目录
算子:Operator(操作)
主要原因是RDD的方法和scala集合对象的方法不一样,scala集合对象的方法都是在同一个节点的内存中完成的;而RDD的方法可以将计算逻辑发送到Executor端(分布式节点)执行的。所以为了区分scala集合的方法和RDD的方法,所以才把RDD的方法叫做算子
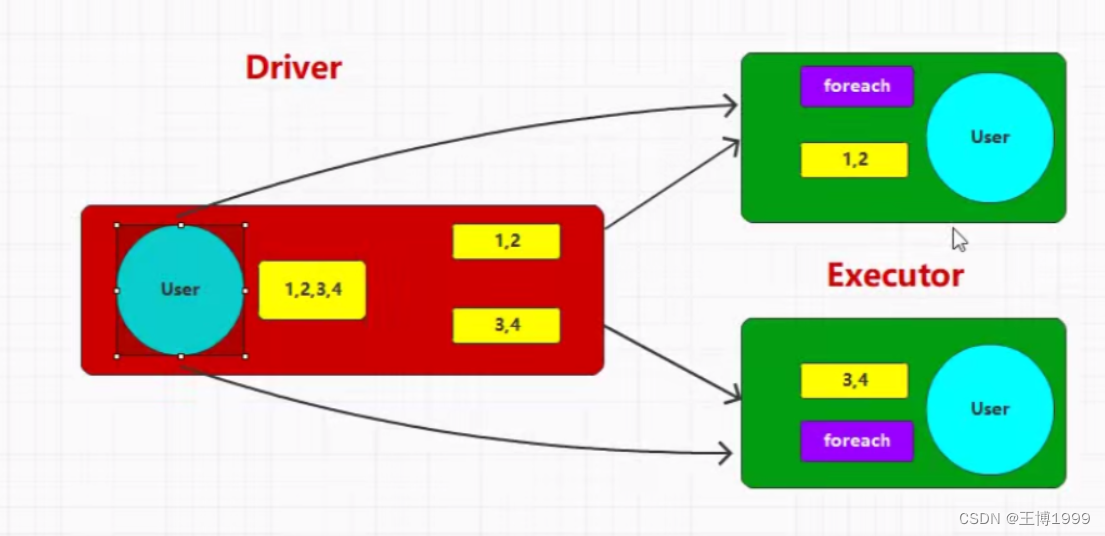
RDD方法外部的操作都是在Driver端执行的,而方法的内部的逻辑代码是在Executor端执行的
分区内的数据都是有序的
案例说明
package com.bigdata.SparkCore.wd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author wangbo
* @version 1.0
*/
object test1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val user = new User()
rdd.foreach(
num => {
println(user.age + num)
}
)
sc.stop()
}
class User {
val age : Int = 30
}
}
上面代码会报错主要错误为:Caused by: java.io.NotSerializableException: com.bigdata.SparkCore.wd.test1$User,就是User这个类没有序列化
为什么会提示没有序列化这个错误?
首先foreach这个算子内部进行了user.age + num操作,而RDD方法的内部逻辑代码是在Executor端执行的,val user = new User()这段代码是在RDD方法的外部,是在Driver端执行的。所以Executor端没有User这个对象,这需要到Driver端去拉去,拉去的过程中需要进行网络传输,而网络传输是不能进行对象的传输,只能进行asccii码的传输,所以User这个类需要序列化操作
下面是图解:
正确代码:
package com.bigdata.SparkCore.wd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author wangbo
* @version 1.0
*/
object test1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
//Driver端执行
val user = new User()
rdd.foreach(
num => {
//Executor端执行
println(user.age + num)
}
)
sc.stop()
}
class User extends Serializable {
val age : Int = 30
}
}
或者把User类变成一个样例类
case class User() {
val age : Int = 30
}
样例类会自动生成很多的方法,其中也会自动实现可序列化的接口
比如会自动生成:apply方法、toString方法、equals方法、hashCode方法、copy方法等
1.判断是否存在闭包
2.如果是闭包操作,那么会对数据进行序列化检查
(1)首先什么是闭包?
只要是函数式编程都会有闭包操作
首先闭包是有一个生命周期的概念,一个函数使用了外部的变量,改变这个变量的生命周期,将变量包含到函数的内部,形成闭合的环境,这个环境称之为闭包环境,简称闭包
(2)案例引入
package com.bigdata.SparkCore.wd
/**
* @author wangbo
* @version 1.0
*/
object test2 {
def main(args: Array[String]): Unit = {
def outer() ={
val a = 100
def inner(): Unit ={
val b = 200
println(a + b)
}
inner _
}
//Scala的函数本质是Java中的方法
val funObj = outer()
funObj()
}
}
输出为:300
代码解析:
①当代码val funObj = outer()执行完的时候,上面的函数outer()已经执行完结束了,为什么说执行完了,如果没执行完,就不会返回一个结果给funObj
②而Scala的函数本质是Java中的方法,而Java中方法结束后那么方法中的局部变量就会弹栈
③所以上面outer()函数结束后局部变量a 就会弹栈,而outer()返回结果是一个函数对象inner,下面就执行了funObj()相当于执行该函数(加了个括号相当于函数调用)
④在val funObj = outer()执行完以后 funObj()刚执行,而inner()函数里用到了 outer()函数中的局部变量a,但是局部变量a 在outer()函数结束后就已经弹栈不存在了,最后运行的时候并没有报错,可以输出300,那这到底是为什么?
原因:
因为这里就涉及到了函数闭包,当一个函数使用了外部的变量,改变这个变量的生命周期,将变量包含到函数的内部,形成闭合的环境,这个环境称之为闭包环境,简称闭包
案例深入:根据第一个案例进行小小改动
package com.bigdata.SparkCore.wd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author wangbo
* @version 1.0
*/
object test1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List[int]())
val user = new User()
rdd.foreach(
num => {
println(user.age + num)
}
)
sc.stop()
}
class User {
val age : Int = 30
}
}
代码依然报错主要错误为:Caused by: java.io.NotSerializableException: com.bigdata.SparkCore.wd.test1$User,还是User这个类没有序列化,但是我RDD列表里没数据,那么它就不会执行foreach中的代码,没有执行那怎么会报没有序列化呢?它是怎么检测出来的?
代码解析:
因为RDD算子里面传递的函数为匿名函数,RDD算子在引入了外部的变量时,外部的变量user(Driver端)就会传入到foreach算子内部(Executor端),那么就会改变user的生命周期,形成闭包。所以说匿名函数就会用到闭包操作,那么就会有闭包检测功能。从而发现user没有序列化,所以说根本不需要执行foreach中的代码,就会检测出错误,而这个功能称为闭包检测功能
注意:所有的匿名函数都有闭包
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor
端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就
形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor
端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列
化,这个操作我们称之为闭包检测。
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
如何用IDEA2022创建并初始化一个SpringBoot项目?目录如何用IDEA2022创建并初始化一个SpringBoot项目?0. 环境说明1. 创建SpringBoot项目 2.编写初始化代码0. 环境说明IDEA2022.3.1JDK1.8SpringBoot1. 创建SpringBoot项目 打开IDEA,选择NewProject创建项目。 填写项目名称、项目构建方式、jdk版本,按需要修改项目文件路径等信息。 选择springboot版本以及需要的包,此处只选择了springweb。 此处需特别注意,若你使用的是jdk1
前言上一篇我们简要讲述了粒子系统是什么,如何添加,以及基本模块的介绍,以及对于曲线和颜色编辑器的讲解。从本篇开始,我们将按照模块结构讲解下去,本篇主要讲粒子系统的主模块,该模块主要是控制粒子的初始状态和全局属性的,以下是关于该模块的介绍,请大家指正。目录前言本系列提要一、粒子系统主模块1.阅读前注意事项2.参考图3.参数讲解DurationLoopingPrewarmStartDelayStartLifetimeStartSpeed3DStartSizeStartSize3DStartRotationStartRotationFlipRotationStartColorGravityModif
VMware虚拟机与本地主机进行磁盘共享前提虚拟机版本为Windows10(专业版,不是可能有问题)本地主机为家庭版或学生版(此版本会有问题,但有替代方式)最好是专业版VMware操作1.关闭防火墙,全部关闭。2.打开电脑属性3.点击共享-》高级共享-》权限4.如果没有everyone,就添加权限选择完全控制,然后应用确定。5.打开cmd输入lusrmgr.msc(只有专业版可以打开)如果不是专业版,可以跳过这一步。点击用户-》administrator密码要复杂密码,否则不行。推荐admaiN@1234类型的密码。设置完密码,点击属性,将禁用解开。6.如果虚拟机的windows不是专业版,可
一、获取当前时间1、current_date当前日期(年月日)Examples:SELECTcurrent_date;2、current_timestamp/now()当前日期(时间戳)Examples:SELECTcurrent_timestamp;二、从日期字段中提取时间1、year,month,day/dayofmonth,hour,minute,secondExamples:SELECTyear(now());其他的日期函数以此类推month:1day:12(当月的第几天)dayofmonth:12hour,minute,second:分别对应时分秒2、dayofweek、dayofm
IK分词器本文分为简介、安装、使用三个角度进行讲解。简介倒排索引众所周知,ES是一个及其强大的搜索引擎,那么它为什么搜索效率极高呢,当然和他的存储方式脱离不了关系,ES采取的是倒排索引,就是反向索引;常见索引结构几乎都是通过key找value,例如Map;倒排索引的优势就是有效利用Value,将多个含有相同Value的值存储至同一位置。分词器为了配合倒排索引,分词器也就诞生了,只有合理的利用Value,才会让倒排索引更加高效,如果一整个Value不进行任何操作直接进行存储,那么Value和key毫无区别。分词器Analyzer通常会对Value进行操作:一、字符过滤,过滤掉html标签;二、分