由于深度学习模型结构越来越复杂,参数量也越来越大,需要大量的算力去做模型的训练和推理。然而随着移动设备的普及,将深度学习模型部署于计算资源有限基于ARM的移动设备成为了研究的热点。
ShuffleNet[1]是一种专门为计算资源有限的设备设计的神经网络结构,主要采用了pointwise group convolution 和 channel shuffle两种技术,在保留了模型精度的同时极大减少了计算开销。
[1] Zhang X, Zhou X, Lin M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices[C].Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6848-6856.
在论文中,提到了目前sota的两个工作,一个是谷歌的Xception,另一个是facebook推出的ResNeXt。
Xception[2]主要涉及了一个技术:深度可分离卷积,即把原本常规的卷积操作分为两步去做。
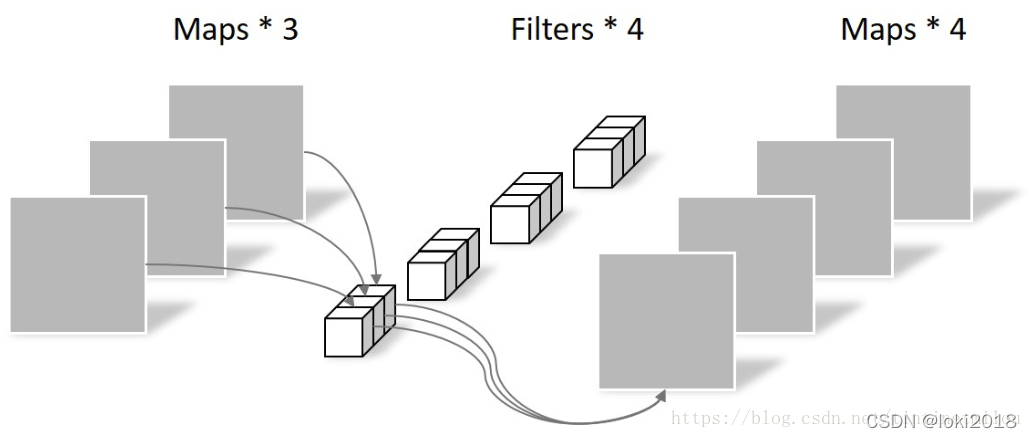
常规卷积是利用若干个多通道卷积核对输入的多通道图像进行处理,输出的是既提取了通道特征又提取了空间特征的feature map。

而深度可分离卷积将提取通道特征(PointWise Convolution)和空间特征(DepthWise Convolution)分为了两步去做:
首先卷积核从三维变为了二维的,每个卷积核只负责输入图像的一个通道,用于提取空间特征,这一步操作中不涉及通道和通道之间的信息交互。接着通过一维卷积来完成通道之间特征提取的工作,即一个常规的卷积操作,只不过卷积核是1*1的。

这样做的好处是降低了常规卷积时的参数量,假设输入通道为
M
M
M, 输出通道为
N
N
N,卷积核大小为
k
×
k
,
那
么
k \times k, 那么
k×k,那么常规卷积的参数是:
N
×
M
×
k
×
k
N \times M \times k \times k
N×M×k×k。而通过深度可分离卷积之后,参数量为
M
×
k
×
k
+
N
×
M
×
1
×
1
M \times k \times k + N \times M \times 1 \times 1
M×k×k+N×M×1×1。
代码如下:
class SeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1):
super(SeparableConv2d, self).__init__()
self.conv1 = nn.Conv2d(
in_channels, in_channels, kernel_size, stride, padding, dilation, groups=in_channels, bias=False)
self.pointwise = nn.Conv2d(in_channels, out_channels, 1, 1, 0, 1, 1, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.pointwise(x)
return x
[2] Chollet F. Xception: Deep learning with depthwise separable convolutions[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1251-1258.
作者灵感来源于VGG的模块化堆叠的结构,提出了一种基于分组卷积和残差连接的模块化卷积块从而降低了参数的数量。简单来说,理解了分组卷积的思想就能理解ResNeXt。
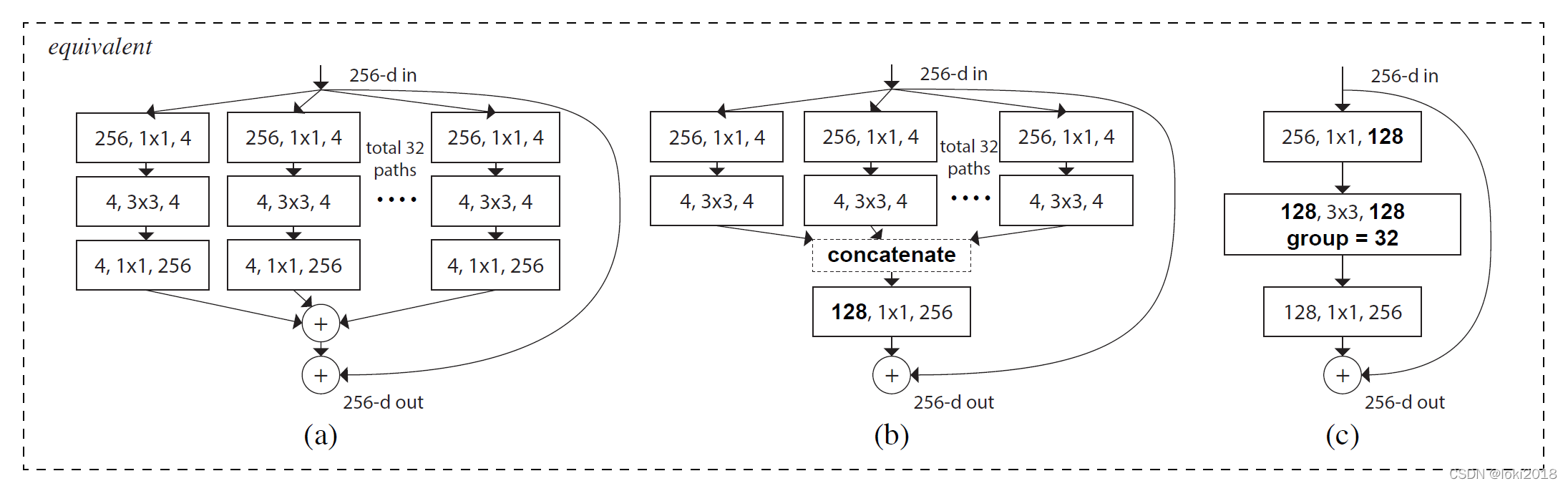
[3] Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1492-1500.
由于使用
1
×
1
1 \times 1
1×1卷积核进行操作时的复杂度较高,因为需要和每个像素点做互相关运算,作者关注到ResNeXt的设计中,
1
×
1
1 \times 1
1×1卷积操作的那一层需要消耗大量的计算资源,因此提出将这一层也设计为分组卷积的形式。然而,分组卷积只会在组内进行卷积,因此组和组之间不存在信息的交互,为了使得信息在组之间流动,作者提出将每次分组卷积后的结果进行组内分组,再互相交换各自的组内的子组。
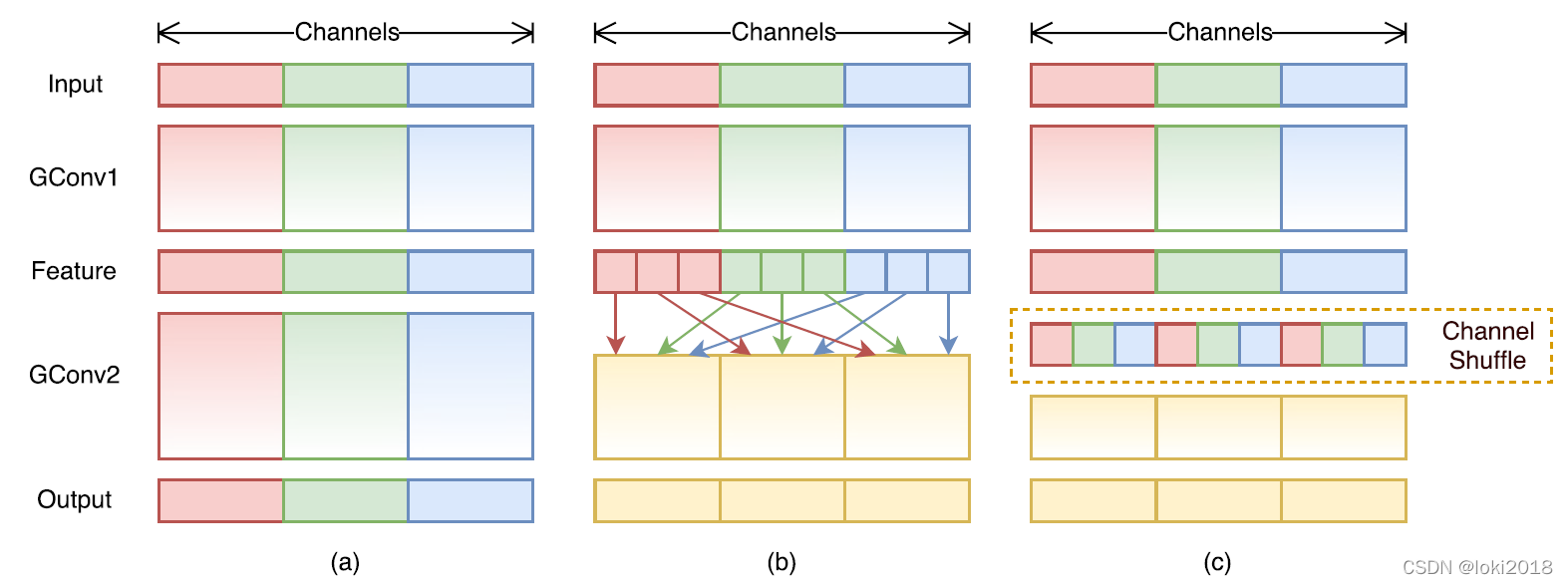
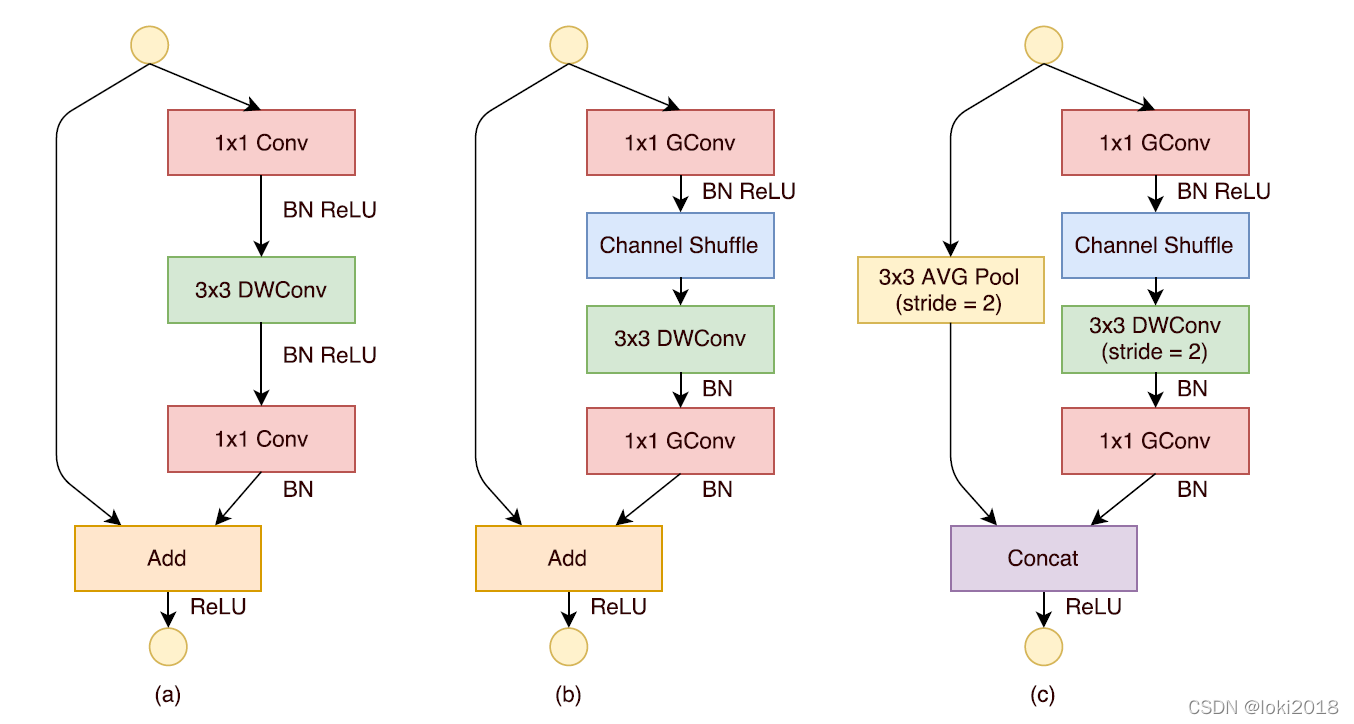
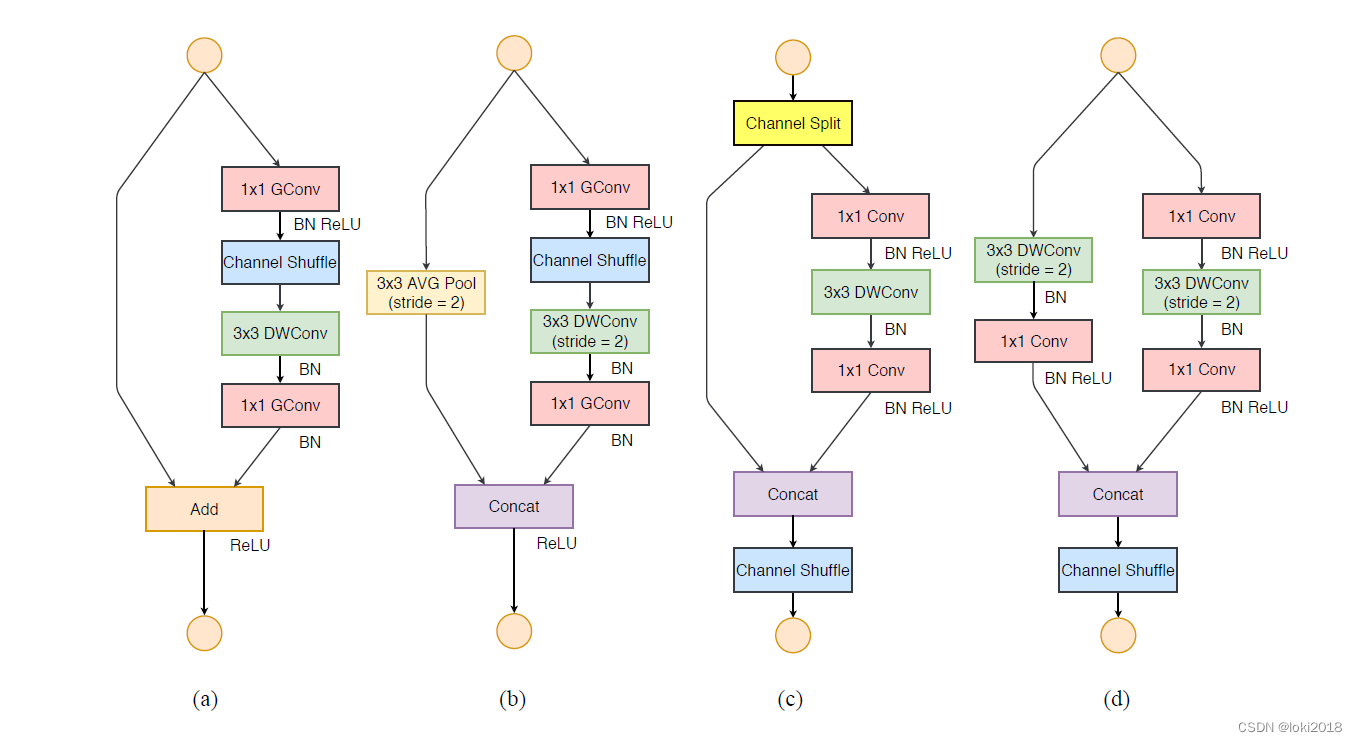
上图c就是一个shufflenet块,图a是一个简单的残差连接块,区别在于,shufflenet将残差连接改为了一个平均池化的操作与卷积操作之后做cancat,并且将
1
×
1
1 \times 1
1×1卷积改为了分组卷积,并且在分组之后进行了channel shuffle操作。
代码如下:
首先定义1x1,3x3,depthwise_3x3卷积操作:
import torch
import torch.nn as nn
import torchvision
from torch.utils import data
import matplotlib.pyplot as plt
import copy
def conv1x1(in_channels, out_channels, stride=1, groups=1, bias=False):
# 1x1卷积操作
return nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=1, stride=stride, groups=groups, bias=bias)
def conv3x3(in_channels, out_channels, stride=1, padding=1, dilation=1, groups=1, bias=False):
# 3x3卷积操作
# 默认不是下采样
return nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=3, stride=stride, padding=padding, dilation=dilation,
groups=groups,bias=bias)
def depthwise_con3x3(channels, stride):
# 空间特征抽取
# 输入通道和输出通道相等,且分组数等于通道数
return nn.Conv2d(in_channels=channels, out_channels=channels,
kernel_size=3, stride=stride, padding=1, groups=channels,bias=False)
接着是核心的channel shuffle操作:
通过矩阵变化即可实现,此操作并不会改变通道数和图像的尺寸

def channel_shuffle(x, groups):
# x[batch_size, channels, H, W]
batch, channels, height, width = x.size()
channels_per_group = channels // groups # 每组通道数
x = x.view(batch, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(batch, channels, height, width)
return x
class ChannelShuffle(nn.Module):
def __init__(self, channels, groups):
super(ChannelShuffle, self).__init__()
if channels % groups != 0:
raise ValueError("通道数必须可以整除组数")
self.groups = groups
def forward(self, x):
return channel_shuffle(x, self.groups)
然后定义shufflenet块,分为下采样和不下采样:
class ShuffleUnit(nn.Module):
def __init__(self, in_channels, out_channels, groups, downsample, ignore_group):
# 如果做下采样,那么通道数翻倍,高宽减半
# 如果不做下采样,那么输入输出通道数相等,高宽不变
super(ShuffleUnit, self).__init__()
self.downsample = downsample
mid_channels = out_channels // 4
if downsample:
out_channels -= in_channels
else:
assert in_channels == out_channels, "不做下采样时应该输入输出通道相等"
self.compress_conv1 = conv1x1(
in_channels=in_channels,
out_channels=mid_channels,
groups=(1 if ignore_group else groups)
)
self.compress_bn1 = nn.BatchNorm2d(num_features=mid_channels)
self.c_shuffle = ChannelShuffle(channels=mid_channels, groups=groups)
self.dw_conv2 = depthwise_con3x3(channels=mid_channels, stride=(2 if downsample else 1))
self.dw_bn2 = nn.BatchNorm2d(num_features=mid_channels)
self.expand_conv3 = conv1x1(
in_channels=mid_channels,
out_channels=out_channels,
groups=groups
)
self.expand_bn3 = nn.BatchNorm2d(num_features=out_channels)
if downsample:
self.avgpool = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
self.activ = nn.ReLU(inplace=True)
def forward(self, x):
identity = x
x = self.compress_conv1(x) # x[batch_size, mid_channels, H, W]
x = self.compress_bn1(x)
x = self.activ(x)
x = self.c_shuffle(x)
x = self.dw_conv2(x) # x[batch_size, mid_channels, H, w]
x = self.dw_bn2(x)
x = self.expand_conv3(x) # x[batch_size, out_channels, H, W]
x = self.expand_bn3(x)
if self.downsample:
identity = self.avgpool(identity)
x = torch.cat((x, identity), dim=1) # 通道维上拼接
else:
x = x + identity
x = self.activ(x)
return x
在进入shufflenet之前常规地做一个下采样:
class ShuffleInitBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(ShuffleInitBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1) # 下采样
self.bn = nn.BatchNorm2d(out_channels)
self.activ = nn.ReLU(inplace=True)
self.pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 下采样
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.activ(x)
x = self.pool(x)
return x
建立shufflenet完整的流程:
class ShuffleNet(nn.Module):
def __init__(self, channels, init_block_channels, groups, in_channels=1, in_size=(224, 224), num_classes=10):
super(ShuffleNet, self).__init__()
self.in_size = in_size
self.num_classes = num_classes
self.features = nn.Sequential()
self.features.add_module("init_block", ShuffleInitBlock(in_channels, init_block_channels))
in_channels = init_block_channels
for i, channels_per_stage in enumerate(channels):
stage = nn.Sequential()
for j, out_channels in enumerate(channels_per_stage):
downsample = (j == 0)
ignore_group = (i==0) and (j==0)
stage.add_module("unit{}".format(j + 1), ShuffleUnit(
in_channels=in_channels,
out_channels=out_channels,
groups=groups,
downsample=downsample,
ignore_group=ignore_group))
in_channels = out_channels
self.features.add_module("stage{}".format(i + 1), stage)
self.features.add_module("final_pool", nn.AvgPool2d(
kernel_size=7,
stride=1))
self.output = nn.Linear(
in_features=in_channels,
out_features=num_classes)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.output(x)
return x
def get_shufflenet(groups, width_scale):
init_block_channels = 24
layers = [2, 4, 2]
if groups == 1:
channels_per_layers = [144, 288, 576]
elif groups == 2:
channels_per_layers = [200, 400, 800]
elif groups == 3:
channels_per_layers = [240, 480, 960]
elif groups == 4:
channels_per_layers = [272, 544, 1088]
elif groups == 8:
channels_per_layers = [384, 768, 1536]
else:
raise ValueError("The {} of groups is not supported".format(groups))
channels = [[ci] * li for (ci, li) in zip(channels_per_layers, layers)]
if width_scale != 1.0:
channels = [[int(cij * width_scale) for cij in ci] for ci in channels]
init_block_channels = int(init_block_channels * width_scale)
net = ShuffleNet(
channels=channels,
init_block_channels=init_block_channels,
groups=groups)
return net
训练过程:
net = get_shufflenet(groups=2, width_scale=1.0)
NUM_EPOCHS = 10
BATCH_SIZE = 64
NUM_CLASSES = 10
LR = 0.001
def load_data_fashion_mnist(batch_size, resize=None):
trans = [torchvision.transforms.ToTensor()]
if resize:
trans.insert(0, torchvision.transforms.Resize(resize))
trans = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="./FashionMinist", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="./FashionMinist", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,),
data.DataLoader(mnist_test, batch_size, shuffle=False,))
train_loader, test_loader = load_data_fashion_mnist(BATCH_SIZE, 224)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def validate(net, data):
total = 0
correct = 0
net.eval()
with torch.no_grad():
for i, (images, labels) in enumerate(data):
images = images.to(device)
x = net(images)
value, pred = torch.max(x,1)
pred = pred.data.cpu()
total += x.size(0)
correct += torch.sum(pred == labels)
return correct*100./total
def train(net):
lossfunc = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=LR)
max_accuracy = 0
accuracies = []
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net = net.to(device)
net.train()
for epoch in range(NUM_EPOCHS):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
out = net(images)
loss = lossfunc(out, labels)
loss_item = loss.item()
loss.backward()
optimizer.step()
accuracy = float(validate(net, test_loader))
accuracies.append(accuracy)
print("Epoch %d accuracy: %f loss: %f" % (epoch, accuracy, loss_item))
if accuracy > max_accuracy:
best_model = copy.deepcopy(net)
max_accuracy = accuracy
print("Saving Best Model with Accuracy: ", accuracy)
plt.plot(accuracies)
return best_model
shufflenet = train(net)
Ma N, Zhang X, Zheng H T, et al. Shufflenet v2: Practical guidelines for efficient cnn architecture design[C]. Proceedings of the European conference on computer vision (ECCV). 2018: 116-131.
ShuffleNetV2 这篇文章对shufflenet进行了进一步的改进,并且提出了四个设计轻量化网络的原则:
class ShuffleUnitV2(nn.Module):
def __init__(self, in_channels, out_channels, downsample, use_residual):
super(ShuffleUnitV2, self).__init__()
self.downsample = downsample
self.use_residual = use_residual
mid_channels = out_channels // 2
self.compress_conv1 = conv1x1(
in_channels=(in_channels if downsample else mid_channels),
out_channels=mid_channels
)
self.compress_bn1 = nn.BatchNorm2d(num_features=mid_channels)
self.dw_conv2 = depthwise_con3x3(
channels=mid_channels,
stride=(2 if downsample else 1)
)
self.dw_bn2 = nn.BatchNorm2d(mid_channels)
self.expand_conv3 = conv1x1(
in_channels=mid_channels,
out_channels=mid_channels
)
self.expand_bn3 = nn.BatchNorm2d(num_features=mid_channels)
if downsample:
self.dw_conv4 = depthwise_con3x3(
channels=in_channels,
stride=2
)
self.dw_bn4 = nn.BatchNorm2d(num_features=in_channels)
self.expand_conv5 = conv1x1(
in_channels=in_channels,
out_channels=mid_channels
)
self.expand_bn5 = nn.BatchNorm2d(num_features=mid_channels)
self.activ = nn.ReLU(inplace=True)
self.c_shuffle = ChannelShuffle(
channels=out_channels,
groups=2
)
def forward(self, x):
if self.downsample:
y1 = self.dw_conv4(x)
y1 = self.dw_bn4(y1)
y1 = self.expand_conv5(y1)
y1 = self.expand_bn5(y1)
y1 = self.activ(y1)
x2 = x
else:
y1, x2 = torch.chunk(x, chunks=2, dim=1)
y2 = self.compress_conv1(x2)
y2 = self.compress_bn1(y2)
y2 = self.activ(y2)
y2 = self.dw_conv2(y2)
y2 = self.dw_bn2(y2)
y2 = self.expand_conv3(y2)
y2 = self.expand_bn3(y2)
y2 = self.activ(y2)
if self.use_residual and not self.downsample:
y2 = y2 + x2
x = torch.cat((y1, y2), dim=1)
x = self.c_shuffle(x)
return x
class ShuffleNetV2(nn.Module):
def __init__(self, channels, init_block_channels, final_block_channels,
use_residual=False, in_channels=1, in_size=(224, 224), num_classes=10):
super(ShuffleNetV2, self).__init__()
self.in_size = in_size
self.num_classes = num_classes
self.features = nn.Sequential()
self.features.add_module("init_block", ShuffleInitBlock(
in_channels=in_channels,
out_channels=init_block_channels))
in_channels = init_block_channels
for i, channels_per_stage in enumerate(channels):
stage = nn.Sequential()
for j, out_channels in enumerate(channels_per_stage):
downsample = (j==0)
stage.add_module("unit{}".format(j+1), ShuffleUnitV2(
in_channels=in_channels,
out_channels=out_channels,
downsample=downsample,
use_residual=use_residual
))
in_channels=out_channels
self.features.add_module("stage{}".format(i + 1), stage)
self.features.add_module("final_block", conv1x1(
in_channels=in_channels,
out_channels=final_block_channels
))
in_channels = final_block_channels
self.features.add_module("final_bn", nn.BatchNorm2d(num_features=in_channels))
self.features.add_module("final_pool", nn.AdaptiveAvgPool2d(output_size=(1, 1)))
self.features.add_module("flatten", nn.Flatten())
self.output = nn.Linear(
in_features=in_channels,
out_features=num_classes
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.output(x)
return x
def get_shufflenetv2(width_scale):
init_block_channels = 24
final_block_channels = 1024
layers = [4, 8, 4]
channels_per_layers = [116, 232, 464]
channels = [[ci] * li for (ci, li) in zip(channels_per_layers, layers)]
if width_scale != 1.0:
channels = [[int(cij * width_scale) for cij in ci] for ci in channels]
if width_scale > 1.5:
final_block_channels = int(final_block_channels * width_scale)
net = ShuffleNetV2(
channels=channels,
init_block_channels=init_block_channels,
final_block_channels=final_block_channels)
return net
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
我怀念ipython的一件事是它有一个?为特定功能挖掘文档的运算符。我知道ruby有一个类似的命令行工具,但是我在irb中调用它非常不方便。ruby/irb有类似的东西吗? 最佳答案 Pry是IPython的Ruby版本,它支持?命令来查找有关方法的文档,但语法略有不同:pry(main)>?File.dirnameFrom:file.cinRubyCore(CMethod):Numberoflines:6visibility:publicsignature:dirname()Returnsallcomponentsofthef
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
我经常使用嵌套数据结构,很多时候我必须从控制台手动分析它们。问题是它们全部打印在一行中。是否有一种简单的方法可以根据{,[,],}和逗号重新构造数据结构的显示,使其看起来像Ruby的pretty_print输出? 最佳答案 :%s/\([{,]\)/\1\r/gggVG=:setft=ruby呜呜呜 关于ruby-如何将Vim中的"expand"文本转换成一种易于阅读的方式?,我们在StackOverflow上找到一个类似的问题: https://stacko
TCP是面向连接的协议,连接的建立和释放是每一次面向连接的通信中必不可少的过程。TCP连接的管理就是使连接的建立和释放都能正常地进行。三次握手TCP连接的建立—三次握手建立TCP连接①若主机A中运行了一个客户进程,当它需要主机B的服务时,就发起TCP连接请求,并在所发送的分段中用SYN=1表示连接请求,并产生一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x。主机B收到A的连接请求报文,就完成了第一次握手。客户端发送SYN=1表示连接请求客户端发送一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x②主机B如果同意建立连接,则向主机A发送确认报
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
我正在使用Watir进行自动化,它会创建一封我需要检查的电子邮件。有人指出电子邮件gem是执行此操作的最简单方法。我添加了以下代码,并且能够从我的收件箱中收到第一封电子邮件。require'mail'require'openssl'Mail.defaultsdoretriever_method:pop3,:address=>"email.someemail.com",:port=>995,:user_name=>'domain/username',:password=>'pwd',:enable_ssl=>trueendputsMail.first我是这个论坛的新手,有以下问题:如何获