127.0.0.1:6379> info memory
# Memory
used_memory:1132832 // Redis Amount of memory used to store data
used_memory_human:1.08M // Returns the total amount of memory in human readable form
used_memory_rss:2977792 // From the perspective of the operating system, the total physical memory occupied by the process
used_memory_rss_human:2.84M // used_memory_rss Readability mode display
used_memory_peak:1183808 // The maximum value of memory used, representing the peak value of used_memory
used_memory_peak_human:1.13M // Returns the value of used_memory_peak in a human readable format
used_memory_lua:37888 // Lua The amount of memory consumed by the engine。
used_memory_lua_human:37.00K
maxmemory:2147483648 // The maximum memory value that can be used, in bytes.
maxmemory_human:2.00G // readable form
maxmemory_policy:noeviction // Memory Retirement Policy
mem_fragmentation_ratio:2.79 // The ratio of used_memory_rss & used_memory represents the memory fragmentation rate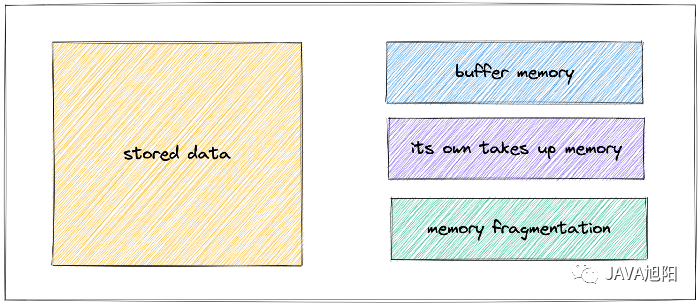 Redis自身的空进程占用的内存很小,可以忽略不计,而对象内存是最大的,里面存放了所有的数据。需要注意, 如果缓冲区有大流量的场景很容易失控,导致Redis内存不稳定。内存碎片过多导致有可用空间不足,无法存储数据。内存碎片Fragmentation = used_memory_rss 实际使用的物理内存(RSS 值)除以 used_memory 实际存储的数据内存。
Redis自身的空进程占用的内存很小,可以忽略不计,而对象内存是最大的,里面存放了所有的数据。需要注意, 如果缓冲区有大流量的场景很容易失控,导致Redis内存不稳定。内存碎片过多导致有可用空间不足,无法存储数据。内存碎片Fragmentation = used_memory_rss 实际使用的物理内存(RSS 值)除以 used_memory 实际存储的数据内存。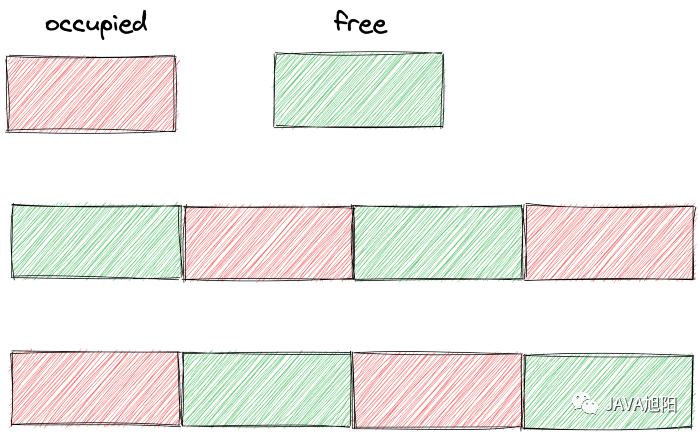
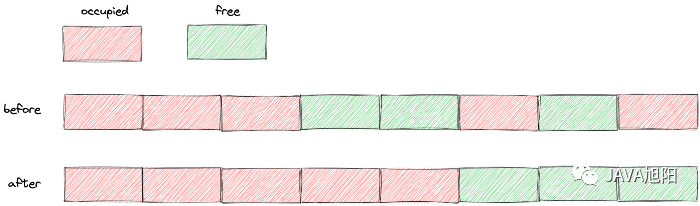 图片由作者提供自动清理虽然好,但也不要乱来。操作系统需要消耗资源将数据移动到新的位置,然后释放原来的空间。Redis 操作数据的指令是单线程的,所以在数据复制和移动时,只有清理碎片后才能处理请求,会造成性能损失。那么问题来了,如何减少对性能的影响来实现自动清理碎片?问得好,用下面两个参数来控制内存碎片清理和结束的时机,避免占用过多CPU,减少清理碎片对Redis处理请求的性能影响。启用自动内存碎片整理:
图片由作者提供自动清理虽然好,但也不要乱来。操作系统需要消耗资源将数据移动到新的位置,然后释放原来的空间。Redis 操作数据的指令是单线程的,所以在数据复制和移动时,只有清理碎片后才能处理请求,会造成性能损失。那么问题来了,如何减少对性能的影响来实现自动清理碎片?问得好,用下面两个参数来控制内存碎片清理和结束的时机,避免占用过多CPU,减少清理碎片对Redis处理请求的性能影响。启用自动内存碎片整理:CONFIG SET activedefrag yes作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
目录一.大致如下常见问题:(1)找不到程序所依赖的Qt库version`Qt_5'notfound(requiredby(2)CouldnotLoadtheQtplatformplugin"xcb"in""eventhoughitwasfound(3)打包到在不同的linux系统下,或者打包到高版本的相同系统下,运行程序时,直接提示段错误即segmentationfault,或者Illegalinstruction(coredumped)非法指令(4)ldd应用程序或者库,查看运行所依赖的库时,直接报段错误二.问题逐个分析,得出解决方法:(1)找不到程序所依赖的Qt库version`Qt_5'
我想使用ruby-prof和JMeter分析Rails应用程序。我对分析特定Controller/操作/或模型方法的建议方法不感兴趣,我想分析完整堆栈,从上到下。所以我运行这样的东西:RAILS_ENV=productionruby-prof-fprof.outscript/server>/dev/null然后我在上面运行我的JMeter测试计划。然而,问题是使用CTRL+C或SIGKILL中断它也会在ruby-prof可以写入任何输出之前杀死它。如何在不中断ruby-prof的情况下停止mongrel服务器? 最佳答案
在部署在heroku上的Rails应用程序(v:3.1)中,我在内存中获得了更多具有相同ID的对象。我的heroku控制台日志:>>Project.find_all_by_id(92).size=>2>>ActiveRecord::Base.connection.execute('select*fromprojectswhereid=92').to_a.size=>1这怎么可能?可能是什么问题? 最佳答案 解决方案根据您的SQL查询,您的数据库中显然没有重复条目。也许您的类项目中的size或length方法已被覆盖。我试过find_