get_json_object无法解析key为中文的key:value对。带着这个问题,老六通过源码研究了get_json_object这个函数,探索其中奥秘。一、get_json_object使用语法:get_json_object(json_string,'$.key')说明:解析json的字符串json_str
博学之,审问之,慎思之,明辨之,笃行之🏂hiveonspark搭建好后,任务提交会有问题,因为通过hive会话提交的任务一直存在且不会结束(除非关掉这个hive会话),根本原因是这些任务提交到了Yarn的同一个队列中,前面的任务没有执行完毕后面的任务不会执行,所以解决办法是增加一个Yarn队列,指定任务提交的队列,这样就不会出现任务的阻塞。目录一、情景复现二、原因三、Yarn队列配置—增加队列1.情景复现:搭建好hiveonspark后,在命令行直接进入hive会话,提交任务后,在ResourceManager上jps查看进程可以看到有个进程ApplicationMaster一直存在,打开Re
文章目录一、启动hive1.hive启动的前置条件2.启动方式一:hive命令3.方式二:使用jdbc连接hive二、Hive常用交互命令1.hive-help命令2.hive-e命令3.hive-f命令4.退出hive窗口5.在hive窗口中执行dfs-ls/;三、Hive语法1.DDL语句1.1创建数据库1.2两种方式查询数据库1.3显示数据库信息1.4切换数据库1.5修改数据库配置信息1.6删除数据库1.7创建hive表(重点)1.7.1hive详细的建表语句1.7.2创建hive内部表:1.7.3创建hive外部表:2.DML语句2.1向表中装载数据(Load)2.2Load命令添加o