柯煜昌 青云科技研发顾问级工程师 目前从事 RadonDB 容器化研发,华中科技大学研究生毕业,有多年的数据库内核开发经验。
文章字数 3800+,阅读时间 15 分钟
MySQL 5.7 的字典信息保存在非事务表中,并且存放在不同的文件中(.FRM,.PAR,.OPT,.TRN,.TRG 等)。所有 DDL 操作都不是 Crash Safe,而且对于组合 DDL(ALTER 多个表)会出现有的成功有的失败的情况,而不是总体失败。这样主从复制就出现了问题,也导致基于复制的高可用系统不再安全。
MySQL 8.0 推出新特性 - 原子 DDL,解决了以上的问题。
DDL 是指数据定义语言(Data Definition Language),负责数据结构的定义与数据对象的定义。原子 DDL 是指一个 DDL 操作是不可分割的,要么全成功要么全失败。
MySQL 8.0 只有 InnoDB 存储引擎支持原子 DDL。
支持语句:数据库、表空间、表、索引的 CREATE、ALTER 以及 DROP 语句,以及 TRUNCATE TABLE 语句。
MySQL 8.0 系统表均以 InnoDB 存储引擎存储,涉及到字典对象的均支持原子 DDL。
支持的语句:存储过程、触发器、视图以及用户定义函数(UDF)的 CREATE 和 DROP 、ALTER 操作,用户和角色的 CREATE、ALTER、DROP 语句,以及适用的 RENAME 语句,以及 GRANT 和 REVOKE 语句。
不支持的语句:
首先,8.0 将字典信息存放到事务引擎的系统表(InnoDB 存储引擎)中。这样 DDL 操作转变成一组对系统表的 DML 操作,从而失败后可以依据事务引擎自身的事务回滚保证系统表的原子性。
似乎 DDL 原子性就此就可以完成,但实际上并没有这么简单。首先字典信息不光是系统表,还有一组字典缓存,如:
此外,字典信息只是数据库对象的元数据,DDL 操作不光要修改字典信息,还要实实在在的操作对象,以及对象本身在内存中缓存。
此外,binlog 也要考虑 DDL 失败的情况。
因此,原子 DDL 在处理 DDL 失败的时候,不光是直接回滚系统表的数据,而且也要保证内存缓存,数据库对象也能回滚到一致状态。
为了解决 DDL 失败情况中数据库对象的回滚,8.0 引入了系统表 DDL_LOG。该表在 mysql 库中。不可见,也不能人为操作。如果想了解该表的结果,先编译一个 debug 版的 MySQL:
SET SESSION debug='+d,skip_dd_table_access_check';
show create table mysql.innodb_ddl_log;
可以看到如下表结构:
CREATE TABLE `innodb_ddl_log` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`thread_id` bigint unsigned NOT NULL,
`type` int unsigned NOT NULL,
`space_id` int unsigned DEFAULT NULL,
`page_no` int unsigned DEFAULT NULL,
`index_id` bigint unsigned DEFAULT NULL,
`table_id` bigint unsigned DEFAULT NULL,
`old_file_path` varchar(512) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`new_file_path` varchar(512) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `thread_id` (`thread_id`)
) /*!50100 TABLESPACE `mysql` */ ENGINE=InnoDB AUTO_INCREMENT=48 DEFAULT CHARSET=utf8 COLLATE=utf8_bin STATS_PERSISTENT=0 ROW_FORMAT=DYNAMIC
在 8.0 中,这个表需要满足两个场景以及两个任务:
场景 1: 符合 DDL 失败的场景,需要回滚部分完成的 DDL。
场景 2:DDL 进行中,发生故障(掉电、软硬件故障等),重启机器需要完成部分 DDL。
两个任务:
任务 1:失败后回滚,执行反向操作。
任务 2:如果成功,则执行清理工作。
也许有人会问,为什么执行成功需要执行清理工作呢?
之所以要执行清理工作,因为 ibd 文件和索引一旦删除就不能恢复。为了实现回滚,DDL 删除这些对象时候,并不是真正删除,而是先将它们备份一下,以备回滚时使用。所以只有确认 DDL 已经执行成功,这些备份对象不需要了,才执行清理工作。
为了将这个原理将清楚,我们流程相对简单的 CREATE TABLE 讲起,管中窥豹,可见一斑。假设已经有编译好了 8.0 debug 版本,并且 innodb_file_per_table 为 on,先执行以下命令:
mysql> set global log_error_verbosity=3;
Query OK, 0 rows affected (0.00 sec)
mysql> set global innodb_print_ddl_logs = on;
Query OK, 0 rows affected (0.00 sec)
从而开启了ddl log的日志,然后创建表:
mysql> create table t2 (a int);
Query OK, 0 rows affected (25 min 26.42 sec)
可以看到如下日志:
XXXXX 8 [Note] [MY-012473] [InnoDB] DDL log insert : [DDL record: DELETE SPACE, id=20, thread_id=8, space_id=6, old_file_path=./test/t2.ibd]
XXXXX 8 [Note] [MY-012478] [InnoDB] DDL log delete : 20
XXXXX 8 [Note] [MY-012477] [InnoDB] DDL log insert : [DDL record: REMOVE CACHE, id=21, thread_id=8, table_id=1067, new_file_path=test/t2]
XXXXX 8 [Note] [MY-012478] [InnoDB] DDL log delete : 21
XXXXX 8 [Note] [MY-012472] [InnoDB] DDL log insert : [DDL record: FREE, id=22, thread_id=8, space_id=6, index_id=157, page_no=4]
XXXXX 8 [Note] [MY-012478] [InnoDB] DDL log delete : 22
XXXXX 8 [Note] [MY-012485] [InnoDB] DDL log post ddl : begin for thread id : 8
XXXXX 8 [Note] [MY-012486] [InnoDB] DDL log post ddl : end for thread id : 8
create table 的 DDL 只有反向操作日志记录,而无清理操作日志记录。细心的读者可能看到日志中插入某条 DDL log,随后又将其删除,会心生疑惑。但这正是 MySQL 原子 DDL 的秘密所在。我们选 DELETE SPACE 这个 DDL 日志写入函数Log_DDL::write_delete_space_log 来揭秘这个过程。
dberr_t Log_DDL::write_delete_space_log(trx_t *trx, const dict_table_t *table,
space_id_t space_id,
const char *file_path, bool is_drop,
bool dict_locked) {
ut_ad(trx == thd_to_trx(current_thd));
ut_ad(table == nullptr || dict_table_is_file_per_table(table));
if (skip(table, trx->mysql_thd)) {
return (DB_SUCCESS);
}
uint64_t id = next_id();
ulint thread_id = thd_get_thread_id(trx->mysql_thd);
dberr_t err;
trx->ddl_operation = true;
DBUG_INJECT_CRASH("ddl_log_crash_before_delete_space_log",
crash_before_delete_space_log_counter++);
if (is_drop) { //(1)
err = insert_delete_space_log(trx, id, thread_id, space_id, file_path,
dict_locked);
if (err != DB_SUCCESS) {
return err;
}
DBUG_INJECT_CRASH("ddl_log_crash_after_delete_space_log",
crash_after_delete_space_log_counter++);
} else { // (2)
err = insert_delete_space_log(nullptr, id, thread_id, space_id, file_path,
dict_locked);
if (err != DB_SUCCESS) {
return err;
}
DBUG_INJECT_CRASH("ddl_log_crash_after_delete_space_log",
crash_after_delete_space_log_counter++);
DBUG_EXECUTE_IF("DDL_Log_remove_inject_error_2",
srv_inject_too_many_concurrent_trxs = true;);
err = delete_by_id(trx, id, dict_locked); //(3)
ut_ad(err == DB_SUCCESS || err == DB_TOO_MANY_CONCURRENT_TRXS);
DBUG_EXECUTE_IF("DDL_Log_remove_inject_error_2",
srv_inject_too_many_concurrent_trxs = false;);
DBUG_INJECT_CRASH("ddl_log_crash_after_delete_space_delete",
crash_after_delete_space_delete_counter++);
}
return (err);
}
在create table 这个过程中调用write_delete_space_log,is_drop 为false,执行以上代码执行分支 (2) 和 (3) 。注意的是 insert_delete_space_log 第一个参数为空,这意味着会在创建一个后台事务(调用trx_allocate_for_background)插入DELETE_SPACE 记录到innodb_ddl_log 表中,然后提交该事务。注意到(3) 处delete_by_id 第一个参数为trx , 这里的trx 即本次 DDL 的事务,(3) 所做的动作是在本次事务中删除(2)插入的记录。
为什么是这样的逻辑呢?
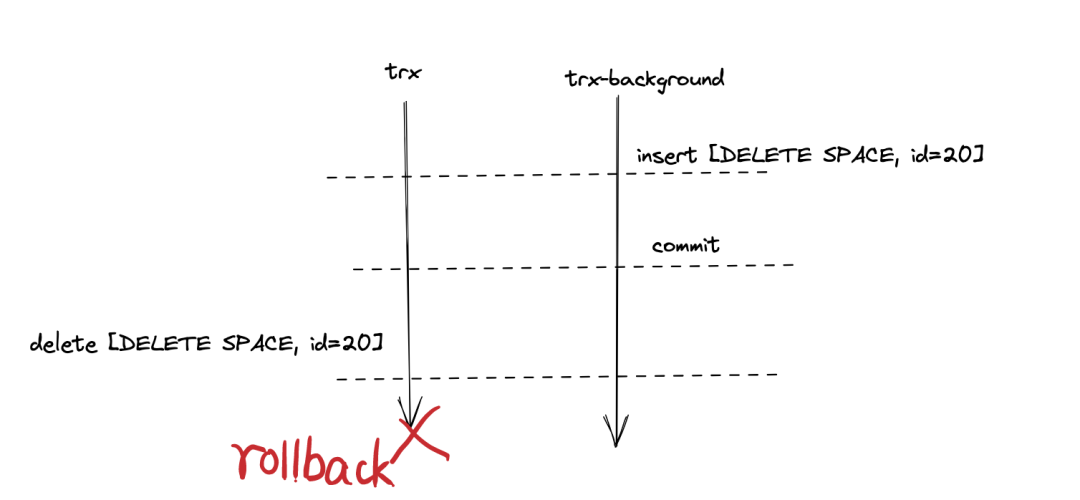
以下分两种情况来讨论,如上图所示:
trx 成功提交,那么 innodb_ddl_log 并没有该 DDL 的记录,因此在后续的post_ddl 中什么也不做(post_ddl 在后面会描述)。trx会回滚。此时,上图中delete [DELETE SPACE, id=20]这个动作也会回滚。最后,innodb_ddl_log 中就会存在DELETE SPACE 这条记录,后续执行post_ddl 进行 Replay(重演), 从而删除这次失败的create table 的 DDL 已经创建的表空间。你可以发现,create table 的 DDL 创建表空间,就一定会以这样的机制往innodb_ddl_log 中插入一条相反的动作DELETE SPACE的日志记录,所以也被称为反向操作日志。其它 DDL log 记录的操作如REMOVE CACHE 、FREE 日志记录的写入也是类似的逻辑。复杂的 DDL,不光是会插入反向操作日志记录,也会插入清理操作日志。比如TRUNCATE 表操作会将原有的表空间重命名为一个零时表空间,当 DDL 成功之后,需要通过post_ddl Replay DDL log 记录,将临时表空间删除。如果失败,又需要 post_ddl重演 DDL log,执行反向操作,将临时表空间重命名为原来的表空间。总之,如果是反向操作日志,则使用background trx 插入并提交,然后使用trx 删除;如果是清理日志,则使用trx 插入即可。
注意:
innodb_ddl_log表与其他 InnoDB 表一样,对该表所有操作 InnoDB 引擎都会产生 Redo 日志与 Undo 记录,所以不要将 DDL log 表中反向操作记录看作 Undo log,这两者不在同一个抽象层次上。而且反向操作在另一个事务中执行,而回滚时,Undo log 则是在原有同一个事务上执行。
我们知道 MySQL 有一个 innodb_flush_log_at_trx_commit 参数,当设置为 0 时,提交时并不会立刻将 Redo log 刷入持久存储中。虽然能提高性能,但在掉电或者停机时会有一定概率丢失已经提交的事务。对于 DML 操作来说,这样仅仅是丢失事务,但对于 DDL 来说,丢失 DDL 的事务,就会导致数据库元数据与其他数据不一致,以至数据库系统无法正常工作。
所以,在trx_commit 会根据该事务是否为 DDL 操作,进行特殊处理:
无论innodb_flush_log_at_trx_commit参数如何设置,与 DDL 有关的事务,提交时必须日志刷盘!
在理解了 DDL log 的机制之后,笔者问大家一个问题,对于create table 来说,是先执行write_delete_space_log 还是先创建表空间呢?
我们先假设是先创建表空间(A 动作),再写反向操作日志(B 动作)。如果 A 执行结束后出现掉的情况,此时 B 还未执行,此时create table 动作并没有完成,而innodb_ddl_log 不存在DELETE SPACE 这样的 DDL 反向日志记录,数据库崩溃恢复后,数据库系统会将系统表数据回滚,但是 A 创建的表空间却没有删除,由于存在中间状态,此时create table 就不是原子DDL 了。
所以,在 DDL 中每个步骤中,先写入该步骤的反向操作日志记录到innodb_ddl_log ,再执行该步骤。也就是说 DDL Log 写入时机在执行步骤之前。如果create table 已经写入了 DDL log, 但是没有创建表空间就出现掉电情况呢? 这并不要紧,在 post_ddl 做 Replay 的时候,会进行处理。
在 DDL 操作完成之后,无论 DDL 的事务提交还是回滚,都会调用post_ddl 函数,post_ddl 则会调用replay函数进行 Replay。此外,MySQL 8.0 数据库崩溃恢复过程中,与 MySQL 5.7 相比,也多了ha_post_recover的过程,它会调用log_ddl->recover 将 innodb_ddl_log 所有的日志记录进行 Replay。
在post_ddl调用的是replay_by_thread_id,崩溃恢复中ha_post_recover 调用的是replay_all,其逻辑如下描述:
thread_id 为索引(thread_id 与trx 是可以一一对应的),以逆序方式将所有记录获取出来,然后根据记录的内容,依次执行 Replay 动作,最后删除已经重演的记录。replay_all 将innodb_ddl_log 所有记录逆序方式获取出来,依次执行 Replay 动作,最后删除已经重演的记录。可以看到,以上两个函数都有将记录逆序的获取的过程,为什么要逆序呢?
我们如果将 DDL 中每个步骤看做一个函数,参数为数据库系统。假设第 i 个步骤函数为oi,那么n个步骤就是 n 个函数的复合函数:
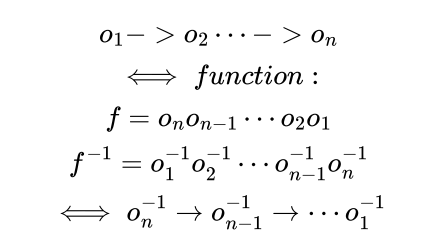
也即,复合函数的逆时所有步骤逆函数的反向复合。所以反向操作需要将 DDL log 逆序进行处理。
DDL 的清理动作往往没有顺序要求,逆向操作与正向操作效果往往是一样的,所以统一进行逆序处理也没有问题。
与 Redo、Undo 类似,每个类型的日志重演均要考虑其幂等性。
所谓幂等性,就是执行多次和执行一次的效果是一样的。特别是在崩溃恢复的时候,在重演反向操作的时候,尚未完成时发生掉电故障,重新进行崩溃恢复。此时某项重演操作可能发生多次。
因此,MySQL 8.0 实现这些重演操作,必须要考虑幂等性。最典型是重演一些删除操作,必须先判断数据库对象是否存在。如果存在,才进行删除,否则什么都不做。
Tips:说到这里,笔者推荐一本书《具体数学:计算机科学中的一块基石》此书讲解了许多计算机科学中用到的数学知识及技巧,并特别著墨于算法分析方面。
post_ddl , post_ddl 作用在前面已经描述,用以r Replay 系统表 innodb_ddl_log 记录的日志;ha_post_recover,而 InnoDB 的 ha_post_recover 就是调用 post_ddl 执行 DDL 的反向操作;write_bin_log 写 binlog。MySQL 8.0 支持原子 DDL,并不意味着 DDL 可以通过 SQL 语句命令进行回滚。实际上除了 SQLServer 外,几乎所有的数据库系统不支持 DDL 的 SQL 命令进行回滚,DDL 回滚引入的问题远远多于其带来的好处。
MySQL 8.0 只承诺单个 DDL 语句的原子性,并不能保证多个 DDL 组合也能保持原子性。某大厂为了实现 Truncate table flashback ,仅仅在 MySQL 的 Server 层将 truncate table 动作转换为 rename table 动作,flashback 的时候将表、索引、约束重新以 RENAME DDL 组合执行来实现 flashback,这个是及其危险的,不保证其原子性。笔者也完成过此功能,并没有如此取巧,而是老老实实的从 Server 层、InnoDB 存储引擎、binlog 各方面进行改造,完整保证其原子性。
MySQL 8.0 用这种方法实现原子 DDL,并不意味着其它数据库也是这种方式实现原子DDL。
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
术语中文解释Ability原子化服务帮助用户完成任务的原子化服务,和用户的意图进行关联。Fulfillment服务履行通过图标,卡片,语音等形式呈现用户意图。开发者通过接口的方式,处理用户意图,返回内容。Intent意图用于表达用户想要达成的目标或完成的任务。HUAWEIAssistant智能助手“无微不智”的个人助手,通过不断的学习用户的使用习惯,不断的为用户提供贴心的精准的便捷的个性化服务。AISearch全局搜索用户可快速搜索关键词,与之匹配的原子化服务则会出现在搜索结果中。SmartService智慧服务用户订阅原子化服务,在到达特定触发条件(时间、地点、事件)后,卡片推送至用户智能助
我正在尝试绕过rails配置这个极其复杂的迷宫。到目前为止,我设法在ubuntu上设置了rvm(出于某种原因,ruby在ubuntu存储库中已经过时了)。我设法建立了一个Rails项目。我希望我的测试项目使用mysql而不是mysqlite。当我尝试“rakedb:migrate”时,出现错误:“!!!缺少mysql2gem。将其添加到您的Gemfile:gem'mysql2'”当我尝试“geminstallmysql”时,出现错误,告诉我需要为安装命令提供参数。但是,参数列表很大,我不知道该选择哪些。如何通过在ubuntu上运行的rvm和mysql获取rails3?谢谢。
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
目录1、yum安装mysql修改密码(1)在mysql里面修改(2)第二种方式,利用mysqladmin修改密码2、没有密码,登录mysql修改密码3、mysql的安全设置1、yum安装mysql在CentOS中默认安装有MariaDB(MySQL的一个分支),安装完成之后可以直接覆盖MariaDB。rpm-qa|grepmariadb查询是否安装了mariadbrpm-e--nodepsmariadb-libs-5.5.60-1.el7_5.x86_64卸载mariadwgethttp://dev.mysql.com/get/mysql57-community-release-el7-11.
我是Ruby的新手。我安装了DataMapper并且正在尝试安装dm-mysql-adapter-1.0.2gem。但是当我尝试安装时,出现以下错误。我正在使用ubuntu操作系统。vinoth@vinoth-laptop:~/Downloads$geminstalldm-mysql-adapter-1.0.2----with-mysql-lib=/usr/lib/mysql----with-mysql-conf=/usr/bin/mysqlWARNING:Installingto~/.gemsince/home/vinoth/gemsand/home/vinoth/gems/bina
我目前正在构建一个需要mysql2gem的RoR项目。我成功安装了gem。因为它出现在我的gem列表中。[root@vc2cmmka035538nsimple_cms]#gemlist***LOCALGEMS***actionmailer(3.2.3)actionpack(3.2.3)activemodel(3.2.3)activerecord(3.2.3)activeresource(3.2.3)activesupport(3.2.14,3.2.3)arel(3.0.2)bigdecimal(1.1.0)builder(3.2.2,3.0.0)bundler(1.1.5)c2c_li
我想使用托管在我自己服务器上的mysql数据库。我已经更改了DATABASE_URL和SHARED_DATABASE_URL配置变量以指向我的服务器,但它仍在尝试连接到heroku的amazonaws服务器。我该如何解决? 最佳答案 根据Herokudocumentation,更改DATABASE_URL是正确的方法。Ifyouwouldliketohaveyourrailsapplicationconnecttoanon-Herokuprovideddatabase,youcantakeadvantageofthissamemec