UC伯克利,谷歌研究院(Ashish Vaswani, 大名鼎鼎的Transformer一作)
论文:https://arxiv.org/abs/2101.11605
Github:https://github.com/leaderj1001/BottleneckTransformers
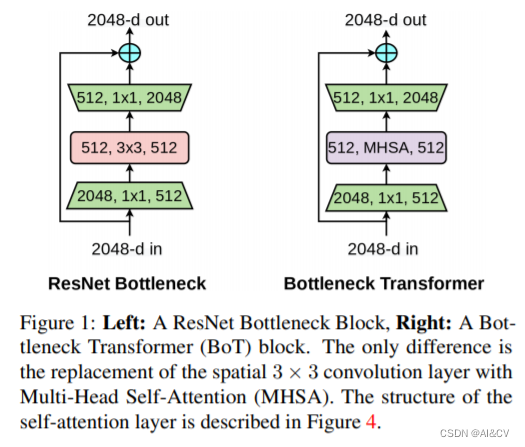
BoTNet(Bottleneck Transformer Network):一种基于Transformer的新骨干架构。BoTNet同时使用卷积和自注意力机制,即在ResNet的最后3个bottleneck blocks中使用全局多头自注意力(Multi-Head Self-Attention, MHSA)替换3 × 3空间卷积。
common.py中class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4, pos_emb=False):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.pos = pos_emb
if self.pos:
self.rel_h_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, 1, int(height)]),
requires_grad=True)
self.rel_w_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, int(width), 1]),
requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
# print('q shape:{},k shape:{},v shape:{}'.format(q.shape,k.shape,v.shape)) #1,4,64,256
content_content = torch.matmul(q.permute(0, 1, 3, 2), k) # 1,C,h*w,h*w
# print("qkT=",content_content.shape)
c1, c2, c3, c4 = content_content.size()
if self.pos:
# print("old content_content shape",content_content.shape) #1,4,256,256
content_position = (self.rel_h_weight + self.rel_w_weight).view(1, self.heads, C // self.heads, -1).permute(
0, 1, 3, 2) # 1,4,1024,64
content_position = torch.matmul(content_position, q) # ([1, 4, 1024, 256])
content_position = content_position if (
content_content.shape == content_position.shape) else content_position[:, :, :c3, ]
assert (content_content.shape == content_position.shape)
# print('new pos222-> shape:',content_position.shape)
# print('new content222-> shape:',content_content.shape)
energy = content_content + content_position
else:
energy = content_content
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2)) # 1,4,256,64
out = out.view(n_batch, C, width, height)
return out
class BottleneckTransformer(nn.Module):
# Transformer bottleneck
# expansion = 1
def __init__(self, c1, c2, stride=1, heads=4, mhsa=True, resolution=None, expansion=1):
super(BottleneckTransformer, self).__init__()
c_ = int(c2 * expansion)
self.cv1 = Conv(c1, c_, 1, 1)
# self.bn1 = nn.BatchNorm2d(c2)
if not mhsa:
self.cv2 = Conv(c_, c2, 3, 1)
else:
self.cv2 = nn.ModuleList()
self.cv2.append(MHSA(c2, width=int(resolution[0]), height=int(resolution[1]), heads=heads))
if stride == 2:
self.cv2.append(nn.AvgPool2d(2, 2))
self.cv2 = nn.Sequential(*self.cv2)
self.shortcut = c1 == c2
if stride != 1 or c1 != expansion * c2:
self.shortcut = nn.Sequential(
nn.Conv2d(c1, expansion * c2, kernel_size=1, stride=stride),
nn.BatchNorm2d(expansion * c2)
)
self.fc1 = nn.Linear(c2, c2)
def forward(self, x):
out = x + self.cv2(self.cv1(x)) if self.shortcut else self.cv2(self.cv1(x))
return out
class BoT3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, e=0.5, e2=1, w=20, h=20): # ch_in, ch_out, number, , expansion,w,h
super(BoT3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(
*[BottleneckTransformer(c_, c_, stride=1, heads=4, mhsa=True, resolution=(w, h), expansion=e2) for _ in
range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)).py中 if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, C2f,
EVCBlock, ODConv_3rd, ConvNextBlock, SEAM, RFEM, C3RFEM, ConvMixer, MultiSEAM,MLPBlock,Partial_conv3,CBAM,GAM_Attention,MHSA,BoT3}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x, C2f,EVCBlock,C3RFEM,BoT3}:
args.insert(2, n) # number of repeats
n = 1# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, BoT3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
#- [5,6, 7,9, 12,10] # P2/4
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args] # [c=channels,module,kernlsize,strides]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [c=3,64*0.5=32,3]
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, MHSA, [1024,1024]], #9
[-1, 1, SPPF, [1024,5]], #10
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, MHSA, [256,256]], #19
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 22 (P4/16-medium) [256, 256, 1, False]
[-1, 1, MHSA, [512,512]],
[-1, 1, Conv, [512, 3, 2]], #[256, 256, 3, 2]
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large) [512, 512, 1, False]
[-1, 1, MHSA, [1024,1024]], #
[[19, 23, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
在python中,我们可以使用多处理模块。如果Perl和Ruby中有类似的库,你会教它吗?如果您能附上一个简短的示例,我将不胜感激。 最佳答案 ruby:WorkingwithmultipleprocessesinRubyConcurrencyisaMythinRubyPerl:HarnessingthepowerofmulticoreWhyPerlIsaGreatLanguageforConcurrentProgramming此外,Perl的线程是native操作系统线程,因此您可以使用它们来利用多核。
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我是那些没有在他的任何Ruby/RubyonRails工作中使用TextMate的开发人员之一。我在这个领域的特别忠诚在于vim。您最喜欢将vim与Ruby和/或RubyonRails结合使用以尽可能提高工作效率的提示/技巧是什么? 最佳答案 最重要获取rails.vim的副本它在数百万级别上很棒。Readthedoc.提示太多了,:Rviewcustomer,:RSmodelfoo,:Rinvert,gf,:Rextract,:Rake等等。您可能需要NERDTree以及轻松导航(您可以使用:Rtree访问)第二重要在推特上关注t
最近做了一个平台项目,需要进行动态代码测试,入门了嵌入式单元测试工具Tessy,总结了一些简单的测试技巧。当前网上的教程普遍只写内容概要,真正入手还得自己认真摸索一番。为此,特意总结了一些Tessy测试技巧以供有缘人参考。提几个Tessy工具使用的问题。1.如何导入工程的头文件?2.如何解决文件内存在汇编语言代码分析时候报错的问题?3.如何规避本文件创建却不使用的函数,宏和变量,在执行executetest出现的undefinedreferencetoxx的问题?4.如何创建测试用例testcase?5.为什么testcase的结果输出与期望不一致?6.创建testcase的方法有几种?7.C
目录前言一、SQLServer基础1.SQLServer2012安装启动navicat远程连接2.SQLServer概念数据库的组成数据库中常用对象默认库介绍3.T-SQL语言创建数据库创建表插入数据基础语法总结4.sqlserver权限新建用户并赋予权限权限总结二、Sqlserver手工注入环境搭建注入手法1.联合查询2.报错注入3.布尔盲注4.延时注入三、SQlserver提权getshellxp_cmdshell执行系统命令sp_oacreate执行系统命令使用CLR执行系统命令数据库差异备份写webshell日志差异备份写webshell前言本文详细的介绍了SqlServer安全基础,
Ruby2.3在Array和Hash上引入了一种新方法,称为dig。我在有关新版本的博客文章中看到的示例是做作和令人费解的:#Hash#diguser={user:{address:{street1:'123Mainstreet'}}}user.dig(:user,:address,:street1)#=>'123Mainstreet'#Array#digresults=[[[1,2,3]]]results.dig(0,0,0)#=>1我没有使用三层嵌套平面数组。什么是这将如何有用的现实示例?更新事实证明,这些方法解决了最常见的Ruby问题之一。下面的问题大约有20个重复项,所有这些问
趁着寒假期间稍微尝试跑了一下yolov5和yolov7的代码,由于自己用的笔记本没有独显,台式机虽有独显但用起来并不顺利,所以选择了租云服务器的方式,选择的平台是矩池云(价格合理,操作便捷)需要特别指出的是,如果需要用pycharm链接云服务器训练,必须要使用pycharm的专业版而不是社区版,专业版可以使用SSH服务连接云服务器。关于专业版的获取,据我所知一是可以买,二是如果你是在校大学生,可以用学生证向JetBrain申请专业版使用权,我就是通过这种方式激活专业版账户的,我记得当时两三天官方就发激活邮件了,还是很人性化的,使用期一年。下面开始正题本教程只涉及将yolov5及yolov7跑通