HTML Tag 的 id 属性值是唯一的,故不存在根据 id 定位多个元素的情况。下面以在百度首页搜索框输入文本“python”为例。搜索框的 id 属性值为“kw”,如图1.1所示:
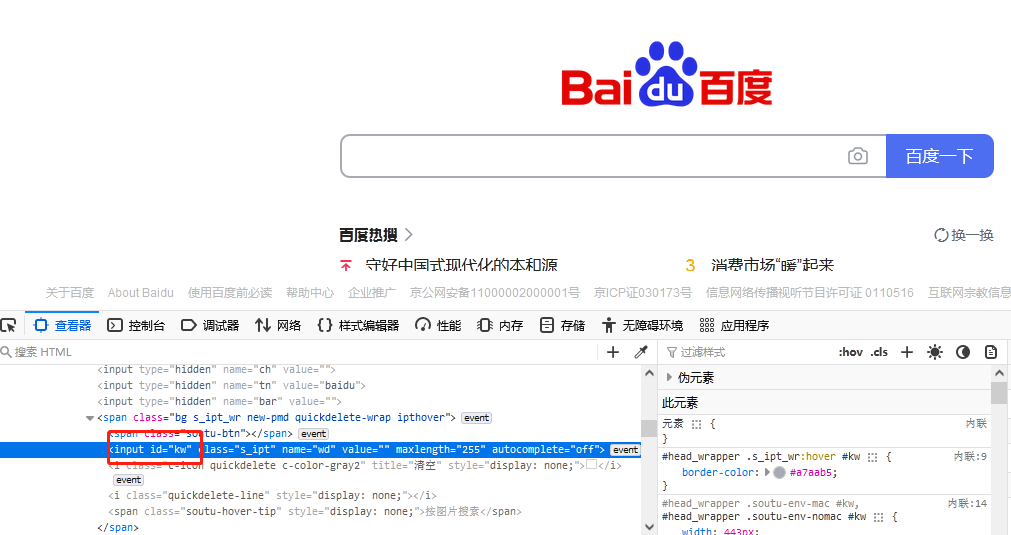
代码如下,“find_element_by_id”方法已废弃,使用find_element(By.ID, 'kw')
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
# 需要将浏览器驱动添加到环境变量中
# 打开百度
driver.get('https://www.baidu.com/')
# 通过id,在搜索输入框中输入文本“python”
driver.find_element(By.ID, 'kw').send_keys('python')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()以上百度搜索框也可以用 name 来实现,如图 1.1 所示,其 name 属性值为“wd”,方法“find_element(By.NAME, 'wd')”表示通过 name 来定位
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过name,在搜索输入框中输入文本“自动化测试”
driver.find_element(By.NAME, 'wd').send_keys('自动化测试')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()注意:用 name 方式定位需要保证 name 值唯一,否则定位失败。
以百度首页搜索框为例,如图 1.1所示,其 class 属性值为“s_ipt”,“By.CLASS_NAME, 's_ipt'”表示通过 class_name 来定位
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过class,在搜索输入框中输入文本“web测试”
driver.find_element(By.CLASS_NAME, 's_ipt').send_keys('web测试')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()link_text 是以超链接全部名字作为关键字来定位元素的。以百度首页“新闻”超链接为例,如图 1.2 所示,关键字为“新闻”。
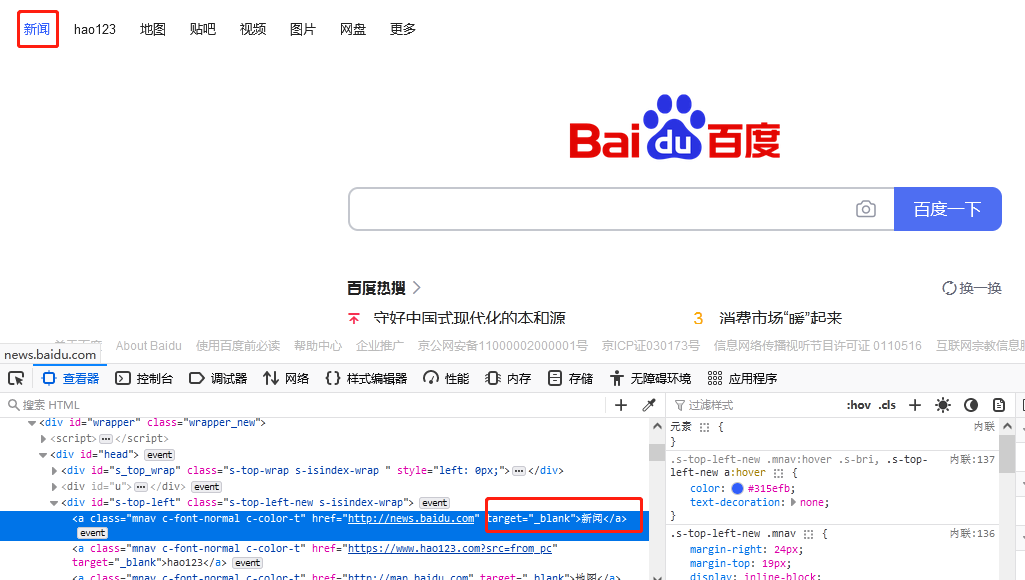
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过link_text定位,点击‘新闻’超链接
driver.find_element(By.LINK_TEXT, '新闻').click()
# 关闭浏览器
driver.close()注意:用此方法定位元素超链接,中文字需要写全。
即用超链接文字的部分文本来定位元素,类似数据库的模糊查询。以“新闻”超链接为例,只需“新”一个字即可,即取超链接全部文本的一个子集。
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 通过partial_link_text定位,用超链接文字的部分文本来定位元素,类似数据库的模糊查询
driver.find_element(By.PARTIAL_LINK_TEXT, '新').click()
# 关闭浏览器
driver.close()tag_name 定位即通过标签名称定位,如图 1.6所示,定位标签“form”并打印标签属性值“name”。
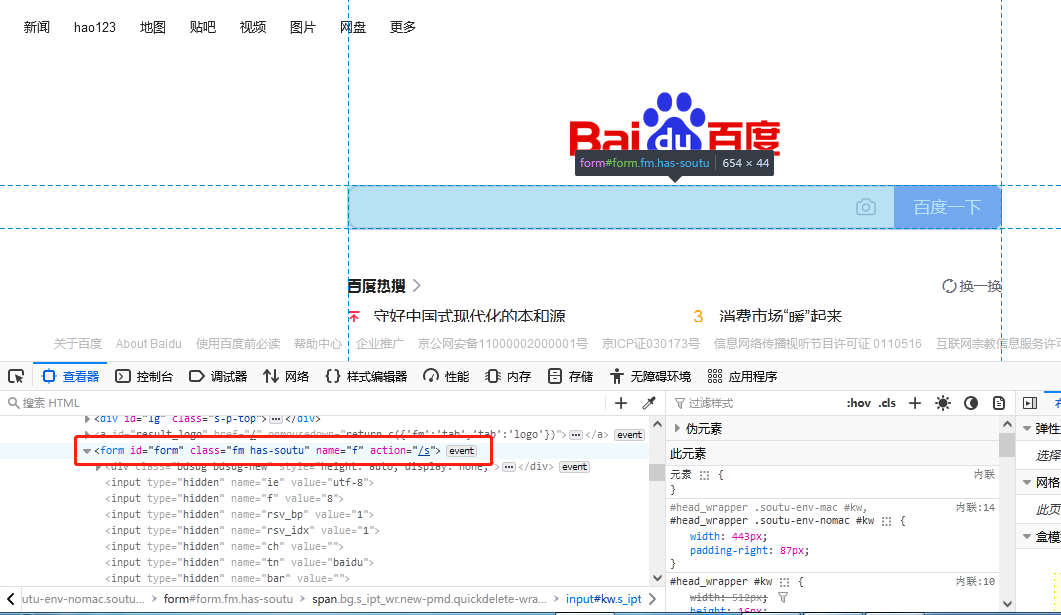
代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# tag_name 定位即通过标签名称定位
print(driver.find_element(By.TAG_NAME, 'form').get_attribute('name'))成功后控制台输出“f”:

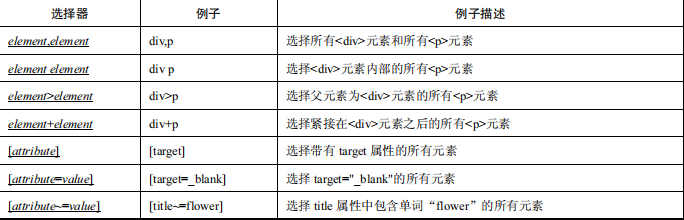
CSS 定位的优点是速度快、语法简洁。表 1.1 中的内容出自 W3School 的 CSS 参考手册。CSS 定位的选择器有十几种,在本节中主要介绍几种比较常用的选择器。
仍以百度搜索框为例,代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# 以class选择器为例,实现CSS定位,在搜索框输入“python3”
driver.find_element(By.CSS_SELECTOR, '.s_ipt').send_keys('python3')
# 以id定位语法结构为:#加 id 名,实现CSS定位,在搜索框输入“python3”
driver.find_element(By.CSS_SELECTOR, '#kw').send_keys('python3')
# CSS 定位主要利用属性 class 和 id 进行元素定位。也可以利用常规的标签名称来定位,如输入框标签“input”,在标签内部又设置了属性值为“name=’wd’”
driver.find_element(By.CSS_SELECTOR, "input[name='wd']").send_keys('python3')
# CSS 定位方式可以使用元素在页面布局中的绝对路径来实现元素定位。百度首页搜索输入框元素的绝对路
# 径为“html>body>div>div>div>div>div>form>span>input[name="wd"]”
driver.find_element(By.CSS_SELECTOR, 'html>body>div>div>div>div>div>form>span>input[name="wd"]').send_keys('python3')
# CSS 定位也可以使用元素在页面布局中的相对路径来实现元素定位。相对路径的写法和直接利用标签名称来定位,两者
# 的代码实现的功能是一致的
driver.find_element(By.CSS_SELECTOR, "input[name='wd']").send_keys('python3')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()通过 XPath 来定位元素的方式,对比较难以定位的元素来说很有效,几乎都可以解决,特别是对于有些元素没有 id、name 等属性的情况。
XPath 是 XML Path 语言的缩写,是一种用来确定 XML 文档中某部分位置的语言。它在 XML 文档中通过元素名和属性进行搜索,主要用途是在 XML 文档中寻找节点。XPath定位比 CSS 定位有更大的灵活性。XPath 可以向前搜索也可以向后搜索,而 CSS 定位只能向前搜索,但是 XPath 定位的速度比 CSS 慢一些。
XPath 语言包含根节点、元素、属性、文本、处理指令、命名空间等。以下文本为 XML实例文档,用于演示 XML 的各种节点类型,便于理解 XPath。
<?xml version = "1.0" encoding = "utf-8" ?>
<!-- 这是一个注释节点 -->
<animalList type="mammal">
<animal categoruy = "forest">
<name>Tiger</name>
<size>big</size>
<action>run</action>
</animal>
</animalList>其中<animalList>为文档节点,也是根节点;<name>为元素节点;type=“mammal”为属性节点。
节点之间的关系:
• 父节点。每个元素都有一个父节点,如上面的 XML 示例中,animal 元素是 name、size,以及 action 元素的父节点。
• 子节点。与父节点相反,这里不再赘述。
• 兄弟节点,有些也叫同胞节点。它表示拥有相同父节点的节点。如上代码所示,name、size 和 action 元素都是同胞节点。
• 先辈节点。它是指某节点的父节点,或者父节点的父节点,以此类推。如上代码所示,name 元素节点的先辈节点有 animal 和 animalList。
• 后代节点。它表示某节点的子节点、子节点的子节点,以此类推。如上代码所示,animalList 元素节点的后代节点有 animal、name 等。
仍以百度搜索框为例,代码如下:
driver = webdriver.Firefox()
# 打开百度
driver.get('https://www.baidu.com/')
# XPath 有多种定位策略,最简单直观的就是写出元素的绝对路径。
driver.find_element(By.XPATH, '/html/body/div/div/div/div/div/form/span/input').send_keys('python3')
# XPath还可以使用元素的属性值来定位。//input 表示当前页面某个 input 标签,[@id='kw'] 表示这个元素的 id 值是 kw。
driver.find_element(By.XPATH, "//input[@id='kw']").send_keys('python3')
# 如果一个元素本身没有可以唯一标识这个元素的属性值,我们可以查找其上一级元素。
# form[@class='fm has-soutu']通过 class 定位到父元素,后面的/span/input 表示父元素下面的子元素。
driver.find_element(By.XPATH, "//form[@class='fm has-soutu']/span/input").send_keys('python3')
# 如果一个属性不能唯一区分一个元素,那么我们可以使用逻辑运算符连接多个属性来查找元素
driver.find_element(By.XPATH, "//input[@id='kw' and @class='s_ipt']").send_keys('python3')
# 点击搜索
driver.find_element(By.ID, 'su').click()
# 关闭浏览器
driver.close()本章主要介绍了 Selenium 元素的八大定位,每一种定位方式都有其特殊的用法,读者只要掌握其特殊性即可。需要在项目中多用多想、总结经验,时间久了会对这些定位方式有更深的理解。
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞