一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势。
一个broker如果对应多个partition,需要随机分发,顺序IO会退化成随机IO。
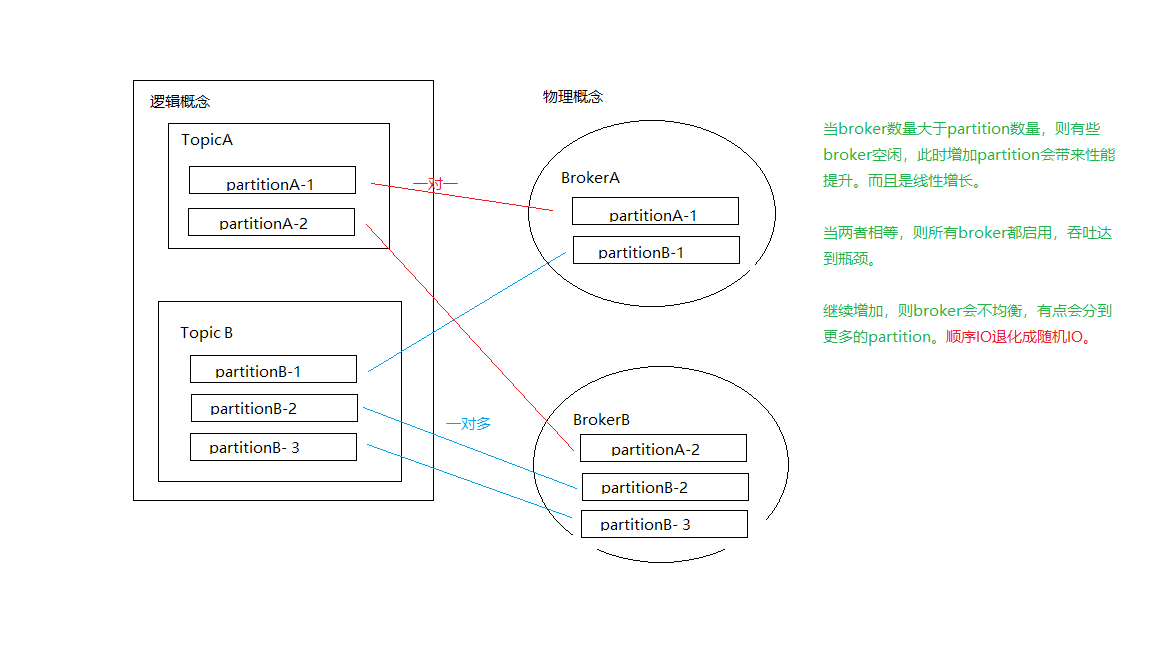
实验条件:3个 Broker,1个 Topic,无Replication,异步模式,3个 Producer,消息 Payload 为100字节:
当 Partition 数量小于 Broker个数时,Partition 数量越大,吞吐率越高,且呈线性提升。
Kafka 会将所有 Partition 均匀分布到所有Broker 上,所以当只有2个 Partition 时,会有2个 Broker 为该 Topic 服务。
3个 Partition 时,同理会有3个 Broker 为该 Topic 服务。
当 Partition 数量多于 Broker 个数时,总吞吐量并未有所提升,甚至还有所下降。
可能的原因是,当 Partition 数量为4和5时,不同 Broker 上的 Partition 数量不同,而 Producer 会将数据均匀发送到各 Partition 上,这就造成各Broker 的负载不同,不能最大化集群吞吐量。
• 当broker数量大于partition数量,则有些broker空闲,此时增加partition会带来性能提升。而且是线性增长。
• 当两者相等,则所有broker都启用,吞吐达到瓶颈。
• 继续增加,则broker会不均衡,有点会分到更多的partition。
顺序IO退化成随机IO。
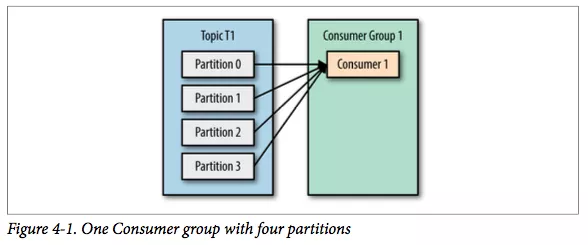
假设有一个 T1 主题,该主题有 4 个分区;同时我们有一个消费组 G1,这个消费组只有一个消费者 C1。
那么消费者 C1 将会收到这 4 个分区的消息。
如果我们增加新的消费者 C2 到消费组 G1,那么每个消费者将会分别收到两个分区的消息。
相当于 T1 Topic 内的 Partition 均分给了 G1 消费的所有消费者,在这里 C1 消费 P0 和 P2,C2 消费 P1 和 P3。

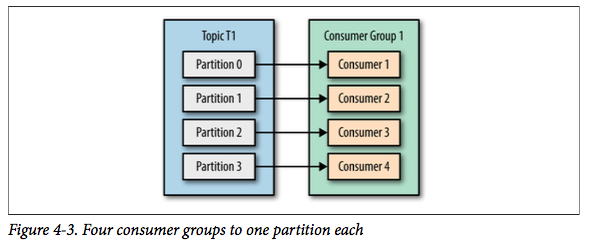
如果增加到 4 个消费者,那么每个消费者将会分别收到一个分区的消息。 这时候每个消费者都处理其中一个分区,满负载运行。
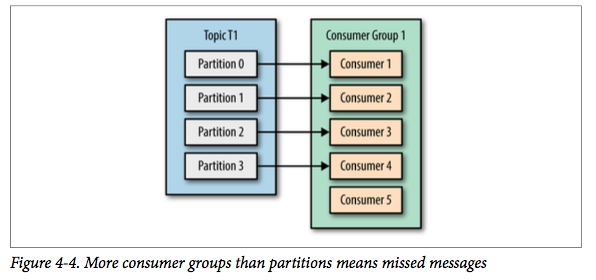
但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息。
总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。
这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。
另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
如果我们的 C1 处理消息仍然还有瓶颈,我们如何优化和处理?
把 C1 内部的消息进行二次 sharding,开启多个 goroutine worker 进行消费,为了保障 offset 提交的正确性,需要使用 watermark 机制,保障最小的 offset 保存,才能往 Broker 提交。
● 保证顺序性,避免大的offest先提交,小的offest挂了,重启后会消息丢失。
● 解决:开一个协程专门提交offest,保证只提交最小的,重复消费代替消息丢失。
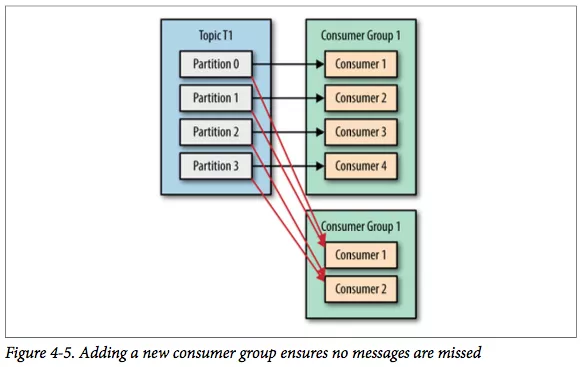
Kafka 一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。 换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。
对于上面的例子,假如我们新增了一个新的消费组 G2,而这个消费组有两个消费者如图。 在这个场景中,消费组 G1 和消费组 G2 都能收到 T1 主题的全量消息,在逻辑意义上来说它们属于不同的应用。
如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我在关注RyanbatesRailsCast的devise和omniauth(第235集-devise-and-omniauth-revised)。当我尝试使用Twitter登录时,标题中不断出现错误。defself.new_with_session(params,session)ifsession["devise.user_attributes"]new(session["devise.user_attributes"],without_protection:true)do|user|user.attributes=paramsuser.valid?end完整跟踪:C:/Ruby20
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包
n00b问题警报!这是问题所在:我正在创建一个至少包含3个参数的shell脚本:一个字符串、一个行号和至少一个文件。我已经编写了一个脚本,可以接受EXACTLY3个参数,但我不知道如何处理多个文件名参数。这是我的代码的相关部分(跳过写回文件等):#!/usr/bin/envrubythe_string=ARGV[0]line_number=ARGV[1]the_file=ARGV[2]definsert_script(str,line_n,file)f=files=strln=line_n.to_iif(File.file?f)read_in(f,ln,s)elseputs"false
给定一个包含各种语言字符的UTF-8文件,我如何计算它包含的唯一字符的数量,同时排除选定数量的符号(例如:“!”、“@”、"#",".")从这个算起? 最佳答案 这是一个bash解决方案。:)bash$perl-CSD-ne'BEGIN{$s{$_}++forsplit//,q(!@#.)}$s{$_}++||$c++forsplit//;END{print"$c\n"}'*.utf8 关于python-如何计算文件中唯一字符的数量?,我们在StackOverflow上找到一个类似的问题
如何以最佳方式在字符串中找到唯一元素?示例字符串格式为myString="34345667543"对/对['3','4','3','5'.....] 最佳答案 这是一个有趣的问题,因为它返回了很多几乎相似的结果,所以我做了一个简单的基准测试来决定哪个实际上是最好的解决方案:require'rubygems'require'benchmark'require'set'puts"Dothetest"Benchmark.bm(40)do|x|STRING_TEST="26263636362626218118181111232112233"
MODEL1有一个account_type,所以使用gem'enumerated_attributes',我制作了这样的模型:classMODEL1我不明白的奇怪的事情是,当我像这样查询任意MODEL1的种子时(这是我在rubymine控制台中运行follwing命令时的错误,但在rakedb期间会发生同样的2for1错误:种子):MODEL1.all.sample和MODEL1.all我明白了:DealerLoad(0.3ms)SELECT"MODEL1".*FROM"MODEL1S"ArgumentError:wrongnumberofarguments(2for1)from/
我最近正在进行Rails5升级,当我尝试启动Rails控制台时遇到了这个错误:/actionpack-5.0.0/lib/action_controller/test_case.rb:49:ininitialize':wrongnumberofarguments(0for2)(ArgumentError)当前bundleupdaterails已经完成了gem依赖项的解决,足以更新到5.0.0,rspec正在运行(尽管我正在修复很多中断)。我也可以运行railss没有错误。这里是代码中断行:https://github.com/rails/rails/blob/master/action
我知道我们可以做到:sidekiq_optionsqueue:"Foo"但在这种情况下,Worker只分配给一个队列:“Foo”。我需要在特定队列中分配作业(而不是worker)。使用Resque很容易:Resque.enqueue_to(queue_name,my_job)另外,为了并发问题,我需要限制每个队列的Worker数量为1。我该怎么做? 最佳答案 您可能会使用https://github.com/brainopia/sidekiq-limit_fetch然后:Sidekiq::Client.push({'class'=>
我有两个模型用户和事件。基数是一个用户有很多事件。当我查询数据库以提供所有用户及其相应事件时,它会返回正确的结果。示例语句:Users.find(:all,:include=>[:events])但是,我需要帮助的是根据条件为用户获取事件。我需要返回的每个用户只获取今天安排的事件(例如:CREATED_DATE=TODAY)。也就是说,我不希望所有事件都与用户关联。也就是说,我仍然需要在数据库中找到的所有用户,但对于今天没有安排事件的一些用户,他们不应该在HashMap中加载事件。有人可以帮我修改“Users.find(:all,:include=>[:events])”Rails语句