C 题 电商物流网络包裹应急调运与结构优化问题
电商物流网络由物流场地(接货仓、分拣中心、营业部等)和物流场地之间的运输线路组成,如图 1 所示。受节假日和“双十一”、“618”等促销活动的影响,电商用户的下单量会发生显著波动,而疫情、地震等突发事件导致物流场地临时或永久停用时,其处理的包裹将会紧急分流到其他物流场地,这些因素均会影响到各条线路运输的包裹数量,以及各个物流场地处理的包裹数量。
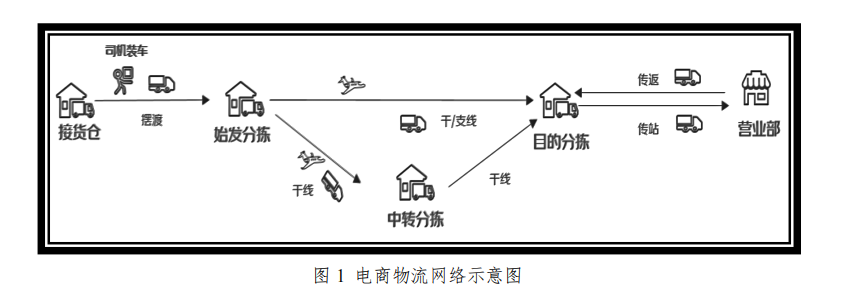
如果能预测各物流场地及线路的包裹数量(以下简称货量),管理者将可以提前安排运输、分拣等计划,从而降低运营成本,提高运营效率。特别地,在某些场地临时或永久停用时,基于预测结果和各个物流场地的处理能力及线路的运输能力,设计物流网络调整方案,将会大大降低物流场地停用对物流网络的影响,保障物流网络的正常运行。
附件 1 给出了某物流网络在 2021-01-01 至 2022-12-31 期间每天不同物流场地之间流转的货量数据,该物流网络有 81 个物流场地,1049 条线路。其中线路是有方向的,比如线路 DC1→DC2 和线路 DC2→DC1 被认为是两条线路。假设每个物流场地的处理能力和每条线路的运输能力上限均为其历史货量最大值。
基于以上背景,请你们团队完成以下问题:
问题 1:建立线路货量的预测模型,对 2023-01-01 至 2023-01-31 期间每条线路每天的货量进行预测,并在提交的论文中给出线路 DC14→DC10、DC20→DC35、DC25→DC62 的预测结果。
问题 2:如果物流场地 DC5 于 2023-01-01 开始关停,请在问题 1 的预测基础上,建立数学模型,将 DC5 相关线路的货量分配到其他线路使所有包裹尽可能正常流转,并使得 DC5 关停前后货量发生变化的线路尽可能少,且保持各条线路的工作负荷尽可能均衡。如果存在部分日期部分货量没有正常流转,你们的分流方案还应使得 2023-01-01 至 2023-01-31 期间未能正常流转的包裹日累计总量尽可能少。正常流转时,请给出因 DC5 关停导致货量发生变化的线路数及网络负荷情况;不能正常流转时,请给出因 DC5关停导致货量发生变化的线路数、不能正常流转的货量及网络的负荷情况。
问题 3:在问题 2 中,如果被关停的物流场地为 DC9,同时允许对物流网络结构进行动态调整(每日均可调整),调整措施为关闭或新开线路,不包含新增物流场地,假设新开线路的运输能力的上限为已有线路运输能力的最大值。请将 DC9 相关线路的货量分配到其他线路,使所有包裹尽可能正常流转,并使得 DC9 关停前后货量发生变化的线路数尽可能少,且保持各条线路的工作负荷尽可能均衡。如果存在部分日期没有满足要求的流转方案,你们的分流方案还应使得 2023-01-01 至 2023-01-31 期间未能正常流转的包裹日累计总量尽可能少。正常流转时,请给出因 DC9 关停导致货量发生变化的线路数及网络负荷情况;不能正常流转时,请给出因 DC9 关停导致货量发生变化的线路数、不能正常流转的货量及网络的负荷情况;同时请给出每天的线路增减情况。
问题 4:根据附件 1,请对该网络的不同物流场地及线路的重要性进行评价;为了改善网络性能,如果打算新增物流场地及线路,结合问题 1 的预测结果,探讨分析新增物流场地应与哪几个已有物流场地之间新增线路,新增物流场地的处理能力及新增线路的运输能力应如何设置?考虑到预测结果的随机性,请进一步探讨你们所建网络的鲁棒性。
建立线路货量的预测模型,对 2023-01-01 至 2023-01-31 期间 每条线路每天的货量进行预测,并在提交的论文中给出线路 DC14→DC10、 DC20→DC35、DC25→DC62 的预测结果。
思路:第一问相当简单,对于某条线路,比如DC14→DC10,先把数据从表中提取出来(这里建议用python+panda模块),对每条线路进行的数量进行线性预测,或者时间序列预测
Python panda使用样例:
import pandas as pd
# 读取Excel表格
df = pd.read_excel('your_excel_file.xlsx')
# 打印表格中的数据(前5行)
print(df.head())
注意:由于数据量较小不适合使用任何深度学习预测方法,比如lstm,小数据量预测出来的结果基本都是错的。
篇幅有限详细思路写在文档里

🥇 最新思路更新(看最新发布的文章即可):
https://blog.csdn.net/dc_sinor?type=blog
🥇 最新思路更新(看最新发布的文章即可):
https://blog.csdn.net/dc_sinor?type=blog
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
我希望Ruby的解析器会进行这种微不足道的优化,但似乎并没有(谈到YARV实现,Ruby1.9.x、2.0.0):require'benchmark'deffib1a,b=0,1whileb由于这两种方法除了在第二种方法中使用预定义常量而不是常量表达式外是相同的,因此Ruby解释器似乎在每个循环中一次又一次地计算幂常数。是否有一些Material说明为什么Ruby根本不进行这种基本优化或只在某些特定情况下进行? 最佳答案 很抱歉给出了另一个答案,但我不想删除或编辑我之前的答案,因为它下面有有趣的讨论。正如JörgWMittag所说,
我正在尝试从数据库中读取大量单元格(超过100.000个)并将它们写入VPSUbuntu服务器上的csv文件。碰巧服务器没有足够的内存。我正在考虑一次读取5000行并将它们写入文件,然后再读取5000行,等等。我应该如何重构我当前的代码以使内存不会被完全消耗?这是我的代码:defwrite_rows(emails)File.open(file_path,"w+")do|f|f该函数由sidekiqworker调用:write_rows(user.emails)感谢您的帮助! 最佳答案 这里的问题是,当您调用emails.each时,
link有两个组件:componenta_id和componentb_id。为此,在Link模型文件中我有:belongs_to:componenta,class_name:"Component"belongs_to:componentb,class_name:"Component"validates:componenta_id,presence:truevalidates:componentb_id,presence:truevalidates:componenta_id,uniqueness:{scope::componentb_id}validates:componentb_id
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
文章目录前言约束硬约束的轨迹优化Corridor-BasedTrajectoryOptimizationBezierCurveOptimizationOtherOptions软约束的轨迹优化Distance-BasedTrajectoryOptimization优化方法前言可以看看我的这几篇Blog1,Blog2,Blog3。上次基于MinimumSnap的轨迹生成,有许多优点,比如:轨迹让机器人可以在某个时间点抵达某个航点。任何一个时刻,都能数学上求出期望的机器人的位置、速度、加速度、导数。MinimumSnap可以把问题转换为凸优化问题。缺点:MnimumSnap可以控制轨迹一定经过中间的
我对为我的RubyonRails3.1.3应用优化我的Unicorn设置的方法很感兴趣。我目前正在高CPU超大实例上生成14个工作进程,因为我的应用程序在负载测试期间似乎受CPU限制。在模拟负载测试中,每秒大约20个请求重放请求,我的实例上的所有8个内核都达到峰值,盒子负载飙升至7-8个。每个unicorn实例使用大约56-60%的CPU。我很好奇可以通过哪些方式对其进行优化?我希望能够每秒将更多请求汇集到这种大小的实例上。内存和所有其他I/O一样完全正常。在我的测试过程中,CPU越来越低。 最佳答案 如果您受CPU限制,您希望使用