遇到没GPU想训练模型的情况,CPU跑好久,可利用Kaggle的云GPU。
2、进入主页,可用creat创建nootbook,之后可按正常jupyter的操作进行

3、上传数据
可利用Kaggle上的线上的数据集,如果想利用自己的数据来训练模型,需从本地上传
(1)右上方的Add data
(2)上传自己的数据集
点击upload a dataset,dataset取名,然后选择browse files上传文件。最好将文件压缩之后上传,这样比较快。上传压缩包后kaggle会自动解压。
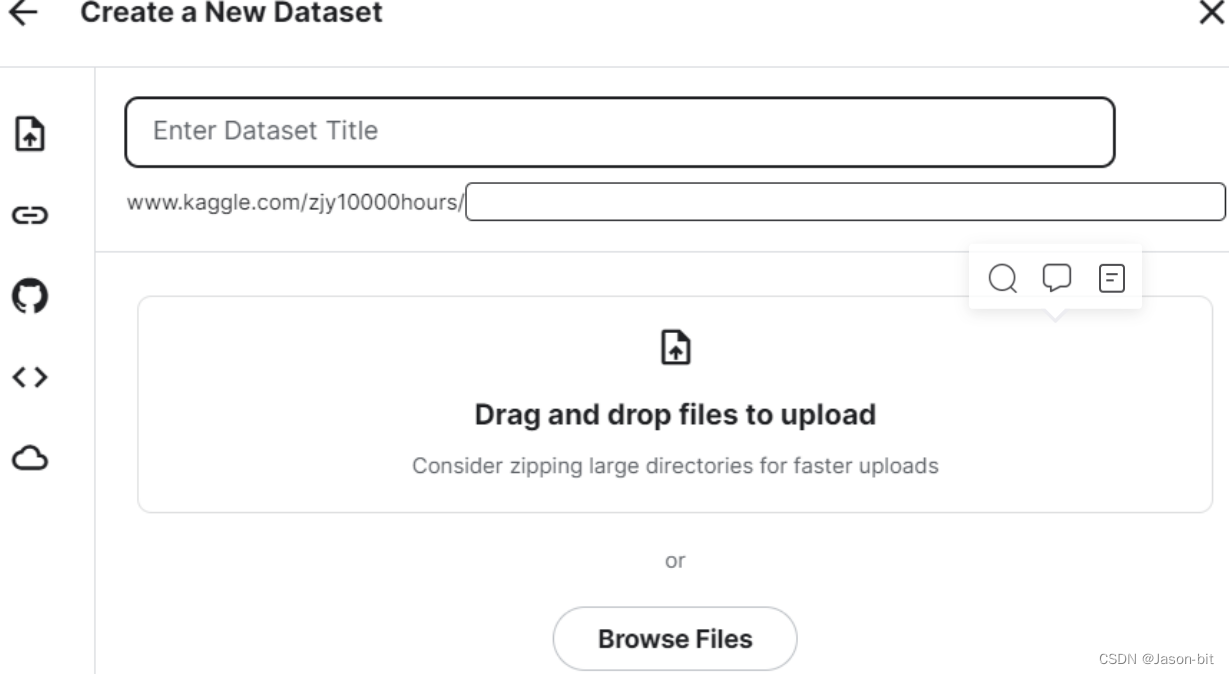
上传完成之后点击Create,正在处理你的数据集时,不要点击别的地方。
运行下述代码可查看数据路径[4]
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
4、编写代码,训练
(1)上传的文件无法在kaggle上进行修改,需要copy到输出文件夹中,
上传文件的进度如果始终为0,则需要科学上网上传数据。
上传的文件会放置在\kaggle\input下,这个目录只能读,而/kaggle/working是放输出文件的,可读可写,但如果不点右上角的Save version,输出文件并不会保存。
将数据集和代码都压缩成一个zip文件,上传,kaggle会自动将其解压缩,从kaggle读取文件名,会发现少了.zip后缀。在上传数据集时,会让人输入一个名字,作为上传文件的上一层目录,文件名中的中划线会被省略,但是下滑线会自动转为中划线。为方便读写,可将上传到到input下的文件传一份到working目录下,使用shutil包[5]原文链接
import shutil
shutil.copytree(r'../input/trydata/image_classification-pytorch', r'./trydata')使用python的pyautogui包来模拟鼠标操作,就可以刮着了,参考[6]Python 实现按键精灵的功能
因此,为了简单,直接在在notebook中重新写代码
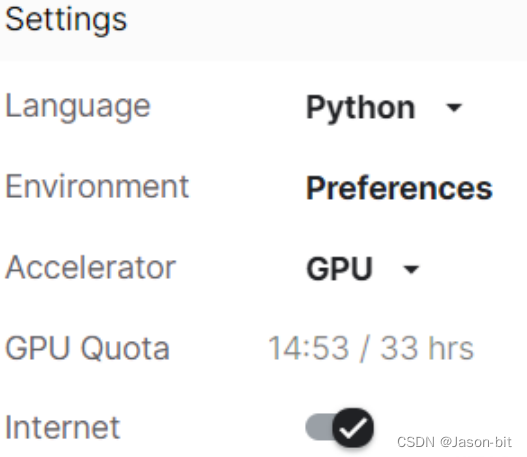
(2)配置运行环境
在settings里配置环境:
(3)运行
直接运行
(4)离线运行
参考:地址
使用GPU训练模型过程中,出现了提示是否继续操作,紧接着就断了连接,里面的产生的数据都消失了,Kaggle如果长时间不动,会自己断掉,判断离开
如果训练模型需要很久,就要后台跑了,并且要保存训练出来的模型。
点击右上角的Save Version,给version取个名,注意选择Save & Run All
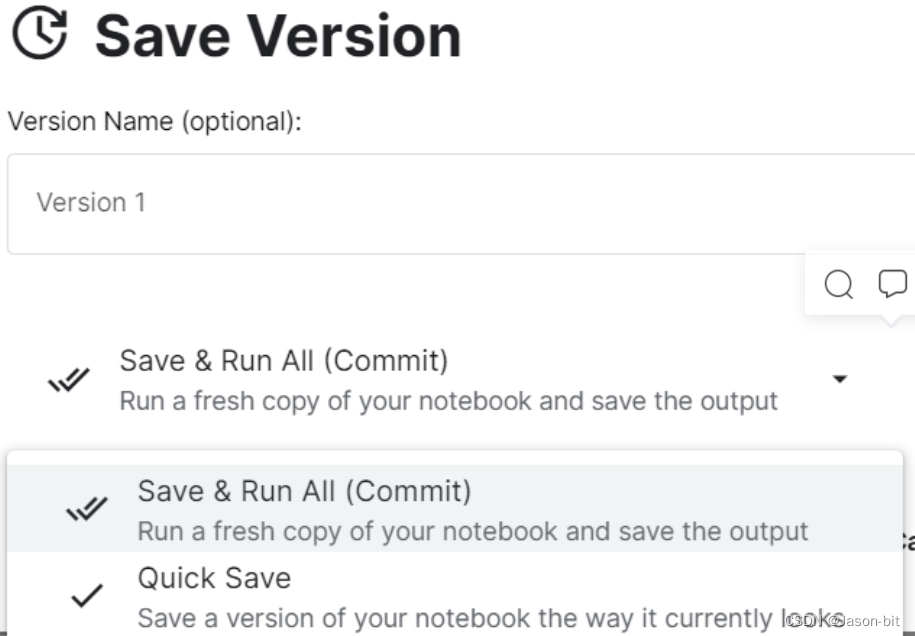
save保存。
左下角的活动会出现各个活动文件
5、下载输出结果
把训练的权值文件下载下来,可以直接点击权值文件并下载。
也可下载整个文件夹,但下载整个文件夹会很慢,参考博客[2]:压缩下载
直接在cell中运行此代码即可[2]
import os
import zipfile
import datetime
def file2zip(packagePath, zipPath):
'''
:param packagePath: 文件夹路径
:param zipPath: 压缩包路径
:return:
'''
zip = zipfile.ZipFile(zipPath, 'w', zipfile.ZIP_DEFLATED)
for path, dirNames, fileNames in os.walk(packagePath):
fpath = path.replace(packagePath, '')
for name in fileNames:
fullName = os.path.join(path, name)
name = fpath + '\\' + name
zip.write(fullName, name)
zip.close()
if __name__ == "__main__":
# 文件夹路径
packagePath = '/kaggle/working/'
zipPath = '/kaggle/working/output.zip'
if os.path.exists(zipPath):
os.remove(zipPath)
file2zip(packagePath, zipPath)
print("打包完成")
print(datetime.datetime.utcnow())
下载即可
下载完,可清空kaggle/working下指定文件夹 直接在cell中运行下面代码[2]
import shutil
import os
if __name__ == '__main__':
path = '/kaggle/working/model'
if os.path.exists(path):
shutil.rmtree(path)
print('删除完成')
else:
print('原本为空')
=============================================
更多基本介绍,可参考[7]在Kaggle免费使用GPU训练自己的神经网络
参考文献
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
我在Rails应用程序中使用CarrierWave/Fog将视频上传到AmazonS3。有没有办法判断上传的进度,让我可以显示上传进度如何? 最佳答案 CarrierWave和Fog本身没有这种功能;你需要一个前端uploader来显示进度。当我不得不解决这个问题时,我使用了jQueryfileupload因为我的堆栈中已经有jQuery。甚至还有apostonCarrierWaveintegration因此您只需按照那里的说明操作即可获得适用于您的应用的进度条。 关于ruby-on-r
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
默认情况下:回形针gem将所有附件存储在公共(public)目录中。出于安全原因,我不想将附件存储在公共(public)目录中,所以我将它们保存在应用程序根目录的uploads目录中:classPost我没有指定url选项,因为我不希望每个图像附件都有一个url。如果指定了url:那么拥有该url的任何人都可以访问该图像。这是不安全的。在user#show页面中:我想实际显示图像。如果我使用所有回形针默认设置,那么我可以这样做,因为图像将在公共(public)目录中并且图像将具有一个url:Someimage:看来,如果我将图像附件保存在公共(public)目录之外并且不指定url(同
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e