文章目录
Quartz是一个定时任务调度框架,比如你遇到这样的问题:
Quartz是一套轻量级的任务调度框架,只需要定义了 Job(任务),Trigger(触发器)和 Scheduler(调度器),即可实现一个定时调度能力。支持基于数据库的集群模式,可以做到任务幂等执行。
<!-- https://mvnrepository.com/artifact/org.quartz-scheduler/quartz -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.3</version>
</dependency>
package com.lyx.job;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import java.util.Date;
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("hello job exec"+new Date());
}
}
package com.lyx.job;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
import java.util.GregorianCalendar;
public class HelloQuartz {
public static void main(String[] args) throws SchedulerException {
//1. 调度器
Scheduler defaultScheduler = StdSchedulerFactory.getDefaultScheduler();
//2. trigger触发器
SimpleTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","group1")
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(3).repeatForever())
.endAt(new GregorianCalendar(2022,5,11,16,05,30).getTime())
.build();
//3. JobDetail
JobDetail jobDetail = JobBuilder.newJob(HelloJob.class).withIdentity("job1","group1").build();
//4. 将JobDetail和trigger增加到调度器
defaultScheduler.scheduleJob(jobDetail,trigger);
//5. 启动调度器
defaultScheduler.start();
}
}

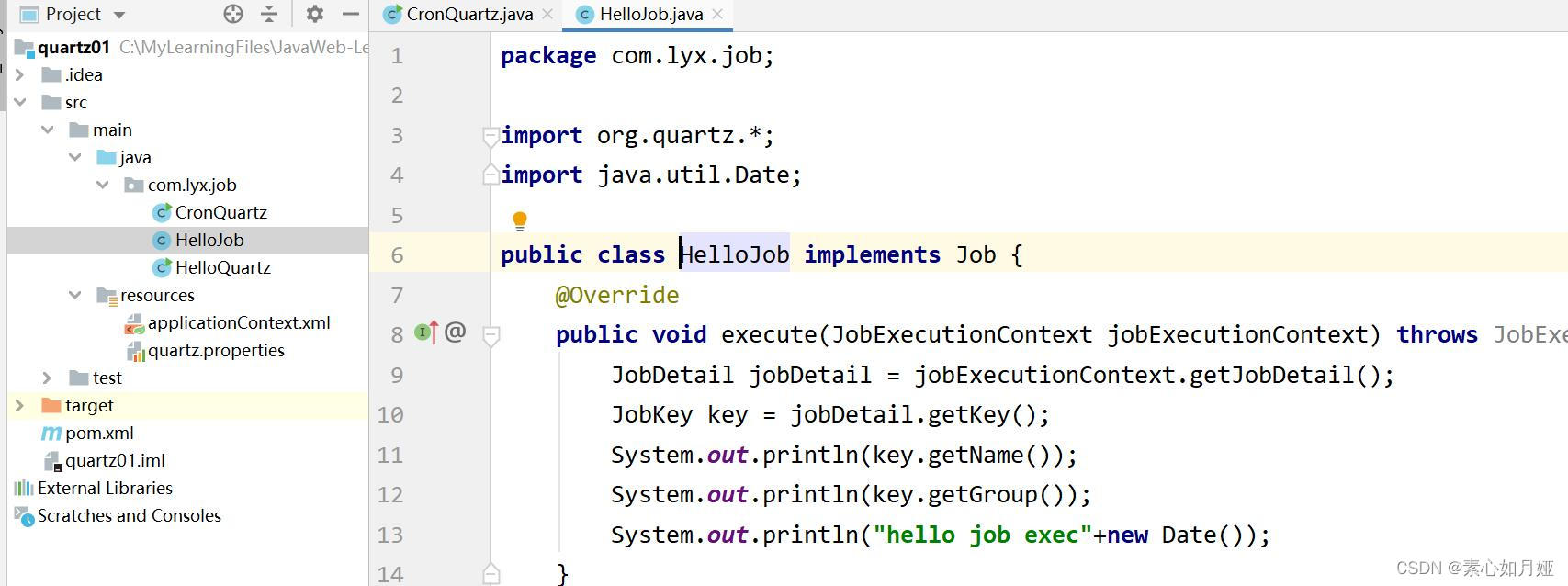
import org.quartz.*;
import java.util.Date;
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
JobDetail jobDetail = jobExecutionContext.getJobDetail();
JobKey key = jobDetail.getKey();
System.out.println(key.getName());
System.out.println(key.getGroup());
System.out.println("hello job exec"+new Date());
}
}

#指定调度器名称,非实现类
org.quartz.scheduler.instanceName=DefaultQuartzScheduler
#指定线程池实现类
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
#线程池线程数量
org.quartz.threadPool.threadCount = 10
#优先级,默认5
org.quartz.threadPool.threadPriority = 5
#非持久化job
org.quartz.jobStore.class=org.quartz.simpl.RAMJobStore
Scheduler:调度器。所有的调度都是由它控制,是Quartz的大脑,所有任务都是由它来管理
Job:任务,想定时执行的事情(定义业务逻辑)
JobDetail:基于Job,进一步包装,其中关联一个Job,并为Job指定更详细的属性,比如标识等
Trigger:触发器。可以指定给某个任务,指定任务的触发机制
触发器在Quartz中有很多种
以一定的时间间隔(单位是毫秒)执行的任务
- 指定起始和截止时间(时间端)
- 指定时间间隔、执行次数
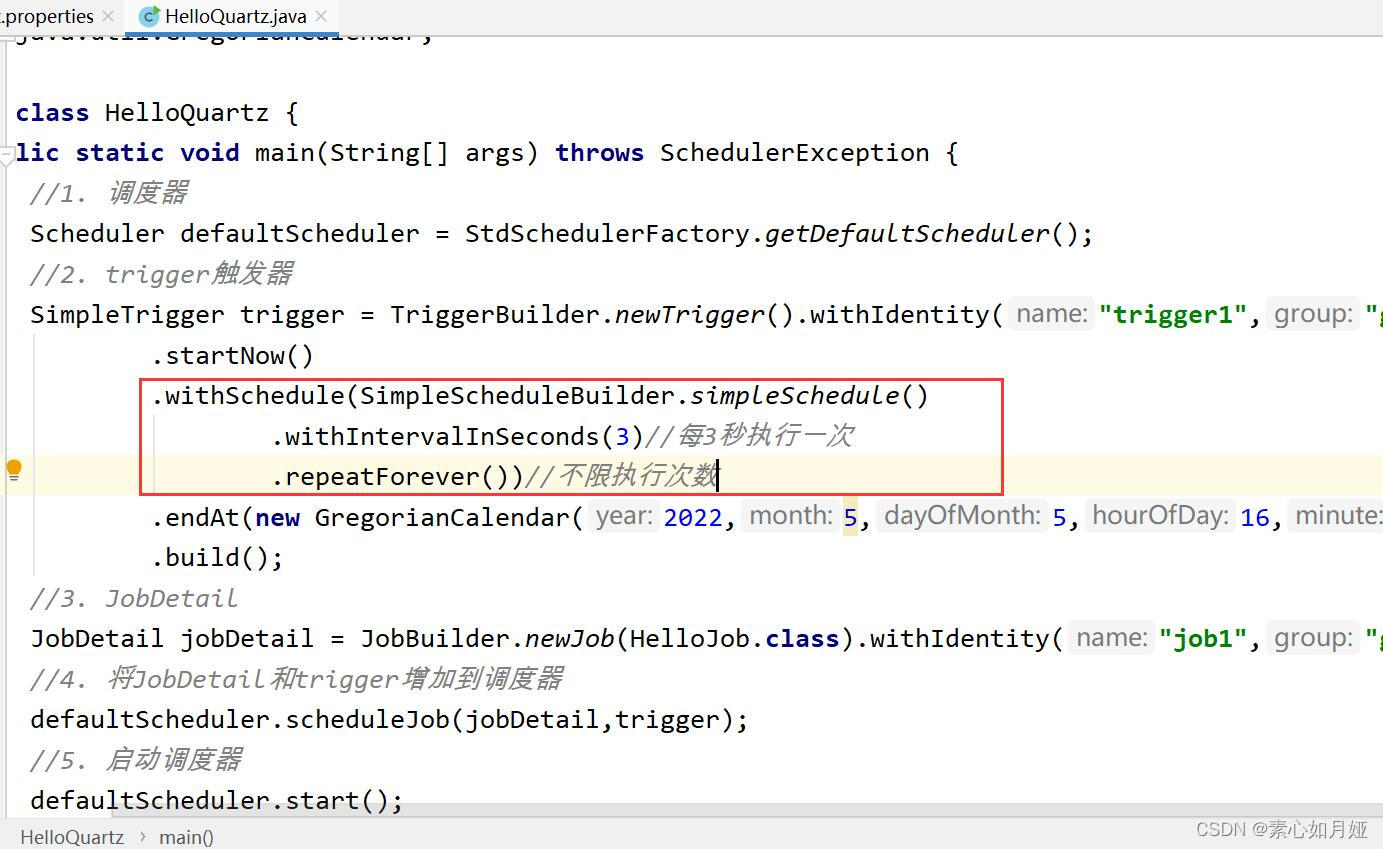
SimpleTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","group1")
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(3)//每3秒执行一次
.repeatForever())//不限执行次数
.endAt(new GregorianCalendar(2022,5,5,16,05,30).getTime())
.build();

SimpleTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","group1")
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(3)//每3秒执行一次
.withRepeatCount(3))//执行次数不超过3次
.endAt(new GregorianCalendar(2022,5,5,16,05,30).getTime())
.build();
适合更复制的任务,它支持类似于于Linus Cron的语法(并且更强大)。
- 指定Cron表达式即可
触发器不再使用startNow()、endAt()
只用withSchedule(CronScheduleBuilder.cronSchedule(“30 01 17 11 5 ?”))
""里面的数值依次对应:秒、分、时、日、月、周几(?:自动判断周几),时分秒的数值换成*,意思是每个时分秒都执行一次
示例:如下:
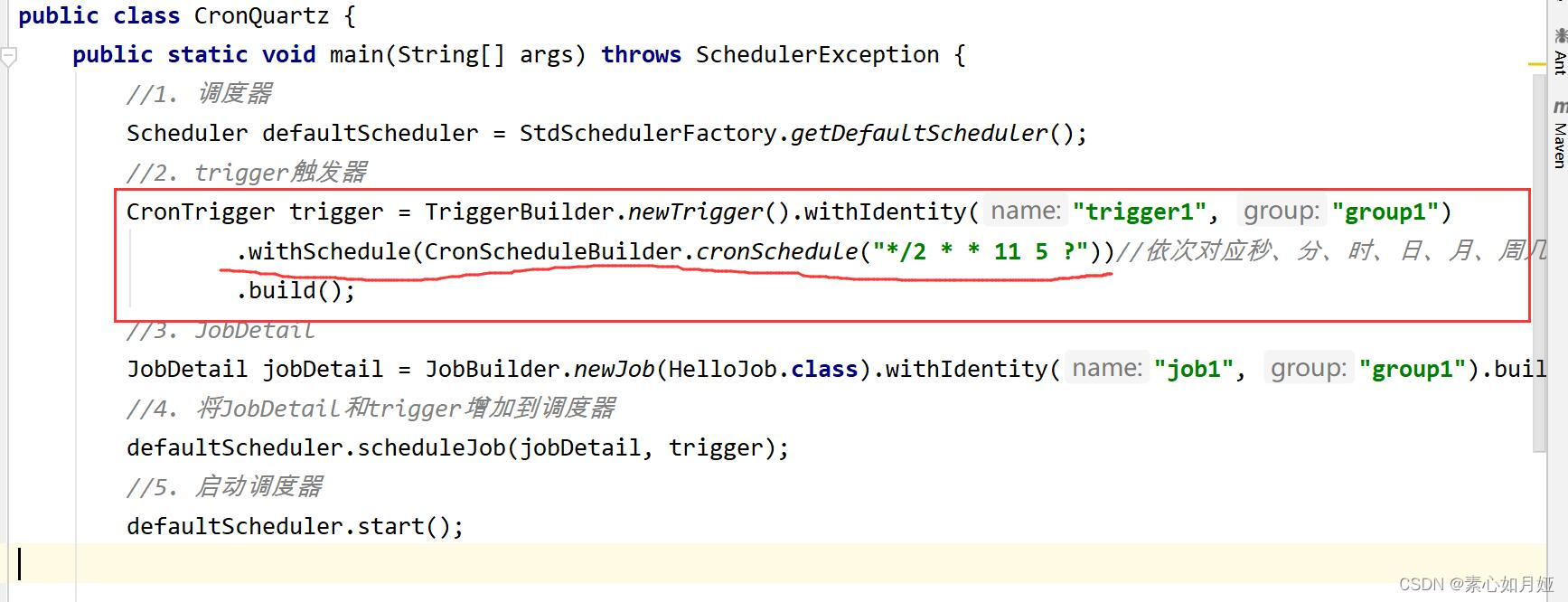
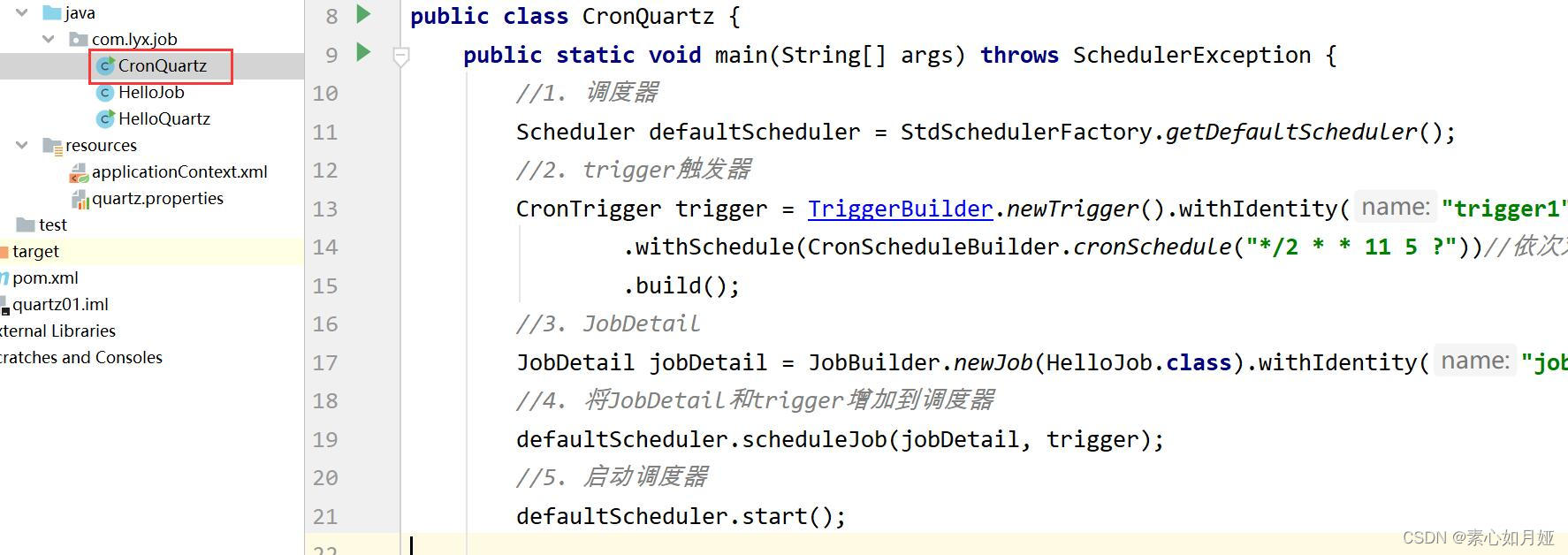
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","group1")
.withSchedule(CronScheduleBuilder.cronSchedule( "* * * 11 5 ?"))
.build();
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","group1")
.withSchedule(CronScheduleBuilder.cronSchedule( "*/2 * * 11 5 ?"))
.build();
推荐一个cron在线校验工具:quartz/Cron表达式在线校验工具
表达式组成:“秒 分 时 日 月 星期几 [年]” ,年一般不写
- 如 :“10 20 18 3 5 ?”代表“5月3日18点20分10秒,星期几不确定”
| 位置 | 时间域 | 允许值 | 特殊值 |
|---|---|---|---|
| 1 | 秒 | 0~59 | , - * /(4种字符) |
| 2 | 分钟 | 0~59 | , - * /(4种字符) |
| 3 | 小时 | 0~23 | , - * /(4种字符) |
| 4 | 日期 | 1~31 | , - * ?/ L W C(8种字符) |
| 5 | 月份 | 1~12 | , - * ?/ L # C(8种字符) |
| 6 | 星期 | 1-7(1代表周日) | , - * /(4种字符) |
| 7 | 年份(可选) | , - * /(4种字符) |

以下详细介绍
(1):表示匹配该域的任意值。假如在Minutes域使用, 即表示每分钟都会触发事件。
(2)?:只能用在DayofMonth和DayofWeek两个域。它也匹配域的任意值,但实际不会。因为DayofMonth和DayofWeek会相互影响。例如想在每月的20日触发调度,不管20日到底是星期几,则只能使用如下写法:
13 13 15 20 * ?, 其中最后一位只能用?,而不能使用*,如果使用*表示不管星期几都会触发,实际上并不是这样。(3)-:表示范围。例如在Minutes域使用5-20,表示从5分到20分钟每分钟触发一次
(4)/:表示起始时间开始触发,然后每隔固定时间触发一次。例如在Minutes域使用5/20,则意味着5分钟触发一次,而25,45等分别触发一次.
(5),:表示列出枚举值。例如:在Minutes域使用5,20,则意味着在5和20分每分钟触发一次。
(6)L:表示最后Last,只能出现在DayofWeek和DayofMonth域。如果在DayofWeek域使用5L,意味着在最后的一个星期四触发。
(7)W:表示有效工作日(周一到周五),只能出现在DayofMonth域,系统将在离指定日期的最近的有效工作日触发事件。例如:在
DayofMonth使用5W,如果5日是星期六,则将在最近的工作日:星期五,即4日触发。如果5日是星期天,则在6日(周一)触发;如果5日在星期一到星期五中的一天,则就在5日触发。另外一点,W的最近寻找不会跨过月份
。(8)LW:这两个字符可以连用,表示在某个月最后一个工作日,即最后一个星期五。
(9)#:用于确定每个月第几个星期几,只能出现在DayofWeek域。例如在4#2,表示某月的第二个星期三。
注意:
“/”字符用来指定数值的增量 例如:在子表达式(分钟)里的“0/15”表示从第0分钟开始,每15分钟 在子表达式(分钟)里的“3/20”表示从第3分钟开始,每20分钟(它和“3,23,43”)的含义一样
“?”字符仅被用于天(月)和天(星期)两个子表达式,表示不指定值 当2个子表达式其中之一被指定了值以后,为了避免冲突,需要将另一个子表达式的值设为“?”
“L” 字符仅被用于天(月)和天(星期)两个子表达式,它是单词“last”的缩写 但是它在两个子表达式里的含义是不同的。 在天(月)子表达式中,“L”表示一个月的最后一天 在天(星期)自表达式中,“L”表示一个星期的最后一天,也就是SAT,如果在“L”前有具体的内容,它就具有其他的含义了 例如:“6L”表示这个月的倒数第6天,“FRIL”表示这个月的最一个星期五
注意:在使用“L”参数时,不要指定列表或范围,因为这会导致问题
三、常用表达式例子
(0)0/20 * * * * ? 表示每20秒 调整任务
(1)0 0 2 1 * ? 表示在每月的1日的凌晨2点调整任务
(2)0 15 10 ? * MON-FRI 表示周一到周五每天上午10:15执行作业
(3)0 15 10 ? 6L 2002-2006 表示2002-2006年的每个月的最后一个星期五上午10:15执行作
(4)0 0 10,14,16 * * ? 每天上午10点,下午2点,4点
(5)0 0/30 9-17 * * ? 朝九晚五工作时间内每半小时
(6)0 0 12 ? * WED 表示每个星期三中午12点
(7)0 0 12 * * ? 每天中午12点触发
(8)0 15 10 ? * * 每天上午10:15触发
(9)0 15 10 * * ? 每天上午10:15触发
(10)0 15 10 * * ? * 每天上午10:15触发
(11)0 15 10 * * ? 2005 2005年的每天上午10:15触发
(12)0 * 14 * * ? 在每天下午2点到下午2:59期间的每1分钟触发
(13)0 0/5 14 * * ? 在每天下午2点到下午2:55期间的每5分钟触发
(14)0 0/5 14,18 * * ? 在每天下午2点到2:55期间和下午6点到6:55期间的每5分钟触发
(15)0 0-5 14 * * ? 在每天下午2点到下午2:05期间的每1分钟触发
(16)0 10,44 14 ? 3 WED 每年三月的星期三的下午2:10和2:44触发
(17)0 15 10 ? * MON-FRI 周一至周五的上午10:15触发
(18)0 15 10 15 * ? 每月15日上午10:15触发
(19)0 15 10 L * ? 每月最后一日的上午10:15触发
(20)0 15 10 ? * 6L 每月的最后一个星期五上午10:15触发
(21)0 15 10 ? * 6L 2002-2005 2002年至2005年的每月的最后一个星期五上午10:15触发
(22)0 15 10 ? * 6#3 每月的第三个星期五上午10:15触发
<!-- https://mvnrepository.com/artifact/org.quartz-scheduler/quartz -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework/spring-context-support -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>5.1.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>5.3.16</version>
</dependency>
接下来用配置文件,替换以下方法中的代码
<?xml version="1.0" encoding="UTF8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd"
>
<!--Spring整合Quartz进行配置:
1. 定义工作任务Job
2. 定义触发器Trigger,并将触发器与工作任务绑定
3. 定义调度器,并将Trigger注册到Scheduler-->
<!--1. 定义Job ,这里使用JobDetailFactoryBean,也可以使用MethodInvokingJobDetailFactoryBean-->
<bean name="lxJob" class="org.springframework.scheduling.quartz.JobDetailFactoryBean">
<property name="name" value="job1"/>
<property name="group" value="group1"/>
<property name="jobClass" value="com.lyx.job.HelloJob"/>
</bean>
<!--2. 定义Trigger,定义一个cron的trigger,一个触发器只能和一个任务进行绑定-->
<bean id="cronTrigger" class="org.springframework.scheduling.quartz.CronTriggerFactoryBean">
<property name="name" value="trigger1"/>
<property name="group" value="group1"/>
<property name="jobDetail" ref="lxJob"/>
<!--指定cron的表达式,当前是每隔5s运行一次-->
<property name="cronExpression" value="*/5 * * * * ?"/>
</bean>
<!-- 3.定义调度器,并将Trigger注册到调度器中-->
<bean id="scheduler" class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref bean="cronTrigger"/>
</list>
</property>
<!--定义的quartz.properties-->
<property name="configLocation" value="classpath:quartz.properties"></property>
</bean>
</beans>
quartz.properties
#指定调度器名称,非实现类
org.quartz.scheduler.instanceName=DefaultQuartzScheduler
#指定线程池实现类
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
#线程池线程数量
org.quartz.threadPool.threadCount = 10
#优先级,默认5
org.quartz.threadPool.threadPriority = 5
#非持久化job
org.quartz.jobStore.class=org.quartz.simpl.RAMJobStore
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class QuartzTest {
public static void main(String[] args) {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("application.xml");
}
}
import org.quartz.impl.StdScheduler;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class QuartzTest {
public static void main(String[] args) throws InterruptedException, SchedulerException {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("application.xml");
Thread.sleep(3000);
StdScheduler stdScheduler = (StdScheduler) context.getBean("scheduler");
//删除
stdScheduler.deleteJob(JobKey.jobKey("job1","group1"));
}
}
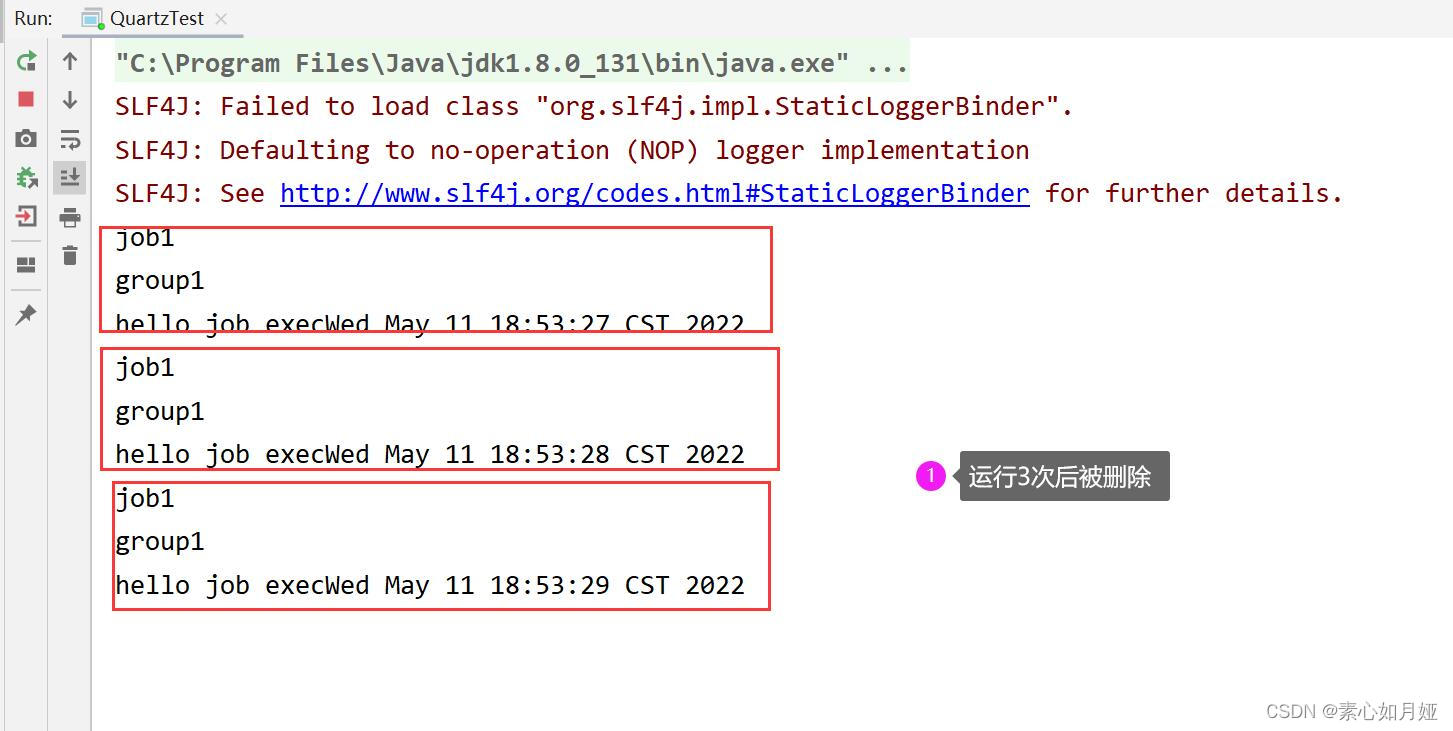
import org.quartz.JobKey;
import org.quartz.SchedulerException;
import org.quartz.impl.StdScheduler;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class QuartzTest {
public static void main(String[] args) throws InterruptedException, SchedulerException {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Thread.sleep(2000);
StdScheduler stdScheduler = (StdScheduler) context.getBean("scheduler");
//暂停
stdScheduler.pauseJob(JobKey.jobKey("job1","group1"));
//5秒后恢复
Thread.sleep(5000);
stdScheduler.resumeJob(JobKey.jobKey("job1","group1"));
}
}
import org.quartz.JobKey;
import org.quartz.SchedulerException;
import org.quartz.impl.StdScheduler;
import org.quartz.impl.matchers.GroupMatcher;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class QuartzTest {
public static void main(String[] args) throws InterruptedException, SchedulerException {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
Thread.sleep(2000);
StdScheduler stdScheduler = (StdScheduler) context.getBean("scheduler");
//group1中的job全部暂停
stdScheduler.pauseJobs(GroupMatcher.groupEquals("group1"));
//5秒后恢复
Thread.sleep(5000);
stdScheduler.resumeJobs(GroupMatcher.groupEquals("group1"));
}
}
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
我以前没有使用过cron,所以我不能确定我这样做是对的。我想要自动化的任务似乎没有运行。我在终端中执行了这些步骤:sudogeminstall每当切换到应用程序目录无论何时。(这创建了文件schedule.rb)我将此代码添加到schedule.rb:every10.minutesdorunner"User.vote",environment=>"development"endevery:hourdorunner"Digest.rss",:environment=>"development"end我将此代码添加到deploy.rb:after"deploy:symlink","depl
如何在Rake任务中运行Capybara功能?例如:访问('http://google.com')谢谢! 最佳答案 在任务中尝试这样的事情:require'capybara'require'capybara/dsl'Capybara.current_driver=:seleniumBrowser=Class.new{includeCapybara::DSL}page=Browser.new.pagepage.visit("http://www.google.com")puts(page.html)
我想开始使用“Sinatra”框架进行编码,但我找不到该框架的“MVC”模式。是“MVC-Sinatra”模式或框架吗? 最佳答案 您可能想查看Padrino这是一个围绕Sinatra构建的框架,可为您的项目提供更“类似Rails”的感觉,但没有那么多隐藏的魔法。这是使用Sinatra可以做什么的一个很好的例子。虽然如果您需要开始使用这很好,但我个人建议您将它用作学习工具,以对您来说最有意义的方式使用Sinatra构建您自己的应用程序。写一些测试/期望,写一些代码,通过测试-重复:)至于ORM,你还应该结帐Sequel其中(imho
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n
根据thispostbyStephenHagemann,我正在尝试为我的一个rake任务编写Rspec测试.lib/tasks/retry.rake:namespace:retrydotask:message,[:message_id]=>[:environment]do|t,args|TextMessage.new.resend!(args[:message_id])endendspec/tasks/retry_spec.rb:require'rails_helper'require'rake'describe'retrynamespaceraketask'dodescribe're