目录
3.1 试析在什么情形下式(3.2) 中不必考虑偏置项 b.
3.2、试证明,对于参数w,对率回归的目标函数(3.18)是非凸的,但其对数似然函数(3.27)是凸的.
3.3、编程实现对率回归,并给出西瓜数据集3.0α上的结果.
3.4 选择两个 UCI 数据集,比较 10 折交叉验证法和留一法所估计出的对率回归的错误率。
3.5 编辑实现线性判别分析,并给出西瓜数据集 3.0α 上的结果.
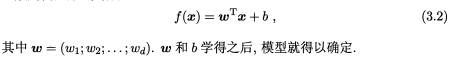
①b与输入毫无关系,如果没有b,y‘=wx必须经过原点
②当两个线性模型相减时,消除了b。可用训练集中每个样本都减去第一个样本,然后对新的样本做线性回归,不用考虑偏置项b。

3.27

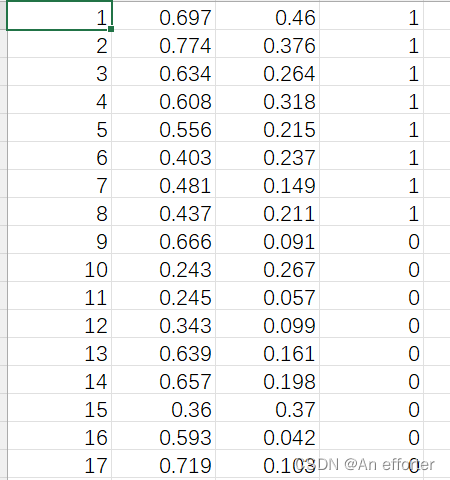
数据集:
3.3.py
# -*- coding: utf-8 -*
'''
data importion
'''
import numpy as np # for matrix calculation
import matplotlib.pyplot as plt
# load the CSV file as a numpy matrix
# 将CSV文件加载为numpy矩阵
dataset = np.loadtxt('watermelon3_0_Ch.csv', delimiter=",")
# separate the data from the target attributes
# 将数据与目标属性分离
X = dataset[:, 1:3]
y = dataset[:, 3]
m, n = np.shape(X)
# draw scatter diagram to show the raw data
#绘制出数据点
f1 = plt.figure(1)
plt.title('watermelon_3a')
plt.xlabel('density')
plt.ylabel('ratio_sugar')
plt.scatter(X[y == 0, 0], X[y == 0, 1], marker='o', color='k', s=100, label='bad')
plt.scatter(X[y == 1, 0], X[y == 1, 1], marker='o', color='g', s=100, label='good')
plt.legend(loc='upper right')
# plt.show()
'''
using sklearn lib for logistic regression
使用sklearn库进行逻辑回归
'''
from sklearn import metrics
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
import matplotlib.pylab as pl
# generalization of test and train set
# 先划分训练集和测试集,采用sklearn.model_selection.train_test_split()实现
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.5, random_state=0)
# model training
# 采用sklearn.linear_model.LogisticRegression,基于训练集直接拟合出逻辑回归模型,然后在测试集上评估模型(查看混淆矩阵和F1值)
log_model = LogisticRegression() # using log-regression lib model
log_model.fit(X_train, y_train) # fitting
# model validation 模型确认
y_pred = log_model.predict(X_test)
# summarize the fit of the model 总结模型的拟合情况
print(metrics.confusion_matrix(y_test, y_pred))
print(metrics.classification_report(y_test, y_pred))
precision, recall, thresholds = metrics.precision_recall_curve(y_test, y_pred)
# show decision boundary in plt 在PLT中显示决策边界
# X - some data in 2dimensional np.array X -二维np.array中的一些数据
f2 = plt.figure(2)
h = 0.001
x0_min, x0_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
x1_min, x1_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
x0, x1 = np.meshgrid(np.arange(x0_min, x0_max, h),
np.arange(x1_min, x1_max, h))
# here "model" is your model's prediction (classification) function
# 这里的“模型”是模型的预测(分类)函数
z = log_model.predict(np.c_[x0.ravel(), x1.ravel()])
# Put the result into a color plot 把结果放入颜色图中
z = z.reshape(x0.shape)
# 采用matplotlib.contourf绘制的决策区域和边界,可以看出对率回归分类器还是成功的分出了绝大多数类:
plt.contourf(x0, x1, z, cmap=pl.cm.Paired)
# Plot also the training pointsplt.title('watermelon_3a')
plt.title('watermelon_3a')
plt.xlabel('density')
plt.ylabel('ratio_sugar')
plt.scatter(X[y == 0, 0], X[y == 0, 1], marker='o', color='k', s=100, label='bad')
plt.scatter(X[y == 1, 0], X[y == 1, 1], marker='o', color='g', s=100, label='good')
# plt.show()
'''
coding to implement logistic regression
编码以实现逻辑回归
'''
from sklearn import model_selection
import self_def
# X_train, X_test, y_train, y_test
np.ones(n)
m, n = np.shape(X)
X_ex = np.c_[X, np.ones(m)] # extend the variable matrix to [x, 1]
X_train, X_test, y_train, y_test = model_selection.train_test_split(X_ex, y, test_size=0.5, random_state=0)
# using gradDescent to get the optimal parameter beta = [w, b] in page-59
beta = self_def.gradDscent_2(X_train, y_train)
# prediction, beta mapping to the model
y_pred = self_def.predict(X_test, beta)
m_test = np.shape(X_test)[0]
# calculation of confusion_matrix and prediction accuracy
# #混淆矩阵的计算和预测精度
cfmat = np.zeros((2, 2))
for i in range(m_test):
if y_pred[i] == y_test[i] == 0:
cfmat[0, 0] += 1
elif y_pred[i] == y_test[i] == 1:
cfmat[1, 1] += 1
elif y_pred[i] == 0:
cfmat[1, 0] += 1
elif y_pred[i] == 1:
cfmat[0, 1] += 1
print(cfmat)
self_def.py 是 需要调用的函数
import numpy as np
def likelihood_sub(x, y, beta):
'''
@param X: one sample variables
@param y: one sample label
@param beta: the parameter vector in 3.27
@return: the sub_log-likelihood of 3.27
3.27式子的变成对象
'''
return -y * np.dot(beta, x.T) + np.math.log(1 + np.math.exp(np.dot(beta, x.T)))
def likelihood(X, y, beta):
'''
@param X: the sample variables matrix
@param y: the sample label matrix
@param beta: the parameter vector in 3.27
@return: the log-likelihood of 3.27
'''
sum = 0
m, n = np.shape(X)
for i in range(m):
sum += likelihood_sub(X[i], y[i], beta)
return sum
def partial_derivative(X, y, beta): # refer to 3.30 on book page 60 请参阅第60页的3.30
'''
@param X: the sample variables matrix
@param y: the sample label matrix
@param X:样本变量矩阵
@param y:样本标签矩阵
@param beta: the parameter vector in 3.27
@return: the partial derivative of beta [j]
'''
m, n = np.shape(X)
pd = np.zeros(n)
for i in range(m):
tmp = y[i] - sigmoid(X[i], beta)
for j in range(n):
pd[j] += X[i][j] * (tmp)
return pd
def gradDscent_1(X, y): # implementation of fundational gradDscent algorithms 基本梯度算法的实现
'''
@param X: X is the variable matrix
@param y: y is the label array
@return: the best parameter estimate of 3.27
然后基于训练集(注意x->[x,1]),给出基于3.27似然函数的定步长梯度下降法,降低损失,注意这里的偏梯度实现技巧:
'''
import matplotlib.pyplot as plt
h = 0.1 # step length of iterator 迭代器的步长
max_times = 500 # give the iterative times limit 给出迭代次数的极限
m, n = np.shape(X)
b = np.zeros((n, max_times)) # for show convergence curve of parameter 表示参数的收敛曲线
beta = np.zeros(n) # parameter and initial 参数和初始
delta_beta = np.ones(n) * h
llh = 0
llh_temp = 0
for i in range(max_times):
beta_temp = beta.copy()
for j in range(n):
# for partial derivative 偏导数
beta[j] += delta_beta[j]
llh_tmp = likelihood(X, y, beta)
delta_beta[j] = -h * (llh_tmp - llh) / delta_beta[j]
b[j, i] = beta[j]
beta[j] = beta_temp[j]
beta += delta_beta
llh = likelihood(X, y, beta)
t = np.arange(max_times)
f2 = plt.figure(3)
p1 = plt.subplot(311)
p1.plot(t, b[0])
plt.ylabel('w1')
p2 = plt.subplot(312)
p2.plot(t, b[1])
plt.ylabel('w2')
p3 = plt.subplot(313)
p3.plot(t, b[2])
plt.ylabel('b')
plt.show()
return beta
'''
采用随机梯度下降法来优化:上面采用的是全局定步长梯度下降法(称之为批量梯度下降),
这种方法在可能会面临收敛过慢和收敛曲线波动情况的同时,每次迭代需要全局计算,
计算量随数据量增大而急剧增大。所以尝试采用随机梯度下降来改善参数迭代寻优过程。
'''
def gradDscent_2(X, y): # implementation of stochastic gradDscent algorithms 随机梯度算法的实现
'''
@param X: X is the variable matrix
@param y: y is the label array
@return: the best parameter estimate of 3.27
随机梯度下降法的核心思想是增量学习:一次只用一个新样本来更新回归系数,从而形成在线流式处理。
同时为了加快收敛,采用变步长的策略,h随着迭代次数逐渐减小。
'''
import matplotlib.pyplot as plt
m, n = np.shape(X)
h = 0.5 # step length of iterator and initial
beta = np.zeros(n) # parameter and initial
delta_beta = np.ones(n) * h
llh = 0
llh_temp = 0
b = np.zeros((n, m)) # for show convergence curve of parameter
for i in range(m):
beta_temp = beta.copy()
for j in range(n):
# for partial derivative
h = 0.5 * 1 / (1 + i + j) # change step length of iterator
beta[j] += delta_beta[j]
b[j, i] = beta[j]
llh_tmp = likelihood_sub(X[i], y[i], beta)
delta_beta[j] = -h * (llh_tmp - llh) / delta_beta[j]
beta[j] = beta_temp[j]
beta += delta_beta
llh = likelihood_sub(X[i], y[i], beta)
t = np.arange(m)
f2 = plt.figure(3)
p1 = plt.subplot(311)
p1.plot(t, b[0])
plt.ylabel('w1')
p2 = plt.subplot(312)
p2.plot(t, b[1])
plt.ylabel('w2')
p3 = plt.subplot(313)
p3.plot(t, b[2])
plt.ylabel('b')
plt.show()
return beta
#sigmoid函数
def sigmoid(x, beta):
'''
@param x: is the predict variable
@param beta: is the parameter
@return: the sigmoid function value
'''
return 1.0 / (1 + np.math.exp(- np.dot(beta, x.T)))
def predict(X, beta):
'''
prediction the class lable using sigmoid 使用sigmoid预测类标签
@param X: data sample form like [x, 1] 数据样本形式如[x, 1]
@param beta: the parameter of sigmoid form like [w, b] 形如[w, b]的参数
@return: the class lable array 类标签数组
'''
m, n = np.shape(X)
y = np.zeros(m)
for i in range(m):
if sigmoid(X[i], beta) > 0.5: y[i] = 1;
return y
return参考代码: han1057578619/MachineLearning_Zhouzhihua_ProblemSets
3.5.py
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
class LDA(object):
# 绘图,求出均值向量,根据公式3.34和3.39求出类内散度矩阵和类间散度矩阵
def fit(self, X_, y_, plot_=False):
pos = y_ == 1
neg = y_ == 0
X0 = X_[neg]
X1 = X_[pos]
# 均值向量,(1, 2)
u0 = X0.mean(0, keepdims=True) # (1, n)
u1 = X1.mean(0, keepdims=True)
# 类内散度矩阵,公式3.33,(2, 2)
sw = np.dot((X0 - u0).T, (X0 - u0)) + np.dot((X1 - u1).T, (X1 - u1))
# 类间散度矩阵,公式3.37,(1, 2)
w = np.dot(np.linalg.inv(sw), (u0 - u1).T).reshape(1, -1)
if plot_:
fig, ax = plt.subplots()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['left'].set_position(('data', 0))
ax.spines['bottom'].set_position(('data', 0))
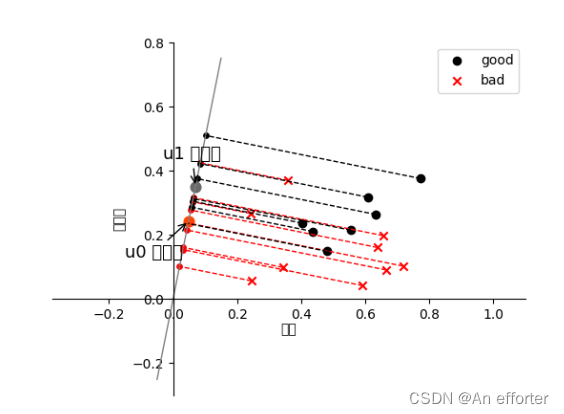
plt.scatter(X1[:, 0], X1[:, 1], c='k', marker='o', label='good')
plt.scatter(X0[:, 0], X0[:, 1], c='r', marker='x', label='bad')
plt.xlabel('密度', labelpad=1)
plt.ylabel('含糖量')
plt.legend(loc='upper right')
x_tmp = np.linspace(-0.05, 0.15)
y_tmp = x_tmp * w[0, 1] / w[0, 0]
plt.plot(x_tmp, y_tmp, '#808080', linewidth=1)
wu = w / np.linalg.norm(w)
# 正负样板店
X0_project = np.dot(X0, np.dot(wu.T, wu))
plt.scatter(X0_project[:, 0], X0_project[:, 1], c='r', s=15)
for i in range(X0.shape[0]):
plt.plot([X0[i, 0], X0_project[i, 0]], [X0[i, 1], X0_project[i, 1]], '--r', linewidth=1)
X1_project = np.dot(X1, np.dot(wu.T, wu))
plt.scatter(X1_project[:, 0], X1_project[:, 1], c='k', s=15)
for i in range(X1.shape[0]):
plt.plot([X1[i, 0], X1_project[i, 0]], [X1[i, 1], X1_project[i, 1]], '--k', linewidth=1)
# 中心点的投影
u0_project = np.dot(u0, np.dot(wu.T, wu))
plt.scatter(u0_project[:, 0], u0_project[:, 1], c='#FF4500', s=60)
u1_project = np.dot(u1, np.dot(wu.T, wu))
plt.scatter(u1_project[:, 0], u1_project[:, 1], c='#696969', s=60)
# 均值向量的投影点
ax.annotate(r'u0 投影点',
xy=(u0_project[:, 0], u0_project[:, 1]),
xytext=(u0_project[:, 0] - 0.2, u0_project[:, 1] - 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
ax.annotate(r'u1 投影点',
xy=(u1_project[:, 0], u1_project[:, 1]),
xytext=(u1_project[:, 0] - 0.1, u1_project[:, 1] + 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
plt.axis("equal") # 两坐标轴的单位刻度长度保存一致
plt.show()
self.w = w
self.u0 = u0
self.u1 = u1
return self
def predict(self, X):
project = np.dot(X, self.w.T)
wu0 = np.dot(self.w, self.u0.T)
wu1 = np.dot(self.w, self.u1.T)
return (np.abs(project - wu1) < np.abs(project - wu0)).astype(int)
if __name__ == '__main__':
data_path = r'watermelon3_0_Ch.csv'
data = pd.read_csv(data_path).values
X = data[:, 1:3].astype(float)
y = data[:, 3]
y[y == '是'] = 1
y[y == '否'] = 0
y = y.astype(int)
lda = LDA()
lda.fit(X, y, plot_=True)
print(lda.predict(X)) # 和逻辑回归的结果一致
print(y)
想要代码与数据资源的,可以加我微信好友

参考的博客:
(4条消息) 周志华《机器学习》课后习题第三章解答:Ch3.3 - 编程实现对率回归_zhangriqi的博客-CSDN博客
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
我有两个文本文件,master.txt和926.txt。如果926.txt中有一行不在master.txt中,我想写入一个新文件notinbook.txt。我写了我能想到的最好的东西,但考虑到我是一个糟糕的/新手程序员,它失败了。这是我的东西g=File.new("notinbook.txt","w")File.open("926.txt","r")do|f|while(line=f.gets)x=line.chompifFile.open("master.txt","w")do|h|endwhile(line=h.gets)ifline.chomp!=xputslineendende
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞