文章目录
docker 安装就不介绍了,去 dockerHub 搜索 flink 镜像,选择合适的版本安装 https://hub.docker.com/_/flink/tags
使用 docker 命令 docker pull flink: 1.16.0-scala_2.12-java8拉去镜像

1.16.0-scala_2.12-java8 镜像版本说明,flink 1.16.0,flink 内置 scala 版本 2.12,Java 版本 8
建议先简单启动 flink 容器 JobManager、TaskManager 两个容器将配置文件复制出来方便挂载
# 创建 docker 网络,方便 JobManager 和 TaskManager 内部访问
docker network create flink-network
# 创建 JobManager
docker run \
-itd \
--name=jobmanager \
--publish 8081:8081 \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:1.16.0-scala_2.12-java8 jobmanager
# 创建 TaskManager
docker run \
-itd \
--name=taskmanager \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:1.16.0-scala_2.12-java8 taskmanager
启动成功

访问 8081 端口如下
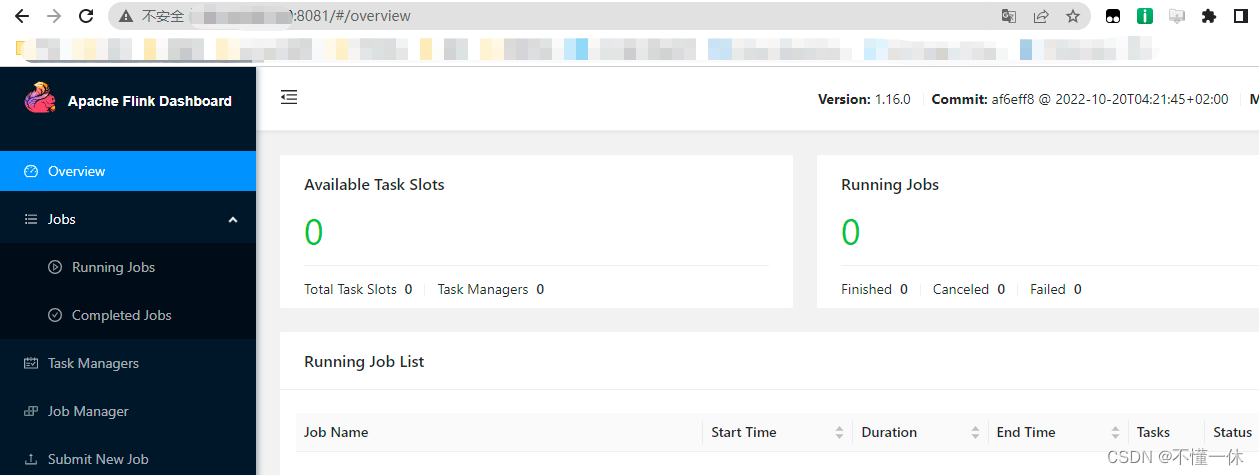
copy 配置文件
# jobmanager 容器
docker cp jobmanager:/opt/flink/conf ./JobManager/
# taskmanager 容器
docker cp taskmanager:/opt/flink/conf ./TaskManager/
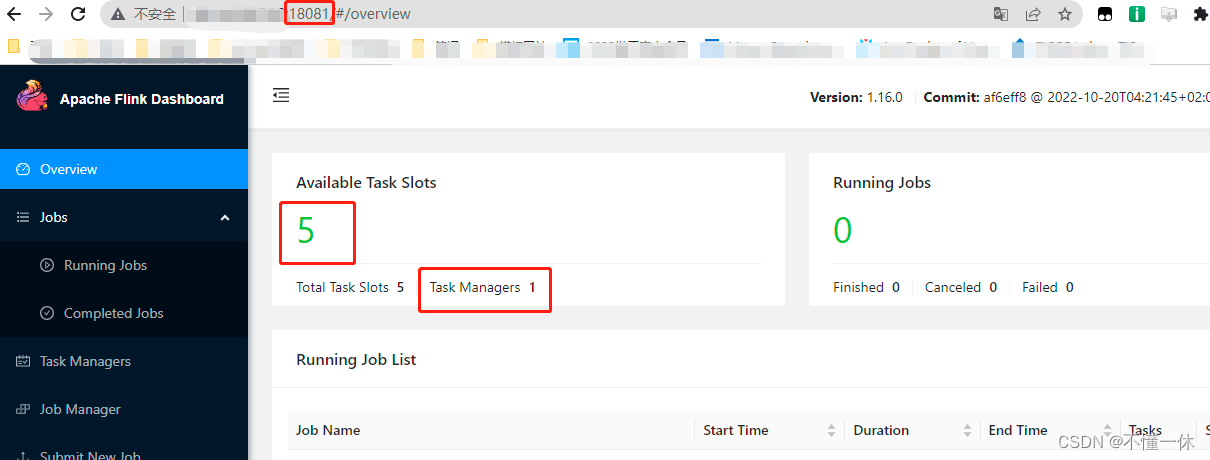
修改 JobManager/conf/flink-conf.yaml web 端口号为 18081

修改 TaskManager/conf/flink-conf.yaml 容器任务槽为 5

启动容器挂载配置文件
# 启动 jobmanager
docker run -itd -v /root/docker/flink/JobManager/conf/:/opt/flink/conf/ --name=jobmanager --publish 18081:18081 --env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" --network flink-network flink:1.16.0-scala_2.12-java8 jobmanager
# 启动 taskmanager
docker run -itd -v /root/docker/flink/TaskManager/conf/:/opt/flink/conf/ --name=taskmanager --network flink-network --env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" flink:1.16.0-scala_2.12-java8 taskmanager
参数解释
如下两个容器启动成功,可以看到 web 端口为 18081,taskmanager 启动一个,包含 5 个任务槽
使用 maven 命令指定原型 Flink Maven Archetype 快速创建一个包含了必要依赖的 Flink 程序骨架,自定义项目 groupId、artifactId、package 等信息
mvn archetype:generate ^
-DarchetypeGroupId=org.apache.flink ^
-DarchetypeArtifactId=flink-quickstart-java ^
-DarchetypeVersion=1.16.0 ^
-DgroupId=com.ye ^
-DartifactId=flink-study ^
-Dversion=0.1 ^
-Dpackage=com.ye ^
-DinteractiveMode=false
下载成功打开项目目录
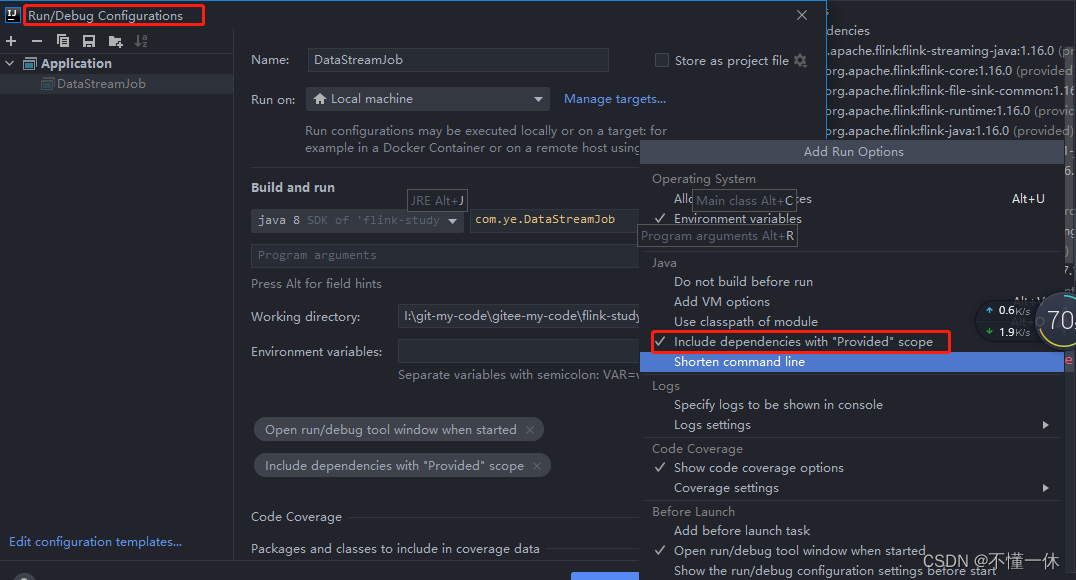
如下:注意运行需要设置启动参数,否则启动会找不到类,因为 pom.xml 文件 flink 相关包都添加了 <scope>provided</scope> 表示只用于生产环境,另一种方法就是将 <scope>provided</scope> 修改为<scope>runtime</scope>
流处理和批处理在 flink 低版本(貌似1.12)需要区分,目前都使用流处理写法
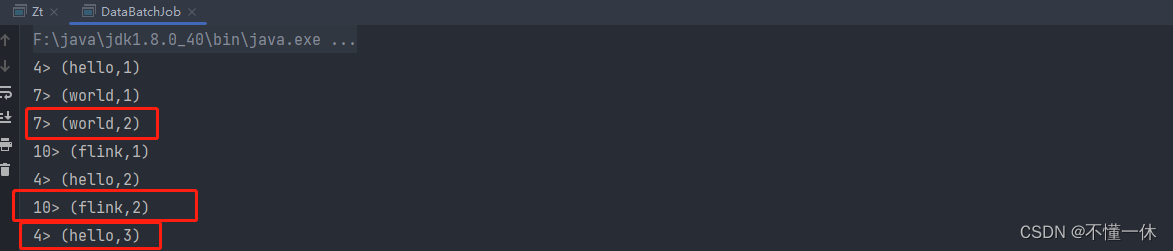
下面代码用来统计单词出现的的次数
public class DataBatchJob {
/* 下面示例统计单词出现的次数 */
public static void main(String[] args) throws Exception {
// 获取 flink 环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 添加数据源
DataStreamSource<String> streamSource = env.fromElements("hello world", "hello flink", "flink", "hello", "world");
// 对传入的流数据分组
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
// value 传入的数据,out
// Tuple2 二元组
// out 传出的值
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] split = value.split(" ");
for (String s : split) {
out.collect(Tuple2.of(s, 1));
}
}
});
// 按二元组的第 0 个位置分组
KeyedStream<Tuple2<String, Integer>, Tuple> keyBy = streamOperator.keyBy(0);
// 按二元组的第 1 个位置求和
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = keyBy.sum(1);
sum.print();
env.execute("统计单词出现的次数");
}
}
执行结果如下
上传 flink 集群
下面示例通过 socket 文本源,对输入的大于 500 和小于 500 的分别求和
public class DataStreamJob {
private static final Logger logger = LoggerFactory.getLogger(DataStreamJob.class);
/* 下面示例对大于 500 和小于 500 的分别求和 */
public static void main(String[] args) throws Exception {
// 获取 flink 环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 添加 socket 文本流数据源
//DataStreamSource<String> streamSource = env.fromElements("200", "100", "6000", "500", "2000", "300", "1500", "900");
DataStreamSource<String> streamSource = env.socketTextStream("127.0.0.1", 7777);
// 对大于 500 和小于 500 进行分组
KeyedStream<String, String> stringKeyedStream = streamSource.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String s) throws Exception {
int i = Integer.parseInt(s);
return i > 500 ? "ge" : "lt";
}
});
// 开 10 秒滚动窗口,每 10 秒为一批数据 【00:00:00 ~ 00:00:10)、【00:00:10 ~ 00:00:20)左闭右开区间
WindowedStream<String, String, TimeWindow> windowedStream = stringKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 窗口处理函数,泛型 String, Integer, String, TimeWindow 依次对应 输入类型、输出类型、 KEY类型(即keyBy 返回的类型), 窗口
SingleOutputStreamOperator<Integer> outputStreamOperator = windowedStream.process(new ProcessWindowFunction<String, Integer, String, TimeWindow>() {
/*
* key: 分组的 key
* context: 上下文信息
* elements: 传过来的一批数据
* out: 数据输出
* */
@Override
public void process(String key, ProcessWindowFunction<String, Integer, String, TimeWindow>.Context context, Iterable<String> elements, Collector<Integer> out) throws Exception {
System.out.println(key);
AtomicInteger sum = new AtomicInteger();
elements.forEach(item -> sum.addAndGet(Integer.parseInt(item)));
out.collect(sum.get());
}
});
// 输出
outputStreamOperator.print();
env.execute("分组求和");
}
}
在 window 或 Linux 开启 Socket 文本流测试

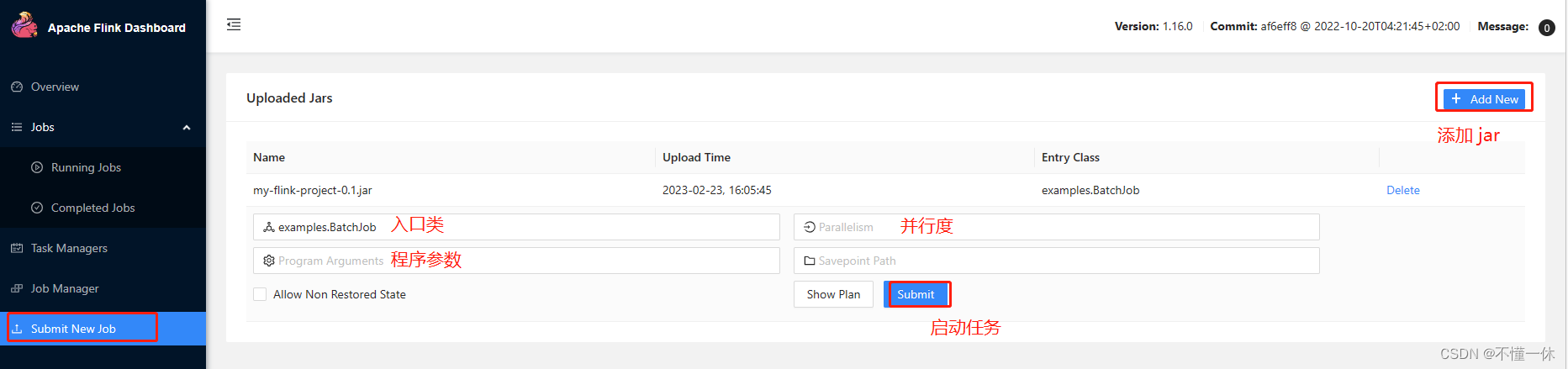
打包项目:可以在 pom.xml 修改启动类,也可以在命令启动或者 ui 界面上传设置启动类参数

使用 ui 界面上传 jar 到 flink 集群,点击 submit 运行
# 如果集群( 即JobManager) 在当前服务器可以使用如下命令
$ bin/flink run -Dexecution.runtime-mode=BATCH <jarFile>
# 如果集群( 即JobManager) 不在当前服务器,在 TaskManager 服务器提交作业可以使用如下命令
# -m 指定 JobManager 服务器地址
# -c 指定作业入口程序
# -p 指定并行度
$ bin/flink run -m 192.168.1.1:8081 -c com.ye.StreamWordCount -p 2 <jarFile>
# 撤销任务
$ bin/flink cancle <jobId>
批处理运行完成
流处理正在运行

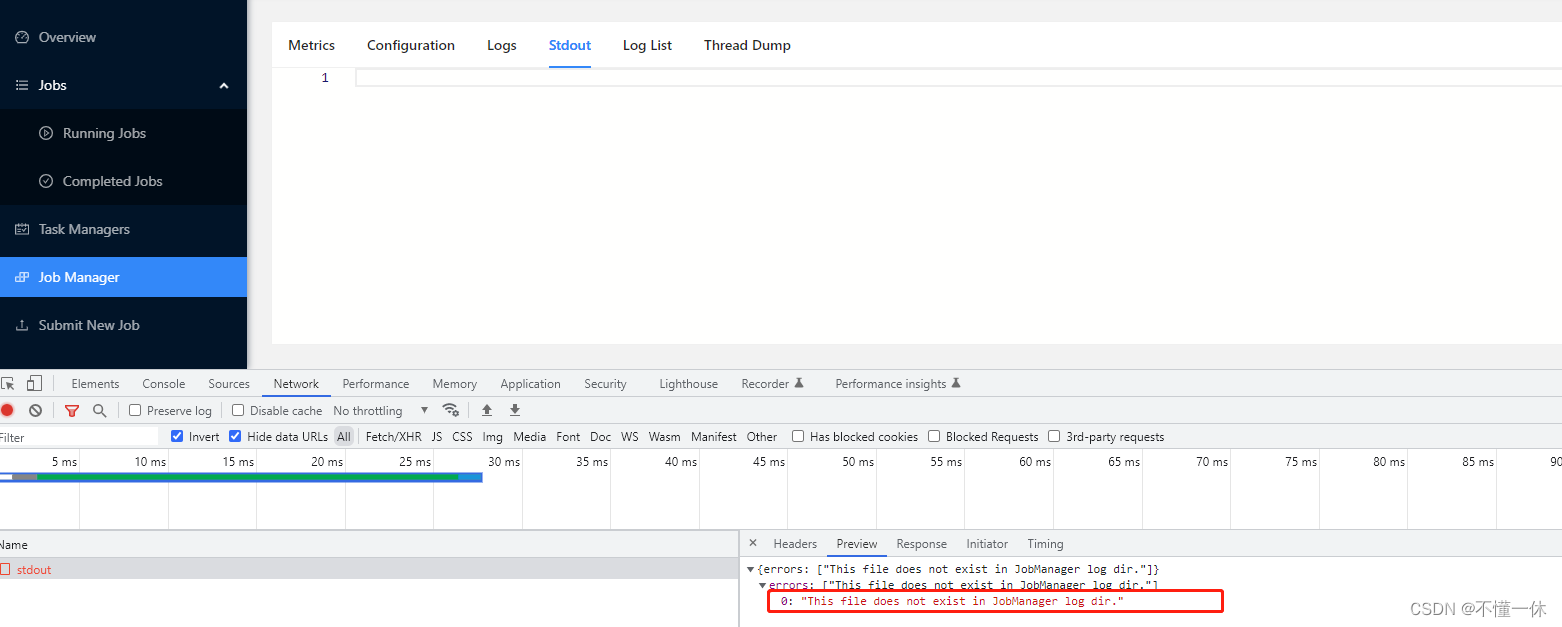
使用 docker 启动的 flink 集群发现 UI 界面的 stdout 没有 print 输出
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
我在Rails应用程序中使用CarrierWave/Fog将视频上传到AmazonS3。有没有办法判断上传的进度,让我可以显示上传进度如何? 最佳答案 CarrierWave和Fog本身没有这种功能;你需要一个前端uploader来显示进度。当我不得不解决这个问题时,我使用了jQueryfileupload因为我的堆栈中已经有jQuery。甚至还有apostonCarrierWaveintegration因此您只需按照那里的说明操作即可获得适用于您的应用的进度条。 关于ruby-on-r
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
默认情况下:回形针gem将所有附件存储在公共(public)目录中。出于安全原因,我不想将附件存储在公共(public)目录中,所以我将它们保存在应用程序根目录的uploads目录中:classPost我没有指定url选项,因为我不希望每个图像附件都有一个url。如果指定了url:那么拥有该url的任何人都可以访问该图像。这是不安全的。在user#show页面中:我想实际显示图像。如果我使用所有回形针默认设置,那么我可以这样做,因为图像将在公共(public)目录中并且图像将具有一个url:Someimage:看来,如果我将图像附件保存在公共(public)目录之外并且不指定url(同
我以前没有使用过cron,所以我不能确定我这样做是对的。我想要自动化的任务似乎没有运行。我在终端中执行了这些步骤:sudogeminstall每当切换到应用程序目录无论何时。(这创建了文件schedule.rb)我将此代码添加到schedule.rb:every10.minutesdorunner"User.vote",environment=>"development"endevery:hourdorunner"Digest.rss",:environment=>"development"end我将此代码添加到deploy.rb:after"deploy:symlink","depl