爬虫获取m3u8视频资源的步骤
目前所要作的流程处理
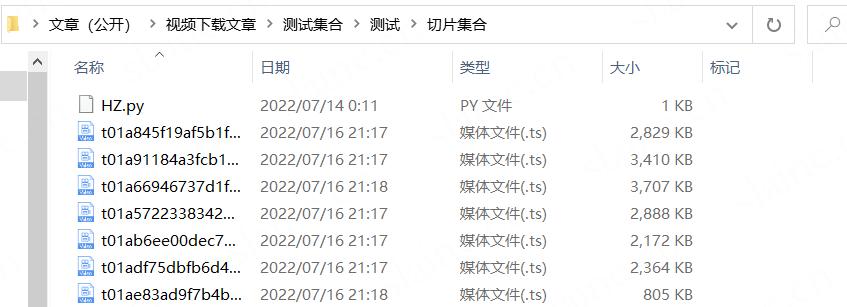
先把m3u8里下载链接批量提取.png
把这几百个切片链接先批量下载.png
再批量改文件后缀为.ts
再按照m3u8文件提取所有不规则链接文件的【顺序】.png
然后改切片的文件名为0001,0002,0003......顺序.png
然后用ffmpeg或者moviepy或者其他工具合并就行.png
看起来也没有那么麻烦…(流汗黄豆)
目前已有材料:爬下来的网页源码和从中获取的m3u8文件

把.m3u8改成.txt格式便于操作
写脚本从原来的m3u8文件中正则表达提取出所有干净的下载链接,将其放到另外一个.txt文件;并且从中下载所有的切片文件
程序代码如下
import requests
import re
from io import BytesIO
import urllib3
import os
t = open("b7729bb022ae5d382df1fd28ac61f1178c3f424c.txt", "r", encoding='utf-8')
data = t.readlines()
t.close()
for line in data:
pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
string = str(line)
url = re.findall(pattern,string)
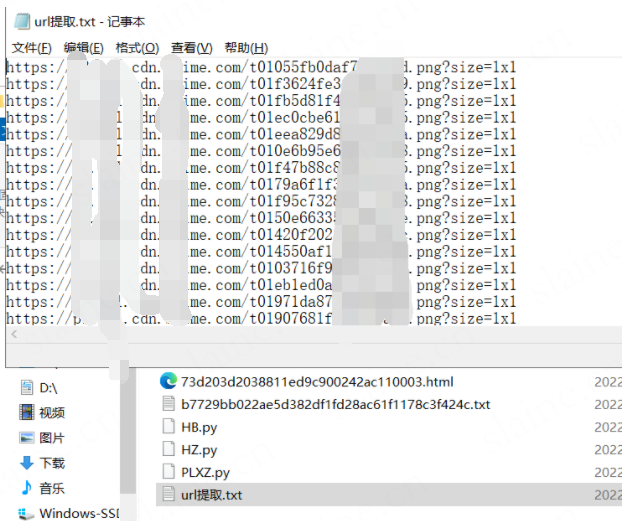
f1 = open("url提取.txt", "a+", encoding='utf-8')
for urls in url:
f1.write(urls+'\n')
f1.close()
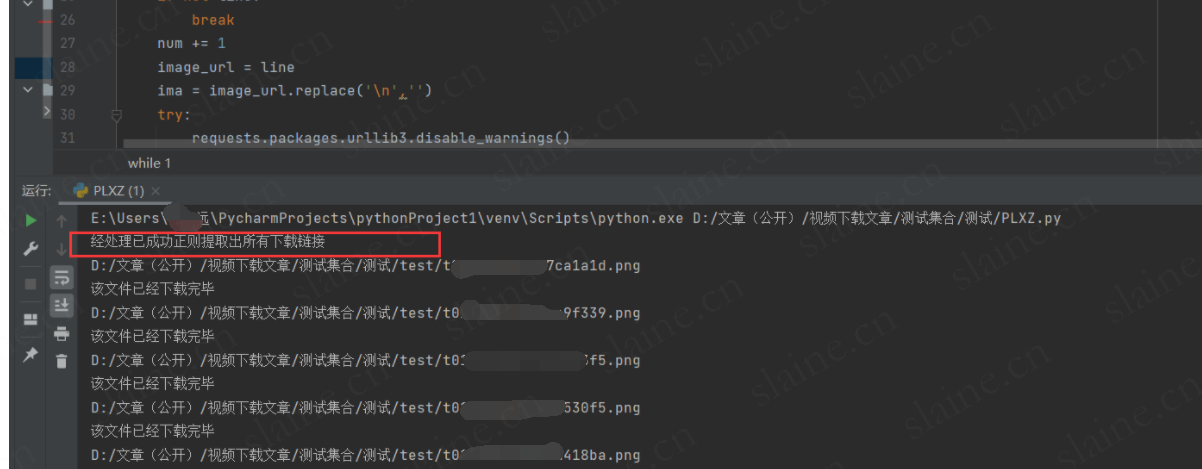
print("经处理已成功正则提取出所有下载链接")
file = open("./url提取.txt") # 打开存放链接的TXT文档
num = 0
while 1:
line = file.readline()
if not line:
break
num += 1
image_url = line
ima = image_url.replace('\n','')
try:
requests.packages.urllib3.disable_warnings()
r = requests.get(ima,verify=False)
path = re.sub("https://p0.ssl.cdn.btime.com/|https://p1.ssl.cdn.btime.com/|https://p2.ssl.cdn.btime.com/|https://p3.ssl.cdn.btime.com/|https://p4.ssl.cdn.btime.com/", "D:/文章(公开)/视频下载文章/测试集合/测试/test/", line)
path = re.sub('\n', '',path)
path = path.replace("?size=1x1", "")
print(path)
f = open(path, "wb")
f.write(r.content) # 将响应对象的内容写下来
print("该文件已经下载完毕")
f.close()
except Exception as e:
print('无法下载,%s' % e)
continue
print("经处理所有切片文件已经下载完毕")
file.close()
正常运行
生成提取出的下载链接
并且下载到指定位置
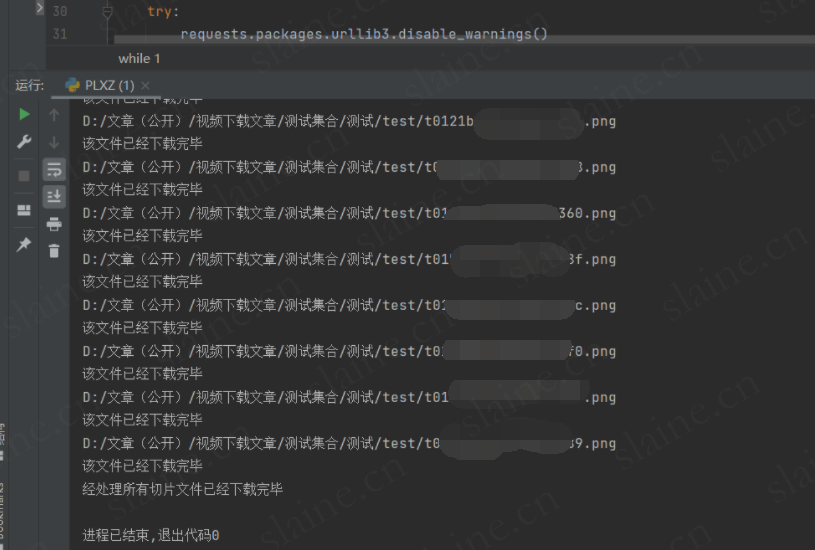
运行结束
程序代码如下
import os
files = os.listdir('.')
for filename in files:
portion = os.path.splitext(filename)
if portion[1] == ".png":
newname = portion[0] + ".ts"
os.rename(filename,newname)
正常运行
接下来就是最关键的根据.m3u8里文件下载链接顺序批量修改文件名的环节
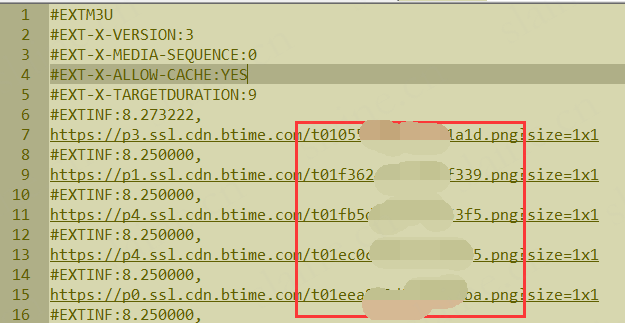
根据已有顺序改文件名为0001,0002,0003…顺序,这对之后的文件合并至关重要
这里就用到刚才提取的url文件
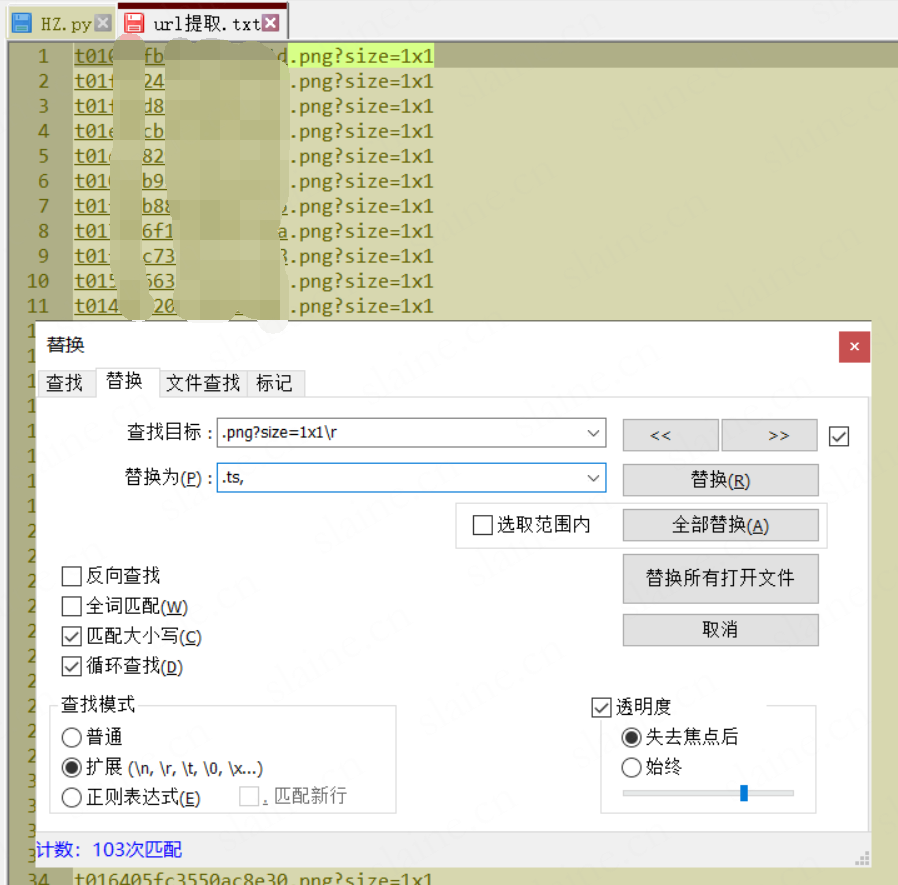
全部替换为.ts结尾且 , 间隔,整理为一行的队列形式

前提需要都准备好了,现在开始批量按照顺序改文件名
程序代码如下
import os
with open("01.txt","r",encoding="utf-8") as f:
list =f.readline().split(",")
list
print("01.txt内文件名数量:",len(list))
filelist=os.listdir(os.getcwd()+"/test")
print("test文件夹内文件数量:",len(filelist))
a=1
for i in list:
old_name=os.getcwd()+"\\test\\"+i
print("修改旧文件:",old_name)
if len(str(a))==1:
temp="000"+str(a)
elif len(str(a))==2:
temp="00"+str(a)
elif len(str(a))==3:
temp="0"+str(a)
else:
temp=str(a)
#print(temp)
new_name=os.getcwd()+"\\test\\"+temp+".ts"
print('新文件:',new_name)
a+=1
os.rename(old_name, new_name) # 用os模块中的rename方法对文件改名
正常运行完成
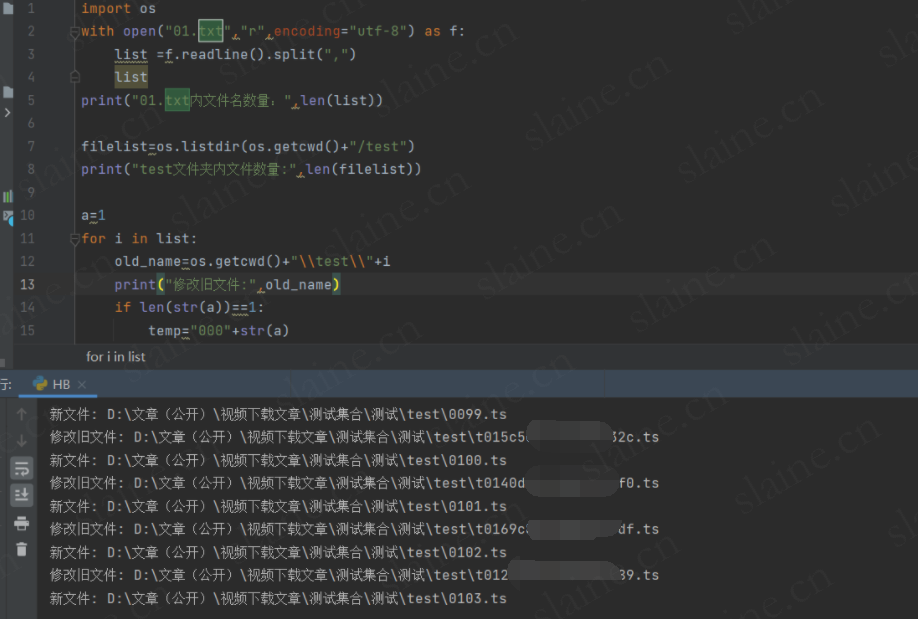
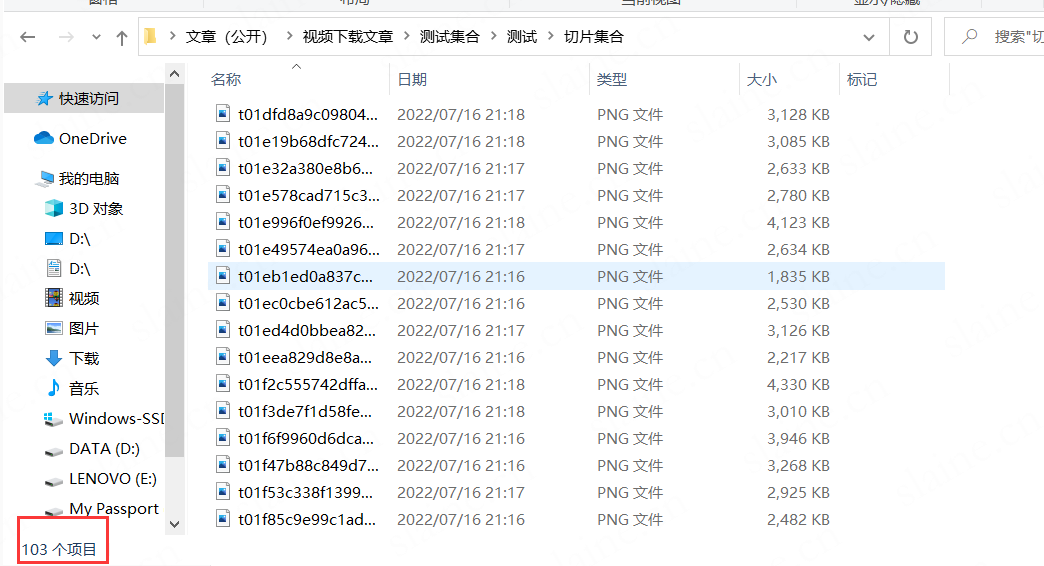
所有视频文件按照指定顺序排列完成
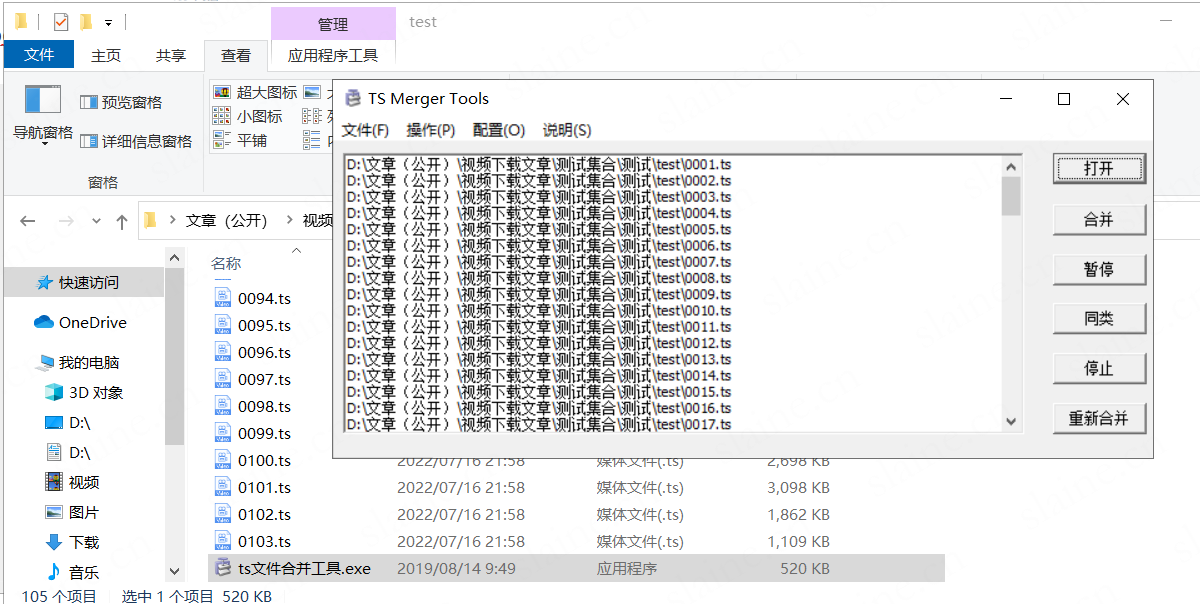
然后用ffmpeg或者moviepy包或者其他工具合并就行
注意:前提必须是按照m3u8里下载链接的顺序改文件名(上操作)后才能正常合并出成品视频,否则会导致视频片段混乱(作者亲测)
这里网上随便一搜就找到了
小东西真不错
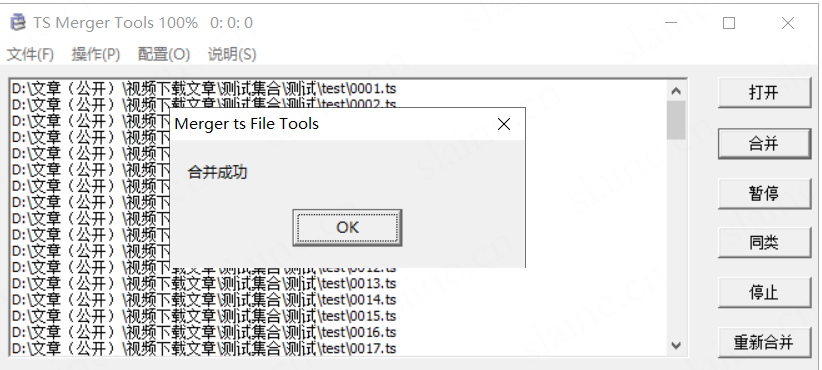
然后就得到成品的文件了
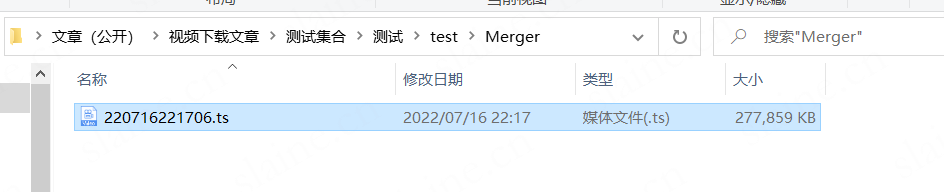
打开看看

内容清晰,完整流畅,达到目的
OVER
老工具人了
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1