canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元。ps. 目前内部使用的同步,已经支持mysql5.x和oracle部分版本的日志解析
基于日志增量订阅&消费支持的业务:
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间。主要用来备份和数据同步。
binlog 有三种模式:STATEMENT、ROW、MIXED
举例来说,下面的sql
COPYupdate user set age=20
对应STATEMENT模式只有一条记录,对应ROW模式则有可能有成千上万条记录(取决数据库中的记录数)。
mysql的binlog文件长这个样子。
COPYmysql-bin.003831
mysql-bin.003840
mysql-bin.003849
mysql-bin.003858
启用Binlog注意以下几点:
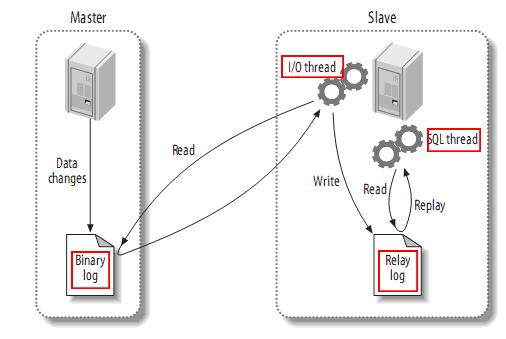
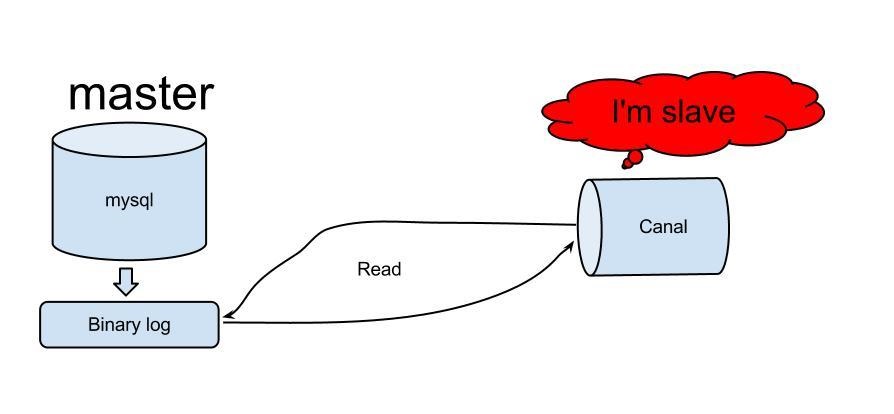
理解了mysql的主从同步的机制再来看canal就比较清晰了,canal主要是听过伪装成mysql从server来向主server拉取数据。
canal的组件化设计非常好,有点类似于tomcat的设计。使用组合设计,依赖倒置,面向接口的设计。
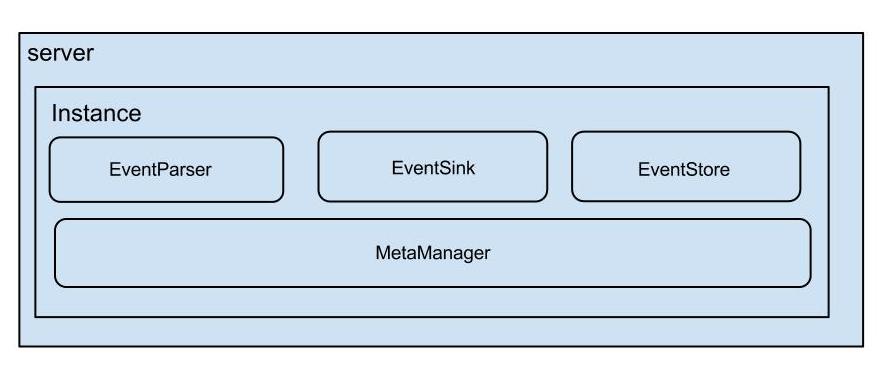
每个canal instance 有多个组件构成。在conf/spring/default-instance.xml中配置了这些组件。他其实是使用了spring的容器来进行这些组件管理的。
这里是一个cannalInstance工作所包含的大组件。截取自
conf/spring/default-instance.xml
COPY<bean id="instance" class="com.alibaba.otter.canal.instance.spring.CanalInstanceWithSpring">
<property name="destination" value="${canal.instance.destination}" />
<property name="eventParser">
<ref local="eventParser" />
</property>
<property name="eventSink">
<ref local="eventSink" />
</property>
<property name="eventStore">
<ref local="eventStore" />
</property>
<property name="metaManager">
<ref local="metaManager" />
</property>
<property name="alarmHandler">
<ref local="alarmHandler" />
</property>
</bean>
eventParser 最基本的组件,类似于mysql从库的dump线程,负责从master中获取bin_log
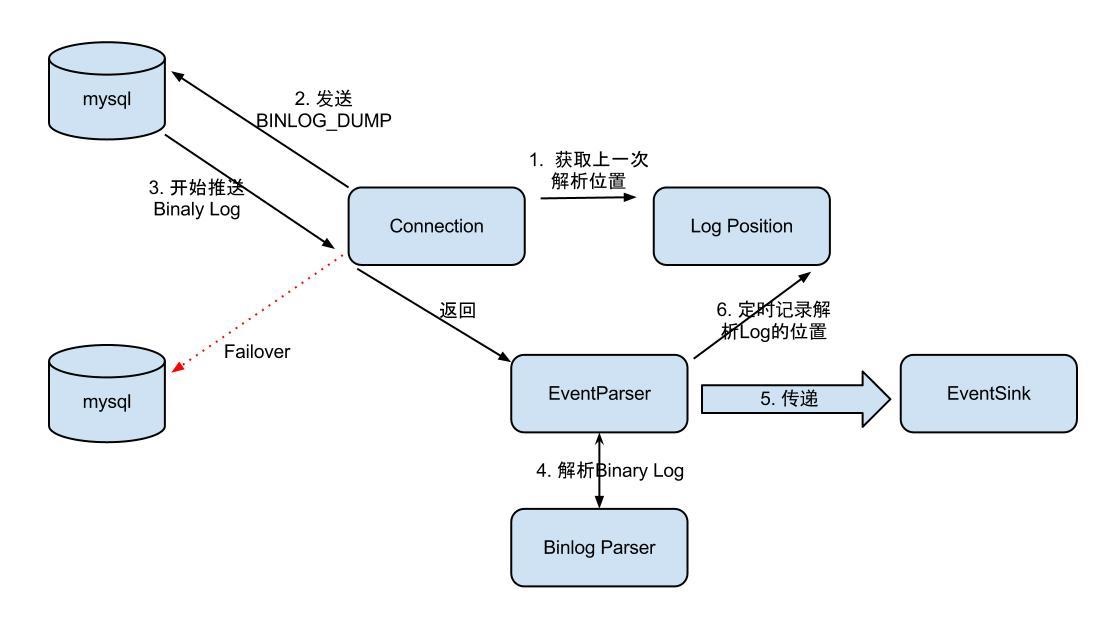
整个parser过程大致可分为几步:
eventSink 数据的归集,使用设置的filter对bin log进行过滤,工作的过程如下。
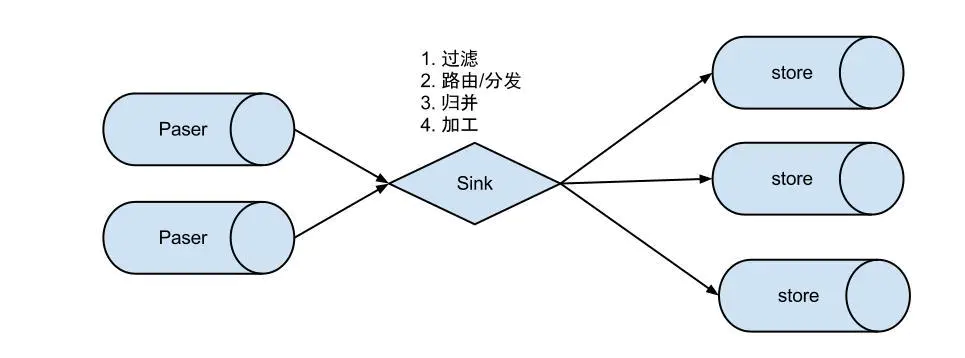
说明:
数据过滤:支持通配符的过滤模式,表名,字段内容等
数据路由/分发:解决1:n (1个parser对应多个store的模式)
数据归并:解决n:1 (多个parser对应1个store)
数据加工:在进入store之前进行额外的处理,比如join
为了合理的利用数据库资源, 一般常见的业务都是按照schema进行隔离,然后在mysql上层或者dao这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过cobar/tddl来解决数据源路由问题。
所以,一般一个数据库实例上,会部署多个schema,每个schema会有由1个或者多个业务方关注
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。
所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并.
eventStore 用来存储filter过滤后的数据,canal目前的数据只在这里存储,工作流程如下
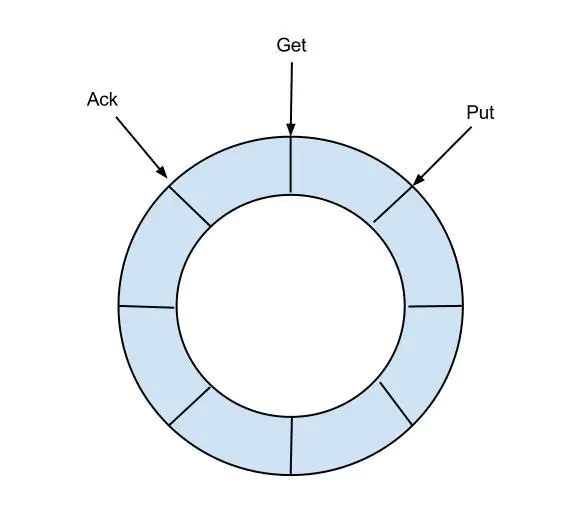
定义了3个cursor
借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:
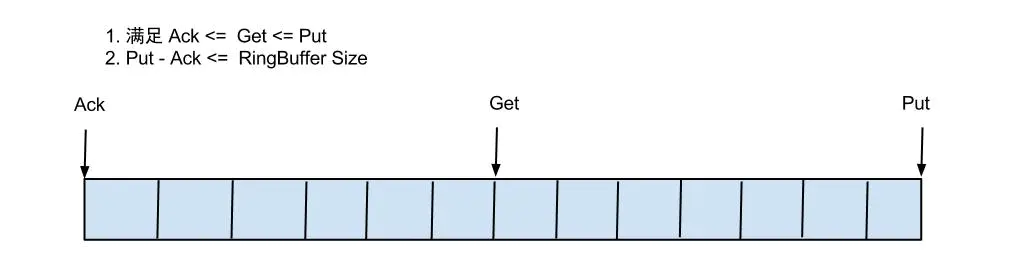
实现说明:
metaManager 用来存储一些原数据,比如消费到的游标,当前活动的server等信息
alarmHandler 报警,这个一般情况下就是错误日志,理论上应该是可以定制成邮件等形式,但是目前不支持
canal采用了spring bean container的方式来组装一个canal instance ,目的是为了能够更加灵活。
canal通过这些组件的选取可以达到不同使用场景的效果,比如单机的话,一般使用file来存储metadata就行了,HA的话一般使用zookeeper来存储metadata。
eventParser 目前只有三种
eventSink 目前只有EntryEventSink 就是基于mysql的binlog数据对象的处理操作
eventStore 目前只有一种 MemoryEventStoreWithBuffer,内部使用了一个ringbuffer 也就是说canal解析的数据都是存在内存中的,并没有到zookeeper当中。
metaManager 这个比较多,其实根据元数据存放的位置可以分为三大类,memory,file,zookeeper
canal是支持HA的,其实现机制也是依赖zookeeper来实现的,用到的特性有watcher和EPHEMERAL节点(和session生命周期绑定),与HDFS的HA类似。
canal的ha分为两部分,canal server和canal client分别有对应的ha实现
server ha的架构图如下
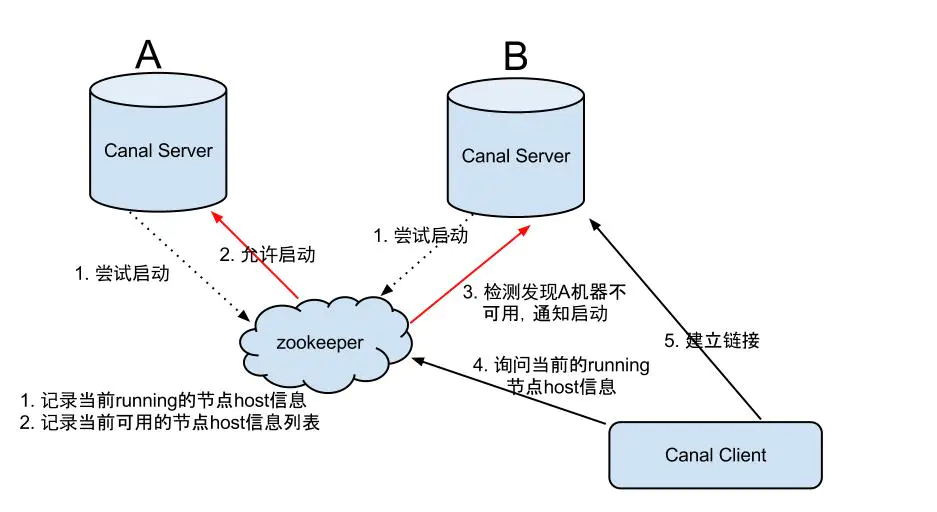
大致步骤:
Canal Client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制.
启动时去MySQL 进行dump操作的binlog 位置确定
工作的过程。在启动一个canal instance 的时候,首先启动一个eventParser 线程来进行数据的dump 当他去master拉取binlog的时候需要binlog的位置,这个位置的确定是按照如下的顺序来确定的(这个地方讲述的是HA模式哈)。
show master status 这个语句会显示当前mysql binlog最后位置的信息,也就是刚写入的binlog所在的位置信息。把这个信息存到内存中(MemoryLogPositionManager),然后拿这个信息去mysql中dump binlog。后面的eventParser的操作就会以内存中(MemoryLogPositionManager)存储的binlog位置去master进行dump操作了。
mysql的
show master status操作
COPYmysql> show master status\G
*************************** 1. row ***************************
File: mysql-bin.000028
Position: 635762367
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 18db0532-6a08-11e8-a13e-52540042a113:1-2784514,
318556ef-4e47-11e6-81b6-52540097a9a8:1-30002,
ac5a3780-63ad-11e8-a9ac-52540042a113:1-5,
be44d87c-4f25-11e6-a0a8-525400de9ffd:1-156349782
1 row in set (0.00 sec
数据在dump回来之后进行的归集(sink)和存储(store)
sink操作是可以支撑将多个eventParser的数据进行过滤filter
filter使用的是instance.properties中配置的filter,当然这个filter也可以由canal的client端在进行subscribe的时候进行设置。如果在client端进行了设置,那么服务端配置文件instance.properties的配置都会失效
sink 之后将过滤后的数据存储到eventStore当中去。
目前eventStore的实现只有一个MemoryEventStoreWithBuffer,也就是基于内存的ringbuffer,使用这个store有一个特点,这个ringbuffer是基于内存的,大小是有限制的(bufferSize = 16 * 1024 也就是16M),所以,当canal的客户端消费比较慢的时候,ringbuffer中存满了就会阻塞sink操作,那么正读取mysql binlog的eventParser线程也会受阻。
这种设计其实也是有道理的。 因为canal的操作是pull 模型,不是producer push的模型,所以他没必要存储太多数据,这样就可以避免了数据存储和持久化管理的一些问题。使数据管理的复杂度大大降低。
上面这些整个是canal的parser 线程的工作流程,主要对应的就是将数据从mysql搞下来,做一些基本的归集和过滤,然后存储到内存中。
canal从mysql订阅了binlog以后主要还是想要给消费者使用。那么binlog是在什么时候被消费呢。这就是另一条主线了。就像咱们做一个toC的系统,管理系统是必须的,用户使用的app或者web又是一套,eventParser 线程就像是管理系统,往里面录入基础数据。canal的client就像是app端一样,是这些数据的消费方。
binlog的主要消费者就是canal的client端。使用的协议是基于tcp的google.protobuf,当然tcp的模式是io多路复用,也就是nio。当我们的client发起请求之后,canal的server端就会从eventStore中将数据传输给客户端。根据客户端的ack机制,将binlog的元数据信息定期同步到zookeeper当中。
配置父目录:
在下面可以看到
COPYcanal
├── bin
│ ├── canal.pid
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
└── conf
├── canal.properties
├── gamer ---目录
├── ww_social ---目录
├── wother ---目录
├── nihao ---目录
├── liveim ---目录
├── logback.xml
├── spring ---目录
├── ym ---目录
└── xrm_ppp ---目录
这里是全部展开的目录
COPYcanal
├── bin
│ ├── canal.pid
│ ├── startup.bat
│ ├── startup.sh
│ └── stop.sh
└── conf
├── canal.properties
├── game_center
│ └── instance.properties
├── ww_social
│ ├── h2.mv.db
│ ├── h2.trace.db
│ └── instance.properties
├── wwother
│ ├── h2.mv.db
│ └── instance.properties
├── nihao
│ ├── h2.mv.db
│ ├── h2.trace.db
│ └── instance.properties
├── movie
│ ├── h2.mv.db
│ └── instance.properties
├── logback.xml
├── spring
│ ├── default-instance.xml
│ ├── file-instance.xml
│ ├── group-instance.xml
│ ├── local-instance.xml
│ ├── memory-instance.xml
│ └── tsdb
│ ├── h2-tsdb.xml
│ ├── mysql-tsdb.xml
│ ├── sql
│ └── sql-map
└── ym
└── instance.properties
canal一个常见应用场景是同步缓存/全文搜索,当数据库变更后通过binlog进行缓存/ES的增量更新。当缓存/ES更新出现问题时,应该回退binlog到过去某个位置进行重新同步,并提供全量刷新缓存/ES的方法,如下图所示。
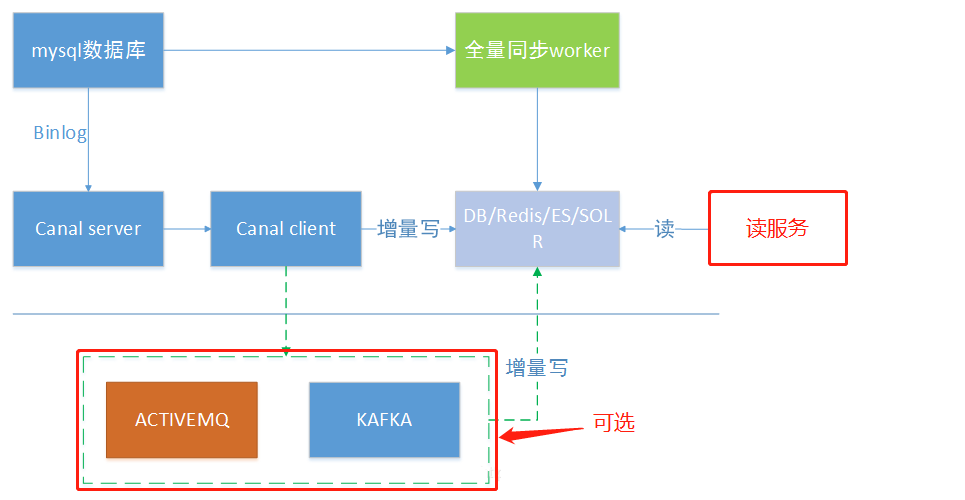
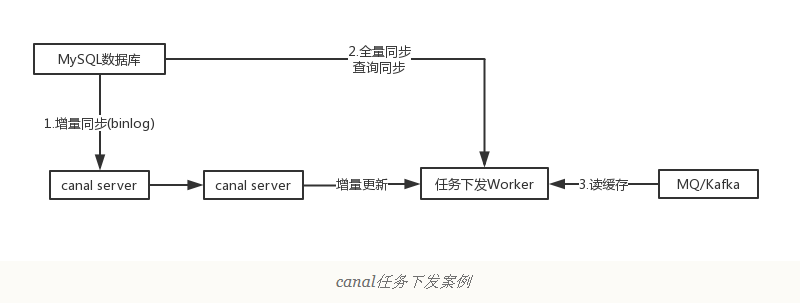
另一种常见应用场景是下发任务,当数据变更时需要通知其他依赖系统。其原理是任务系统监听数据库变更,然后将变更的数据写入MQ/kafka进行任务下发,比如商品数据变更后需要通知商品详情页、列表页、搜索页等先关系统。这种方式可以保证数据下发的精确性,通过MQ发送消息通知变更缓存是无法做到这一点的,而且业务系统中不会散落着各种下发MQ的代码,从而实现了下发归集,如下图所示。
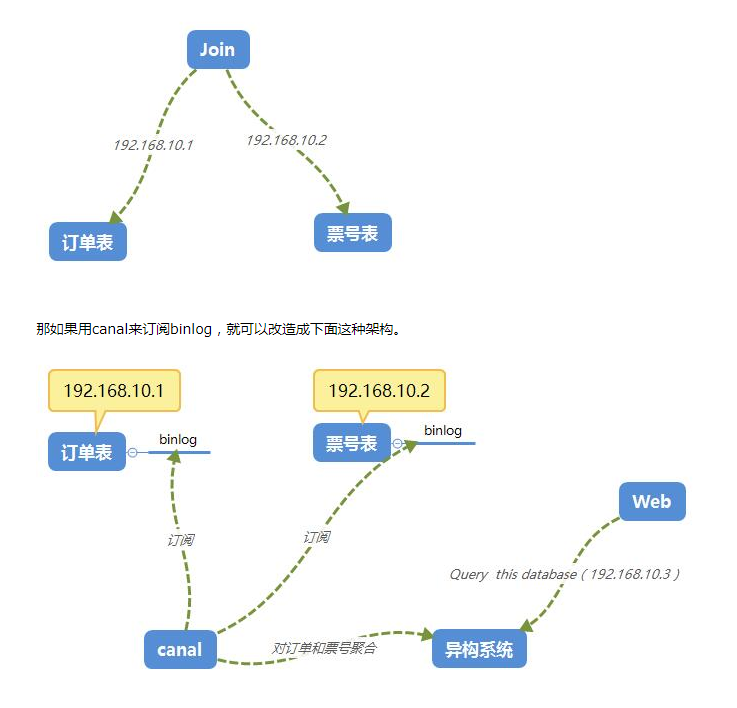
在大型网站架构中,DB都会采用分库分表来解决容量和性能问题,但分库分表之后带来的新问题。比如不同维度的查询或者聚合查询,此时就会非常棘手。一般我们会通过数据异构机制来解决此问题。
所谓的数据异构,那就是将需要join查询的多表按照某一个维度又聚合在一个DB中。让你去查询。canal就是实现数据异构的手段之一。
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我正在使用Maruku,将Markdown(超集)转换为HTML,你知道我该怎么做才能从HTML转换为Markdown吗? 最佳答案 Google发现了一个名为reverse_markdown的ruby脚本.它似乎可以满足您的需求。 关于ruby-on-rails-我需要从HTML转到markdown,有什么建议吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/175162
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva