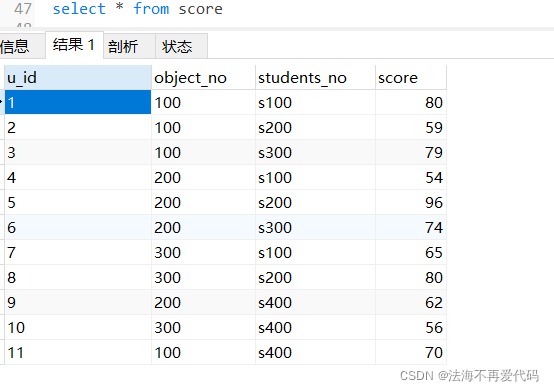
以mysql为例,汇总sql查询最高分、最低分、平均分等sql语句,oracle语法类似,可自行修改以下sql语句
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`u_id` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '编号',
`object_no` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '课程编号',
`students_no` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '学号',
`score` int(11) NULL DEFAULT NULL COMMENT '分数'
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
INSERT INTO `score` VALUES ('1', '100', 's100', 80);
INSERT INTO `score` VALUES ('2', '100', 's200', 59);
INSERT INTO `score` VALUES ('3', '100', 's300', 79);
INSERT INTO `score` VALUES ('4', '200', 's100', 54);
INSERT INTO `score` VALUES ('5', '200', 's200', 96);
INSERT INTO `score` VALUES ('6', '200', 's300', 74);
INSERT INTO `score` VALUES ('7', '300', 's100', 65);
INSERT INTO `score` VALUES ('8', '300', 's200', 80);
INSERT INTO `score` VALUES ('9', '200', 's400', 62);
INSERT INTO `score` VALUES ('10', '300', 's400', 56);
INSERT INTO `score` VALUES ('11', '100', 's400', 70);
SET FOREIGN_KEY_CHECKS = 1;
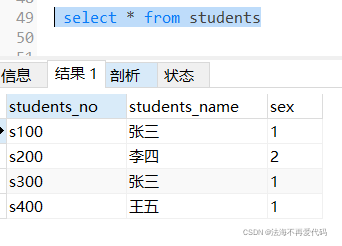
DROP TABLE IF EXISTS `students`;
CREATE TABLE `students` (
`students_no` varchar(12) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '编号',
`students_name` varchar(12) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '姓名',
`sex` varchar(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '性别',
PRIMARY KEY (`students_no`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
INSERT INTO `students` VALUES ('s100', '张三', '1');
INSERT INTO `students` VALUES ('s200', '李四', '2');
INSERT INTO `students` VALUES ('s300', '张三', '1');
INSERT INTO `students` VALUES ('s400', '王五', '1');
SET FOREIGN_KEY_CHECKS = 1;
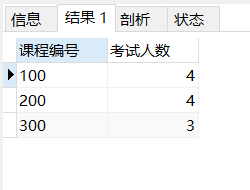
select object_no as '课程编号', count(DISTINCT students_no) '考试人数' from score group by object_no
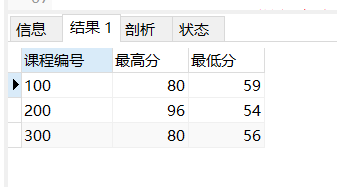
select object_no as '课程编号',max(score) as '最高分',min(score) as '最低分' from score group by object_no
select object_no as '课程编号', count(DISTINCT students_no) as '学生编号' from score group by object_no
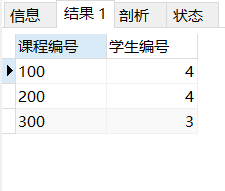
select sex '性别',count(DISTINCT students_no) '数量' from students group by sex
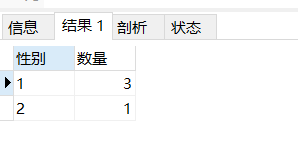
select students_no as '学生编号',avg(score) as '平均成绩' from score group by students_no
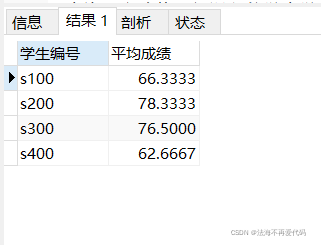
select students_no as '学生编号',avg(score) as '平均成绩' from score group by students_no HAVING avg(score)>70
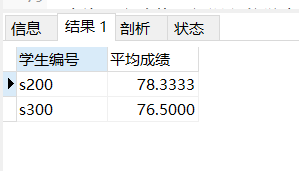
select students_no as '学生编号',count(object_no) as '课程编号' from score group by students_no
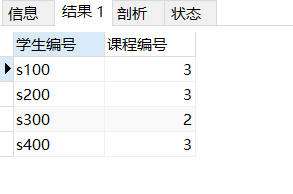
select students_no as '学生编号',count(object_no) as '课程编号' from score group by students_no HAVING count( object_no)>2
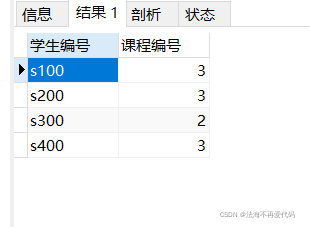
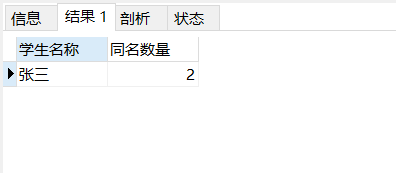
select students_name as '学生名称',count(students_name) as '同名数量' from students group by students_name HAVING count(students_name)>1
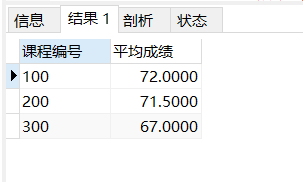
select object_no as '课程编号',avg(score) as '平均成绩' from score group by object_no
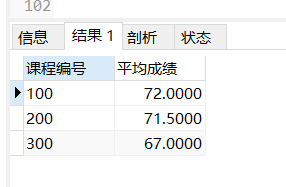
select object_no as '课程编号',avg(score) as '平均成绩' from score group by object_no HAVING avg(score)>70
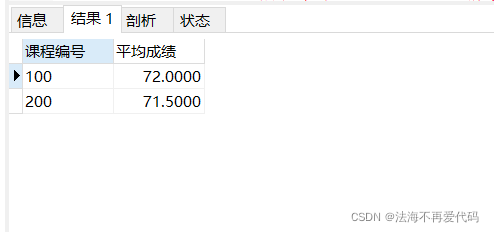
select object_no as '课程编号',students_no '学生编号',score '分数' from score where score<60 order by object_no desc
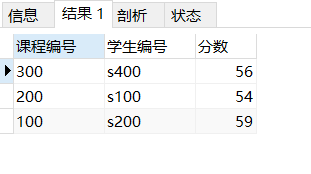
select object_no as '课程编号',avg(score) as '平均成绩' from score group by object_no order by avg(score) desc,object_no asc
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我注意到类定义,如果我打开classMyClass,并在不覆盖的情况下添加一些东西我仍然得到了之前定义的原始方法。添加的新语句扩充了现有语句。但是对于方法定义,我仍然想要与类定义相同的行为,但是当我打开defmy_method时似乎,def中的现有语句和end被覆盖了,我需要重写一遍。那么有什么方法可以使方法定义的行为与定义相同,类似于super,但不一定是子类? 最佳答案 我想您正在寻找alias_method:classAalias_method:old_func,:funcdeffuncold_func#similartoca
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl
我想从then子句中访问case语句表达式,即food="cheese"casefoodwhen"dip"then"carrotsticks"when"cheese"then"#{expr}crackers"else"mayo"end在这种情况下,expr是食物的当前值(value)。在这种情况下,我知道,我可以简单地访问变量food,但是在某些情况下,该值可能无法再访问(array.shift等)。除了将expr移出到局部变量然后访问它之外,是否有直接访问caseexpr值的方法?罗亚附注我知道这个具体示例很简单,只是一个示例场景。 最佳答案
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
如何在Ruby的if语句中检查bash命令的返回值(true/false)。我想要这样的东西,if("/usr/bin/fswscell>/dev/null2>&1")has_afs="true"elsehas_afs="false"end它会提示以下错误含义,它总是返回true。(irb):5:warning:stringliteralincondition正确的语法是什么?更新:/usr/bin/fswscell寻找afs安装和运行状态。它会抛出这样的字符串,Thisworkstationbelongstocell如果afs没有运行,命令以状态1退出 最