本文经AI新媒体量子位(公众号 ID: QbitAI)授权转载,转载请联系出处
国产对话机器人ChatGLM,和GPT-4诞生于同一天。
由智谱AI和清华大学KEG实验室联合推出,开启alpha内测版。
这个巧合让智谱AI创始人兼CEO张鹏有一种说不清的复杂感觉。但看到技术被OpenAI做到这么牛,这名被AI新进展轰炸麻了的技术老兵又猛然亢奋起来。
特别是在追GPT-4发布会直播时,他看一下屏幕里的画面,就埋头笑一阵,再看一段,又咧嘴笑一会儿。
从成立起,张鹏带队的智谱AI就是大模型领域的一员,定下“让机器像人一样思考”的愿景。
但这条路坎坷不断。和几乎所有做大模型的公司遇到的问题一样,缺数据、缺机器,同时还缺钱。好在一路走来,有一些机构和公司提供无偿支持。
去年8月,公司联合一众科研院所,开源的双语预训练大语言模型GLM-130B,能在准确性和恶意性指标上与GPT-3 175B (davinci) 接近或持平,也就是后来ChatGLM的基座。和ChatGLM同时开源的还有个62亿参数版本ChatGLM-6B,千元单卡就可跑的那种。
除了GLM-130B,智谱另一个有名的产品是AI人才库AMiner,学界大佬都在玩:
这一回和GPT-4撞到同一天,OpenAI的速度和技术,让张鹏和智谱团队都有些压力山大。
ChatGLM内测后,量子位第一时间拿到名额, 出了一波人肉测评。
先不说别的,几轮测试下来就不难发现,ChatGLM身上有着包括ChatGPT、新必应在内都拥有的一项本领:
一本正经胡说八道,包括但不限于在鸡兔同笼问题中算出-33只小鸡崽。
对大多数把对话AI当“玩具”或办公助手的人来说,怎么才能提高准确度,是格外被关注和看重的一点。
对话AI一本正经胡说八道这回事,可以纠正吗?又真的需要纠正吗?

△ChatGPT的经典胡说八道语录
张鹏在表达个人意见时说,要去纠正这个“顽疾”,是一件本身就很奇怪的事情。
(保证说的每一句话都正确)这件事连人自己都做不到,却想让一个人造的机器不犯这样的错。
关于这个话题的不同看法与不同人对机器的理解息息相关。张鹏看来,抨击AI有这一行为的人,可能一直以来对机器的理解都是一丝不苟的,它们非0即1,严苛而精确——持有这种观念的人,潜意识认为机器不应该也不能犯错。
知其然与知其所以然同样重要,“这可能源于大家对整个技术的演进和变化,以及技术的本质没有深入理解。”
张鹏用人的学习作为类比:
AI技术的逻辑和原理,其实还是在模拟人的大脑。
面对学习过的东西,一是知识本身可能有错,或有更新迭代(如珠穆朗玛峰的海拔);二是学习的知识之间也存在互相冲突的可能了;三是人也总有犯错、犯迷糊的时候,
AI犯错好比人犯错,原因是缺少知识,或者错误运用了某项知识。
总之,这是很正常的事情。
与此同时,智谱当然关注到了OpenAI向CloseAI的默默转身。
从GPT-3选择闭源,到GPT-4进一步掩盖架构层面的更多细节,OpenAI对外回应的两个原因,一是竞争,二是安全。
OpenAI的用心,张鹏表示理解。
“那走开源路线,智谱没有竞争和安全方面的考虑吗?”
“肯定也会有。但难道闭源就一定能解决安全问题吗?我看未必。而且我相信世界上聪明人很多,竞争是促进整体行业和生态快速往前推进的优质催化剂。”
比如和OpenAI同台竞技,哪怕只是奋起追赶,也是竞争中的一环。
这里的追赶是在陈述过程,建立在认为OpenAI研究方向是通往更远目标路径上的必经之路,但追赶上OpenAI并不是最终目的。
追赶上,不代表可以停下;追赶过程,不代表要原样照搬硅谷模式,甚至可以发挥中国调动顶层设计集中力量办大事的特色和优势,才有可能去弥补发展速度上的差异。
虽然有2019年至今4年多的经验,但智谱还不敢给出什么避坑指南。不过,智谱了解大致对的方向,这也是智谱透露的正在和CCF聊的共同想法——
大模型技术的诞生,是一个非常综合、复杂的系统化工程。
它不再是几个聪明的脑袋在实验室里琢磨,掉几根头发,做点实验,发点paper就了事。除了原始的理论创新,还需要很强的工程实现和系统化能力,甚至还需要很好的产品能力。
就像ChatGPT这样,选择合适场景,设定和封装一个上到80岁、下到8岁都能接触使用的产品。
算力、算法、数据,具体到背后都是人才,尤其是系统工程的从业者,重要程度远远大于往日。
基于这种认知,张鹏透露道,在大模型领域中加入知识系统(知识图谱),让二者像左右脑一样系统工作,是智谱在研究和实验当中的下一步。
ChatGLM整体参考了ChatGPT的设计思路。
也就是在千亿双语基座模型GLM-130B中注入代码预训练,通过有监督微调等技术,实现人类意图对齐(就是让机器的回答符合人类价值观、人类期望)。
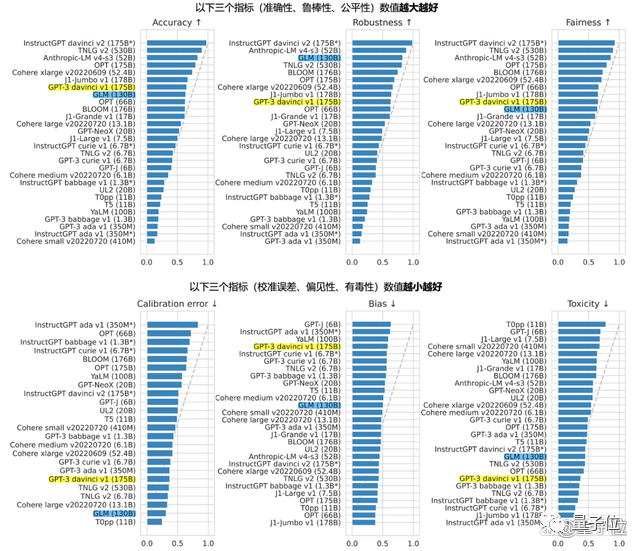
背后1300亿参数的GLM-130B,由智谱和清华大学KEG实验室共同研发。不同于BERT、GPT-3以及T5的架构,GLM-130B是一个包含多目标函数的自回归预训练模型。
去年8月,GLM-130B对外发布,同时开源。Standford报告中,它的表现在多项任务上可圈可点。
对开源的坚持,源于智谱不想做通往AGI道路上孤独的前行者。
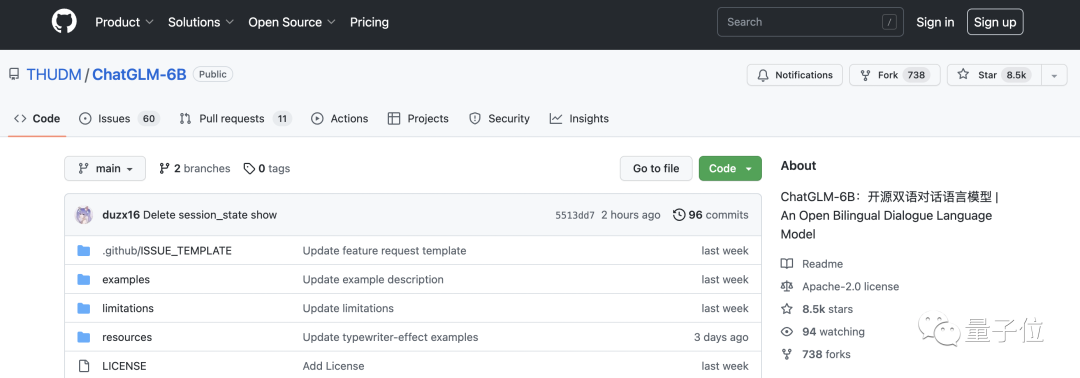
这也是继开源GLM-130B后,今年继续开源ChatGLM-6B的原因。
ChatGLM-6B是模型的“缩小版”,62亿参数大小,技术基底与ChatGLM相同,初具中文问答和对话功能。
持续开源,理由无外乎两点。
一个是希望把预训练模型的生态做大,吸引更多人投入大模型研究,解决现存的很多研究性问题;
另一个是希望大模型作为基础设施沉淀下来,以帮助产生更大的后续价值。
加入开源社区确实很吸引人。ChatGLM内测的几天内,ChatGLM-6B在GitHub上已有8.5k星标,一度跃升trending排行榜上的第一位。
从本次对话中,量子位还从眼前这位从业者身上听到这样的声音:
同样bug频出,但人们对OpenAI推出的ChatGPT,和对谷歌对话机器人Bard、百度文心一言的容忍程度差别明显。
这既公平,又不公平。
从纯技术的角度来说,评判标准不一,这是不公平所在;但谷歌、百度之类的大厂,占据更多资源,大家天然觉得它们技术实力更强,做出更好的东西的可能性更高,期待值就更高。
“希望大家可以给更多的耐心,无论是对百度,对我们,还是其他机构。”

除了上述内容,在本次谈话中,量子位还和张鹏具体聊了聊ChatGLM的体验感受。
下面附上对话实录。为了方便阅读,我们在不改变原意的基础上做了编辑整理。
量子位:内测版本给自己打的标签好像没那么“通用”,官网给它的适用领域框定了三个圈,教育、医疗和金融。
张鹏:这跟训练数据没什么关系,主要是考虑到它的应用场景。
ChatGLM和ChatGPT类似,是一个对话模型。哪些应用领域天然更接近对话场景?像客服,像医生问诊,或者比如线上金融服务。这些场景下,更适合ChatGLM的技术去发挥作用。
量子位:但医疗领域,要看病的人对AI的态度还是比较谨慎的。
张鹏:肯定不能直接拿大模型往上怼啊!(笑)想要完全替代人类,还是要慎重。
现阶段不是用它去代替人工作,更多的是辅助作用,给从业者提供建议来提升工作效率。
量子位:我们把GLM-130B的论文链接扔给ChatGLM,让它简要概括一下主题,它叭叭半天,结果说的根本不是这篇。
张鹏:ChatGLM的设定就是不能获取链接的东西。倒不是技术上的困难,而是系统边界的问题,主要是从安全角度考虑,不希望它任意访问外部链接。
可以试一下把130B的论文文字copy下来扔给输入框,一般不会瞎说。
量子位:鸡兔同笼我们也扔给它了,算出了-33只鸡。
张鹏:在数学处理、逻辑推理方面,它确实还有一定缺陷,做不到那么好。内测说明里我们其实写了这件事。

量子位:知乎有人做了测评,写代码能力好像也一般。
张鹏:至于写代码的能力,我觉得还行啊?不知道你们的测试方式是什么。但具体也要看跟谁比了,和ChatGPT比的话,ChatGLM本身在代码数据的投入可能就没有那么多。
就像ChatGLM和ChatGLM-6B比,后者只有6B(62亿)的参数,整体能力,比如整体的逻辑性、回答时的幻觉和长度上,缩小版和原版的差距就很明显。
但是“缩小版”能在普通电脑上部署,带来的是更高的可用性和更低的门槛。
量子位:它有个优点,对新信息的掌握度不错,知道推特现在的CEO是马斯克,也知道何恺明3月10日回归学界的事情——虽然不知道GPT-4已经发布了,哈哈。
张鹏:我们做了一些特殊的技术处理。
量子位:是什么?
张鹏:具体细节就不展开讲了。但对时间比较近的新信息,是有办法处理的。
量子位:那透露下成本?GLM-130B训练一次的成本还是有几百万,ChatGLM进行一轮问答的成本目前压到什么程度?
张鹏:我们大概测试和估算了一下,和OpenAI倒数第二次公布的成本差不多,比他们略低一些。
但OpenAI的最新报价缩减到原来的10%,只有0.002美元/750个单词,这就比我们更低了。这个成本确实是很惊人的,估计他们做了模型压缩、量化、优化等工作,否则不可能降到这么低。
我们也在做相关的事情,期望能把成本压下去。
量子位:假以时日,能和搜索成本一样低吗?
张鹏:什么时候能降到这么低?我也不知道。还需要一点时间。
我之前看过对每次搜索价格平均成本的计算,其实与主营业务相关。比如搜索引擎主要业务就是广告,所以要用广告总收入作为上限来计算成本。这样计算的话,其实要考虑的并不是消耗的成本,而是企业盈利收益的平衡点。
做模型推理需要的是AI算力,肯定比搜索这类只用CPU算力的成本是要更高的。但大家也在努力吧,很多人提出一些想法,比如持续去做模型的压缩量化。
甚至有人想把模型做一些转化,让它在CPU上跑,因为CPU更便宜,量更大,跑起来的话,成本下降就会很明显。
量子位:最后还想聊两句人才方面的话题,现在大家都在抢大模型人才,智谱怕招不到人吗?
张鹏:我们从清华KEG的技术项目孵化出来,和各个高校的关系一直都不错。而且公司对年轻人来说氛围比较open,75%的同事都是年轻人,我这种已经算老家伙了。大模型人才现在确实奇货可居,但我们还没什么招人方面的担心。
反过来,其实我们现在比较担心被别人撬墙角(狗头)。
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Rubysyntaxquestion:Rational(a,b)andRational.new!(a,b)我正在阅读ruby镐书,我对创建有理数的语法感到困惑。Rational(3,4)*Rational(1,2)产生=>3/8为什么Rational不需要new方法(我还注意到例如我可以在没有new方法的情况下创建字符串)?
我有一个电子邮件表格。但是我正在制作一个测试电子邮件表单,用户可以在其中添加一个唯一的电子邮件,并让电子邮件测试将其发送到该特定电子邮件。为了简单起见,我决定让测试电子邮件通过ajax执行,并将整个内容粘贴到另一个电子邮件表单中。我不知道如何将变量从我的HAML发送到我的Controllernew.html.haml-form_tagadmin_email_blast_pathdoSubject%br=text_field_tag'subject',:class=>"mass_email_subject"%brBody%br=text_area_tag'message','',:nam
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
修改(澄清问题)我已经花了几天时间试图弄清楚如何从Facebook游戏中抓取特定信息;但是,我遇到了一堵又一堵砖墙。据我所知,主要问题如下。我可以使用Chrome的检查元素工具手动查找我需要的html-它似乎位于iframe中。但是,当我尝试抓取该iframe时,它是空的(属性除外):如果我使用浏览器的“查看页面源代码”工具,这与我看到的输出相同。我不明白为什么我看不到iframe中的数据。答案不是它是由AJAX之后添加的。(我知道这既是因为“查看页面源代码”可以读取Ajax添加的数据,也是因为我有b/c我一直等到我可以看到数据页面之后才抓取它,但它仍然不存在)。发生这种情况是因为
我使用Jekyll运行博客,并认为我会解决RedcarpetMarkdown解释器,因为它是developedandusedbyGitHub.好吧,我只是碰巧遇到了一个错误,去检查问题,然后foundthis.Maintainersays,"Asyouprobablyhavenoticed(harharharhar)Idon'thavetimetomaintainRedcarpetanymore.It'snotapriorityforme(IfindMarkdownthoroughlyboring)andit'snotapriorityforGitHub,becausewenolong
这个问题在这里已经有了答案:HashsyntaxinRuby[duplicate](1个回答)关闭5年前。我有一个Recipe,其中包含以下未通过lint测试的代码:service'apache'dosupports:status=>true,:restart=>true,:reload=>trueend失败并出现错误:UsethenewRuby1.9hashsyntax.supports:status=>true,:restart=>true,:reload=>true不确定新语法是什么样的...有人可以帮忙吗?
我的问题很简单:我是否必须在使用RubyonRails的类上require'csv'?如果我打开一个railsconsole并尝试使用CSVgem它可以工作,但我必须在文件中这样做吗? 最佳答案 CSVlibrary是ruby标准库的一部分;它不是gem(即第三方库)。与所有标准库(与核心库不同)一样,csv不会由ruby解释器自动加载。所以是的,在您的应用程序中某处您确实需要要求它:irb(main):001:0>CSVNameError:uninitializedconstantCSVfrom(irb):1from/Us