
导读|过去几年,数据湖能力已经在腾讯内部包括微信视频号、小程序等多个业务大规模落地,数据规模达到 PB至 EB 级别。在此基础上,腾讯自研业务也启动了云原生湖仓能力建设。云原生湖仓架构最大的挑战什么?腾讯云原生湖仓 DLC 从哪些方面着手解决问题?接下来由腾讯云大数据专家工程师于华丽带来相关分享。

云原生湖仓的诞生背景、价值、挑战
当前这个阶段,相信大家对于数据湖,数据仓,湖仓一系列的名词已经不算陌生了,我用最直白、最狭义方式去解释“湖仓”的话,就是数据湖跟数仓存储架构统一。
数据湖最初的需求是,要存储和分析海量的半结构化、非结构化的数据,以及数据仓备份和温冷数据存储。在公有云找到了对象存储(海量、低价、高 SLA 和高可靠性)这样一个全托管的存储产品后,成本方面对象存储对比客户 HDFS 自建大概为 1:10,非常有吸引力。
这个存储系统看起来这么好,有没有可能把数仓一起解决,结构化数据是不是存在这里?伴随着这个需求的升级,现代湖仓架构的基础也随之产生。
云原生湖仓又是什么呢?最狭义的理解就是容器计算 + K8s。更加广义的理解应该长在云上,更多的使用云上已有的全托管产品,比如利用对象存储、本身服务云原生化等。
在云原生湖仓架构下,会面临很大的挑战就是“性能”。为什么有“性能”的挑战?第一:对象存储有很好的成本优势,但是引入对象存储之后变成了存算分离的架构,损失了本地计算,整体性能损失 30% 以上;其次弹性计算跟分析性能是矛盾的变量,ScaleUp 需要时间,甚至有可能弹不出来,没有文件缓存,弹性会引起数据倾斜;最后是敏捷分析,海量明细数据直接分析也是很直接的需求。

腾讯云原生湖仓产品 DLC 如何应对挑战
1)DLC 产品定位
DLC 的第一个特点,简单三个字概况便是——“全托管”,不同于 EMR,DLC 是开箱即用的,例如交互界面、元数据、安全、Spark DDL Server、Spark History 服务等都是全托管、免搭建的,甚至有很多是免费提供的。
第二个特点,DLC 是腾讯云数据湖解决方案的粘合剂,不同产品能够用一份湖仓数据,带给用户低成本,低维护成本的价值。
2)DLC 架构理念
接下来讲 DLC 的架构理念。DLC 是腾讯大数据自研能力的上云,但是并不是简单平移部署,产品形态便是最大的差异。DLC 是多租户的全托管产品,我们秉持两大原则:保持简单 KISS、云原生。保持简单上我们是非常执着的。
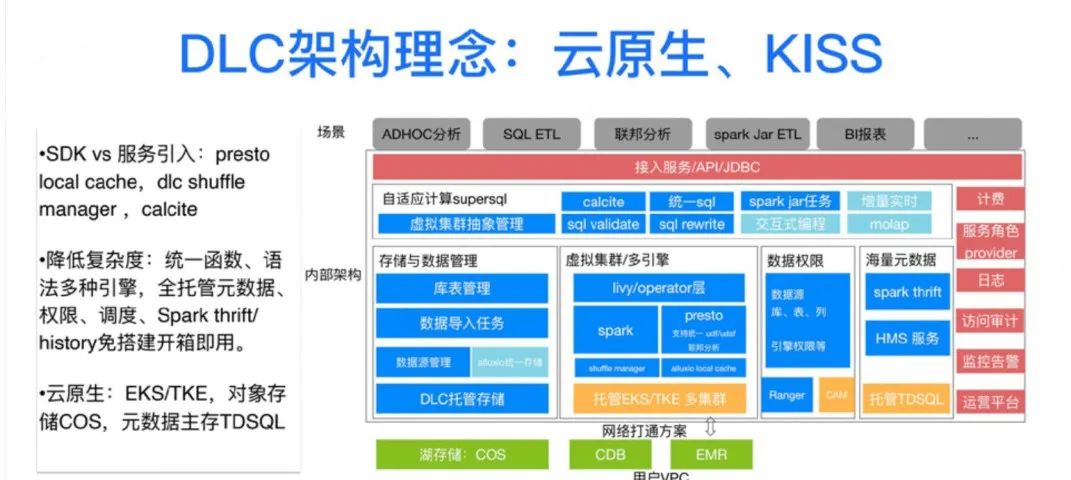
对于服务引用非常保守,服务能少则少。取而代之的是 SDK 的接入,例如上图右侧的 Presto 的 Local Cache 就不会引入 Alluxio Cluster,Spark 这儿不引入 RSS 服务而是轻量简单的 Shuffle Manager 等等。
降低使用复杂度,DLC 集成了腾讯自研 SuperSQL,去实现统一函数和语法来去两个引擎无缝切换。上图右侧大部分服务都是托管的,如元数据、调度、权限、DDL 服务、Spark History 等这些服务都是用户免搭建,开箱即用的,大部分是免费的,而且我们还给到了用户一定的免费额度,只要配置得当,基本是能满足客户需求的。
云原生原则:狭义的说,DLC 都是基于容器的,包括计算引擎和各种服务容器化。广义的说,云原生更应该“长在云上”,DLC 是直接使用云上的对象存储、云数据库、云 Kafka、TDSQL 等等全托管 SaaS 服务的。

LC 实现 PB 级数据秒级分析
回到最开始的问题“高性能”,PB 级数据秒级分析该怎么去做,从三个大维度展开。我们从三个层面出发讲,第一从多维 Cache 的角度出发,包括文件缓存,中间结果缓存等;第二从弹性模型出发;第三从三维 Filter 的模型:分区、列、文件出发。
1)多维 cache
多维 Cache 分了三个角度:文件缓存、Fragment 结果缓存以及中间结果缓存、元数据的缓存,重点说说前两个。
文件缓存:我们在 DLC 上线了 Alluxio Local Cache,优点是没有单独的 Alluxio 集群,也不占用计算资源,免运维。当然也会有需要优化的地方,比如文件 /Split 级别、跨租户 Cache 缓存数据安全、缓存一致性、弹性影响、监控、黑名单等,这些优化空间 DLC 都会帮客户完成。在一些情况下,访问 Cos 的性能有 3—10 倍的提升。
Fragment 结果缓存:优点是不需要预计算,我们知道物化视图也非常流行,但是物化视图的利用率往往不好量化,事实上通常很低,而根据访问行为缓存下来的是用户行为肯定的;另外是用户几乎没有什么成本,同时也很大程度上降低底层存储的压力。当然,还会涉及到一些问题需要大家注意,例如缓存一致性、跨租户的安全等。性能方面,从来自 Presto 社区的数据看,Raptorx 有接近 10X 的提升。
2)虚拟集群弹性模型
刚才讲两种缓存效果接近 10 倍的性能提升,对弹性模型就有了很高的要求,因为缓存的命中是很依赖集群拓扑的稳定性的。另外资源启动要时间,新拉容器和镜像最快也要 1—2 分钟;最后 Client 预热很重要,包括各种服务都是 Lazy 加载的 Module 等等,这也都是需要 30 秒甚至 1 分钟的时间,这跟我们要求的秒级分析就差太远了。
那 DLC 是如何解决这个问题的呢?我们采用了虚拟集群架构,以子集群为最小单位去横向弹子集群,这样子集群拓扑稳定,资源跟 Client 都有很好预热。而且因为子集群的 Query 隔离,子集群也是很容易缩容的。
3)多维 Filter 过滤

继续说性能提升,还是 IO 优化,技术也是比较成熟的,只是还不怎么普及。先看第二个,列存 Parquet/ORC,结合引擎 Project 的下推,这样只有关心的列才会被扫描。第三个分区 / 分桶也比较常规了,但是最新业界的新特性比如 Dynamic Partition Puning,可以很好地加速分区需要推断的场景。
下面仔细说说稀疏索引。Bloomfilter、Zordering 本质逻辑上是类似的,需要结合引擎的谓词下推减少 IO扫描,加速分析。
在大数据的海量低成本要求下,稀疏索引可以做到降低存储成本并且加速分析性能,通过减少数据扫描量达到性能提升。具体分两步:第一步数据要进行 Cluster,类似的数聚在一起,结合引擎谓词下推,性能达到10X 以上的提升。同时也能带来存储的下降,这个原理其实很容易理解,类似的数据在一起了,Encodin 压缩能起到更好的效果。这也是大数据引擎,比如说像 CK、Doris 很重要的性能加速模型。
稳定性也是大数据很重要的诉求,前面看到像索引的构建都需要进行大规模的数据 ETL。对于稳定性我们遇到了很多挑战,包括虚拟集群弹性模型本身减少了弹性引擎的数据倾斜、Iceberg 减少底层 List、Rename导致任务失败等等问题。这里我们主要分享下 DLC 的 Spark Shuffle Manager 架构。
我们知道腾讯开源了 RSS 的服务 Filestorm,在全托管云原生的场景下我们做了简化和改造,原理是:优先使用本地磁盘,不足的时候 Spill 到 Cos,下面是业界几种典型的思路,DLC 的做法秉持着减少服务引入、保持简单、降低用户成本、减少用户/服务的运维。效果也很明显,大部分任务 /Task 都会以原有的性能完成,少量数据倾斜的任务 /Task 会损失一定的性能,但是依然能稳定完成。
DLC 作为全托管的产品,还是要强调一下低成本和易用的特性。COS 湖存储 VS 自建 HDFS 的成本优势,其实 80% 以上节省来至于 EC、HDFS 要预留资源以及 COS 有各种冷热分层策略进一步降低成本等。基于 EKS 或者 TKE 弹性资源,对比固定资源节省约 50% 以上的成本,如果是交互式分析场景,周六周日两天成本就是节省的,晚上也是节省的,离线是类似的。
最后 DLC 是全托管的免运维的一个产品,统一的 SQL 在两个引擎平滑迁移,SaaS的元数据、DDL服务、权限、调度、SaaS级别的Spark History 保障了用户开箱即用,而且这些公共服务大部分免费,有的是有免费额度的,正确使用都完全够用。

湖仓背景下的建模新思路
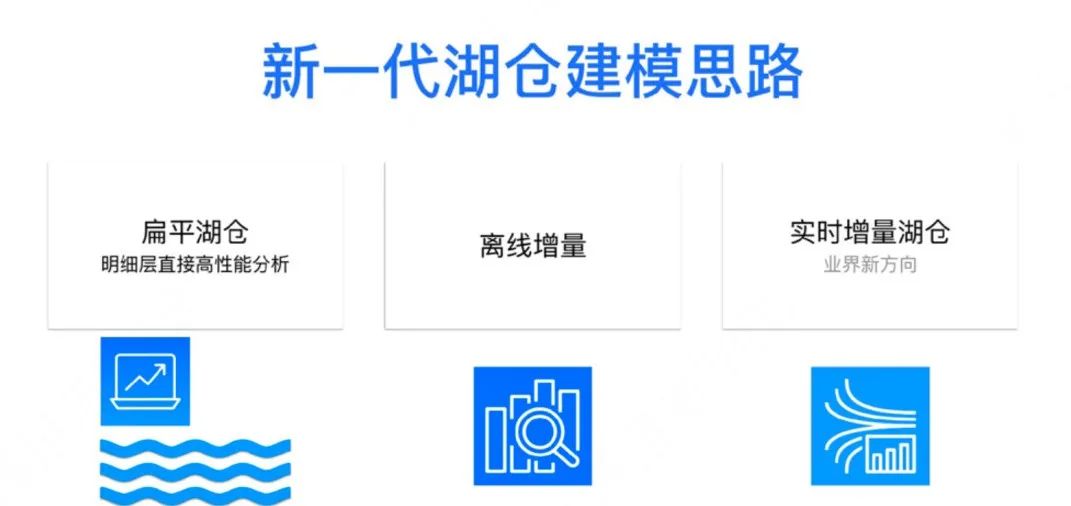
接下来一起看下,在云原生湖仓架构下,建模有有哪些新思路:
第一个,扁平湖仓架构,核心是不再维护复杂的数仓分层,而是把明细层的数据能够直接高性能分析;第二个是离线增量;第三个,现在业界比较时髦的新方向实时增量湖仓。
仔细讲一下扁平湖仓的结构,要解释为什么需要扁平湖仓建模,首先要看一下为什么要一层层去做分层建模。首先是在传统的数仓架构下,明细数据的分析的性能不够高,被迫去进行的预计算,同时因为多个结果可能会重复利用一部分公共数据,进行了 ETL 抽取。但是在 PB 级数据秒级分析的能力下,这些几乎都是不必要的。
层层建模的问题:第一是模式是固定的,不够敏捷。响应需求,从需求对接、历史数据刷新、测试验收,一两个周就过去了;其次是计算利用率往往是低的,尤其 Cube。Cube 虽然命中很快,单 Cube 的利用率往往是个大大的问号,从我们的经验来看其实非常低;另外分层离线更新是比较慢的,而现在特别火的实时增量更新并不是成熟和稳定,即使落地了对于存储和计算硬件的需求往往也是很高的。
结合前面讲的云原生湖仓做性能提升的各种手段,在明细层直接分析的扁平湖仓架构的时代自然是大势所趋了。当然最好能结合 BI 工具的时序结果缓存,这样 BI 层都可以省去。
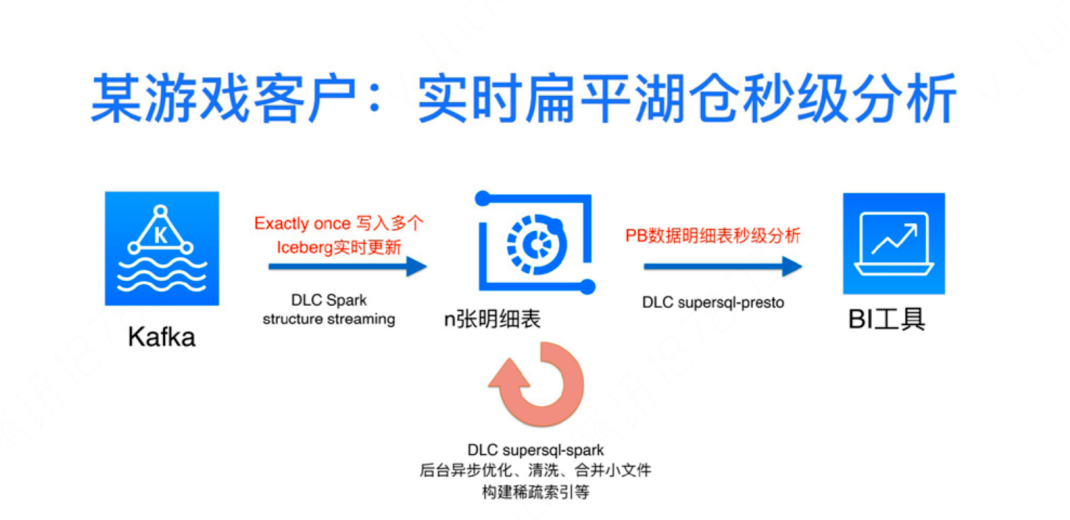
最后介绍下一个游戏客户的案例:实时扁平湖仓秒级分析——逻辑架构非常简单直接,数据都是在 Kafka,通过 DLC Spark 去做实时数据的接入,直接写入几百张Iceberg 明细表,并且能够保证幂等。值得注意的是一个 Kafka 里面有很多张表的数据,保证幂等也有一些比较有意思的逻辑。入到明细表之后,开启明细表背后的一些优化,用 DLC SuperSQL—Spark,进行清洗、合并小文件、以及稀疏索引构建等,最后达到的效果直接用 DLC SuperSQL-Presto 去做秒级分析,最后去对接 BI 的工具,达到一个非常好的分析性能,架构简单明了,无需各种建模。
你可能感兴趣的腾讯工程师作品


后台回复“湖仓”,领本文作者推荐的更多资料

🔹关注我并点亮星标🔹
工作日晚8点 看腾讯技术、学专家经验

我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
目录SpringBootStarter是什么?以前传统的做法使用SpringBootStarter之后starter的理念:starter的实现: 创建SpringBootStarter步骤在idea新建一个starter项目、直接执行下一步即可生成项目。 在xml中加入如下配置文件:创建proterties类来保存配置信息创建业务类:创建AutoConfiguration测试如下:SpringBootStarter是什么? SpringBootStarter是在SpringBoot组件中被提出来的一种概念、简化了很多烦琐的配置、通过引入各种SpringBootStarter包可以快速搭建出一
我尝试用Ruby设计一个基于Web的应用程序。我开发了一个简单的核心应用程序,在没有框架和数据库的情况下在六边形架构中实现DCI范例。核心六边形中有小六边形和网络,数据库,日志等适配器。每个六边形都在没有数据库和框架的情况下自行运行。在这种方法中,我如何提供与数据库模型和实体类的关系作为独立于数据库的关系。我想在将来将框架从Rails更改为Sinatra或数据库。事实上,我如何在这个核心Hexagon中实现完全隔离的rails和mongodb的数据库适配器或框架适配器。有什么想法吗? 最佳答案 ROM呢?(Ruby对象映射器)。还有
三大公有云厂商,香港地区主机测评一、ping时延比对(厦门电信本地测试):Ping时延测试腾讯云阿里云华为云延迟率最低时延44ms,最高72ms,平均46ms47.242段:最低时延59ms,最高204ms,平均107ms最低时延45ms,最高93ms,平均47ms丢包率丢包率小有的ip段丢包率较大每个段都会有概率丢包阿里云:47.242段:最低时延59ms,最高204ms,平均107ms,有的ip段丢包率较大8.210段:最低时延64ms,最高232ms,平均119ms,丢包率较好腾讯云:最低时延44ms,最高72ms,平均46ms,丢包率小华为云:最低时延45ms,最高93ms,平均47m
“架设一个亿级高并发系统,是多数程序员、架构师的工作目标。许多的技术从业人员甚至有时会降薪去寻找这样的机会。但并不是所有人都有机会主导,甚至参与这样一个系统。今天我们用12306火车票购票这样一个业务场景来做DDD领域建模。”开篇要实现软件设计、软件开发在一个统一的思想、统一的节奏下进行,就应该有一个轻量级的框架对开发过程与代码编写做一定的约束。虽然DDD是一个软件开发的方法,而不是具体的技术或框架,但拥有一个轻量级的框架仍然是必要的,为了开发一个支持DDD的框架,首先需要理解DDD的基本概念和核心的组件。一.什么是领域驱动设计(DDD)首先要知道DDD是一种开发理念,核心是维护一个反应领域概
我在/usr/local/lib中安装了一些本地库。我现在正在尝试安装一个需要这些的gem,以便正确构建,但是gem构建失败,因为它找不到图书馆。gem的extconf.rb文件试图确认它可以找到库have_library()但由于某种原因失败了。我尝试设置一堆环境变量,但似乎没有任何效果:irb(main):003:0>require'mkmf'=>trueirb(main):004:0>have_library('gecodesearch')checkingformain()in-lgecodesearch...no=>falseirb(main):005:0>ENV['LD_LI
我在当前项目中使用由Oracle数据库和memcached支持的RubyonRails。有一个非常常用的功能,它依赖于单个数据库View作为数据源,并且该数据源内部有其他数据库View和表。这是一个虚拟数据库View,能够从一个地方访问所有内容,而不是物化数据库View。大多数情况下,如果用户正在使用他们希望更新的功能,那么让数据保持最新很重要。从这个View获取数据时,我将安全表内部连接到View(安全表不是View本身的一部分),其中包含一些我们用来在更细粒度级别上控制数据访问的字段。例如,安全表有user_id,prop_1,prop_2列,其中prop_1,prop_2是数据库
文章目录Kubernetes(k8s)工作负载一、Workloads二、Pod三、Deployment四、RC、RS、DaemonSet、StatefulSet五、Job、CronJob1、Job2、CronJob六、GCKubernetes(k8s)工作负载一、Workloads什么是工作负载(Workloads)工作负载是运行在Kubernetes上的一个应用程序。一个应用很复杂,可能由单个组件或者多个组件共同完成。无论怎样我们可以用一组Pod来表示一个应用,也就是一个工作负载Pod又是一组容器(Containers)所以关系又像是这样工作负载(Workloads)控制一组PodPod控制
我正在开发一个包含大约10个不同功能组件的Sinatra应用程序。我们希望能够将这些组件混合并匹配到应用程序的单独实例中,完全从config.yaml文件配置,如下所示:components:-route:'/chunky'component_type:FoodListercomponent_settings:food_type:baconmax_items:400-route:'places/paris'component_type:Mappercomponent_settings:latitude:48.85387273165654longitude:2.340087890625-
前阵InfoQ社区看到腾讯云腾讯云区块链服务平台(TBaaS)长安链体验活动,一顿操作猛如虎报了个名,体验完用一个字概括:强。非要再加几个字的话,总体感受下来装配模式灵活高效,配套工具完整辩解。话不多说开始主题本文目录结构分为区块链分类和TBaaS平台介绍、TBaaS平台上链教程三个部分一、区块链分类:大体上来说,区块链可分为公链,联盟链,私有链三种:公有链(PublicBlockchain)公有链是指任何人都能参与的区块链。公有链是去中心化程度最高的区块链,不受机构控制,整个账本对所有人公开透明。任何人都能在公有链上查询交易、发送交易、参与记账。加入公有链不需要任何人授权,可以自由加入或者离