文章目录
上一章已经讲过什么是注意力,注意力有哪几种???
接下来,讲一下什么叫做自注意力机制??
李宏毅视频讲解:https://www.bilibili.com/video/BV1v3411r78R
PPT:https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf
自注意力机制实际上是注意力机制中的一种,
自注意力机制实际上也是一种网络的构型,它想要解决的问题是网络接收的输入是很多向量,并且向量的大小也是不确定的情况,比如机器翻译(序列到序列的问题,机器自己决定多少个标签),词性标注(Pos tagging一个向量对应一个标签),语义分析(多个向量对应一个标签)等文字处理问题。
Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。
当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,
输入的内容便是Query,Key(例如商品的种类,颜色,描述等),相似度得到匹配的内容(Value)。self-attention中的Q,K,V也是起着类似的作用,在矩阵计算中,点积是计算两个矩阵相似度的方法之一,因此式1中使用了QKT进行相似度的计算。接着便是根据相似度进行输出的匹配,这里使用了加权匹配的方式,而权值就是query与key的相似度。
自注意力计算公式
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
M
a
x
(
Q
K
T
d
)
V
Attention(Q,K,V)=SoftMax(\frac{QK^T}{\sqrt{d}})V
Attention(Q,K,V)=SoftMax(dQKT)V
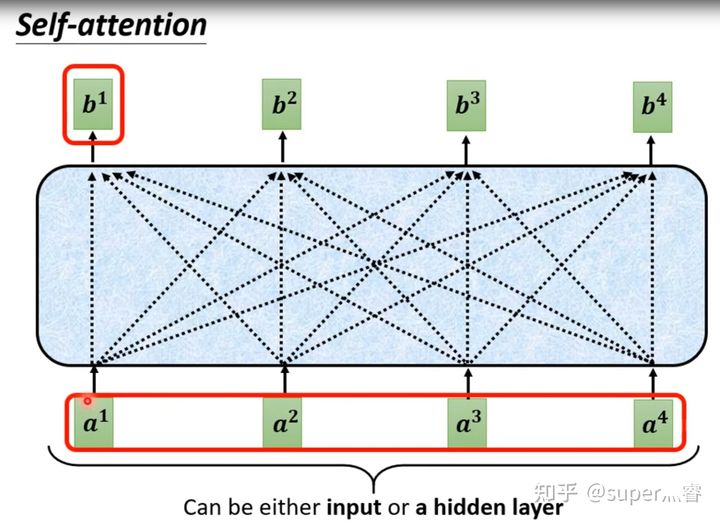
现在我们有一组一维的向量,那么向量b是如何产生的呢?
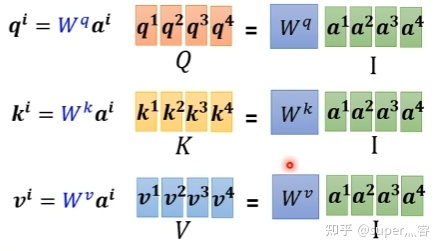
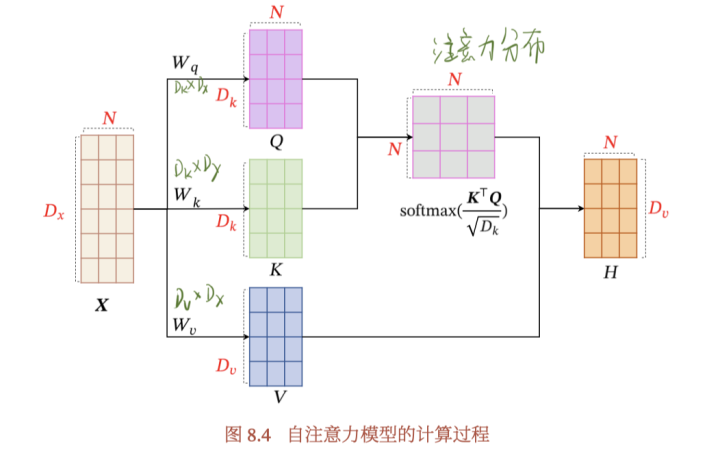
步骤1: 对于每个向量 a a a,分别乘上三个系数 w q , w k , w v w^q,w^k,w^v wq,wk,wv,得到 q , k , v q,k,v q,k,v三个值
q i = w q ⋅ a i q^i=w^q\cdot a^i qi=wq⋅ai写成向量形式 Q = W q ⋅ I Q=W^q\cdot I Q=Wq⋅I
k i = w q ⋅ a i k^i=w^q\cdot a^i ki=wq⋅ai写成向量形式 K = W k ⋅ I K=W^k\cdot I K=Wk⋅I
v i = w q ⋅ a i v^i=w^q\cdot a^i vi=wq⋅ai写成向量形式 V = V q ⋅ I V=V^q\cdot I V=Vq⋅I
得到的Q,K,V分别表示query,key和value。这3个w的参数就是我们需要学习的参数
步骤2:
利用得到的
Q
Q
Q和
K
K
K计算每两个输入向量之间的相关性,也就是计算attention的值
α
\alpha
α,
α
\alpha
α的计算方法有多种,通常采用点乘的方式。
α i , j = q i ⋅ k j \alpha_{i,j}=q^i\cdot k^j αi,j=qi⋅kj写成向量形式: A = K T ⋅ Q A=K^T\cdot Q A=KT⋅Q
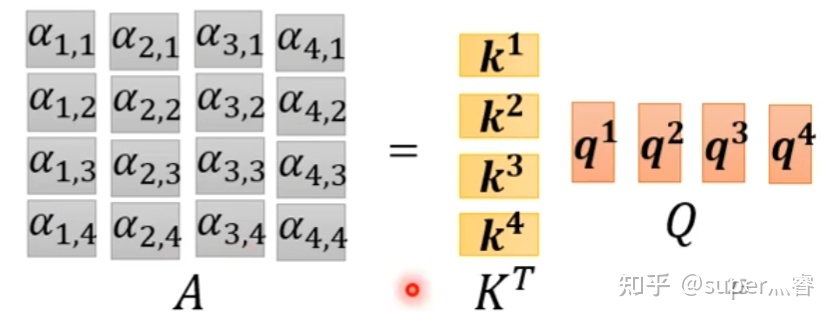
矩阵A中的每一个值记录了对应的两个输入向量的Attention的大小 α \alpha α
Q K T QK^T QKT代表 n n n个查询向量(样本特征)与 n n n个键向量(信息特征)之间的相似度。
如果 A A A的第一行为 [ 2 , 5 , 3 ] [2,5,3] [2,5,3],则代表第一个样本与第一、二、三条信息之间的相似度2,5,3
步骤3:
对A矩阵进行softmax操作或者relu操作得到A’。通常为 S o f t m a x ( ⋅ / d k ) Softmax(\cdot/\sqrt{d_k}) Softmax(⋅/dk)
A ′ A^\prime A′就是各个样本与各条信息间相关或相似程度的分布
对于上一段提到的例子,我们简单地令 w ( x ) = x i ∑ x i w(x)=\frac{x_i}{\sum x_i} w(x)=∑xixi,得到 [ 0.2 , 0.5 , 0.3 ] [0.2,0.5,0.3] [0.2,0.5,0.3]。这代表第一个样本与第一、二、三条信息的相关或相似度分别为20%、50%和30%。
步骤4:利用得到的 A ′ A^\prime A′和 V V V计算每个输入向量a对应的self-attention层的输出向量b:
b i = ∑ j = 1 n v i ⋅ α i , j ′ b_i=\sum_{j=1}^nv_i\cdot \alpha_{i,j}^\prime bi=∑j=1nvi⋅αi,j′,写成向量形式 O = V ⋅ A ′ O=V\cdot A^\prime O=V⋅A′
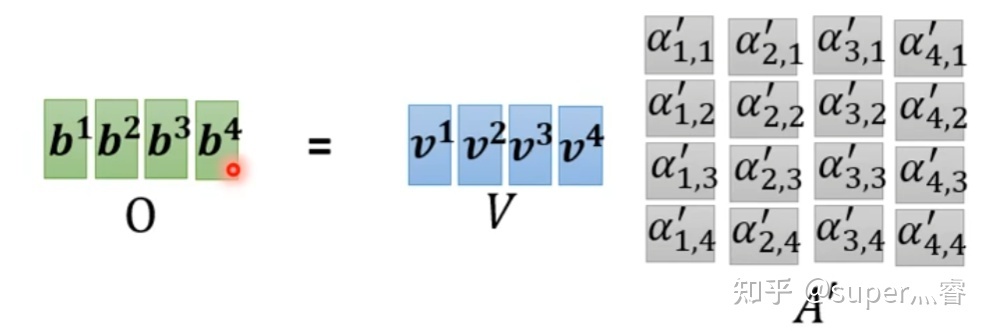
A t t ( Q , K , V ) Att(Q,K,V) Att(Q,K,V)即值向量(信息)的加权和,权值为各个样本与各条信息间相关或相似程度的分布,这就是自注意力的最终结果。
拿第一个向量a1对应的self-attention输出向量b1举例,它的产生过程如下:
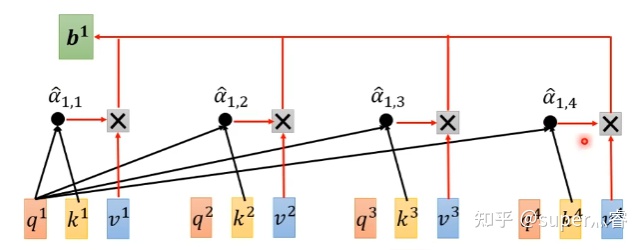
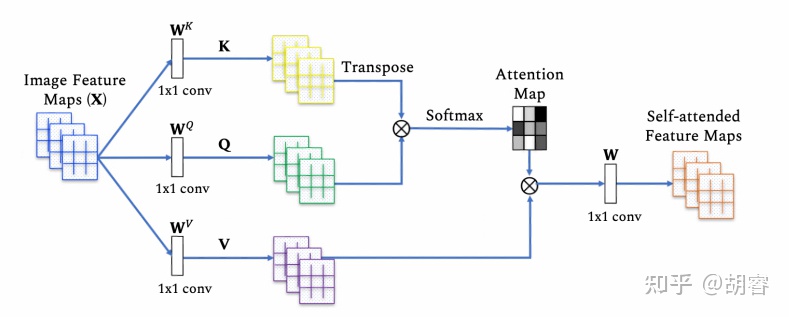
代码来自SAGAN这篇论文:
自注意力代码如下
import numpy as np
import torch
from einops import rearrange
from torch import nn
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self, in_dim, activation=None):
super(Self_Attn, self).__init__()
# self.chanel_in = in_dim
# self.activation = activation
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
# batch,通道数,宽,高
m_batchsize, C, width, height = x.size() # [1, 16, 32, 32]
# 步骤1, 通过conv 得出q,k
q = self.query_conv(x).view(m_batchsize, -1, width * height).permute(0, 2,
1) # B X CX(N) torch.Size([1, 1024, 2])
k = self.key_conv(x).view(m_batchsize, -1, width * height) # B X C x (*W*H) torch.Size([1, 2, 1024])
# 步骤1, 计算得出v
v = self.value_conv(x).view(m_batchsize, -1, width * height) # B X C X N torch.Size([1, 16, 1024])
# 步骤2, 矩阵的乘法 ,q,k进行相乘,得出特征图
# [batch_size,1024,2]*[batch_size,2,1024]
energy = torch.bmm(q, k) # transpose check [1, 1024, 1024]
# 特征图attention map,通过softmax
attention = self.softmax(energy) # BX (N) X (N) torch.Size([1, 1024, 1024])
# 步骤3,v * 特征图= 注意力
# [1,16,1024] * [1,1024,1024]= torch.Size([1, 16, 1024])
out = torch.bmm(v, attention.permute(0, 2, 1)) # torch.Size([1, 16, 1024])
# 重新resize
out = out.view(m_batchsize, C, width, height) # torch.Size([1, 16, 32, 32])
# 加上残差
out = self.gamma * out + x
return out, attention
if __name__ == '__main__':
# 这个通道数需要 是8的倍数。因为 q,k,v 是使用conv算出的。 输出通道需要大于 8
x = torch.randn(size=(1, 16, 32, 32))
model = Self_Attn(16)
out, attention = model(x)
print(out.shape)
print(attention.shape)
自注意力机制虽然考虑了所有的输入向量,但没有考虑到向量的位置信息。在实际的文字处理问题中,可能在不同位置词语具有不同的性质,比如动词往往较低频率出现在句首。
有学者提出可以通过位置编码(Positional Encoding)来解决这个问题:对每一个输入向量加上一个位置向量e,位置向量的生成方式有多种,通过e来表示位置信息带入self-attention层进行计算。
[2003.09229] Learning to Encode Position for Transformer with Continuous Dynamical Model (arxiv.org)
参考资料
注意力机制 & 自注意力模型 - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/48508221
(1条消息) 机器学习中的自注意力(Self Attention)机制详解_I am zzxn的博客-CSDN博客_自注意力机制公式
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
前言 Slowloris攻击是我在李华峰老师的书——《MetasploitWeb 渗透测试实战》里面看的,感觉既简单又使用,现在这种攻击是很容易被防护的啦。不过我也不敢真刀实战的去试,只是拿个靶机玩玩罢了。 废话还是写在结语里面吧。(划掉)结语可以不看(划掉)Slowloris攻击的原理 Slowloris是一种资源消耗类DoS攻击,它利用部分HTTP请求进行操作。也叫做慢速攻击,这里的慢速并不是说发动攻击慢,而是访问一条链接的速度慢。Slowloris攻击的功能是打开与目标Web服务器的连接,然后尽可能长时间的保持这些连接打开。如果由多台电脑同时发起Slo
我正在使用Ruby-Tk为OSX开发一个桌面应用程序,我想为该应用程序提供一个AppleEvents接口(interface)。这意味着应用程序将定义它将响应的AppleScript命令的字典(对应于发送到应用程序的Apple事件),并且用户/其他应用程序可以使用AppleScript命令编写Ruby-Tk应用程序的脚本。其他脚本语言支持此类功能——Python通过位于http://appscript.svn.sourceforge.net/viewvc/appscript/py-aemreceive/的py-aemreceive库和Tcl通过位于http://tclae.source
Method#unbind返回对该方法的UnboundMethod引用,稍后可以使用UnboundMethod#bind将其绑定(bind)到另一个对象.classFooattr_reader:bazdefinitialize(baz)@baz=bazendendclassBardefinitialize(baz)@baz=bazendendf=Foo.new(:test1)g=Foo.new(:test2)h=Bar.new(:test3)f.method(:baz).unbind.bind(g).call#=>:test2f.method(:baz).unbind.bind(h).
目录一、原理部分1、什么是串行通信(1)并行通信与串行通信(2)串行通信的制式(3)串行通信的主要方式 2、配置串口(1)SCON和PCON:串行口1的控制寄存器(2)SBUF:串行口数据缓冲寄存器 (3)AUXR:辅助寄存器编辑(4)ES、PS:与串行口1中断相关的寄存器(5)波特率设置 3、串口框架编写二、程序案例一、原理部分1、什么是串行通信(1)并行通信与串行通信微控制器与外部设备的数据通信,根据连线结构和传送方式的不同,可以分为两种:并行通信和串行通信。并行通信:数据的各位同时发送与接收,每个数据位使用一条导线,这种方式传输快,但是需要多条导线进行信号传输。串行通信:数据一位一
例如,我一直看到称为String#split的方法,但从未见过String.split,这似乎更合乎逻辑。或者甚至可能是String::split,因为您可以认为#split位于String的命名空间中。当假定/隐含类(#split)时,我什至单独看到了该方法。我知道这是ri中识别方法的方式。哪个先出现?例如,这是为了区分方法和字段吗?我还听说这有助于区分实例方法和类方法。但这从哪里开始呢? 最佳答案 不同之处在于您如何访问这些方法。类方法使用::分隔符来表示消息可以发送到类/模块对象,而实例方法使用#分隔符表示消息可以发送到实例对
1、为什么压缩的原始数据一般采用YUV格式(1)利用人对图片感觉的生理特性,对于亮度信息比较敏感,对于色度信息不太敏感,所以视频编码是将Y分量和UV分量分开来编码,并且可以减少UV分量.2、视频压缩原理(1)空间冗余:图像相邻像素之间的相关性,比如一帧图片被划分成多个16x16的块之后,相邻的块之间有很多明显的相似性。(2)时间冗余:时间相差较近的两张图片变化较小。(3)视觉冗余:我们的眼睛对某些细节不太敏感,对图像中的高频信息的敏感度小于低频信息,可以去除一些高频信息。(4)编码冗余:一幅图片中不同像素出现的概率是不同的,对于出现次数较多的像素,用少的位数来编码,对于出现次数较少的像素,用多
Python程序运行原理Python是一种脚本语言,编辑完成的程序,也称源代码,可以直接运行。从计算机的角度看,Python程序的运行过程包含两个步骤:解释器将源代码翻译成字节码(即中间码),然后由虚拟机解释执行。Python程序文件的扩展名通常为.py。在执行时,首先由Python解释器将.py文件中的源代码翻译成中间码,这个中间码是一个扩展名为.pyc的文件,再由Python虚拟机(PythonVirtualMachine,PVM)逐条将中间码翻译成机器指令执行。需要说明的是,pyc文件保存在Python安装目录的pycache文件夹下,如果Python无法在用户的计算机上写人字节码,字节
我正在学习Rails数据库连接池概念。在Rails应用程序中,我将池大小定义为5。我对连接池大小的理解如下。当服务器启动时,rails会自动创建n个在database.yml文件中定义的连接。在我的例子中,它将创建5个连接,因为池大小为5。在每个http请求上,如果需要访问数据库,rails将使用连接池中的可用连接来处理请求。但我的问题是,如果我一次达到1000个请求,那么大部分请求将无法访问数据库连接,因为我的连接池大小只有5个。我上面对rails连接池的理解对吗??谢谢, 最佳答案 目的:数据库连接不是线程安全的;所以Activ