📢 MySQL 系列专栏持续更新中 … MySQL专栏
操作关系型数据库的编程语言,定义了一套操作关系型数据库的统一标准,简称SQL。
1 . SQL语句可以单行或多行书写,以分号结尾。
2 . SQL语句可以使用空格/缩进来增强语句的可读性。
3 . MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
| 分类 | 说明 |
|---|---|
| DDL(deifnition) | 数据定义语言(用来定义数据库对象,数据库,表,字段) |
| DML(manipulation) | 数据操纵语言(对数据库 表中的是数据进行增删改) |
| DQL(query) | 数据查询语言,用来查询数据库中表的记录 |
| DCL(control) | 数据控制语言,用来创建数据库用户,控制数据库的访问权限 |
同一个数据库中,不能有两个表的名字相同,表名和列名不能和SQL的关键词重复。
语法:
create table 表名(定义列1, 定义列2, .......);
列 -> 变量名 数据类型
mysql> create table if not exists book(
-> book_name varchar(32) comment '图书名称',
-> book_author varchar(32)comment '图书作者' ,
-> book_price decimal(12,2) comment '图书价格',
-> book_category varchar(12) comment '图书分类',
-> publish_data timestamp
-> )character set utf8mb4;
Query OK, 0 rows affected (0.04 sec)
语法:
show tables;
举例:
mysql> show tables;
+--------------------+
| Tables_in_mytestdb |
+--------------------+
| book |
+--------------------+
1 row in set (0.00 sec)
语法:
desc 表名;
举例:
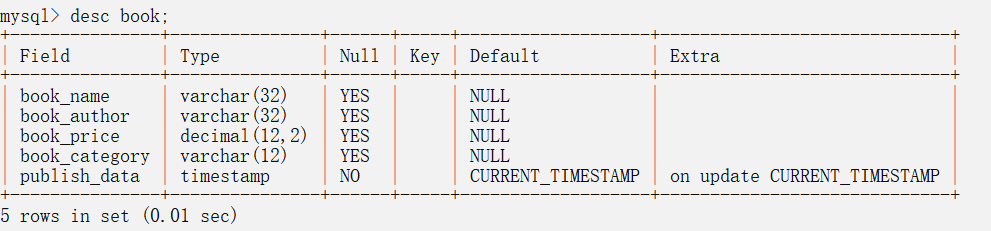
MySQL数据库中的表结构主要包含以下几种信息: 字段名称,字段类型,是否允许为空,索引类型。默认值,扩充信息
drop table 表名
mysql> desc test1;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| name | varchar(10) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.02 sec)
mysql> drop table test1;
Query OK, 0 rows affected (0.04 sec)
mysql> desc test1;
ERROR 1146 (42S02): Table 'mytestdb.test1' doesn't exist
语法:
rename table old_name to new_name;
举例:
mysql> rename table book to eBook;
Query OK, 0 rows affected (0.05 sec)
mysql> show tables;
+--------------------+
| Tables_in_mytestdb |
+--------------------+
| ebook |
+--------------------+
1 row in set (0.00 sec)
CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
案例:
-- 创建一张图书表
mysql> create table if not exists book(
-> book_name varchar(32) comment '图书名称',
-> book_author varchar(32)comment '图书作者' ,
-> book_price decimal(12,2) comment '图书价格',
-> book_category varchar(12) comment '图书分类',
-> publish_data timestamp
-> )character set utf8mb4;
单行插入(全列)
insert into 表名 values(对应列的参数列表);
-- 一次插入一行
多行插入(全列)
insert into 表名 values(对应列的实参列表), (对应列的参数列表), (对应列的参数列表);
-- 一次插入多行
指定列插入
- values 后面( )中的内容, 个数和类型要和表名后面( )中指定的结构匹配.
- 未被指定的列会以默认值进行填充.
insert into 表名 (需要插入的列) values(对应列的参数列表);
-- 一次插入一行
insert into 表名 (需要插入的列) values(对应列的参数列表), (), ()....
-- 一次插入多行
案例
# 单行输入
mysql>
insert into book values('计算机网络','谢希仁',45,'计算机类','2020-12-25 12:51:00');
Query OK, 1 row affected (0.01 sec)
#多行输入
mysql>
insert into book values('计算机组成原理','王峰',45,'硬件类','2020-12-12 12:00:00'),
-> ('微机原理','李华',97,'硬件类','2000-12-19 20:00:00');
Query OK, 2 rows affected (0.04 sec)
Records: 2 Duplicates: 0 Warnings: 0
#指定列插入
mysql>
insert into book(book_name,book_author,publish_data) values ('软件工程','张三','2020-05-06 12:00:00');
Query OK, 1 row affected (0.02 sec)
插入数据后的表如图所示:
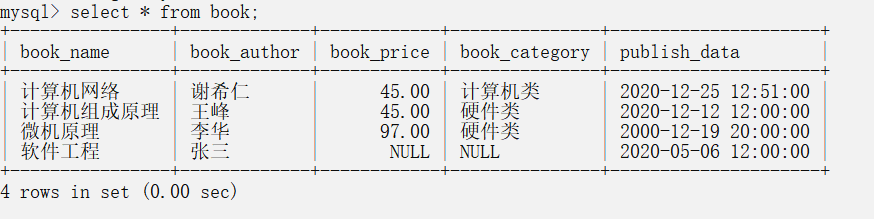
在MySQL当中 , 多条记录逐次插入的效率是要低于一次把多条纪录一起插入的 ,原因如下:
- 网络请求和响应时间开销 , 每次插入都会有一定的时间开销.
- 数据库服务器是把数据保存在硬盘上的 , IO操作时,操作的次数带来的影响大于数据量.
- 每一次sql操作,内部开启的事务也会占据一定的开销.
语法
select * from 表名
-- * 表示通配符, 可以匹配表中的所有列.
企业级别的数据库中慎用, 容易把I/O或者网络带宽吃满,如果有外边的用户客户端要通过宽带访问服务器时,服务器就无法做出正确的响应.
示例
select * from book;
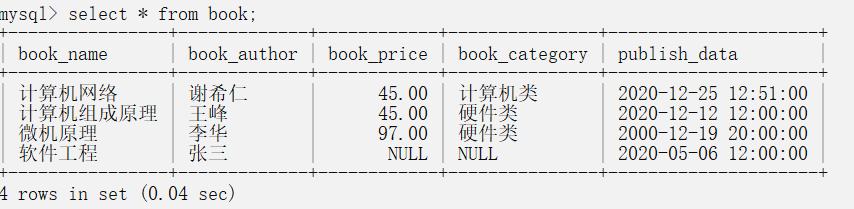
select 列名... from 表名
)mysql> select book_name from book;
+----------------+
| book_name |
+----------------+
| 计算机网络 |
| 计算机组成原理 |
| 微机原理 |
| 软件工程 |
+----------------+
4 rows in set (0.01 sec)
mysql> select book_author,book_price from book;
+-------------+------------+
| book_author | book_price |
+-------------+------------+
| 谢希仁 | 45.00 |
| 王峰 | 45.00 |
| 李华 | 97.00 |
| 张三 | NULL |
+-------------+------------+
4 rows in set (0.00 sec)
select 字段或表达式, 字段或表达式... from 表名;
-- 查询图书涨价10元后所有图书的名称作者和价格
mysql> select book_name ,book_author,book_price + 10 from book;
+----------------+-------------+-----------------+
| book_name | book_author | book_price + 10 |
+----------------+-------------+-----------------+
| 计算机网络 | 谢希仁 | 55.00 |
| 计算机组成原理 | 王峰 | 55.00 |
| 微机原理 | 李华 | 107.00 |
| 软件工程 | 张三 | NULL |
+----------------+-------------+-----------------+
4 rows in set (0.00 sec)
mysql中支持给所查询的表达式取一个别名 , 使用 as 可以使查询结果更加直观 , 代码的可读性也会更强.
select 列名或表达式 as 别名, ... from 表名;
-- 将涨价20元后的图书价格取为别名newprice
mysql> select book_name,book_author,book_price + 20 as newprice from book;
+----------------+-------------+----------+
| book_name | book_author | newprice |
+----------------+-------------+----------+
| 计算机网络 | 谢希仁 | 65.00 |
| 计算机组成原理 | 王峰 | 65.00 |
| 微机原理 | 李华 | 117.00 |
| 软件工程 | 张三 | NULL |
+----------------+-------------+----------+
4 rows in set (0.00 sec)
select distinct 列名 from 表名
--book 表中插入一条重复的book_name数据
mysql> insert into book values('计算机网络','张华',89,'计算机类','2020-11-23 11:00:00');
Query OK, 1 row affected (0.00 sec)
mysql> select book_name from book;
+----------------+
| book_name |
+----------------+
| 计算机网络 |
| 计算机组成原理 |
| 微机原理 |
| 软件工程 |
| 计算机网络 |
+----------------+
5 rows in set (0.00 sec)
mysql> select distinct book_name from book;
+----------------+
| book_name |
+----------------+
| 计算机网络 |
| 计算机组成原理 |
| 微机原理 |
| 软件工程 |
+----------------+
4 rows in set (0.00 sec)
查询结果当中,没有了重复的book _ name 元素,达到了去重效果.
select 列名
from 表名
order by 列名 asc(升序)/desc(降序);
# 想要排序的列
# 按照书的价格升序进行排列
mysql> select book_name,book_price from book order by book_price asc;
+----------------+------------+
| book_name | book_price |
+----------------+------------+
| 软件工程 | NULL |
| 计算机网络 | 45.00 |
| 计算机组成原理 | 45.00 |
| 计算机网络 | 89.00 |
| 微机原理 | 97.00 |
+----------------+------------+
5 rows in set (0.00 sec)
#按照书的价格降序进行排列
mysql> select book_name,book_price from book order by book_price desc;
+----------------+------------+
| book_name | book_price |
+----------------+------------+
| 微机原理 | 97.00 |
| 计算机网络 | 89.00 |
| 计算机网络 | 45.00 |
| 计算机组成原理 | 45.00 |
| 软件工程 | NULL |
+----------------+------------+
5 rows in set (0.00 sec)
- 使用排序查询时 , 升序查询 asc 可以省略, 即默认为升序排列, null值一定为其中最小的.
- 可以对多个字段进行排序,优先级按照书写的顺序进行.
# 查询按照价格升序 ,年份降序
select name,price,age from book order by price asc,age desc;
#查询按照总成绩进行降序
select name,english+math+chinese as total from grade order by total desc;
当我们使用查询时, 通常具有各种各样的前提条件 , 此时就需要使用条件查询来完成.
select 列名.. from 表名..where + 条件
比较运算符
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,null 不安全,例如 null = null 的结果是 null(false) |
| <=> | 等于,null 安全,例如 null <=> null 的结果是 true(1) |
| !=, <> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 true(1) |
| in (option, …) | 如果是 option 中的任意一个,返回 true(1) |
| is null | 是 null |
| is not null | 不是 null |
| like | 模糊匹配; % 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符
| 运算符 | 说明 |
|---|---|
| and | 多个条件必须为 true , 结果才为true |
| or | 任意一个条件为true 结果才为true |
| not | 条件为true , 结果为false |
注:
WHERE条件可以使用表达式,但不能使用别名。
AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
-- 查询图书价格低于50的图书作者和图书名称
mysql> select book_name,book_author from book where book_price < 50;
+----------------+-------------+
| book_name | book_author |
+----------------+-------------+
| 计算机网络 | 谢希仁 |
| 计算机组成原理 | 王峰 |
+----------------+-------------+
2 rows in set (0.05 sec)
-- 查询图书价格等于97的图书作者
mysql> select book_name ,book_author from book where book_price = 97;
+-----------+-------------+
| book_name | book_author |
+-----------+-------------+
| 微机原理 | 李华 |
+-----------+-------------+
1 row in set (0.00 sec)
-- 查询图书价格在50 - 100 之间的图书名称
mysql> select book_name from book where book_price between 50 and 100;
+------------+
| book_name |
+------------+
| 微机原理 |
| 计算机网络 |
+------------+
2 rows in set (0.02 sec)\
-- 查询图书价格在此范围内的图书名称
mysql> select book_name from book where book_price in (12,45);
+----------------+
| book_name |
+----------------+
| 计算机网络 |
| 计算机组成原理 |
+----------------+
2 rows in set (0.00 sec)
模糊查询
- % 匹配任意多个(包括 0 个)字符
- _ 匹配严格的一个字符
#查询姓张的作者的书本价格书名.
mysql> select book_price,book_name,book_author from book where book_author like '张%';
+------------+------------+-------------+
| book_price | book_name | book_author |
+------------+------------+-------------+
| NULL | 软件工程 | 张三 |
| 89.00 | 计算机网络 | 张华 |
+------------+------------+-------------+
2 rows in set (0.00 sec)
# 查询前缀为'计算机'后缀为七个字的书籍名称
mysql> select book_name from book where book_name like '计算机____';
+----------------+
| book_name |
+----------------+
| 计算机组成原理 |
+----------------+
#查询前缀为'计算机'的书籍名称并去重
mysql> select distinct book_name from book where book_name like '计算机%';
+----------------+
| book_name |
+----------------+
| 计算机网络 |
| 计算机组成原理 |
+----------------+
2 rows in set (0.00 sec)
分页查询即将查询出的结果 , 按页进行呈现,并不是一次性展现出来,这种模式就是分页查询, mysql当中使用limit来实现分页查询.
- limit 子句当中接受一个或者两个参数 , 这两个参数的值为0 或者正整数
两个参数的limit子句的用法
select 元素1,元素2 from 表名 limit offset,count;
#offset参数指定要返回的第一行的偏移量。第一行的偏移量为0,而不是1。
#count指定要返回的最大行数。
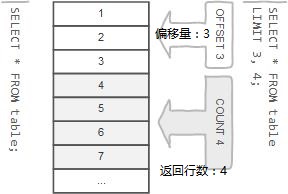
示例:
mysql> select book_author from book limit 2, 3;
+-------------+
| book_author |
+-------------+
| 李华 |
| 张三 |
| 张华 |
+-------------+
3 rows in set (0.02 sec)
#表示获取列表当中偏移量为2(表示从第3行开始), 最大行数为3的作者名称
带有一个参数的limit子句的用法
select 列名1.列名2 from 表名 limit count;
# 表示从结果集的开头返回的最大行数为count;
# 获取前count行的记录
等同于
select 列名1 ,列名2 from 表名 limit 0 , count;
# 第一行的偏移量为0
示例
mysql> select book_price from book limit 5;
+------------+
| book_price |
+------------+
| 45.00 |
| 45.00 |
| 97.00 |
| NULL |
| 89.00 |
+------------+
5 rows in set (0.00 sec)
# 获取表中前五行的图书价格 , 最大行数为5
limit 结合 order by 语句 和其他条件可以获取n个最大或者最小值
select book_name,book_price from book order by book_price desc limit 3;
#获取价格前三高的图书名称和图书价格
mysql> select book_price,book_name from book order by book_price desc limit 3;
+------------+------------+
| book_price | book_name |
+------------+------------+
| 97.00 | 微机原理 |
| 89.00 | 计算机网络 |
| 45.00 | 计算机网络 |
+------------+------------+
3 rows in set (0.01 sec)
使用limit 获取第n高个最大值
偏移量从
0开始,所以要指定从n - 1 开始,然后取一行记录
#示例:获取价格第二高的图书名称
mysql> select book_name from book order by book_price desc limit 1,1;
+------------+
| book_name |
+------------+
| 计算机网络 |
+------------+
1 row in set (0.00 sec)
MySQL当中使用update关键字来对数据进行修改 , 既可以修改单列又可以修改多列.
update 表名 set 列名1 = 值 , 列名2 = 值 ... where 限制条件下修改
SET子句指定要修改的列和新值。要更新多个列,请使用以逗号分隔的列表。以字面值,表达式或子查询的形式在每列的赋值中来提供要设置的值。- 第三,使用WHERE子句中的条件指定要更新的行。
WHERE子句是可选的。 如果省略WHERE子句,则UPDATE语句将更新表中的所有行。
示例:
#将书名为'软件工程'的图书价格修改为66元
mysql> update book set book_price = 66 where book_name = '软件工程';
Query OK, 1 row affected (0.05 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select book_price from book where book_name = '软件工程';
+------------
| book_price |
+------------+
| 66.00 |
+------------+
1 row in set (0.00 sec)
#将所有的图书价格修改为原来的二倍
mysql> update book set book_price = 2 * book_price;
Query OK, 5 rows affected (0.02 sec)
Rows matched: 5 Changed: 5 Warnings: 0
#更新成功
mysql> select book_price from book;
+------------+
| book_price |
+------------+
| 90.00 |
| 90.00 |
| 194.00 |
| 132.00 |
| 178.00 |
+------------+
5 rows in set (0.00 sec)
要从表中删除数据,需要使用delete 语句, delete 语句的 用法如下
delete from 表名 where + 条件
首先指定需要删除数据的表,其次使用条件指定where子句中删除的行记录, 如果行匹配条件,这些行记录将会删除.
WHERE子句是可选的。如果省略WHERE子句,DELETE语句将删除表中的所有行 , 请注意,一旦删除数据,它就会永远消失。因此,在执行DELETE语句之前,应该先备份数据库,以防万一要找回删除过的数据。
示例
#删除图书表中图书单价大于150的图书记录
mysql> delete from book where book_price > 150;
Query OK, 2 rows affected (0.01 sec)
mysql> select book_price from book;
+------------+
| book_price |
+------------+
| 90.00 |
| 90.00 |
| 132.00 |
+------------+
3 rows in set (0.00 sec)
MySQL中delete 语句也可以结合limit语句 和 order by 语句来控制删除的数量和条件
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
1、接口请求基本操作1.1例子tips在view的选项可以zoomin调整窗口字帖大小。1、创建一个测试的workspace,并命名为test2、test后面新增一个addrequest3、选择发送GET,URL为一个开源的https://api.apiopen.top/api/sentences获取每日一句4、点击send查看内容Tips:如果提示出现Error:tunnelingsocketcouldnotbeestablished,statusCode=407错误,参照以下解决办法)关于tunnelingsocketcouldnotbeestablished,cause=getaddri
Linux操作系统——网络配置与SSH远程安装完VMware与系统后,需要进行网络配置。第一个目标为进行SSH连接,可以从本机到VMware进行文件传送,首先需要进行网络配置。1.下载远程软件首先需要先下载安装一款远程软件:FinalShell或者xhell7FinalShellxhell7FinalShell下载:Windows下载http://www.hostbuf.com/downloads/finalshell_install.exemacOS下载http://www.hostbuf.com/downloads/finalshell_install.pkg2.配置CentOS网络安装好