可以通过路由as_view()传参 根据请求方式的不同执行对应不同的方法
在routers模块下 封装了很多关于路由的方法 , 最基础的BaseRouter类,给我提供自定制的接口。
下面这个方法给我们提供了自动生成两条带参数的url
from rest_framework import routers
from django.conf.urls import url, include
from course.models import Course
from course.views import CourseView
routers = routers.DefaultRouter()
routers.register('Course', CourseView)
urlpatterns = [
url(r'^', include(routers.urls)),
] 帮助开发者提供了一些类,并在类中提供了多种方法供我们使用,下图是提供的主要的类以及继承关系。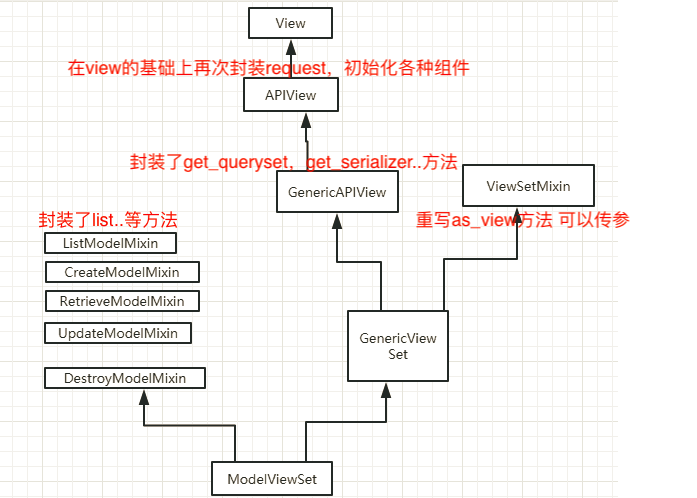
提供其他一些视图函数类,可以去源码里看。
下面以URL上控制版本为例
1、添加配置
REST_FRAMEWORK = {
# 默认使用的版本控制类
'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning',
# 允许的版本
'ALLOWED_VERSIONS': ['v1', 'v2'],
# 版本使用的参数名称
'VERSION_PARAM': 'version',
# 默认使用的版本
'DEFAULT_VERSION': 'v1',
}2、设置路由
urlpatterns = [
#url(r'^admin/', admin.site.urls),
url(r'^api/(?P<version>\w+)/', include('api.urls')),
]3、获取版本
request.version
rest_framework给我们提供了认证的接口,由BaseAuthentication类提供接口,也有一些封装好的认证类(请走入源码....)
接口函数 authticate 认证成功返回一元组(user,token)分别赋值给request.user 和 request.auth
下面是一个简单的认证示例
class Auth(BaseAuthentication):
def authenticate(self, request):
token = request.query_params.get('token')
obj = models.Token.objects.filter(token=token).first()
if not obj:
raise AuthenticationFailed({'code': 1001, 'error': '认证失败'})
return (obj.user.username, obj)我们的认证类可以放在局部视图函数,也可以配置为全局认证。
# 局部视图函数认证
class MyView(APIView):
authentication_classes = [Auth]
pass# 全局配置 在settings.py
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': [Auth],
}由BasePermission类给我提供接口 接口函数为 has_permission 以及 has_object_permission
有权限返回True 没有则返回False,默认的权限类为下图。
# 允许任何人访问
class AllowAny(BasePermission):
"""
Allow any access.
This isn't strictly required, since you could use an empty
permission_classes list, but it's useful because it makes the intention
more explicit.
"""
def has_permission(self, request, view):
return True接口类为下图
class BasePermission(object):
"""
A base class from which all permission classes should inherit.
"""
def has_permission(self, request, view):
"""
Return `True` if permission is granted, `False` otherwise.
"""
# 这里写我们的权限逻辑
return True
def has_object_permission(self, request, view, obj):
"""
Return `True` if permission is granted, `False` otherwise.
"""
return True还封装了一些权限类,只允许admin用户访问的权限,只给认证的用户权限等等,请走源码........
基础的BaseThrottle类提供接口 接口函数为 allow_request,如果返回False则走wait
SimpleRateThrottle类给我们提供了get_cache_key接口,继承这个类要写rate(num_request, duration)多长时间内访问次数
实现原理如下代码:
class SimpleRateThrottle(BaseThrottle):
def allow_request(self, request, view):
if self.rate is None:
return True
self.key = self.get_cache_key(request, view)
if self.key is None:
return True
self.history = self.cache.get(self.key, [])
self.now = self.timer()
# 原理的实现逻辑
while self.history and self.history[-1] <= self.now -self.duration:
self.history.pop()
if len(self.history) >= self.num_requests:
return self.throttle_failure()
return self.throttle_success()这里就放这些~~具体~请大家走入源码.......
对queryset序列化以及对请求数据格式验证。
通常继承两个类 Serializer 以及 ModelSerializer
Serializer 序列化的每个字段都要自己写 ModelSerializer 会根据数据库表渲染所有字段
注意sourse 以及 钩子函数的应用 代码如下:
class CourseDetailModelSerializers(serializers.ModelSerializer):
title = serializers.CharField(source='course.name')
img = serializers.ImageField(source='course.course_img')
level = serializers.CharField(source='course.get_level_display')
recommends = serializers.SerializerMethodField()
chapters = serializers.SerializerMethodField()
def get_recommends(self, obj):
queryset = obj.recommend_courses.all()
return [{'id': row.id, 'title': row.name} for row in queryset]
def get_chapters(self, obj):
queryset = obj.course.course_chapters.all()
return [{'id': row.id, 'name': row.name} for row in queryset]
class Meta:
model = CourseDetail
fields = ['course', 'title', 'img', 'level', 'why_study', 'chapters', 'recommends']
对从数据库中获取到的数据进行分页处理 SQL --> limit offset
- 根据页码:http://www.myclass.com/api/v1/student/?page=1&size=10
- 根据索引:http://www.myclass.com/api/v1/student/?offset=60&limit=10
- 根据游标:http://www.myclass.com/api/v1/student/?page=erd8
页码越大速度越慢,为什么怎么解决?
- 原因:页码越大向后需要扫描的行数越多,因为每次都是从0开始扫描
- 解决:
- 限制当前显示的页数
- 记录当前页面数据ID的最大值和最小值,再次分页时,根据ID进行筛选,在分页
rest_framework 分页的配置
- 全局分页配置
# settings.py
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination',
'PAGE_SIZE': 100
}- 修改分页风格
class MyPagination(PageNumberPagination):
page_size = 100
page_size_query_param = 'page_size'
max_page_size = 1000
# 然后在视图中使用.pagination_class属性调用该自定义类
class MyView(generics.ListAPIView):
queryset = Billing.objects.all()
serializer_class = BillingRecordsSerializer
pagination_class = MyPagination
# 或者是在settings.py中修改DEFAULT_PAGINATION_CLASS
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'apps.core.pagination.MyPagination'
}rest_framework给我提供的API
1、 PageNumberPagination
|
|
GET https://api.example.org/accounts/?page=4 |
响应对象
HTTP 200 OK
{
"count": 1023
"next": "https://api.example.org/accounts/?page=5",
"previous": "https://api.example.org/accounts/?page=3",
"results": [
…
]
}配置属性
- page_size 每页显示对象的数量 如果设置了就重写PAGE_SIZE
- page_query_param 页面查询参数 指示分页空间的查询参数的名字
- page_size_query_param 允许客户端根据每个请求设置页面大小 一般都为None
- max_page_size 设置了page_size_query_param 才有意义 客户端请求页面中显示最大数量
- last_page_strings 储存page_query_param参数请求过的值列表或元组
2、LImitOffsetPagination
路由配置以及返回类型
GET https://api.example.org/accounts/?limit=100&offset=400
HTTP 200 OK
{
"count": 1023
"next": "https://api.example.org/accounts/?limit=100&offset=500",
"previous": "https://api.example.org/accounts/?limit=100&offset=300",
"results": [
…
]
}配置参数
- page_size 每页显示对象的数量 如果设置了就重写PAGE_SIZE
- default_limit: 如果客户端没有提供,则默认使用与PAGE_SIZE值一样。
- limit_query_param:表示限制查询参数的名字,默认为’limit’
- offset_query_param:表示偏移参数的名字, 默认为’offset’
- max_limit:允许页面中显示的最大数量,默认为None
3、CursorPagination
- 基于游标的分页显示了一个不透明的“cursor”指示器,客户端可以使用它来浏览结果集。
- 这种分页方式只允许用户向前或向后进行查询。并且不允许客户端导航到任意位置。
- 基于游标的分页方式比较复杂,它要求结果集给出一个固定的顺序,并且不允许客户端任意的对结果集进行索引
全局配置如下
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.CursorPagination',
'PAGE_SIZE': 100
}配置参数:
- page_size:显示的最大条数
- cursor_query_param: 游标查询参数名,默认为’cursor’
- ordering: 排序字段名的列表或者元组,例如ordering = ‘slug’,默认为-created
4、自定义分页
- 继承pagination.BasePagination
- 重写paginate_queryset(self, queryset, request, view=None)方法 ,
初始化queryset对象,设置pagination实例 返回一个包含用户请求内容的可迭代对象 形成分页对象
- 重写get_paginated_response(self, data)方法
序列化请求页中所包含的对象,返回一个Response对象
class CustomPagination(pagination.PageNumberPagination):
def get_paginated_response(self, data):
return Response({
'links': {
'next': self.get_next_link(),
'previous': self.get_previous_link()
},
'count': self.page.paginator.count,
'results': data
})
# 设置自定义分页、
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'my_project.apps.core.pagination.CustomPagination',
'PAGE_SIZE': 100
}默认的三个解析器
- JsonParser Json数据解析器
- FormParser 和 MultiPartParser 一般同时使用
Both request.data will be populated with a QueryDict. 官方文档的解释
DEFAULTS = {
# rest_framework settings.py
'DEFAULT_PARSER_CLASSES': (
'rest_framework.parsers.JSONParser',
'rest_framework.parsers.FormParser',
'rest_framework.parsers.MultiPartParser'
),
}
默认的两个渲染器,一个是Json的,一个是用浏览器访问rest_framework自带的模板的
DEFAULTS = {
# rest_framework setting.py
'DEFAULT_RENDERER_CLASSES': (
'rest_framework.renderers.JSONRenderer',
'rest_framework.renderers.BrowsableAPIRenderer',
),
}
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我想开始使用“Sinatra”框架进行编码,但我找不到该框架的“MVC”模式。是“MVC-Sinatra”模式或框架吗? 最佳答案 您可能想查看Padrino这是一个围绕Sinatra构建的框架,可为您的项目提供更“类似Rails”的感觉,但没有那么多隐藏的魔法。这是使用Sinatra可以做什么的一个很好的例子。虽然如果您需要开始使用这很好,但我个人建议您将它用作学习工具,以对您来说最有意义的方式使用Sinatra构建您自己的应用程序。写一些测试/期望,写一些代码,通过测试-重复:)至于ORM,你还应该结帐Sequel其中(imho
我是RESTful的新手。但是,我想在我的Rails应用程序中使用它。当我将它添加到我的routes.rbmap.resources:notes时,我得到了创建这些方法的路由:索引创建新编辑展示更新摧毁我想知道编辑/更新和创建/新建之间有什么区别?对于这些方法对如何变化以及每个方法对的作用,是否有任何标准定义? 最佳答案 标准定义如下:index-GET-所有(或部分)记录的Viewshow-GET-单个记录的View新-GET-发布以创建的表单创建-POST-创建新记录edit-GET-用于编辑单个记录的表单更新-PUT-更新记录
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。我一直在Rails上做两个项目,它们运行良好,但在这个过程中重新发明了轮子,自来水(和热水)和止痛药,正如我随后了解到的那样,这些已经存在于框架中。那么基本上,正确了解框架中所有智能部分的最佳方法是什么,这将节省时间而不是自己构建已经实现的功能?从第1页开始阅读文档?是否有公开所有内容的特定示例应用程序?一个特定的开源项目?所有的rails交通?还是完全
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭4年前。Improvethisquestion我希望能够将模板化的YARD文档样式注释插入到我现有的Rails遗留应用程序中。目前它的评论很少。我想要具有指定参数的类header和方法header(通过从我假定的方法签名中提取)和返回值的占位符。在PHP代码中,我有一些工具可以检查代码并在适当的位置创建插入到代码中的文档header注释。在带有Ducktyping等的Ruby中,我确信诸如@params等类型之类
我正在使用Sinatra构建一个API(在客户端使用Angular并希望其他人能够访问API)并且它也是一个OAuth提供者。我想知道采取什么最佳途径(利用现有的gem或从Warden推出自己的解决方案等)。在使用Rails之前使用过devise和doorkeeper进行身份验证和oauth,想知道Sinatra的最佳解决方案是什么。理想情况下,我不想要View或能够扩展/修改现有解决方案的操作,因为我纯粹将其作为API与之交互。 最佳答案 我最近使用S/O的以下答案做了同样的事情Whatisaverysimpleauthentic
我尝试用Ruby设计一个基于Web的应用程序。我开发了一个简单的核心应用程序,在没有框架和数据库的情况下在六边形架构中实现DCI范例。核心六边形中有小六边形和网络,数据库,日志等适配器。每个六边形都在没有数据库和框架的情况下自行运行。在这种方法中,我如何提供与数据库模型和实体类的关系作为独立于数据库的关系。我想在将来将框架从Rails更改为Sinatra或数据库。事实上,我如何在这个核心Hexagon中实现完全隔离的rails和mongodb的数据库适配器或框架适配器。有什么想法吗? 最佳答案 ROM呢?(Ruby对象映射器)。还有
我很难给出正确的答案,所以我会在这里征求我的问题。我正在研究RESTFulAPI。自然地,我有多种资源,其中一些由父子关系组成,一些是独立资源。我有点困难的地方是弄清楚如何让那些将根据我的API构建客户端的人更容易。情况是这样的。假设我有一个“街道”资源。每条街道都有多个住宅。SoStreet:has_manytoHomes和Homes:belongs_toStreet。如果用户想要在特定的home资源上请求HTTPGET,以下应该可行:http://mymap/streets/5/homes/10这允许用户获取ID为10的房屋的信息。直截了当。我的问题是,我授予用户访问权限是否违反了
据我了解,Python的扭曲框架为网络通信提供了更高级别的抽象(?)。我正在寻找在Rails应用程序中使用与twisted等效的Ruby。 最佳答案 看看EventMachine.它不像Twisted那样广泛,但它是围绕事件驱动网络编程的相同概念构建的。 关于python-Ruby是否有相当于Python的扭曲框架作为网络抽象层?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/9
是否有库提供用于编写RESTAPI文档的标记?我见过几家公司使用类似的文档模式,例如:http://api.teamlab.com/2.0/http://www.fullcontact.com/docs/?category=person我想知道他们是否使用相同的库或服务。本质上,该库应该根据标记文本生成用于API导航、搜索和显示的页面(很像用于ruby文档的YARD)。这是我目前发现的:rapi_docgem.这是一个article讨论用法。 最佳答案 你绝对应该看看Swagger.它是开源的,被数百个API使用,也被3sc