首先看一下Elasticsearch的Collector,主要以下几个
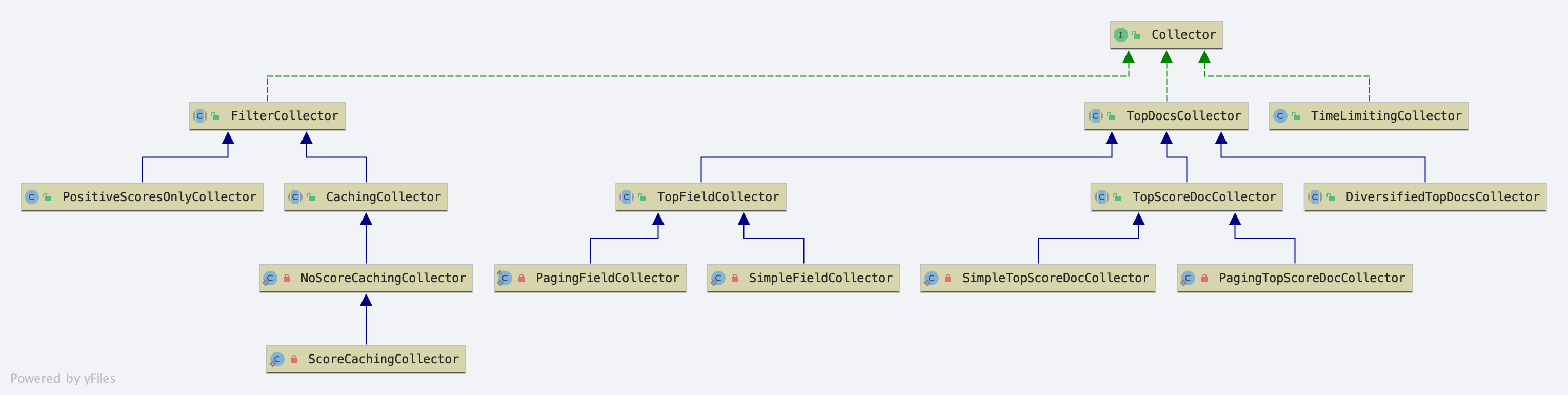
这里主要介绍一下TopDocsCollector,TopDocsCollector类在收集完文档后,会返回一个TopDocs对象。TopDocs对象是收集后的文档信息按照某种规则有序的存放在TopDocs对象中,该对象是搜索结果的返回值。
根据不同排序(sorting)规则,TopDocsCollector派生出类图中的3个子类:
TopFieldCollector,有如下两个内部子类:
TopScoreDocsCollector,有如下两个内部子类:
DiversifiedTopDocsCollector
TopScoreDocCollector类的排序规则是先执行打分,分数相同的文档按文档号排序。
TopFieldCollector则是先按照指定的sort排序,值相同的则再按照文档号排序。
两个Collector的触发逻辑非常简单,就是判断searchContext.sort()是否为null。如果不为null,则走TopFieldCollector。指定_doc排序也属于不为null情况。
对于TopScoreDocsCollector的两个子类SimpleTopScoreDocCollector和PagingTopScoreDocCollector功能上的区别在于PagingTopScoreDocCollector是针对翻页请求的。代码上只是增加了一个对after的判断。
if (score > after.score || (score == after.score && doc <= afterDoc)) {
// hit was collected on a previous page
return;
}
对于使用TopScoreDocsCollector无论是否为翻页请求,每次请求都会扫描全部的命中文档并计算分值。
使用SimpleTopScoreDocCollector还是PagingTopScoreDocCollector是根据after是否为null决定的。
public static TopScoreDocCollector create(int numHits, ScoreDoc after) {
if (numHits <= 0) {
throw new IllegalArgumentException("numHits must be > 0; please use TotalHitCountCollector if you just need the total hit count");
}
if (after == null) {
return new SimpleTopScoreDocCollector(numHits);
} else {
return new PagingTopScoreDocCollector(numHits, after);
}
}
对于scroll请求,after = scrollContext.lastEmittedDoc;即上次翻页最大的ScoreDoc
TopFieldCollectortor一样有两个子类,SimpleFieldCollector和PagingFieldCollector,区别也是一个针对分页一个不分页的情况。
if (topCmp > 0 || (topCmp == 0 && doc <= afterDoc)) {
// Already collected on a previous page
return;
}
是否翻页判断逻辑跟TopScoreDocsCollector也一样
public static TopFieldCollector create(Sort sort, int numHits, FieldDoc after,
boolean fillFields, boolean trackDocScores, boolean trackMaxScore)
throws IOException {
if (sort.fields.length == 0) {
throw new IllegalArgumentException("Sort must contain at least one field");
}
if (numHits <= 0) {
throw new IllegalArgumentException("numHits must be > 0; please use TotalHitCountCollector if you just need the total hit count");
}
FieldValueHitQueue<Entry> queue = FieldValueHitQueue.create(sort.fields, numHits);
if (after == null) {
return new SimpleFieldCollector(sort, queue, numHits, fillFields, trackDocScores, trackMaxScore);
} else {
if (after.fields == null) {
throw new IllegalArgumentException("after.fields wasn't set; you must pass fillFields=true for the previous search");
}
if (after.fields.length != sort.getSort().length) {
throw new IllegalArgumentException("after.fields has " + after.fields.length + " values but sort has " + sort.getSort().length);
}
return new PagingFieldCollector(sort, queue, after, numHits, fillFields, trackDocScores, trackMaxScore);
}
}
在lucene6.4.1版本中,无论是SimpleFieldCollector和PagingFieldCollector都和上面的TopScoreDocsCollector一样,都是不具备提前结束功能的,也就是说都会扫描完全部的命中文档。不过在更高版本的lucene中,具备了这个功能,判断依据是指定的search sort=index sort,如果一致,则在收集topN之后可以通过抛出CollectionTerminatedException异常的方式提前结束收集。
//该部分代码为lucene高版本代码
if (searchSortPartOfIndexSort == null) {
final Sort indexSort = context.reader().getMetaData().getSort();
searchSortPartOfIndexSort = canEarlyTerminate(sort, indexSort);
if (searchSortPartOfIndexSort) {
firstComparator.disableSkipping();
}
}
...
boolean thresholdCheck(int doc) throws IOException {
if (collectedAllCompetitiveHits || reverseMul * comparator.compareBottom(doc) <= 0) {
// since docs are visited in doc Id order, if compare is 0, it means
// this document is largest than anything else in the queue, and
// therefore not competitive.
if (searchSortPartOfIndexSort) {
if (hitsThresholdChecker.isThresholdReached()) {
totalHitsRelation = Relation.GREATER_THAN_OR_EQUAL_TO;
throw new CollectionTerminatedException();
} else {
collectedAllCompetitiveHits = true;
}
} else if (totalHitsRelation == TotalHits.Relation.EQUAL_TO) {
// we can start setting the min competitive score if the
// threshold is reached for the first time here.
updateMinCompetitiveScore(scorer);
}
return true;
}
return false;
}
Elasticsearch从6.x版本开始也支持了自定义写入的顺序,可以不是_doc而是某个字段值。
回到我们现有的Elasticsearch5.2.2对应Lucene6.4.1。虽然Lucene没有提供提前终止功能,但是Elasticsearch做了这个功能。
//QueryPhase
...
final boolean terminateAfterSet = searchContext.terminateAfter() != SearchContext.DEFAULT_TERMINATE_AFTER;
if (terminateAfterSet) {
final Collector child = collector;
// throws Lucene.EarlyTerminationException when given count is reached
collector = Lucene.wrapCountBasedEarlyTerminatingCollector(collector, searchContext.terminateAfter());
if (doProfile) {
collector = new InternalProfileCollector(collector, CollectorResult.REASON_SEARCH_TERMINATE_AFTER_COUNT,
Collections.singletonList((InternalProfileCollector) child));
}
}
...
当terminateAfterSet=true时,进入Lucene.wrapCountBasedEarlyTerminatingCollector方法,该方法返回EarlyTerminatingCollector,该类重写了collect方法。在进入TopFieldCollector$PagingFieldCollector$1.collect方法之前会先调用这个collect方法。
//EarlyTerminatingCollector
...
@Override
public void collect(int doc) throws IOException {
leafCollector.collect(doc);
if (++count >= maxCountHits) {
throw new EarlyTerminationException("early termination [CountBased]");
}
}
...
方法很简单,判断当前搜集的count是否大于等于maxCountHits(即:searchContext.terminateAfter()),如果成立则抛出EarlyTerminationException,然后在QueryPhase捕获异常,查询结束。
//QueryPhase
...
try {
if (collector != null) {
if (doProfile) {
searchContext.getProfilers().getCurrentQueryProfiler().setCollector((InternalProfileCollector) collector);
}
searcher.search(query, collector);
}
} catch (TimeLimitingCollector.TimeExceededException e) {
assert timeoutSet : "TimeExceededException thrown even though timeout wasn't set";
queryResult.searchTimedOut(true);
} catch (Lucene.EarlyTerminationException e) {
assert terminateAfterSet : "EarlyTerminationException thrown even though terminateAfter wasn't set";
queryResult.terminatedEarly(true);
} finally {
searchContext.clearReleasables(SearchContext.Lifetime.COLLECTION);
}
...
到此,我们可以确定目前我们使用的Elasticsearch5.2.2是具备提前终止功能的,下面看触发条件:searchContext.terminateAfter() != SearchContext.DEFAULT_TERMINATE_AFTER;
从代码我们看出触发条件主要涉及一个变量searchContext.terminateAfter(),这个变量是在这里被定义的
//QueryPhase
...
if (searchContext.request().scroll() != null) {
numDocs = Math.min(searchContext.size(), totalNumDocs);
after = scrollContext.lastEmittedDoc;
if (returnsDocsInOrder(query, searchContext.sort())) {
if (scrollContext.totalHits == -1) {
// first round
assert scrollContext.lastEmittedDoc == null;
// there is not much that we can optimize here since we want to collect all
// documents in order to get the total number of hits
} else {
// now this gets interesting: since we sort in index-order, we can directly
// skip to the desired doc and stop collecting after ${size} matches
if (scrollContext.lastEmittedDoc != null) {
BooleanQuery bq = new BooleanQuery.Builder()
.add(query, BooleanClause.Occur.MUST)
.add(new MinDocQuery(after.doc + 1), BooleanClause.Occur.FILTER)
.build();
query = bq;
}
searchContext.terminateAfter(numDocs);
}
}
} else {
after = searchContext.searchAfter();
}
...
从代码中推断出触发终止的场景有三个必要条件:
以上全部成立后,设置terminateAfter为numDocs
final int totalNumDocs = searcher.getIndexReader().numDocs();
int numDocs = Math.min(searchContext.from() + searchContext.size(), totalNumDocs);
//如果为scroll请求
numDocs = Math.min(searchContext.size(), totalNumDocs);
至此,我们确认scroll请求指定_doc排序在从第二页开始,只会收集size个doc,性能上要好上很多。
对于scroll请求,由于scroll不支持向前翻页,所以每次查询对于已经查过的数据是没有必要收集的,Elasticsearch对于scroll请求,包装了一层MinDocQuery,用于过滤掉已经翻页过的数据,大大减少文档的命中数,避免收集无用doc,这对于越深度的翻页,性能差别越大。
after = scrollContext.lastEmittedDoc;
...
if (scrollContext.lastEmittedDoc != null) {
BooleanQuery bq = new BooleanQuery.Builder()
.add(query, BooleanClause.Occur.MUST)
.add(new MinDocQuery(after.doc + 1), BooleanClause.Occur.FILTER)
.build();
query = bq;
}
这样每次就可以跳过已经翻页过的数据,直接从lastEmittedDoc + 1开始匹配。其实这也是为什么scroll不能往回翻,只能往下翻且不能跳页的原因。
lucene收集命中文档在scoreAll方法中
static void scoreAll(LeafCollector collector, DocIdSetIterator iterator, TwoPhaseIterator twoPhase, Bits acceptDocs) throws IOException {
if (twoPhase == null) {
for (int doc = iterator.nextDoc(); doc != DocIdSetIterator.NO_MORE_DOCS; doc = iterator.nextDoc()) {
if (acceptDocs == null || acceptDocs.get(doc)) {
collector.collect(doc);
}
}
} else {
// The scorer has an approximation, so run the approximation first, then check acceptDocs, then confirm
final DocIdSetIterator approximation = twoPhase.approximation();
for (int doc = approximation.nextDoc(); doc != DocIdSetIterator.NO_MORE_DOCS; doc = approximation.nextDoc()) {
if ((acceptDocs == null || acceptDocs.get(doc)) && twoPhase.matches()) {
collector.collect(doc);
}
}
}
}
当执行iterator.nextDoc()时,实际上执行的是ConjunctionDISI.nextDoc()方法,在这里进入doNext方法,开始合并倒排表逻辑,这里就会进入MinDocQuery的advance。
@Override
public int nextDoc() throws IOException {
return doNext(lead1.nextDoc());
}
...
private int doNext(int doc) throws IOException {
advanceHead: for(;;) {
assert doc == lead1.docID();
// find agreement between the two iterators with the lower costs
// we special case them because they do not need the
// 'other.docID() < doc' check that the 'others' iterators need
final int next2 = lead2.advance(doc);
if (next2 != doc) {
doc = lead1.advance(next2);
if (next2 != doc) {
continue;
}
}
// then find agreement with other iterators
for (DocIdSetIterator other : others) {
// other.doc may already be equal to doc if we "continued advanceHead"
// on the previous iteration and the advance on the lead scorer exactly matched.
if (other.docID() < doc) {
final int next = other.advance(doc);
if (next > doc) {
// iterator beyond the current doc - advance lead and continue to the new highest doc.
doc = lead1.advance(next);
continue advanceHead;
}
}
}
// success - all iterators are on the same doc
return doc;
}
}
MinDocQuery重写了createWeight方法,重新定义了Scorer,在advance方法中,当doc=-1时,直接将doc跳到segmentMinDoc(segmentMinDoc=lastEmittedDoc+1)
//MinDocQuery
@Override
public Weight createWeight(IndexSearcher searcher, boolean needsScores) throws IOException {
return new ConstantScoreWeight(this) {
@Override
public Scorer scorer(LeafReaderContext context) throws IOException {
final int maxDoc = context.reader().maxDoc();
if (context.docBase + maxDoc <= minDoc) {
return null;
}
final int segmentMinDoc = Math.max(0, minDoc - context.docBase);
final DocIdSetIterator disi = new DocIdSetIterator() {
int doc = -1;
@Override
public int docID() {
return doc;
}
@Override
public int nextDoc() throws IOException {
return advance(doc + 1);
}
@Override
public int advance(int target) throws IOException {
assert target > doc;
if (doc == -1) {
// skip directly to minDoc
doc = Math.max(target, segmentMinDoc);
} else {
doc = target;
}
if (doc >= maxDoc) {
doc = NO_MORE_DOCS;
}
return doc;
}
@Override
public long cost() {
return maxDoc - segmentMinDoc;
}
};
return new ConstantScoreScorer(this, score(), disi);
}
};
}
这样在合并倒排表之后,实际上就不会再命中上一页的内容了。并且从逻辑上看,如果触发了提前终止,后续倒排表也没必要合并了,性能提升了不少。
其实从上面代码就可以发现,scroll和search_after查询实际上走的逻辑是一样的,都是通过一个after变量来翻页,只不过scroll的after=scrollContext.lastEmittedDoc(ScoreDoc),search_after的after = searchContext.searchAfter(),是FieldDoc,其实也是ScoreDoc,只不过是包含了sort的fieldName信息。最终都会收集全部的命中文档之后才能得到排序结果。只不过scroll对于_doc排序做了优化,性能要非常好。
至于search_after即使指定_doc排序,一样要收集全部的命中文档,因为search_after是动态的,所以使用MinDocQuery跳跃就不是很合适了。但是search_after是可以提前终止的,lucene的后续版本中也是支持了这点。Elasticsearch6.x开始也是支持index sort,写入时指定索引的顺序,这样当查询的时候指定sort=idnex sort,就可以触发提前终止,不再收集全部命中的文档。这点我以前实际应用过了。不过Elasticsearch5.2.2还不支持。
其实我们不妨大胆想象一下,如果我们可以修改lastEmittedDoc这个值呢?像search_after一样传进来,这样就能像search_after一样翻页了,只不过由于是快照,无法获取更新数据,并且保持SearchContext本身也是一种消耗。但是从性能上考虑,如果是_doc排序,scroll要远优秀与search_after。
public class ScrollContext {
public int totalHits = -1; //查询命中总数
public float maxScore; //上一页最大分数
public ScoreDoc lastEmittedDoc; //上一页最大文档
public Scroll scroll; //keepAlive,存活时间
}
ScrollContext只会存储 maxScore和lastEmittedDoc信息用于翻页,并没有找到存储其他信息。从代码分析中也主要用到了lastEmittedDoc和maxScore。
但是scroll请求保存的上下文信息不仅仅是ScrollContext,而是SearchContext,至于SearchContext里面保存的信息就非常多了,最关键的就是searcher,searcher里包含IndexReader的信息,比如leafContexts,leafContexts就是LeafReaderContext。而每次执行查询,都是要读取LeafReaderContext的,由于IndexReader一直保持在SearchContext里,而IndexReader的特性是一旦创建了IndexReader,对于后续索引的更新,是感知不到的,除非是重新打开一个reader或者使用DirectoryReader.openIfChanged(oldreader)。所以这就是为什么scroll查询无法感知索引的更新,而search_after却可以感知索引更新,因为每次search_after查询都是重新打开一个reader。
经过测试,即使scroll过程中触发了merge,被merge的segment文件也不会立即被删除,当然,新的segment也不会被发现。这也就造成了scroll无法感知数据的更新,所以这才是scroll所谓的快照概念。快照的其实是LeafReaderContext。
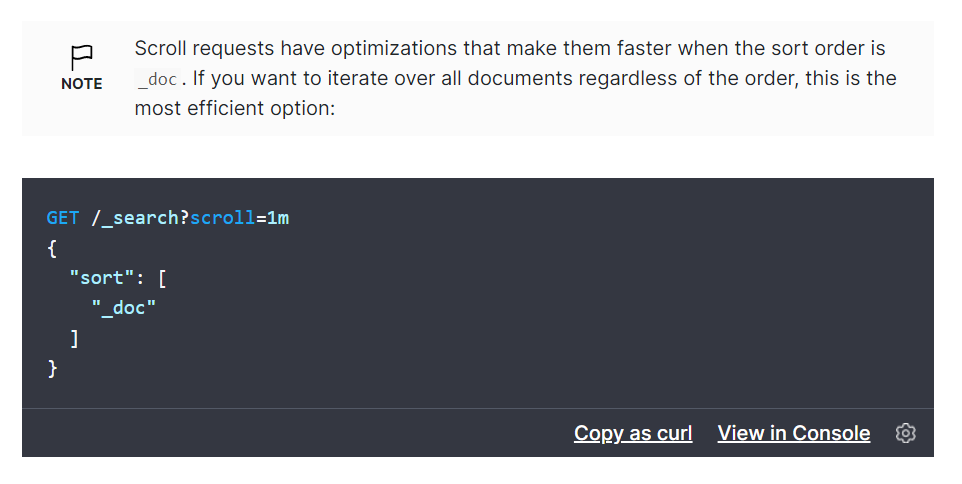
最后放一张官网的截图
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
参考文章搭建文章gitte源码在线体验可以注册两个号来测试演示图:一.整体介绍 介绍SignalR一种通讯模型Hub(中心模型,或者叫集线器模型),调用这个模型写好的方法,去发送消息。 内容有: ①:Hub模型的方法介绍 ②:服务器端代码介绍 ③:前端vue3安装并调用后端方法 ④:聊天室样例整体流程:1、进入网站->调用连接SignalR的方法2、与好友发送消息->调用SignalR的自定义方法 前端通过,signalR内置方法.invoke() 去请求接口3、监听接受方法(渲染消息)通过new signalR.HubConnectionBuilder().on
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
快速导航(持续更新中…)Cesium源码解析一(terrain文件的加载、解析与渲染全过程梳理)Cesium源码解析二(metadataAvailability的含义)Cesium源码解析三(metadata元数据拓展中行列号的分块规则解析)Cesium源码解析四(Quantized-Mesh(.terrain)格式文件在CesiumJS和UE中加载情况的对比)目录1.前言2.本篇的由来3.terrain文件的加载3.1更新环境3.2更新和执行渲染命令3.3数据优化3.4结束当前帧4.总结1.前言 目前市场上三维比较火的实现方案主要有两种,b/s的方案主要是Cesium,c/s的方案主要是u
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就