Java实现BP神经网络MNIST手写数字识别
如果需要源码,请在下方评论区留下邮箱,我看到就会发过去
由训练集数据可知,手写输入的数据维数为784维,而对应的输出结果为分别为0-9的10个数字,所以根据训练集的数据可知,在构建的神经网络的输入层的神经元的节点个数为784个,而对应的输出层的神经元个数为10个。隐层可选择单层或多层。
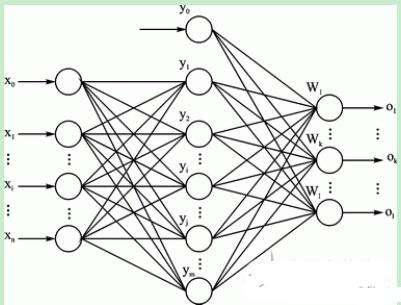
因为对于隐层的神经元个数的确定目前还没有什么比较完美的解决方案,所以对此经过自己查阅书籍和上网查阅资料,有以下的几种经验方式来确定隐层的神经元的个数,方式分别如下所示:
一般取(输入+输出)/2
隐层一般小于输入层
3)(输入层+1)/2
log(输入层)
log(输入层)+10
实验得到以第五种的方式得到的测试结果相对较高。
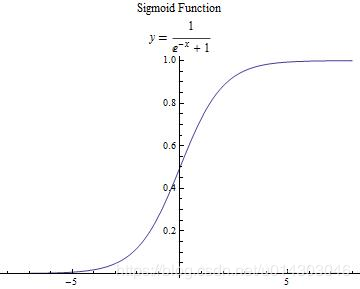
在《机器学习》的书中介绍了两种比较常用的函数,分别是阶跃函数和Sigmoid函数。最后自己采用了后者函数。
采用的是使用简单的随机数分配的方法,并且两层之间的神经元权值是通过二维数组进行保留,数组的索引就代表着两层对应的神经元的索引信息
采用的是使用简单的随机数分配的方法,并且两层之间的神经元权值是通过二维数组进行保留,数组的索引就代表着两层对应的神经元的索引信息
这里主要是采用了下面的方法:
Sum=sum+weight[i][j] * layer0[i];
参数的含义:将每个输入层中的神经元与神经元的权值信息weight[i][j]乘以对应的输入层神经元的阈值累加,然后再调用激活函数得到对应的隐层神经元的阈值。
方法和上面的类似,只是相对应的把权值信息进行了修改即可。
采用书上P103页的方法(西瓜书)
采用书上P103页的方法(西瓜书)
double newVal = momentum * prevWeight[j][i] + eta * delta[i] * layer[j];
参数:其中设置momentum 为0.9,设置eta 为0.25,prevWeight[j][i]表示神经元之间的权值,layer[j]和delta[i]表示两层不同神经元的阈值。
此处放一个多隐层BP神经网络的类(自己写的,有错误请指出):
/**
* BP神经网络类
* 使用了附加动量法进行优化
* 主要使用方法:
* 初始化: BP bp = new BP(new int[]{int,int*n,int}) //第一个int表示输入层,中间n个int表示隐藏层,最后一个int表示输出层
* 训练: bp.train(double[],double[]) //第一个double[]表示输入,第二个double[]表示期望输出
* 测试 int result = bp.test(double[]) //参数表示输入,返回值表示输出层最大权值
* 另有设置学习率和动量参数方法
*/
import java.util.Random;
public class BP {
private final double[][] layers;//输入层、隐含层、输出层
private final double[][] deltas;//每层误差
private final double[][][] weights;//权值
private final double[][][] prevUptWeights;//更新之前的权值信息
private final double[] target; //预测的输出内容
private double eta; //学习率
private double momentum; //动量参数
private final Random random; //主要是对权值采取的是随机产生的方法
//初始化
public BP(int[] size, double eta, double momentum) {
int len = size.length;
//初始化每层
layers = new double[len][];
for(int i = 0; i<len; i++) {
layers[i] = new double[size[i] + 1];
}
//初始化预测输出
target = new double[size[len - 1] + 1];
//初始化隐藏层和输出层的误差
deltas = new double[len - 1][];
for(int i = 0; i < (len - 1); i++) {
deltas[i] = new double[size[i + 1] + 1];
}
//使每次产生的随机数都是第一次的分配,这是有参数和没参数的区别
random = new Random(100000);
//初始化权值
weights = new double[len - 1][][];
for(int i = 0; i < (len - 1); i++) {
weights[i] = new double[size[i] + 1][size[i + 1] + 1];
}
randomizeWeights(weights);
//初始化更新前的权值
prevUptWeights = new double[len - 1][][];
for(int i = 0; i < (len - 1); i++) {
prevUptWeights[i] = new double[size[i] + 1][size[i + 1] + 1];
}
this.eta = eta; //学习率
this.momentum = momentum; //动态量
}
//随机产生神经元之间的权值信息
private void randomizeWeights(double[][][] matrix) {
for (int i = 0, len = matrix.length; i != len; i++) {
for (int j = 0, len2 = matrix[i].length; j != len2; j++) {
for(int k = 0, len3 = matrix[i][j].length; k != len3; k++) {
double real = random.nextDouble(); //随机分配着产生0-1之间的值
matrix[i][j][k] = random.nextDouble() > 0.5 ? real : -real;
}
}
}
}
//初始化输入层,隐含层,和输出层
public BP(int[] size) {
this(size, 0.25, 0.9);
}
//训练数据
public void train(double[] trainData, double[] target) {
loadValue(trainData,layers[0]); //加载输入的数据
loadValue(target,this.target); //加载输出的结果数据
forward(); //向前计算神经元权值(先算输入到隐含层的,然后再算隐含到输出层的权值)
calculateDelta(); //计算误差逆传播值
adjustWeight(); //调整更新神经元的权值
}
//加载数据
private void loadValue(double[] value,double [] layer) {
if (value.length != layer.length - 1)
throw new IllegalArgumentException("Size Do Not Match.");
System.arraycopy(value, 0, layer, 1, value.length); //调用系统复制数组的方法(存放输入的训练数据)
}
//向前计算(先算输入到隐含层的,然后再算隐含到输出层的权值)
private void forward() {
//计算隐含层到输出层的权值
for(int i = 0; i < (layers.length - 1); i++) {
forward(layers[i], layers[i+1], weights[i]);
}
}
//计算每一层的误差(因为在BP中,要达到使误差最小)(就是逆传播算法,书上有P101)
private void calculateDelta() {
outputErr(deltas[deltas.length-1],layers[layers.length - 1],target); //计算输出层的误差(因为要反过来算,所以先算输出层的)
for(int i = (layers.length - 1); i > 1; i--) {
hiddenErr(deltas[i - 2/*输入层没有误差*/],layers[i - 1],deltas[i - 1],weights[i - 1]); //计算隐含层的误差
}
}
//更新每层中的神经元的权值信息
private void adjustWeight() {
for(int i = (layers.length - 1); i > 0; i--) {
adjustWeight(deltas[i - 1], layers[i - 1], weights[i - 1], prevUptWeights[i - 1]);
}
}
//向前计算各个神经元的权值(layer0:某层的数据,layer1:下一层的内容,weight:某层到下一层的神经元的权值)
private void forward(double[] layer0, double[] layer1, double[][] weight) {
layer0[0] = 1.0;//给偏置神经元赋值为1(实际上添加了layer1层每个神经元的阙值)简直漂亮!!!
for (int j = 1, len = layer1.length; j != len; ++j) {
double sum = 0;//保存权值
for (int i = 0, len2 = layer0.length; i != len2; ++i) {
sum += weight[i][j] * layer0[i];
}
layer1[j] = sigmoid(sum); //调用神经元的激活函数来得到结果(结果肯定是在0-1之间的)
}
}
//计算输出层的误差(delte:误差,output:输出,target:预测输出)
private void outputErr(double[] delte, double[] output,double[] target) {
for (int idx = 1, len = delte.length; idx != len; ++idx) {
double o = output[idx];
delte[idx] = o * (1d - o) * (target[idx] - o);
}
}
//计算隐含层的误差(delta:本层误差,layer:本层,delta1:下一层误差,weights:权值)
private void hiddenErr(double[] delta, double[] layer, double[] delta1, double[][] weights) {
for (int j = 1, len = delta.length; j != len; ++j) {
double o = layer[j]; //神经元权值
double sum = 0;
for (int k = 1, len2 = delta1.length; k != len2; ++k) //由输出层来反向计算
sum += weights[j][k] * delta1[k];
delta[j] = o * (1d - o) * sum;
}
}
//更新每层中的神经元的权值信息(这也就是不断的训练过程)
private void adjustWeight(double[] delta, double[] layer, double[][] weight, double[][] prevWeight) {
layer[0] = 1;
for (int i = 1, len = delta.length; i != len; ++i) {
for (int j = 0, len2 = layer.length; j != len2; ++j) {
//通过公式计算误差限=(动态量*之前的该神经元的阈值+学习率*误差*对应神经元的阈值),来进行更新权值
double newVal = momentum * prevWeight[j][i] + eta * delta[i] * layer[j];
weight[j][i] += newVal; //得到新的神经元之间的权值
prevWeight[j][i] = newVal; //保存这一次得到的权值,方便下一次进行更新
}
}
}
//我这里用的是sigmoid激活函数,当然也可以用阶跃函数,看自己选择吧
private double sigmoid(double val) {
return 1d / (1d + Math.exp(-val));
}
//测试神经网络
public int test(double[] inData) {
if (inData.length != layers[0].length - 1)
throw new IllegalArgumentException("Size Do Not Match.");
System.arraycopy(inData, 0, layers[0], 1, inData.length);
forward();
return getNetworkOutput();
}
//返回最后的输出层的结果
private int getNetworkOutput() {
int len = layers[layers.length - 1].length;
double[] temp = new double[len - 1];
for (int i = 1; i != len; i++)
temp[i - 1] = layers[layers.length - 1][i];
//获得最大权值下标
double max = temp[0];
int idx = -1;
for (int i = 0; i <temp.length; i++) {
if (temp[i] >= max) {
max = temp[i];
idx = i;
}
}
return idx;
}
//设置学习率
public void setEta(double eta) {
this.eta = eta;
}
//设置动量参数
public void setMomentum(double momentum){
this.momentum = momentum;
}
}
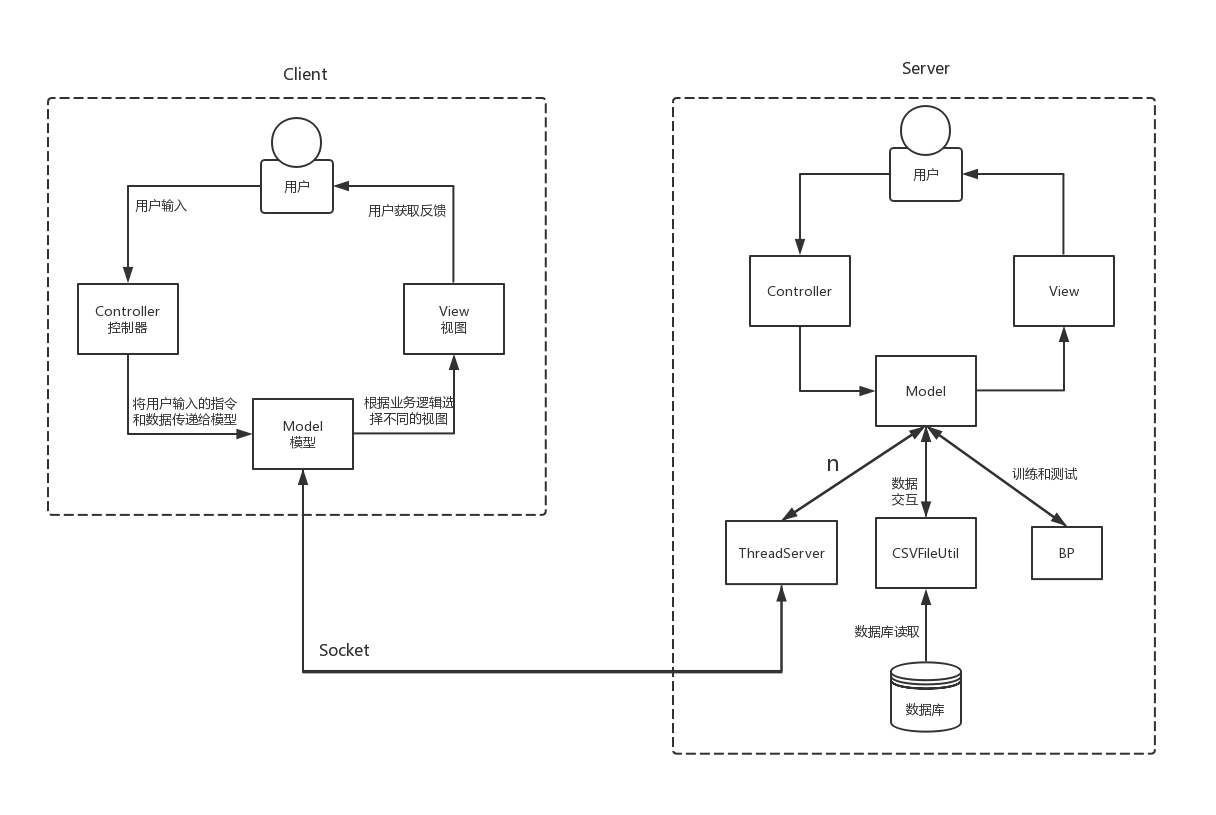
由于BP神经网络训练过程时间较长,所以采用客户端服务器(C/S)的形式,在服务器进行训练,在客户端直接进行识别,使用套接字进行通讯。
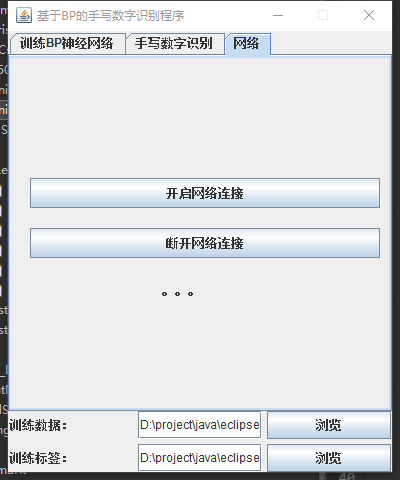
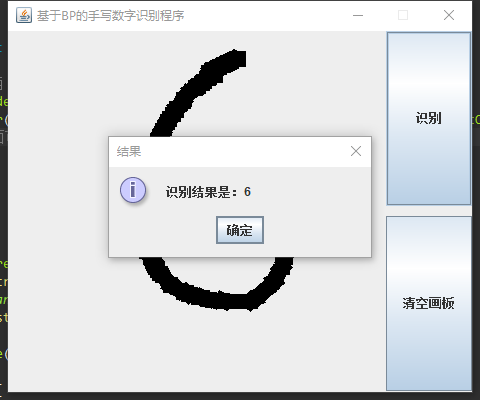
Model(模型)表示应用程序核心。
View(视图)显示数据。
Controller(控制器)处理输入。
MNIST数字集经过整理存储在CSV文件中。
以下是系统架构:
如果需要源码,请在下方评论区留下邮箱,我看到就会发过去
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o