文章目录

🐱🐉作者简介:大家好,我是黑洞晓威,一名大二学生,希望和大家一起进步。
👿本文收录于 算法,本专栏是针对大学生、初学算法的人准备,解析常见的数据结构与算法,同时备战蓝桥杯。
浏览器的前进、后退功能,我想你肯定很熟悉吧?
当你依次访问完一串页面a-b-c之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面b和a。当你后退到页面a,点击前进按钮,就可以重新查看页面b和c。但是,如果你后退到页面b后,点击了新的页面d,那就无法再通过前进、后退功能查看页面c了。
假设你是浏览器的开发工程师,你会如何实现这个功能呢?
这就要用到我们今天要讲的“栈”这种数据结构。带着这个问题,我们来学习今天的内容。
关于“栈”,我有一个非常贴切的例子,就是一摞叠在一起的盘子。我们平时放盘子的时候,都是从下往上一个一个放;取的时候,我们也是从上往下一个一个地依次取,不能从中间任意抽出。 后进者先出,先进者后出,这就是典型的“栈”结构。
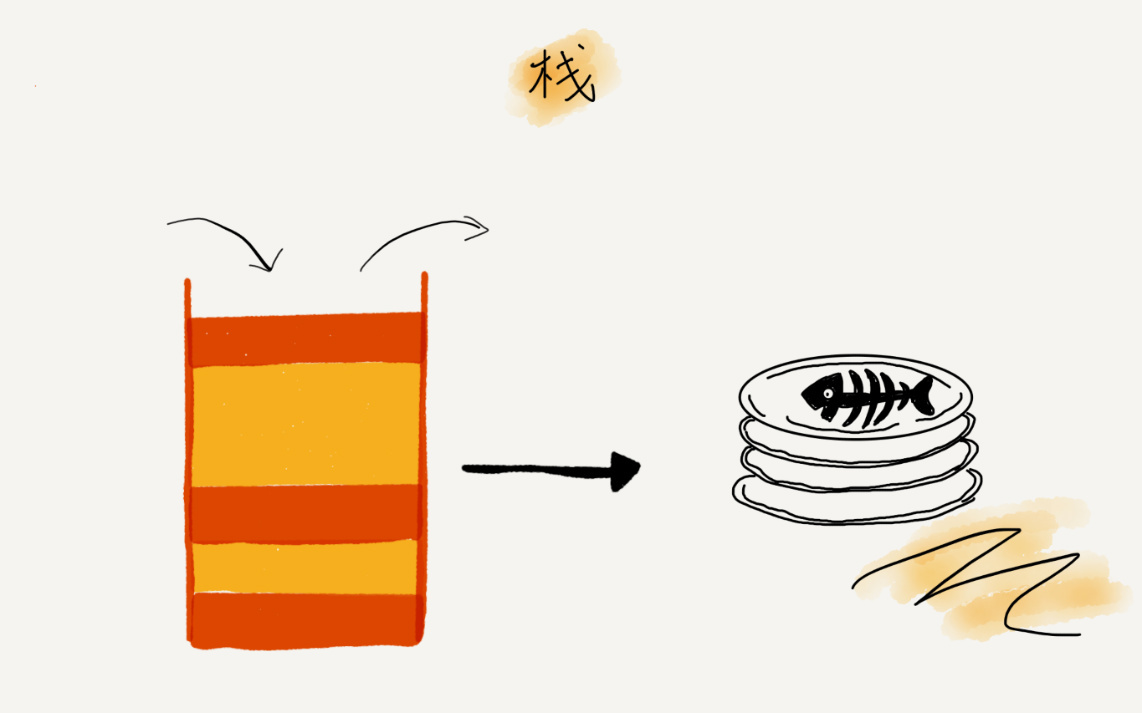
从栈的操作特性上来看, 栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
我第一次接触这种数据结构的时候,就对它存在的意义产生了很大的疑惑。因为我觉得,相比数组和链表,栈带给我的只有限制,并没有任何优势。那我直接使用数组或者链表不就好了吗?为什么还要用这个“操作受限”的“栈”呢?
事实上,从功能上来说,数组或链表确实可以替代栈,但你要知道,特定的数据结构是对特定场景的抽象,而且,数组或链表暴露了太多的操作接口,操作上的确灵活自由,但使用时就比较不可控,自然也就更容易出错。
当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,这时我们就应该首选“栈”这种数据结构。
从刚才栈的定义里,我们可以看出,栈主要包含两个操作,入栈和出栈,也就是在栈顶插入一个数据和从栈顶删除一个数据。理解了栈的定义之后,我们来看一看如何用代码实现一个栈。
实际上,栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作 顺序栈,用链表实现的栈,我们叫作 链式栈。
我这里实现一个基于数组的顺序栈。
// 基于数组实现的顺序栈
public class ArrayStack {
private String[] items; // 数组
private int count; // 栈中元素个数
private int n; //栈的大小
// 初始化数组,申请一个大小为n的数组空间
public ArrayStack(int n) {
this.items = new String[n];
this.n = n;
this.count = 0;
}
// 入栈操作
public boolean push(String item) {
// 数组空间不够了,直接返回false,入栈失败。
if (count == n) return false;
// 将item放到下标为count的位置,并且count加一
items[count] = item;
++count;
return true;
}
// 出栈操作
public String pop() {
// 栈为空,则直接返回null
if (count == 0) return null;
// 返回下标为count-1的数组元素,并且栈中元素个数count减一
String tmp = items[count-1];
--count;
return tmp;
}
}
基于链表实现的链式栈的代码:
/*
* 用链表作为栈的底层
*/
public class SingleLinkedListStack {
// 用链表作为栈的底层
public SingleLinkedList<E> list;
public SingleLinkedListStack() {
list = new SingleLinkedList();
}
@Override
public void push(E e) {
// TODO Auto-generated method stub
list.addFirst(e);
}
@Override
public E pop() {
// TODO Auto-generated method stub
return (E) list.removeFirst();
}
@Override
public E peek() {
// TODO Auto-generated method stub
return list.getfirst();
}
@Override
public int getSize() {
// TODO Auto-generated method stub
return list.getSize();
}
@Override
public boolean isEmpty() {
// TODO Auto-generated method stub
return list.isEmpty();
}
@Override
public String toString() {
StringBuilder sb=new StringBuilder(); sb.append("stack ");
sb.append("push:>");
for(int i=0;i<list.getSize();i++) {
sb.append(list.get(i));
sb.append("->");
}
sb.append("null");
return sb.toString();
}
}
了解了定义和基本操作,那它的操作的时间、空间复杂度是多少呢?
不管是顺序栈还是链式栈,我们存储数据只需要一个大小为n的数组就够了。在入栈和出栈过程中,只需要一两个临时变量存储空间,所以空间复杂度是O(1)。
注意,这里存储数据需要一个大小为n的数组,并不是说空间复杂度就是O(n)。因为,这n个空间是必须的,无法省掉。所以我们说空间复杂度的时候,是指除了原本的数据存储空间外,算法运行还需要额外的存储空间。
空间复杂度分析是不是很简单?时间复杂度也不难。不管是顺序栈还是链式栈,入栈、出栈只涉及栈顶个别数据的操作,所以时间复杂度都是O(1)。
好了,我想现在你已经完全理解了栈的概念。我们再回来看看开篇的思考题,如何实现浏览器的前进、后退功能?其实,用两个栈就可以非常完美地解决这个问题。
我们使用两个栈,X和Y,我们把首次浏览的页面依次压入栈X,当点击后退按钮时,再依次从栈X中出栈,并将出栈的数据依次放入栈Y。当我们点击前进按钮时,我们依次从栈Y中取出数据,放入栈X中。当栈X中没有数据时,那就说明没有页面可以继续后退浏览了。当栈Y中没有数据,那就说明没有页面可以点击前进按钮浏览了。
比如你顺序查看了a,b,c三个页面,我们就依次把a,b,c压入栈,这个时候,两个栈的数据就是这个样子:

当你通过浏览器的后退按钮,从页面c后退到页面a之后,我们就依次把c和b从栈X中弹出,并且依次放入到栈Y。这个时候,两个栈的数据就是这个样子:
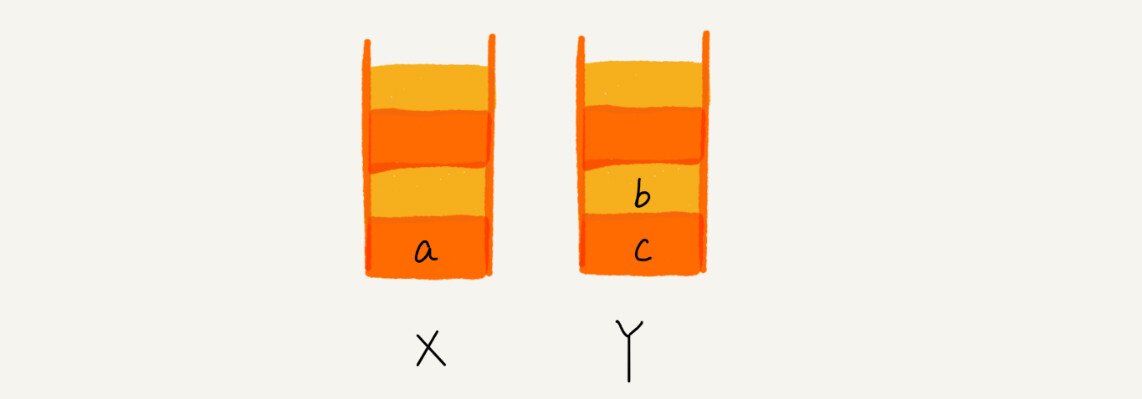
这个时候你又想看页面b,于是你又点击前进按钮回到b页面,我们就把b再从栈Y中出栈,放入栈X中。此时两个栈的数据是这个样子:
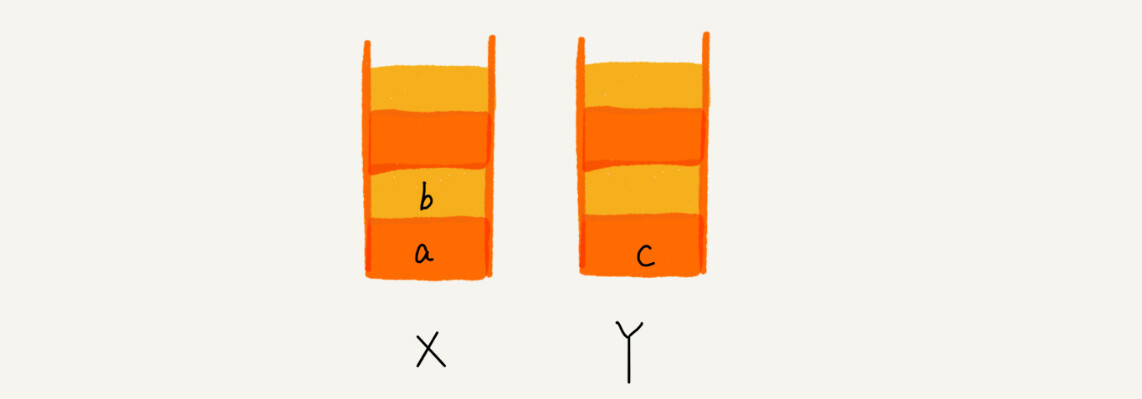
这个时候,你通过页面b又跳转到新的页面d了,页面c就无法再通过前进、后退按钮重复查看了,所以需要清空栈Y。此时两个栈的数据这个样子:
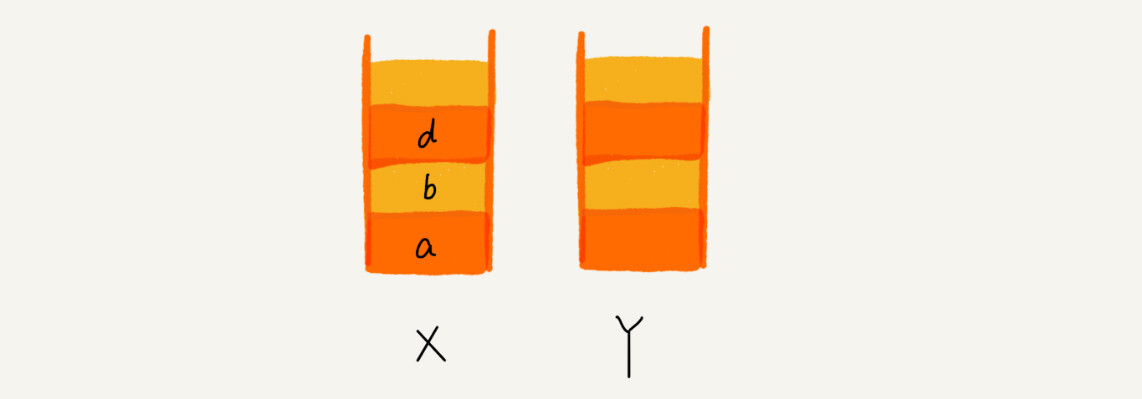
我正在尝试在Ruby中制作一个cli应用程序,它接受一个给定的数组,然后将其显示为一个列表,我可以使用箭头键浏览它。我觉得我已经在Ruby中看到一个库已经这样做了,但我记不起它的名字了。我正在尝试对soundcloud2000中的代码进行逆向工程做类似的事情,但他的代码与SoundcloudAPI的使用紧密耦合。我知道cursesgem,我正在考虑更抽象的东西。广告有没有人见过可以做到这一点的库或一些概念证明的Ruby代码可以做到这一点? 最佳答案 我不知道这是否是您正在寻找的,但也许您可以使用我的想法。由于我没有关于您要完成的工作
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复