相信你有在抖音或视频号刷到过这样的视频
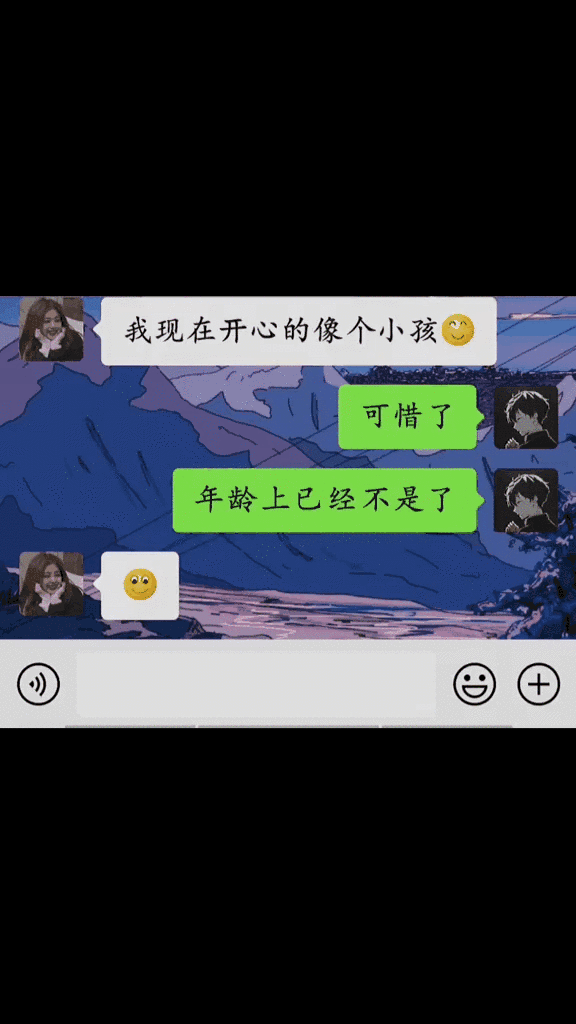
这样由微信对话合成的视频,因为内容有趣,很多人都喜欢看,播放量都是很恐怖的。 做这样的视频也很赚钱,某位大v的收益 
原理就是利用巨大的播放量,添加商品推广链接,有人通过链接购买商品,你赚取佣金。
制作这样的视频,一般做法是:
这样下来几个步骤其实挺麻烦的,并且制作每个视频其实都属于是重复劳作。
所以我们今天,教大家制作一个一键生成微信对话视频的工具,让你能够省时省力,抢占先机!
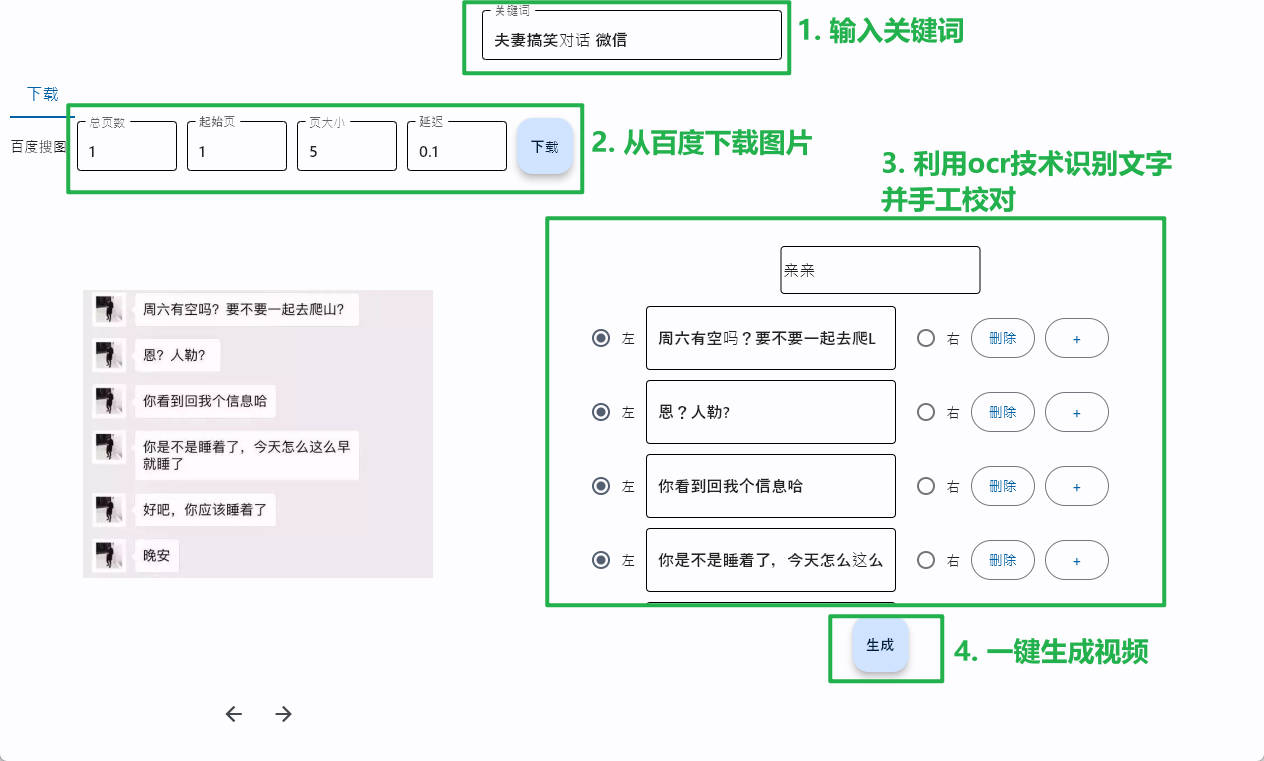
只需要在界面点点点就能生成视频了,很方便有木有!
用到的技术有
原来用到了这么多技术!不过不用担心,我都已经写好了,本文就是教大家怎么实现的,想直接用成品的同学,点击下面的链接获取!
链接:https://pan.baidu.com/s/1u78R9vhtnY5fwehlK17Z6Q?pwd=yb87 提取码:yb87
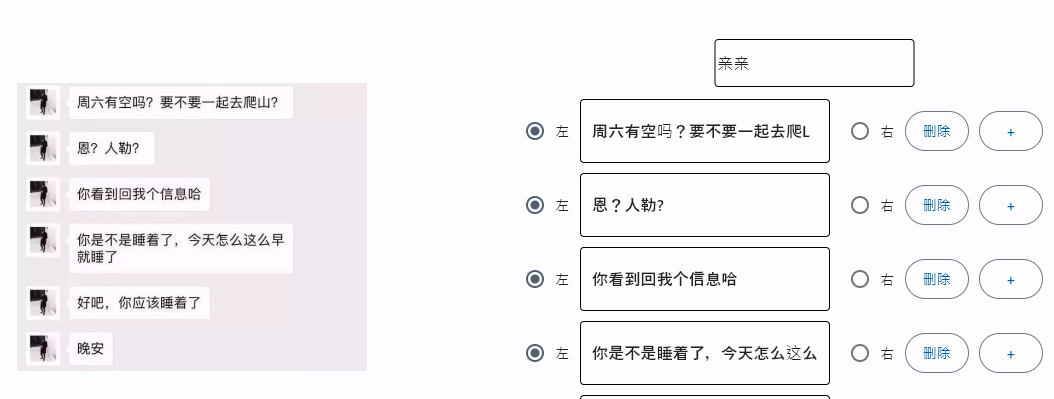
我们从https://image.baidu.com/search搜索图片,提取出每张图片的地址,然后进行下载,主要代码如下(代码为主要部分代码)
url = (
"https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj"
"&ct=201326592&is=&fp=result&queryWord=%s&cl=2&lm=-1&ie=utf-8&oe=utf-8"
"&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%s&s=&se=&tab=&width=&height=&face=0"
"&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=%s&rn=%d&gsm=1e&1594447993172="
% (search, search, str(pn), self.__per_page)
)
# 设置header防403
try:
time.sleep(self.time_sleep)
req = urllib.request.Request(url=url, headers=self.headers)
page = urllib.request.urlopen(req)
self.headers["Cookie"] = self.handle_baidu_cookie(
self.headers["Cookie"], page.info().get_all("Set-Cookie")
)
rsp = page.read()
page.close()
except UnicodeDecodeError as e:
self.logger.error(e)
self.logger.error("-----UnicodeDecodeErrorurl:", url)
使用cnocr库,我们就能实现本地ocr识别,而不需要网络,代码如下
self.model = CnOcr(
det_model_name="ch_PP-OCRv3_det",
)
out = self.model.ocr(
cv2.imdecode(self.read_file(f), -1),
)
for i in out:
i["score"] = float(i["score"])
i["position"] = i["position"].astype(float).tolist()
target_path.joinpath(file_name + ".json").write_text(
json.dumps(out, ensure_ascii=False, indent=4)
)
我们基于文字的内容和位置,判断文字是属于
res = []
"""去掉标题栏"""
if json_content and "中国" in json_content[0]["text"]:
# 中国联通行,去掉
x = json_content[0]["position"][0][0]
for i in range(1, len(json_content)):
if abs(json_content[i]["position"][0][0] - x) <= 20:
continue
else:
break
json_content = json_content[:i]
"""去掉‘微信’"""
if (
json_content
and "微信" in json_content[0]["text"]
and len(json_content[0]["text"]) < 8
):
json_content = json_content[1:]
"""首行是否为标题"""
if not json_content:
return res
left_top_position = json_content[0]["position"][0]
left_top_position_x = left_top_position[0]
left_top_position_y = left_top_position[1]
if left_top_position_y < 30 and len(json_content[0]["text"]) < 5:
# 认为是标题
res.append({"position": "title", "text": json_content[0]["text"]})
json_content = json_content[1:]
"""同一句话判断的阈值"""
same_sentence_threshold = 30
for i in range(1, len(json_content)):
same_sentence_threshold = min(
same_sentence_threshold,
abs(
json_content[i]["position"][0][1]
- json_content[i - 1]["position"][0][1]
),
)
same_sentence_threshold = max(50, same_sentence_threshold + 35) # 误差
if not json_content:
return res
"""找到左侧和右侧的位置"""
left_around_position = min([i["position"][0][0] for i in json_content])
right_around_position = max([i["position"][1][0] for i in json_content])
"""判断左右"""
n = len(json_content)
text = ""
position_left = 0
position_right = 0
for i in range(n):
if re.compile(r"[0-9]{1,2}:[ ]{0,1}[0-9]{1,2}").findall(
json_content[i]["text"]
):
# 微信时间
continue
if "微信" in json_content[i]["text"]:
# ”微信“标题
continue
if (
i > 0
and abs(
json_content[i]["position"][0][1]
- json_content[i - 1]["position"][0][1]
)
< same_sentence_threshold
):
# 认为当前话跟上一句话是同一句话
text += json_content[i]["text"]
else:
# 现在是另一个人说话,将上一个说的话保存
if text:
if res and res[-1]["position"] == "left":
# 如果上一句话是左边说的,我们更倾向于下一句话是右边的人说的
float_value = 25
else:
# 否则,更倾向于左边的人说的
float_value = -5
if not res:
# 第一句话更倾向于右边的人说的
float_value = 25
if abs(position_left - left_around_position) + float_value < abs(
position_right - right_around_position
):
# 离左侧更近
res.append({"position": "left", "text": text})
else:
# 离右侧更近
res.append({"position": "right", "text": text})
text = json_content[i]["text"]
position_left = json_content[i]["position"][0][0]
position_right = json_content[i]["position"][1][0]
if text:
if res and res[-1]["position"] == "left":
# 如果上一句话是左边说的,我们更倾向于下一句话是右边的人说的
float_value = 25
else:
# 否则,更倾向于左边的人说的
float_value = -5
if not res:
# 第一句话更倾向于右边的人说的
float_value = 25
if abs(position_left - left_around_position) + float_value < abs(
position_right - right_around_position
):
# 离左侧更近
res.append({"position": "left", "text": text})
else:
# 离右侧更近
res.append({"position": "right", "text": text})
if len(res) == 1:
return []
return res
当然了,判断无法百分百正确,所以我们后续添加了手工修正
基于flet库, 实现了ui界面
我们启动了一个fastapi服务,用于调用模拟微信对话
app = FastAPI()
app.mount(
"/static",
StaticFiles(directory=MAIN_PATH.joinpath("weixin_chat", "static")),
name="static",
)
@app.route("/")
def index(*args, **kwargs):
return HTMLResponse(
MAIN_PATH.joinpath(
"weixin_chat",
"index.html",
).read_text(encoding="utf-8")
)
使用playwright库,打开浏览器,自动化进行操作,输入每条对话内容后,进行截图,保存到本地。
browser = playwright.chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
page.goto("http://127.0.0.1:36999")
page.wait_for_load_state()
"""生成标题"""
if formatted_jsons[0]["position"] == "title":
page.fill(title, formatted_jsons[0]["text"])
formatted_jsons = formatted_jsons[1:]
else:
titles = ["佳佳", "小小", "♥", "❀", "啊呜", "奔波儿灞与灞波儿奔", "亲亲"]
page.fill(title, random.choice(titles))
time.sleep(0.2)
"""跳转到对话页"""
page.click(
"#vueApp > div > div.edit-content > div.tab > ul > li:nth-child(2) > a"
)
time.sleep(0.2)
page.wait_for_selector(
"#tabContent2 > div > div.dialog-user-items > div:nth-child(1) > div > a.dialog-user-face-a > input[type=file]"
)
"""清空对话"""
page.on("dialog", lambda dialog: dialog.accept())
page.click(clear_conv)
time.sleep(0.2)
"""选取头像"""
photos = self.two_random_photo()
page.set_input_files(my_photo, photos[0])
time.sleep(0.2)
page.set_input_files(second_photo, photos[1])
time.sleep(0.2)
_uuid = "".join(
re.compile(r"[0-9a-zA-Z\u4e00-\u9fa5]*").findall(
"".join(map(lambda e: e["text"], formatted_jsons))
)
)
save_path = WORK_PATH.joinpath(self.keyword, "images", _uuid[:15])
save_path.mkdir(parents=True, exist_ok=True)
index = 0
for _json in formatted_jsons:
if _json["position"] == "left":
page.click(select_left)
else:
page.click(select_right)
time.sleep(0.2)
page.fill(input_words, _json["text"])
page.click(add_words)
time.sleep(0.2)
save_file = save_path.joinpath(f"{index}.jpg")
page.locator(target_area).screenshot(
path=save_file, quality=100, type="jpeg"
)
index += 1
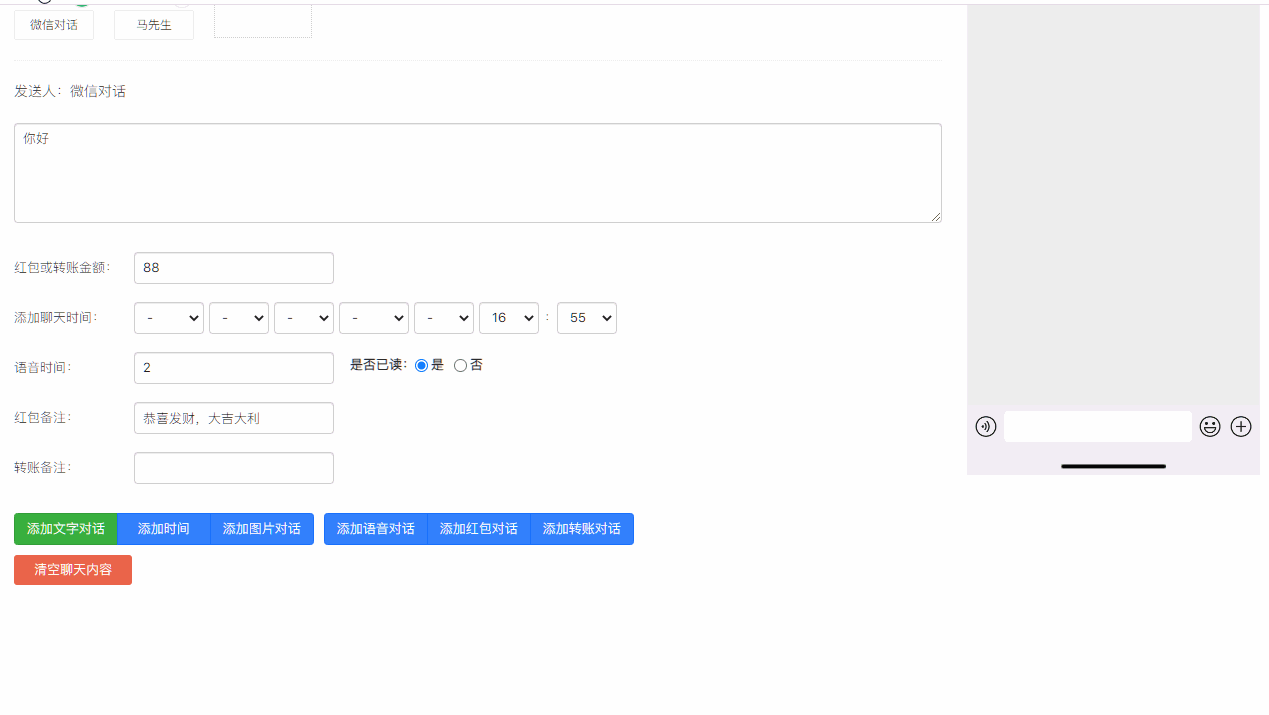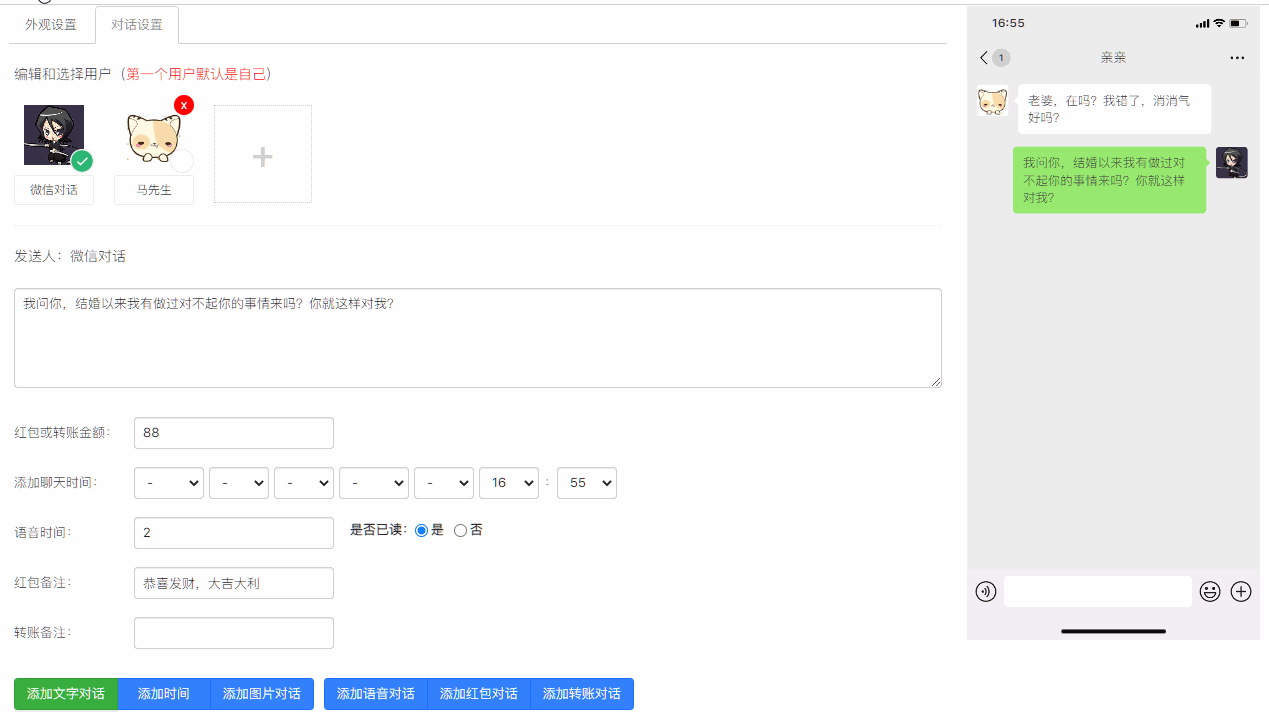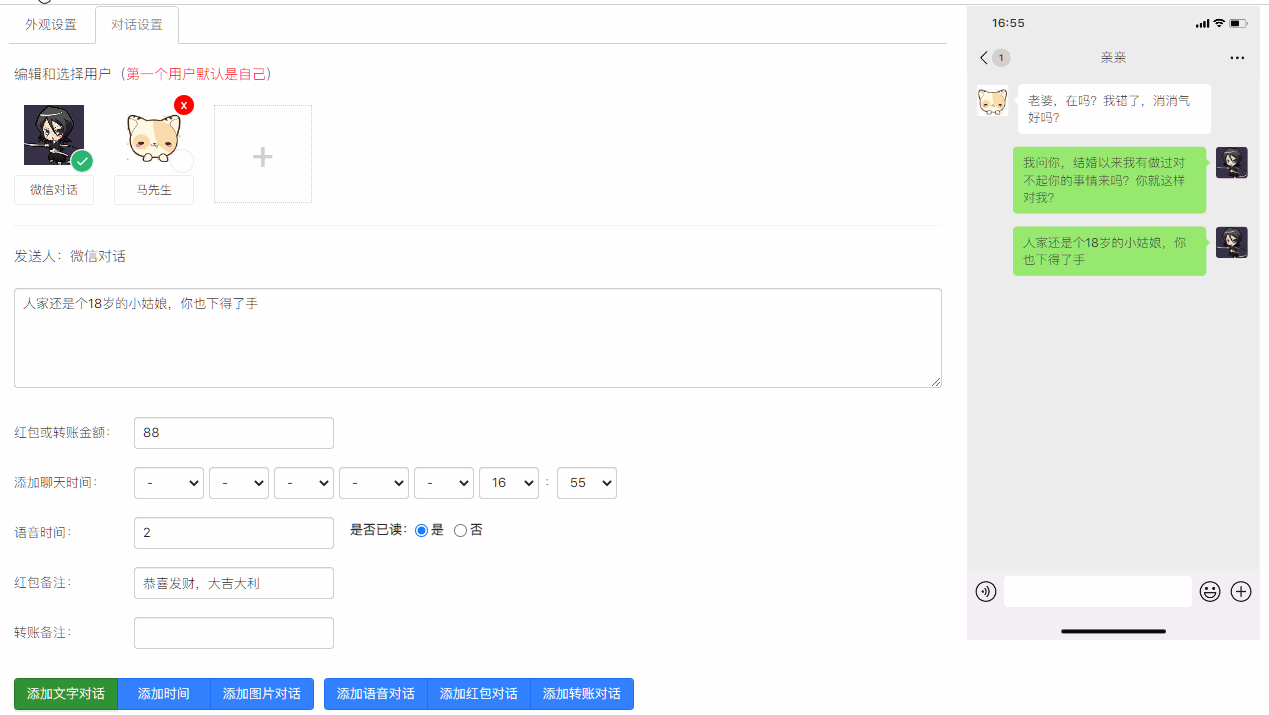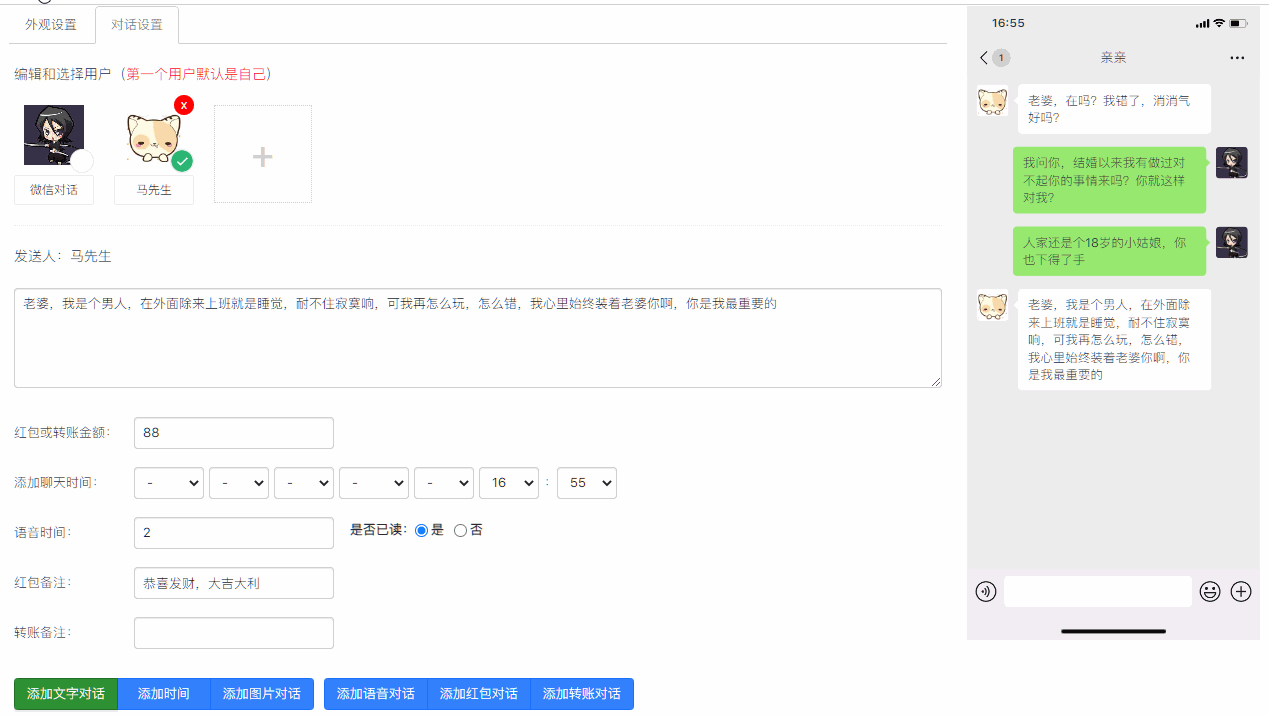
截图、音频合成视频,我们用到了moviepy,Pillow库,将图片按照名称,以固定的间隔拼合为视频,并在每个拼合的位置添加微信消息提示音。
images = glob.glob(str(path.joinpath("*.jpg")))
if not images:
return
images = sorted(images, key=lambda e: int(e.split("\\")[-1].split(".")[0]))
images = self.resize_images(images)
if not self.output_path:
video_path = WORK_PATH.joinpath(self.keyword, "output")
video_path.mkdir(parents=True, exist_ok=True)
else:
video_path = Path(self.output_path)
video_file = video_path.joinpath(str(path).split("\\")[-1] + ".mp4")
fps = 1 / 1.5
video_clip = ImageSequenceClip(images, fps=fps)
during = video_clip.duration
wechat_audio = AudioFileClip(
str(MAIN_PATH.joinpath("wechat_sound", "9411.mp3"))
)
audio_clips = []
i = 0
while i < during:
audio_clips.append(wechat_audio.set_start(i))
i += 1.5
final_audio_clip = CompositeAudioClip(audio_clips).set_fps(44100)
video_clip = video_clip.set_audio(final_audio_clip.subclip(0, during))
video_clip.write_videofile(str(video_file))
self.logger.info(f"{video_file}生成完成")
这样我们的视频就制作完成啦。
生成完后,文件保存在workspace/output文件夹中
 效果⬇
效果⬇  可能有的小伙伴会说:就这?真的有人看?
可能有的小伙伴会说:就这?真的有人看?
我还真做了测试,在抖音发了两个视频!
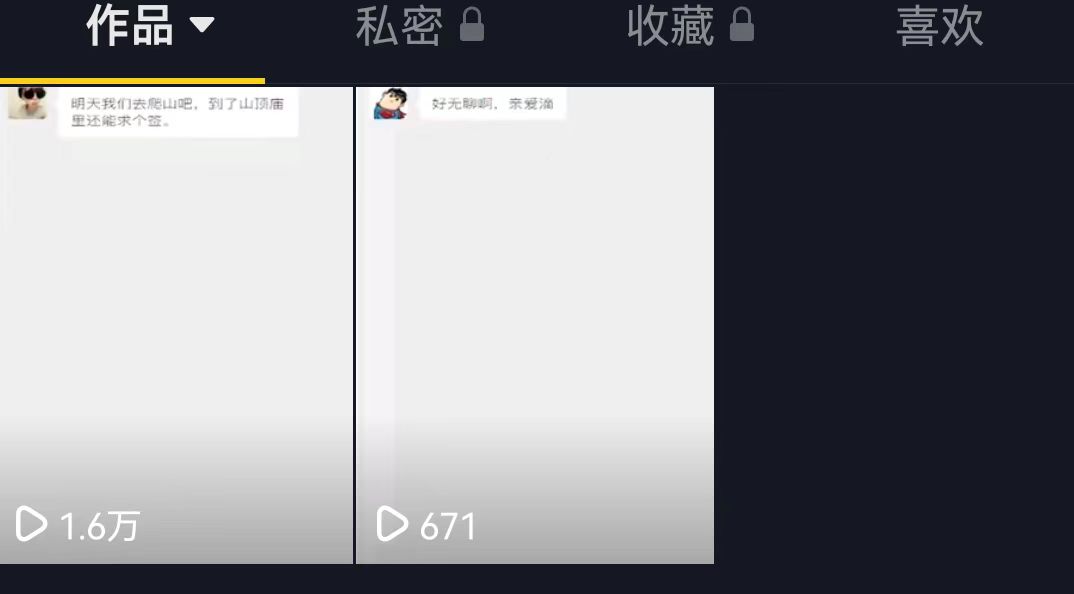 第一个只有167的播放量,第二个视频就冲到了1.6万!
第一个只有167的播放量,第二个视频就冲到了1.6万!
所以完全是行得通的!
需要的小伙伴,点击⬇链接获取全部源代码!
链接:https://pan.baidu.com/s/1u78R9vhtnY5fwehlK17Z6Q?pwd=yb87 提取码:yb87
本文由 mdnice 多平台发布
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
有这些railscast。http://railscasts.com/episodes/218-making-generators-in-rails-3有了这个,你就会知道如何创建样式表和脚手架生成器。http://railscasts.com/episodes/216-generators-in-rails-3通过这个,您可以了解如何添加一些文件来修改脚手架View。我想把两者结合起来。我想创建一个生成器,它也可以创建脚手架View。有点像RyanBates漂亮的生成器或web_app_themegem(https://github.com/pilu/web-app-theme)。我
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
前言一般来说,前端根据后台返回code码展示对应内容只需要在前台判断code值展示对应的内容即可,但要是匹配的code码比较多或者多个页面用到时,为了便于后期维护,后台就会使用字典表让前端匹配,下面我将在微信小程序中通过wxs的方法实现这个操作。为什么要使用wxs?{{method(a,b)}}可以看到,上述代码是一个调用方法传值的操作,在vue中很常见,多用于数据之间的转换,但由于微信小程序诸多限制的原因,你并不能优雅的这样操作,可能有人会说,为什么不用if判断实现呢?但是if判断的局限性在于如果存在数据量过大时,大量重复性操作和if判断会让你的代码显得异常冗余。wxswxs相当于是一个独立
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现