原创文章,转载请注明出处:https://blog.csdn.net/weixin_37864449/article/details/126772830?spm=1001.2014.3001.5502
如上动态图所示,脉冲网络由脉冲神经元连接而成,脉冲神经元输入为脉冲,输出也是脉冲,脉冲神经元内部有电动势v,v在没有接收到任何输入时会随着时间指数衰减到某个稳定的电动势(平衡电压),而某一时刻接收到输入脉冲时电动势会增加某个值,当电动势增加的速度快过衰减的速度时(如频繁有脉冲输入),神经元内部的电动势会越来越大,直到达到某个发放阈值后该脉冲神经元会发放脉冲,此后脉冲神经元电动势迅速置为静息电动势,电动势变化过程如下图二所示。电动势变化的规律又称为神经电位动力学。
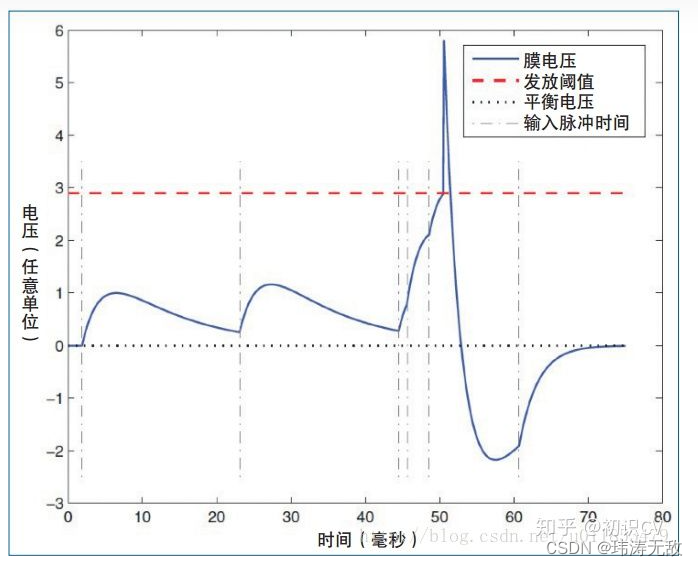
图二 神经元膜电压变化
脉冲神经元电位动力学数学模型最简单常用的是漏电积分-放电(leaky integrate-and-fire ( LIF ))模型,这个模型工作过程与生物神经元充电、漏电、放电过程类似,更精确的描述生物神经动力学模型是Hodgkin-huxley模型,但该模型微分方程复杂难以直观理解,虽然Hodgkin-huxley模型更精确描述了生物神经元电位动力学变化过程,但有观点认为该模型对数据拟合能力没有LIF模型好(https://www.youtube.com/watch?v=GTXTQ_sOxak 25:24),总而言之,LIF是基于生物神经元动力学特性简化后的数学模型,简单好用,下面详细讨论LIF模型。
我们知道,每个脉冲神经元内部有电压v,当没有接收到任何脉冲输入时,电压v会随着时间指数稳定到平衡电压,这个过程用LIF模型描述为:
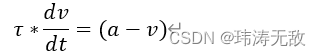
求解这个微分方程,可以得到:
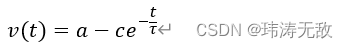
这里是任意常数,
 控制指数下降速率, 越小
控制指数下降速率, 越小 越快指数变化到
,分析这个方程可以看到,初始时t=0时刻v=
,其中
取恰当的值就可以使
等于脉冲神经元初始时刻电压,当t=∞时v=
,该方程控制了电压v随时间指数稳定到平衡电压
。
上面是连续电压的变化方程,然而计算机只能模拟离散过程,取离散时间间隔为
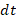 时,则:
时,则:
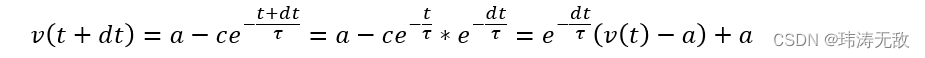
故微分方程的离散形式为:
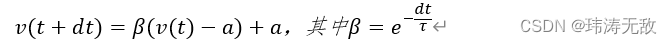
另外,当某个时刻神经元接收到一个脉冲输入时,则要累积该脉冲到电压中,最简单的方式是让当前的电压加上某个值,通常这个值跟连接该输入脉冲的突触权重有关,电压更新过程为:
神经元内部有一个发放阈值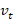 ,当神经元电压v>时,神经元会发放一个脉冲,此后神经元电压会立刻置为静息电位
,当神经元电压v>时,神经元会发放一个脉冲,此后神经元电压会立刻置为静息电位:
为更好的理解LIF模型控制的神经元膜电压变化,下面附上由for循环实现的python代码:
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(5, 4))
ax = plt.subplot(111)
# Function that runs the simulation
# tau: time constant (in ms)
# t0, t1, t2: time of three input spikes
# w: input synapse weight
# threshold: threshold value to produce a spike
# reset: reset value after a spike
def LIF(tau=10, t0=20, t1=30, t2=35, w=0.8, threshold=1.0, reset=0.0):
# Spike times, keep sorted because it's more efficient to pop the last value off the list
times = [t0, t1, t2]
times.sort(reverse=True)
# set some default parameters
duration = 100 # total time in ms
dt = 0.1 # timestep in ms
alpha = np.exp(-dt / tau) # this is the factor by which V decays each time step
V_rec = [] # list to record membrane potentials
V = 0.0 # initial membrane potential
T = np.arange(np.round(duration / dt)) * dt # array of times
spikes = [] # list to store spike times
# run the simulation
# plot everything (T is repeated because we record V twice per loop)
ax.clear()
for t in times:
ax.axvline(t, ls=':', c='b')
for t in T:
V_rec.append(V) # record
V *= alpha # integrate equations
if times and t > times[-1]: # if there has been an input spike
V +=w
times.pop() # remove that spike from list
V_rec.append(V) # record V before the reset so we can see the spike
if V > threshold: # if there should be an output spike
V = reset
spikes.append(t)
ax.plot(np.repeat(T, 2), V_rec, '-k', lw=2)
for t in spikes:
ax.axvline(t, ls='--', c='r')
ax.axhline(threshold, ls='--', c='g')
ax.set_xlim(0, duration)
ax.set_ylim(-1, 2)
ax.set_xlabel('Time (ms)')
ax.set_ylabel('Voltage')
plt.tight_layout()
plt.show()
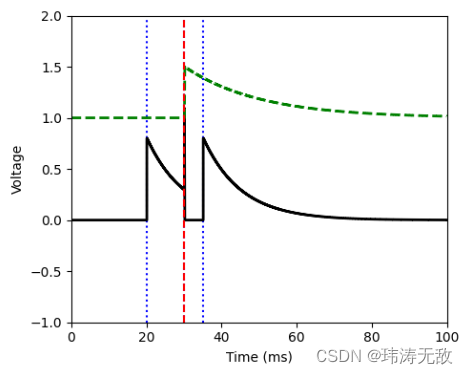
LIF()运行结果为:
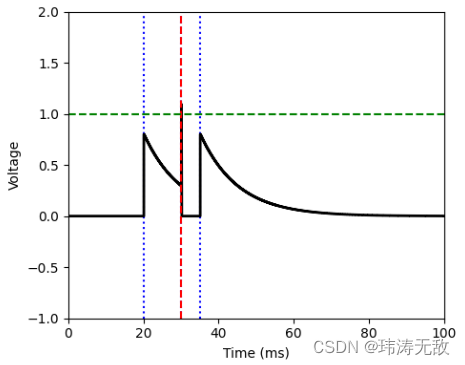
绿色虚线表示发放阈值,黑色为神经元电压,蓝色虚线表示神经元接收到输入脉冲的时刻,红色虚线表示神经发放了一个脉冲。代码里设置神经元平衡电压为0,静息电位为0,发放阈值为1。
更复杂一些,我们可以让发放阈值也能发生变化,下面代码演示了当神经元发放脉冲时,发放阈值会增加某个值,且发放阈值动力学模型也是LIF模型。
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(5, 4))
ax = plt.subplot(111)
# Function that runs the simulation
# tau: time constant (in ms)
# t0, t1, t2: time of three input spikes
# w: input synapse weight
# threshold: threshold value to produce a spike
# reset: reset value after a spike
def LIF2(tau=10, taut=20, t0=20, t1=30, t2=35, w=0.8, threshold=1.0, dthreshold=0.5, reset=0.0):
# Spike times, keep sorted because it's more efficient to pop the last value off the list
times = [t0, t1, t2]
times.sort(reverse=True)
# set some default parameters
duration = 100 # total time in ms
dt = 0.1 # timestep in ms
alpha = np.exp(-dt/tau) # this is the factor by which V decays each time step
beta = np.exp(-dt/taut) # this is the factor by which Vt decays each time step
V_rec = [] # list to record membrane potentials
Vt_rec = [] # list to record threshold values
V = 0.0 # initial membrane potential
Vt = threshold
T = np.arange(np.round(duration/dt))*dt # array of times
spikes = [] # list to store spike times
# clear the axis and plot the spike times
ax.clear()
for t in times:
ax.axvline(t, ls=':', c='b')
# run the simulation
for t in T:
V_rec.append(V) # record
Vt_rec.append(Vt)
V *= alpha # integrate equations
Vt = (Vt-threshold)*beta+threshold
if times and t>times[-1]: # if there has been an input spike
V += w
times.pop() # remove that spike from list
V_rec.append(V) # record V before the reset so we can see the spike
Vt_rec.append(Vt)
if V>Vt: # if there should be an output spike
V = reset
Vt += dthreshold
spikes.append(t)
# plot everything (T is repeated because we record V twice per loop)
ax.plot(np.repeat(T, 2), V_rec, '-k', lw=2)
ax.plot(np.repeat(T, 2), Vt_rec, '--g', lw=2)
for t in spikes:
ax.axvline(t, ls='--', c='r')
ax.set_xlim(0, duration)
ax.set_ylim(-1, 2)
ax.set_xlabel('Time (ms)')
ax.set_ylabel('Voltage')
plt.tight_layout()
plt.show()
#display(fig)
LIF2()运行结果为:
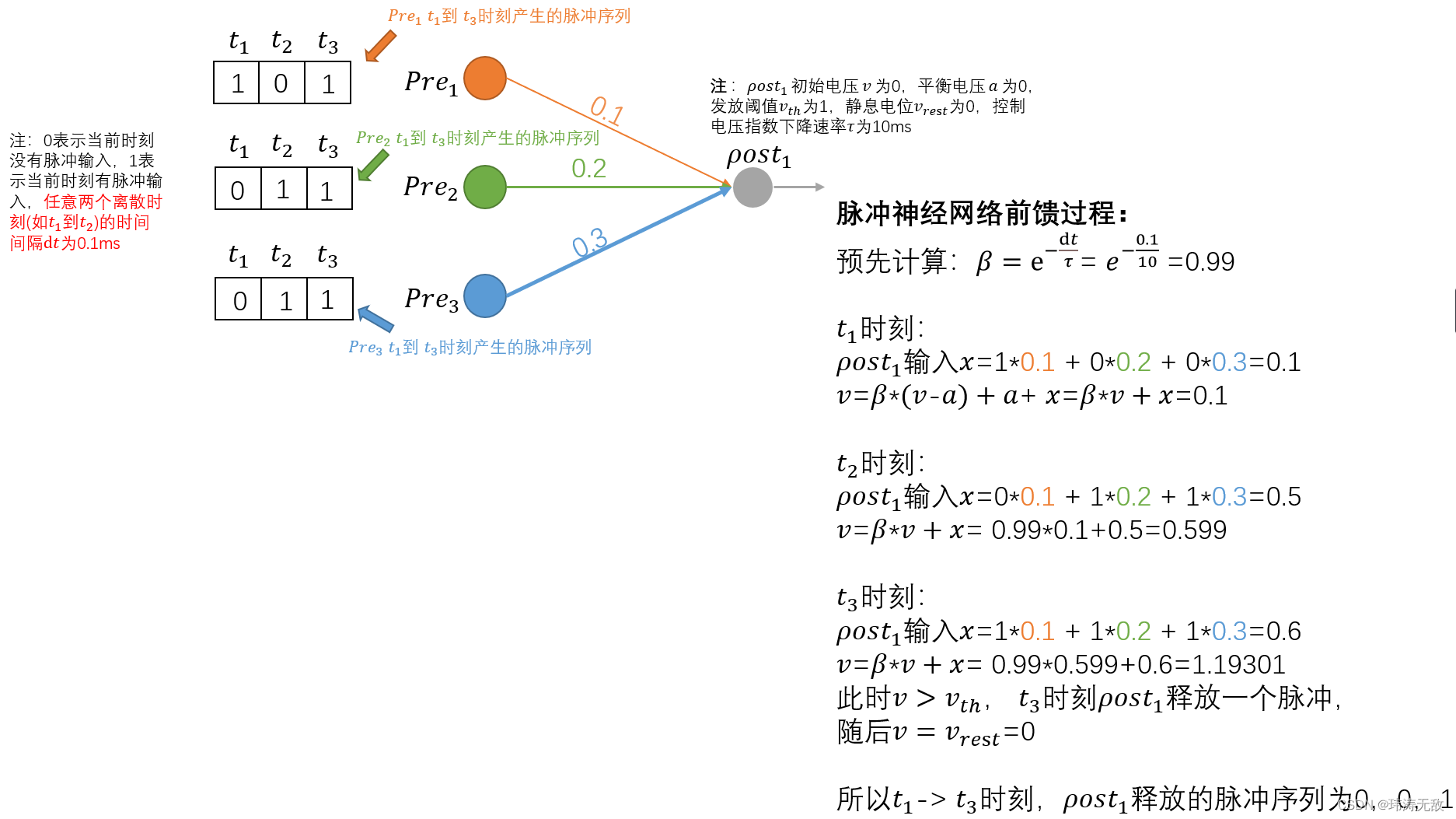
有了上面的知识后,我们来简单模拟一下脉冲神经网络前向传播的过程:
前面我们知道了脉冲神经元内部的电动力学特性及其方程,接下来我们来学习如何更新脉冲神经网络的连接权重,区别于传统的梯度下降方法,脉冲神经网络通常使用的是更具生物学特性的STDP(spike timing dependent plasticity)学习策略。在解释STDP之前,我们先来看看一些概念:
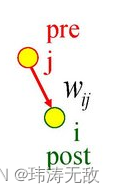
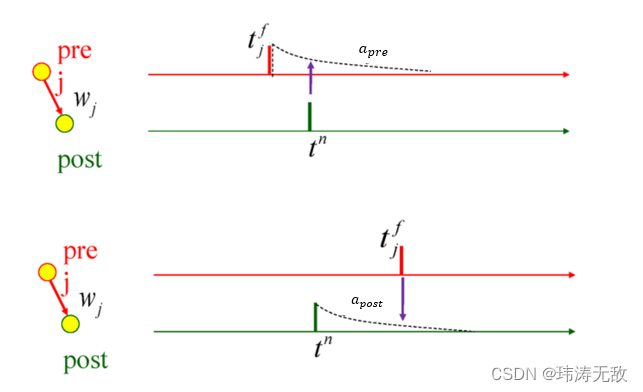
如上图所示,脉冲神经元连接有前突触和后突触之分,索引j 神经元称为前突触,若神经元j产生了一个脉冲,则称神经元j产生了一个突触前脉冲,索引i 神经元称为后突触,同理神经元i产生的脉冲称为突触后脉冲。j与i的连接权重为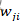 ,神经元i接收到来自神经元j的一个脉冲后,神经元i要累积该脉冲到电压中,即神经元i当前的电压加上某个值,该值的大小与有关,那么该如何更新
,神经元i接收到来自神经元j的一个脉冲后,神经元i要累积该脉冲到电压中,即神经元i当前的电压加上某个值,该值的大小与有关,那么该如何更新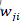 呢?
呢?
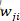 的更新在脉冲神经网络中最常用的方法是STDP方法,STDP更新突触权重的方式是:若突触前脉冲比突触后脉冲到达时间早,会导致Long-Term Potentiation(LTP)效应,即
的更新在脉冲神经网络中最常用的方法是STDP方法,STDP更新突触权重的方式是:若突触前脉冲比突触后脉冲到达时间早,会导致Long-Term Potentiation(LTP)效应,即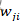 权重会增加。反之,若突触前脉冲比突触后脉冲到达时间晚,会引起LTD,即
权重会增加。反之,若突触前脉冲比突触后脉冲到达时间晚,会引起LTD,即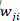 权重会减小。在神经科学实验中,人们多次发现和验证了STDP是大脑突触权重更新的方式,突触权重更新意味着学习和信息的存储,也意味着大脑发育过程中神经元回路的发展和完善。
权重会减小。在神经科学实验中,人们多次发现和验证了STDP是大脑突触权重更新的方式,突触权重更新意味着学习和信息的存储,也意味着大脑发育过程中神经元回路的发展和完善。
根据上面的定义,STDP更新权重的公式可写成:
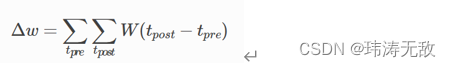
也就是说,突触权重 的变化是某个函数 W的所有突触前尖峰时间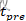 和突触后尖峰时间
和突触后尖峰时间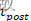 差的总和。一个常用的函数 W 是:
差的总和。一个常用的函数 W 是:

举个例子:
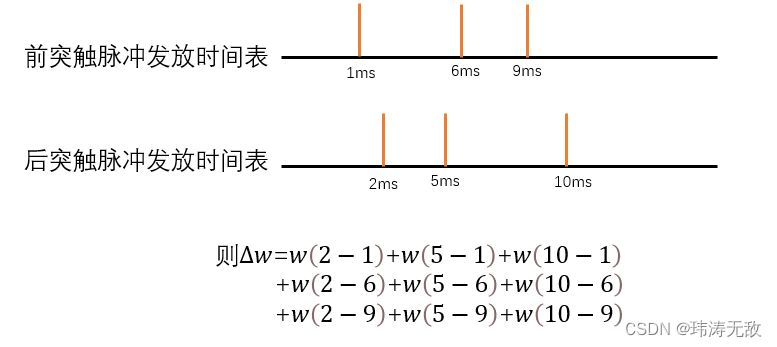
然而使用该定义需要事先知道前突触脉冲和后突触脉冲一段时间内各自发放脉冲的时间表,因此直接使用这个方程更新权重将非常低效,因为我们必须对每个神经元先记录好它的脉冲发放时间表,然后对所有尖峰对时间差求和。这在生物学上也是不现实的,因为神经元无法记住之前的所有尖峰时间。事实证明,有一种更有效、生理上更合理的方法可以达到同样的效果,该方法可以在突触前脉冲发放或突触后脉冲发放就立刻更新权重。
我们先定义两个新变量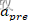 和
和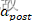 ,它们分别为突触前脉冲发放后的活动“痕迹”变量和突触后脉冲发放后的活动“痕迹”变量(如下图所示):
,它们分别为突触前脉冲发放后的活动“痕迹”变量和突触后脉冲发放后的活动“痕迹”变量(如下图所示):
痕迹变化由LIF模型控制:
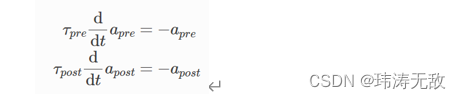
当发放突触前脉冲时,会更新突触前活动痕迹变量并根据规则修改权重w:

同理当突触后脉冲发放时:

这个更新公式可以理解为:当突触前脉冲到达了,突触后脉冲痕迹还未衰减到0,说明突触后脉冲是比突触前脉冲早到达的,所以权重应该削弱,削弱量为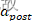 , 需要说明的是通常
, 需要说明的是通常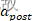 为负数(为负数的原因是在更新痕迹时,初始=0,突触后脉冲发放时,会加
为负数(为负数的原因是在更新痕迹时,初始=0,突触后脉冲发放时,会加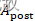 ,通常是某个较小的负数常数);同理当突触后脉冲发生时,突触前脉冲痕迹还未衰减到0时,说明突触前脉冲是比突触后脉冲早到达的,所以权重应该增强,增强量为
,通常是某个较小的负数常数);同理当突触后脉冲发生时,突触前脉冲痕迹还未衰减到0时,说明突触前脉冲是比突触后脉冲早到达的,所以权重应该增强,增强量为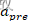 ,这里通常
,这里通常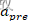 为正数。
为正数。
最后,我们看一下泊松脉冲编码。由于脉冲神经网络接收的是脉冲信号,所以需要对初始输入数据进行脉冲编码,其中输入数据脉冲编码一个比较常用的方式是泊松脉冲编码,更详细的泊松脉冲编码讲解可参考:https://www.youtube.com/watch?v=4r_gc4vf8eE 。
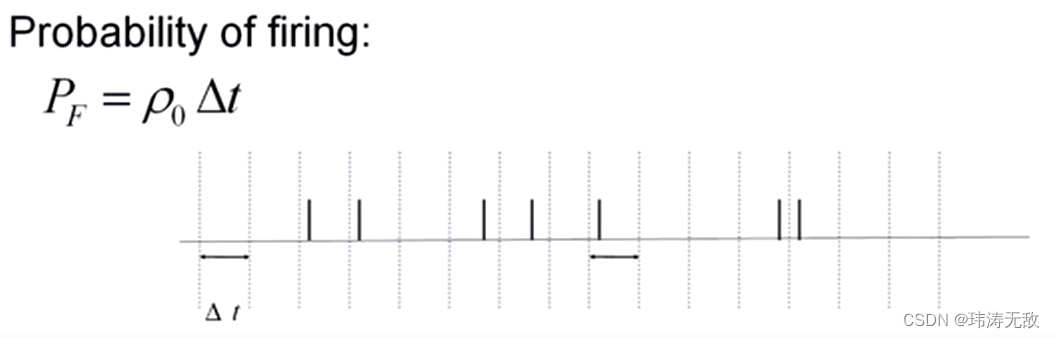
泊松脉冲编码首先需要设置脉冲速率ρ0 ,ρ0 可以是常数,也可以是时间函数。编码过程可描述为:取时间间隔为Δt ,则每个时间间隔脉冲发放的概率为pF=ρ0*Δt ,电脑在每个时间间隔生成一个(0,1)范围内均匀分布的随机数,随机数小于ρ0*Δt 则在该时间间隔内产生一个脉冲。
泊松脉冲编码可以这样应用:把输入时间序列值看成脉冲速率ρ0 ,如t1时刻输入为a, t2时刻输入为b,t3时刻输入为c,若t1时刻0-1随机数大于或等于a*Δt ,则t1时刻神经元不发放脉冲,t2时刻0-1随机数小于b*Δt ,则t2时刻神经元发放脉冲,t3时刻0-1随机数大于或等于c*Δt ,则t3时刻神经元不发放脉冲,所以a,b,c编码后的脉冲序列为无脉冲,脉冲,无脉冲。
python安装方式:pip install brian2
教程:Introduction to Brian part 1: Neurons — Brian 2 2.5.1 documentation
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我正在学习Ruby,遇到了inject。我正处于理解它的风口浪尖,但当我是那种需要真实世界的例子来学习一些东西的人时。我遇到的最常见的例子是人们使用inject来添加一个(1..10)范围的总和,我不太关心这个。这是一个任意的例子。在实际程序中我会用它做什么?我正在学习,所以我可以继续使用Rails,但我不必有一个以Web为中心的示例。我只需要一些我可以全神贯注的目标。谢谢大家。 最佳答案 inject有时可以通过它的“其他”名称reduce更好地理解。它是一个对Enumerable进行操作(迭代一次)并返回单个值的函数。它有许多有
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG