文章目录
其实YOLO系列的原作者,推出YOLO_v3后就退隐江湖了,主要由于老美利用该技术来进行军事打击,十分令作者寒心。但奈何,还是有后继者提出了YOLO_v4系列,别说,一出现,又一次横扫世间。
作者AlexeyAB大神! YOLOv4 拥有43.5%mAP+65FPS ,达到了精度速度最优平衡,
作者团队:Alexey Bochkovskiy&中国台湾中央研究院
论文链接:
https://arxiv.org/pdf/2004.10934.pdf
————————————————
在讲YOLOv4之前,先介绍一下两个包:Bag of Freebies(免费包)和Bag-of-Specials(特赠包)
Bag of Freebies:指的是那些不增加模型复杂度,也不增加推理的计算量的训练方法技巧,来提高模型的准确度
Bag-of-Specials:指的是那些增加少许模型复杂度或计算量的训练技巧,但可以显著提高模型的准确度
BoF指的是
1)数据增强:图像几何变换(随机缩放,裁剪,旋转),Cutmix,Mosaic等
2)网络正则化:Dropout,Dropblock等
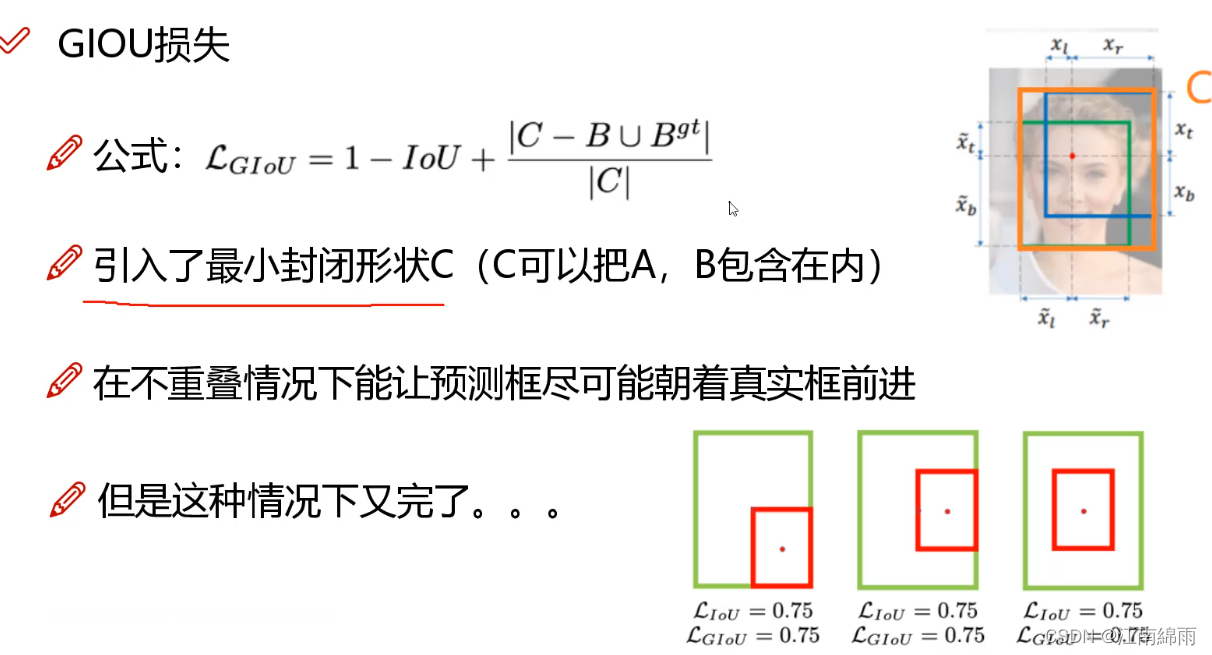
3) 损失函数的设计:边界框回归的损失函数的改进 CIOU
BoS指的是
1)增大模型感受野:SPP、ASPP等
2)引入注意力机制:SE、SAM
3)特征集成:PAN,BiFPN
4)激活函数改进:Swish、Mish
5)后处理方法改进:soft NMS、DIoU NMS
————————————————
YOLO_v4主要就是利用这两个包,修改了最先进的方法,并且使其更为有效。当然,还运用到了CBN,PAN, SAM等方法,从而使得 YOLO-v4 能够在一块 GPU 上就可以训练起来。
输入端的创新点:训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
BackBone主干网络:各种方法技巧结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
Head:输出层的锚框机制和Yolov3相同,主要改进的是训练时的回归框位置损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
下面我分为输入端、Backbone、Neck、Head层,依次进行讲解。
Yolov4对训练时的输入端进行改进,使得训练时在单张GPU上跑的结果也蛮好的。比如数据增强Mosaic、cmBN、SAT自对抗训练。
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。
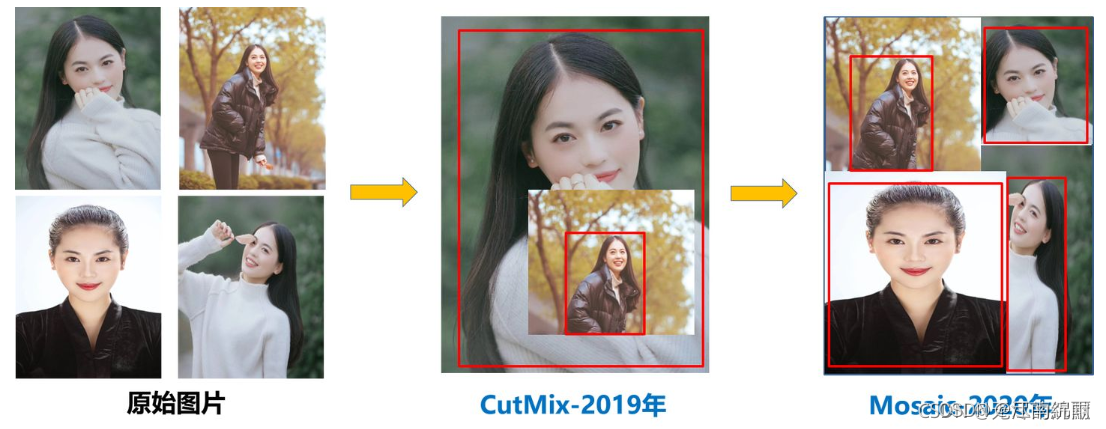
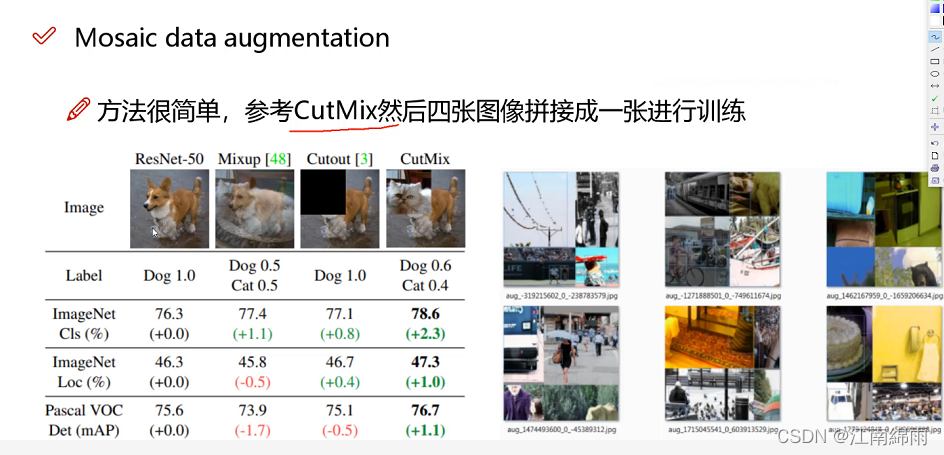
为什么要进行Mosaic数据增强呢?
在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
针对这种状况,Yolov4的作者采用了Mosaic数据增强的方式。
主要有2个优点:
自对抗训练(SAT)也代表了一种新的数据增加技术,在两个前后阶段操作。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对自己执行一种对抗性攻击,改变原始图像,以制造图像上没有期望对象的假象。在第二阶段,神经网络以正常的方式对这个修改后的图像进行检测。具体的可以参考这篇文章

CmBN表示CBN修改后的版本,定义为交叉微批标准化(Cross mini-Batch Normalization, CmBN)。这只在单个批内的小批之间收集统计信息。具体的可以参考这篇文章
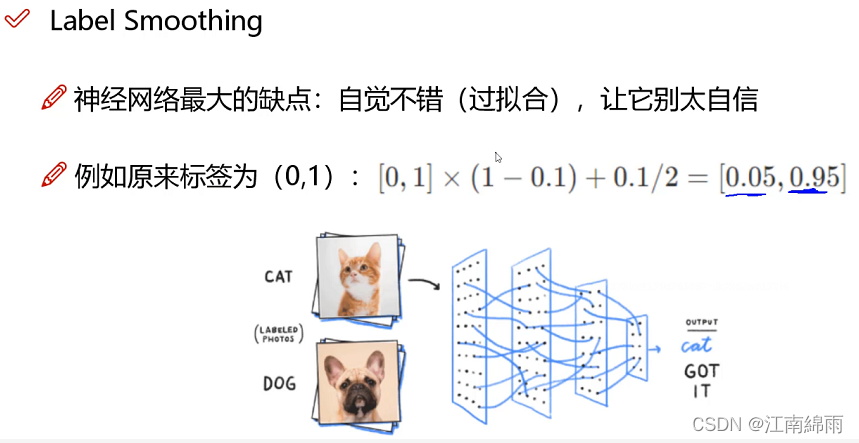
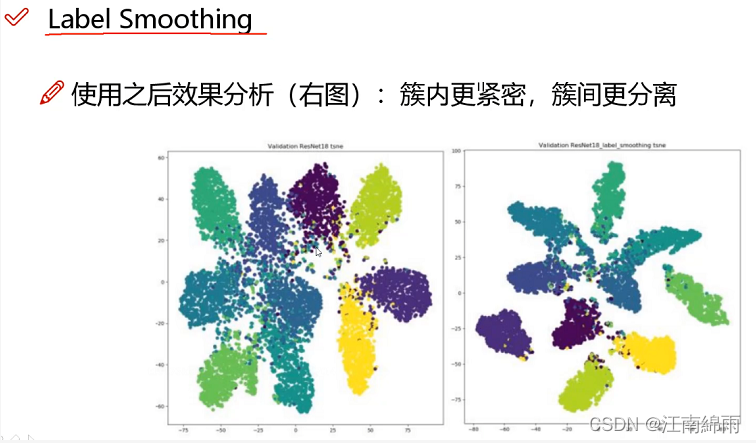
Backbone:采用的主干网络为 CSPDarknet53,CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块
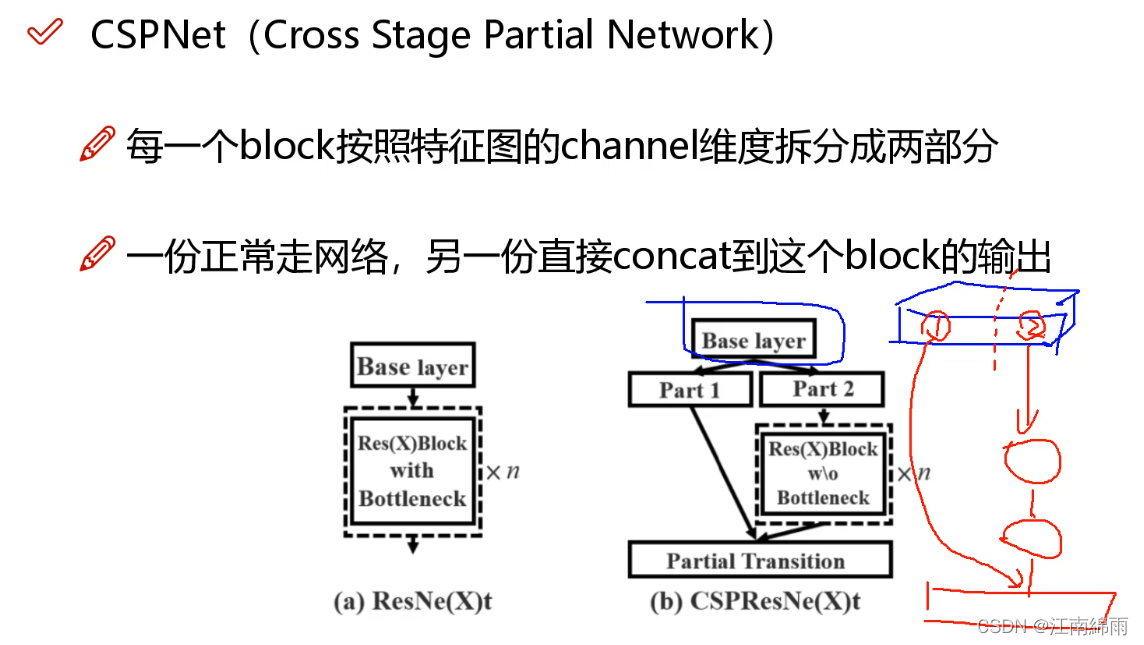
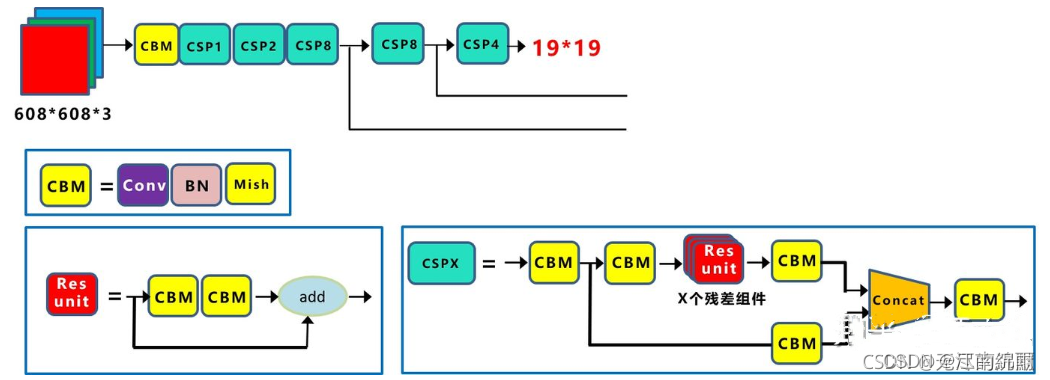
每个CSP模块前面的卷积核的大小都是3*3,stride=2,因此可以起到下采样的作用。
因为Backbone有5个CSP模块,输入图像是608608,所以特征图变化的规律是:608->304->152->76->38->19 经过5次CSP模块后得到1919大小的特征图。而且作者只在Backbone中采用了Mish激活函数,网络后面仍然采用Leaky_relu激活函数。YOLOv3的主干网络采用的是darknet53,yolov4的Backbone:采用的主干网络为 CSPDarknet53。
YOLOv4的作者是根据参考2019年的CSPNet的做法而改进的darknet53网络
CSPNet论文地址:https://arxiv.org/pdf/1911.11929.pdf
CSPNet全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中从计算量很大的问题。
CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。
这是因为类似于DenseNet的网络一样,更新权重的值反向传播,会造成重复计算梯度
因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
Mish激活函数是2019年下半年提出的激活函数
论文地址:https://arxiv.org/abs/1908.08681
和Leaky_relu激活函数的图形对比如下:
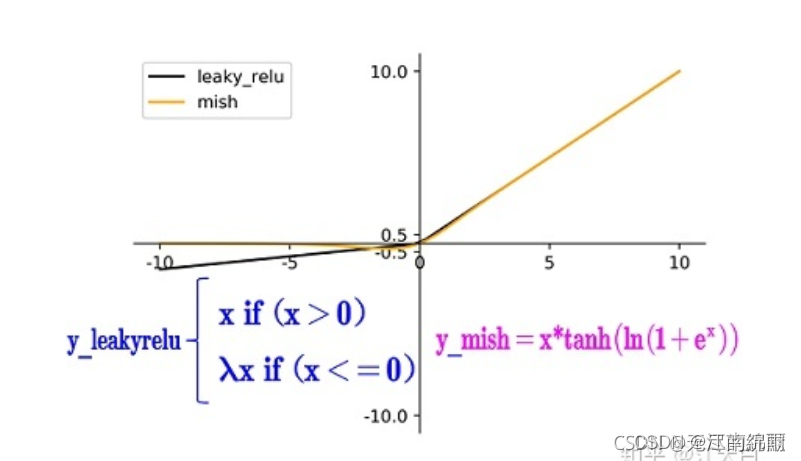
从图中可以看出该激活函数,在负值时并不是完全截断,而允许比较小的负梯度流入从而保证了信息的流动(因为梯度为负值时,作为relu激活函数,大多数神经元没有更新)
mish激活函数无边界,这让他避免了饱和(有下界,无上界)且每一点连续平滑且非单调性,从而使得梯度下降更好。

olov4中使用的Dropblock,其实和常见网络中的Dropout功能类似,也是缓解过拟合的一种正则化方式。
Dropblock在2018年提出,论文地址:https://arxiv.org/pdf/1810.12890.pdf
传统的Dropout很简单,一句话就可以说的清:随机删除减少神经元的数量,使网络变得更简单。
dropout主要作用在全连接层,而dropblock可以作用在任何卷积层之上。
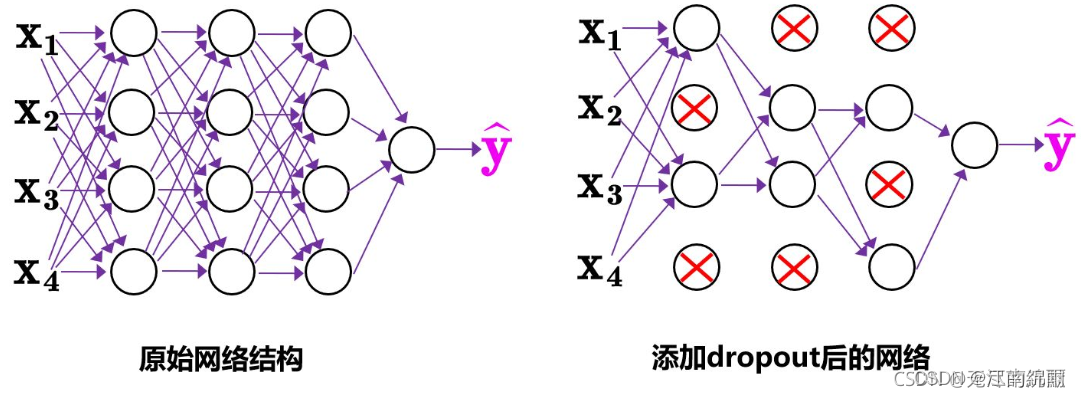
而Dropblock和Dropout相似,比如下图:
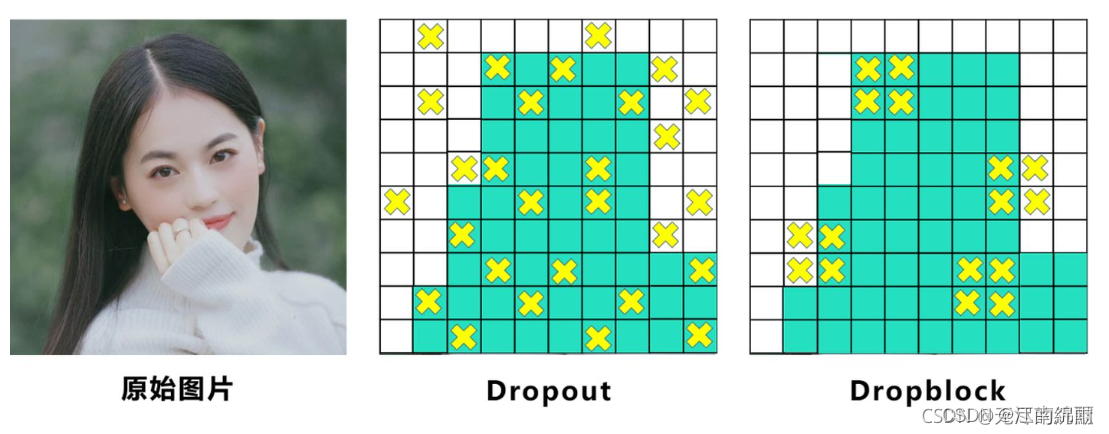
中间Dropout的方式会随机的删减丢弃一些信息,但Dropblock的研究者认为,卷积层对于这种随机丢弃并不敏感,因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。
因此,在全连接层上效果很好的Dropout在卷积层上效果并不好。
所以右图Dropblock的研究者则干脆整个局部区域进行删减丢弃。
这种方式其实是借鉴2017年的cutout数据增强的方式,cutout是将输入图像的部分区域清零,而Dropblock则是将Cutout应用到每一个特征图。而且并不是用固定的归零比率,而是在训练时以一个小的比率开始,随着训练过程线性的增加这个比率。
在特征图上一块一块的进行归0操作,去促使网络去学习更加鲁棒的特征
为了保证Dropblock后的特征图与原先特征图大小一致,需要和dropout一样,进行rescale操作
Dropblock的研究者与Cutout进行对比验证时,发现有几个特点:
优点一:Dropblock的效果优于Cutout
优点二:Cutout只能作用于输入层,而Dropblock则是将Cutout应用到网络中的每一个特征图上
优点三:Dropblock可以定制各种组合,在训练的不同阶段可以修改删减的概率,从空间层面和时间层面,和Cutout相比都有更精细的改进。
Yolov4中直接采用了更优的Dropblock,对网络的正则化过程进行了全面的升级改进。
Yolov4的Neck结构主要采用了SPP模块、FPN+PAN、SAM的方式
作者在SPP模块中,使用k={11,55,99,1313}的最大池化的方式,再将不同尺度的特征图进行Concat操作。spp模块是YOLOv4中在YOLOv3的基础上加了的模块,而PAN则也是YOLOv4的创新模块。
YOLOv3中的neck只有自顶向下的FPN,对特征图进行特征融合,而YOLOv4中则是FPN+PAN的方式对特征进一步的融合
下面是YOLOv3的neck中的FPN
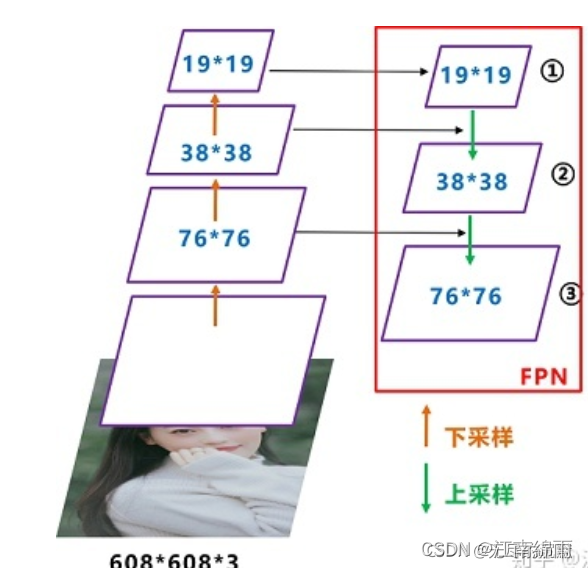
如图所示,FPN是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图。
而YOLOv4中的neck如下:
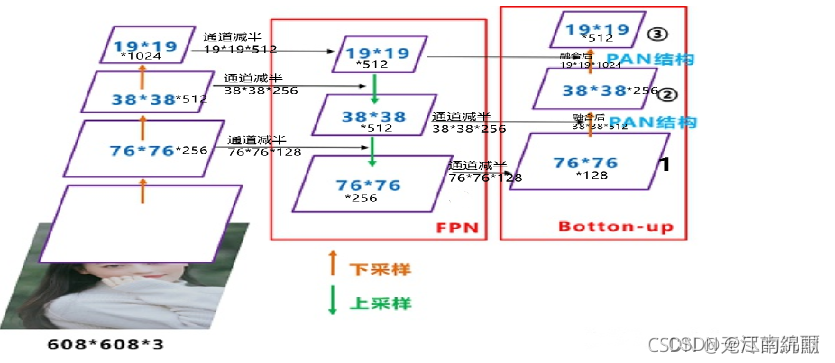
是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力
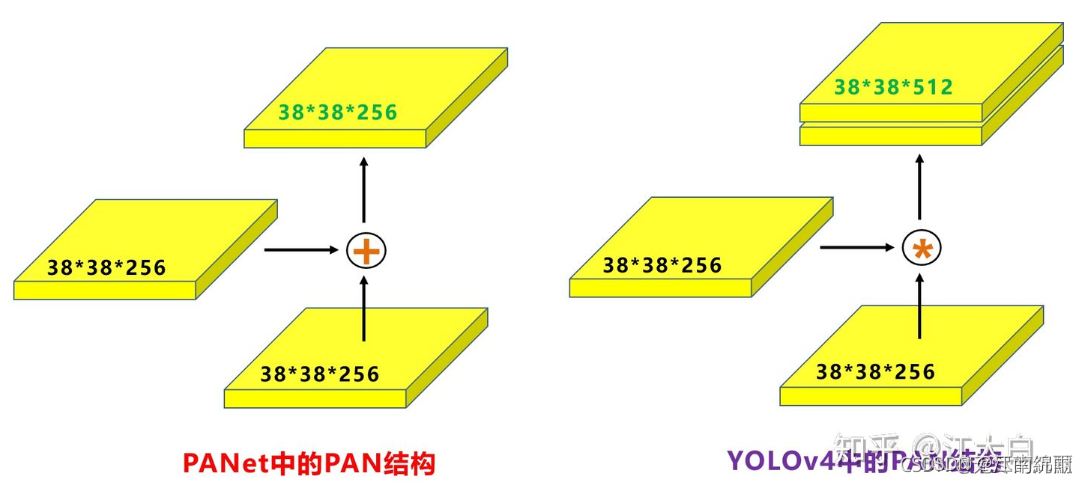
原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4中则采用**concat(route)**操作,特征图融合后的尺寸发生了变化
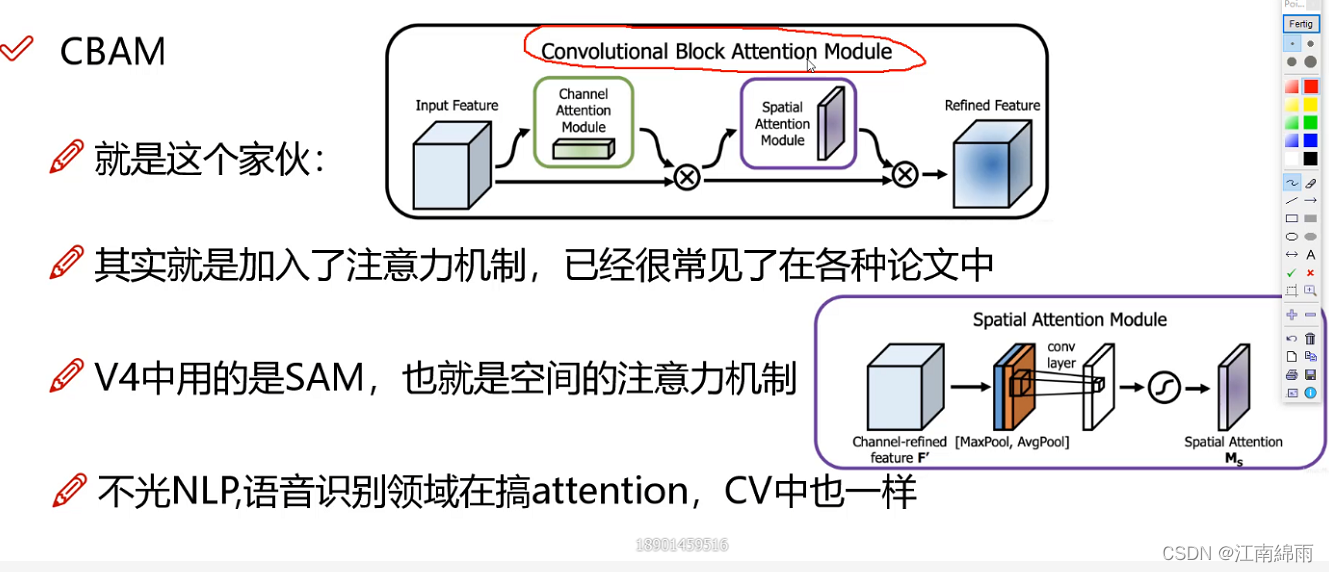
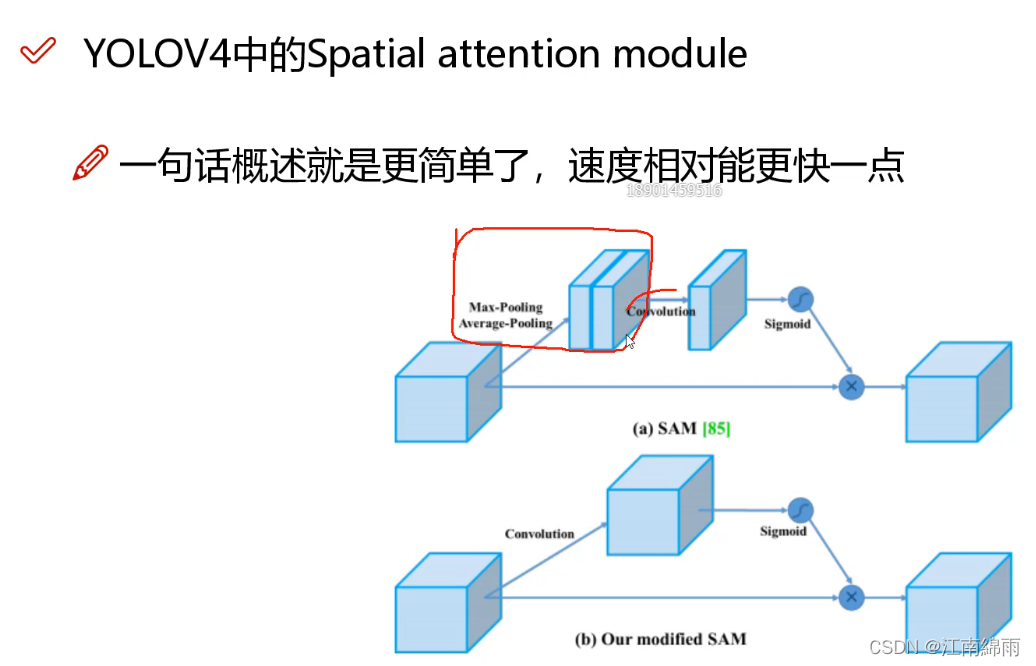
论文中提到的SAM是修改后的SAM版本,启发于CBAM。注意Modified SAM 是和点量权重相乘。
YOLO V4用CIOU损失代替了YOLOv3的box位置损失,取代了预测框和真实框的中心点坐标以及宽高信息设定MSE(均方误差)损失函数或者BCE损失函数,其他部分损失没改变。
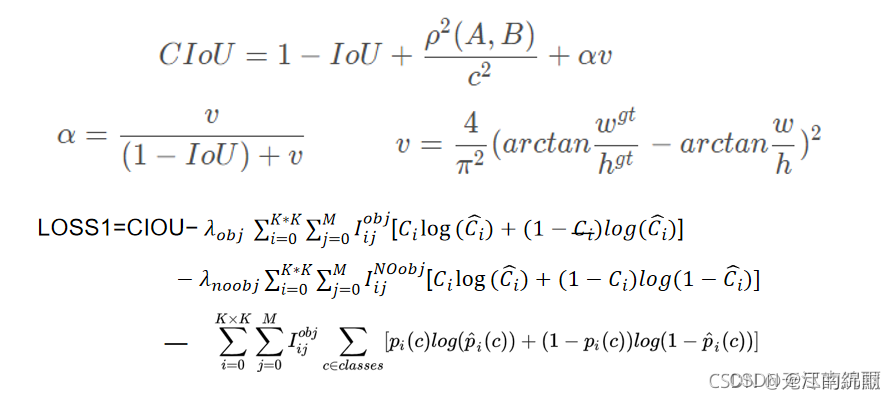


三个特征图一共可以解码出 19 × 19 × 3 + 38 × 38× 3 + 76 × 76 × 3 = 22743个box以及相应的类别、置信度。 首先,设置一个置信度阈值,筛选掉低于阈值的box,再经过DIOU_NMS(非极大值抑制)后,就可以输出整个网络的预测结果了。
DIOU_NMS的处理步骤如下:
1.遍历图片中所有识别出目标的类,对每个类的所有框进行单独分析
2.再将所有的狗的预测框按分数从大到小排序,如下图:

3.下一步,设狗类概率最大的框为target,依次比较它和其他非0框进行(IOU-DIOU)计算,如果计算结果大于设定的DIoU阈值(这里是ε=0.5),就将该框的狗的概率置为0,如下target和第二个框的(IOU-DIOU)明显大于阈值0.5,所以舍去第二个框,把这个框的狗类概率设为0,如下图;

4.依次迭代,假设在经历了所有的扫描之后,对Dog类别只留下了两个框,如下:

因为对计算机来说,图片可能出现两只Dog,保留概率不为0的框是安全的。不过代码后续设置了一定的阈值(比如0.3)来删除掉概率太低的框,这里的蓝色框在最后并没有保留,因为它在最后会因为阈值不够而被剔除。
5.上面描述了对Dog种类进行的框选择。接下来,我们还要对其它79种类别分别进行上面的操作
6.最后进行纵向跨类的比较(为什么?因为上面就算保留了最大概率的Dog框,但该框可能在Cat的类别也为概率最大且比Dog的概率更大,那么我们最终要判断该框为Cat而不是Dog)。
作者除了提到了上述的NMS方法,还提到了如下的方式:

总体而言,YOLO_v4其实就是“超级缝合怪”,集百家之所长。同时还通过数据增强的方式来通过小batch_size来获得高MAP,并且巧用CSP和PAN模块来减少计算量,使得这个融合怪也能在单GPU上快速的训练、运行,获得高效的检测结果。
至此我对YOLO_v4的原理,进行了简单讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
所以我从维基百科上抓取了这段ruby代码并做了一些修改:@trie=Hash.new()defbuild(str)node=@triestr.each_char{|ch|cur=chprev_node=nodenode=node[cur]ifnode==nilprev_node[cur]=Hash.new()node=prev_node[cur]end}endbuild('dogs')puts@trie.inspect我首先在控制台irb上运行它,每次我输出node时,每次{}都会给我一个空哈希值,但当我实际调用时该函数使用参数'dogs'字符串构建,它确实有效,并输出{"d"=>
运行有问题或需要源码请点赞关注收藏后评论区留言一、利用ContentResolver读写联系人在实际开发中,普通App很少会开放数据接口给其他应用访问。内容组件能够派上用场的情况往往是App想要访问系统应用的通讯数据,比如查看联系人,短信,通话记录等等,以及对这些通讯数据及逆行增删改查。首先要给AndroidMaifest.xml中添加响应的权限配置 下面是往手机通讯录添加联系人信息的例子效果如下分成三个步骤先查出联系人的基本信息,然后查询联系人号码,再查询联系人邮箱代码 ContactAddActivity类packagecom.example.chapter07;importandroid
各位朋友们,大家好啊,今天我要分享的是关于文件操作方面的知识。文章目录为什么会有文件操作什么是文件文件操作文件指针文件的打开与关闭fopen(打开文件)fclose(关闭文件)打开文件的方式文件的顺序读写fgets函数fputc函数fgets函数fputs函数fprintf函数fscanf函数文件的非顺序读写fseek函数ftell函数rewind函数二进制读写fwrite函数`fread函数结语为什么会有文件操作那么大家可能会问:为什么会有文件操作呢?前面我们可能都了解了通讯录,我们知道当我们使用通讯录的时候我们可以添加联系人,也可以删除联系人,但是当我们退出程序之后下次再进来的时候,我们要
目录 YOLO简介argpares模块detect模块导入部分主函数main()run()资源处理for循环输出结果 YOLO简介YOLO是目前最先进的目标检测模型之一,现在博客上常有的是如何使用YOLO模型训练自己的数据集,而鲜有对YOLO代码的精读。我认为只有对算法和代码实现有全面的了解,才能将YOLO使用的更加得心应手。这里的代码精读为YOLO v5,github版本为6.0。版本不同代码也会有所不同,请结合源码阅读本文。本文使用注释完成对每行代码的解读,文段来概括总结每个代码段。yolov5代码6.0版本github代码地址argpares模块在了解yolov5代码之前,首先要了解py
本文档适用于SOPHGO(算能)BM1684-SE5及对应通用云开发空间,主要内容:注意:由于SOPHGOSE5微服务器的CPU是基于ARM架构,部分步骤将在基于x86架构CPU的开发环境中完成初始化开发环境(基于x86架构CPU的开发环境中完成)YOLO3D目标检测算法模型转换(基于x86架构CPU的开发环境中完成)YOLO3D模型推理测试(处理后的YOLO3D项目文件将被拷贝至SOPHGOSE5微服务器上推理测试)1.初始化开发环境(基于x86架构CPU的开发环境中完成)1.1初始化开发环境(若wget后的地址不可用,请前往算能官网下载Docker镜像及SDK)#切换成root权限sudo
本篇博文目录:一.SpringSecurity简介1.SpringSecurity2.SpringSecurity相关概念二.认证和授权1.认证(1)使用SpringSecurity进行简单的认证(SpringBoot项目中)(2)SpringSecurity的原理(3)SpringSecurity核心类(4)认证登入案例(JWT+SpringSecurity实现登入案例)2.授权(1)加入权限到Authentication中(2)SecurityConfig配置文件中开启注解权限配置(3)给接口中的方法添加访问权限(4)用户权限表的建立3.自定义失败处理(1)创建异常处理类(2)配置移除处理
从ReactRouterV3过渡到V4后,我再也无法使ReactTransition组低级API工作。React路由器的文档显示了与CSS动画相关的高级API的示例,这些示例与低水平的JS风味不起作用。任何人都设法或知道让这个工作?看答案已经一个月了,所以我想您找到了自己的出路,但可能会对他人有所帮助。我创建了这个:https://www.npmjs.com/package/reeact-router-v4-transition在我遇到同样的问题之后。它在开关组件中提供了一种过渡组。从将开关更改为TransitionSwitch的Appart,它不需要大幅度更改。我将在接下来的几天(可能是星期
性能指标一、性能测试指标性能测试是通过测试工具模拟多种正常、峰值及异常负载条件来对系统的各项性能指标进行测试。目的:验证软件系统是否能够达到用户提出的性能指标,发现系统中存在的性能瓶颈并加以优化。二、指标分为两大类:软件指标:术语释义TPS:(每秒事务数)在每秒时间内系统可处理完毕的事务数。TPS很大程度体现系统性能能力。TPS(TransactionPerSecond)是指单位时间(每秒)系统处理的事务量。事务可以是用户自定义的一系列操作或者动作的集合,比如“用户注册“事务是点击注册按钮,填写用户注册信息,点击提交按钮,以及加载注册成功页面的动作集合。这3个个公式都是对的第1个公式计算的是绝