第一步:在第一台机器的/usr/local下创建文件夹redis‐cluster,然后在其下面分别创建2个文件夹如下
1. mkdir ‐p /opt/module/redis‐cluster
2. mkdir 8001 8004
第二步:把之前的redis.conf配置文件copy到8001下,修改如下内容:
1. daemonize yes
2. port 8001(分别对每个机器的端口号进行设置)
3. pidfile /var/run/redis_8001.pid # 把pid进程号写入pidfile配置的文件
4. dir /opt/module/redis‐cluster/8001/(指定数据文件存放位置,必须要指定不同的目录位置,不然会 丢失数据)
5. cluster‐enabled yes(启动集群模式)
6. cluster‐config‐file nodes‐8001.conf(集群节点信息文件,这里800x最好和port对应上)
7. cluster‐node‐timeout 10000
8. # bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通 过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
9. protected‐mode no (关闭保护模式)
10. appendonly yes
11. 如果要设置密码需要增加如下配置:
requirepass 123456 (设置redis访问密码)
masterauth 123456 (设置集群节点间访问密码,跟上面一致)
第三步:把修改后的配置文件,copy到8004,修改第2、3、4、6项里的端口号,可以用批量替换::%s/源字符串/目的字符串/g
第四步:另外两台机器也需要做上面几步操作,第二台机器用8002和8005,第三台机器用8003和8006
第五步:分别启动6个redis实例,然后检查是否启动成功
1. /opt/module/redis‐7.0.4/src/redis‐server /opt/module/redis‐cluster/800*/redis.conf
2. ps ‐ef | grep redis 查看是否启动成功
第六步:用redis‐cli创建整个redis集群(redis5以前的版本集群是依靠ruby脚本redis‐trib.rb实现)
# 下面命令里的1代表为每个创建的主服务器节点创建一个从服务器节点
# 执行这条命令需要确认三台机器之间的redis实例要能相互访问,可以先简单把所有机器防火墙关掉,如果不关闭防火墙则需要打开redis服务端口和集群节点gossip通信端口16379(默认是在redis端口号上加1W)
# 关闭防火墙
# systemctl stop firewalld # 临时关闭防火墙
# systemctl disable firewalld # 禁止开机启动
/opt/module/redis‐7.0.4/src/redis‐cli ‐a 123456 ‐‐cluster create ‐‐cluster‐replicas 1 192.168.140.129:8001 192.168.140.130:8003 192.168.140.131:8002 192.168.140.129:8004 192.168.140.130:8006 192.168.140.131:8005
‐‐cluster‐replicas 1 代表为集群里面所有主节点配一个副本,这个例子里面就相当于三主三从
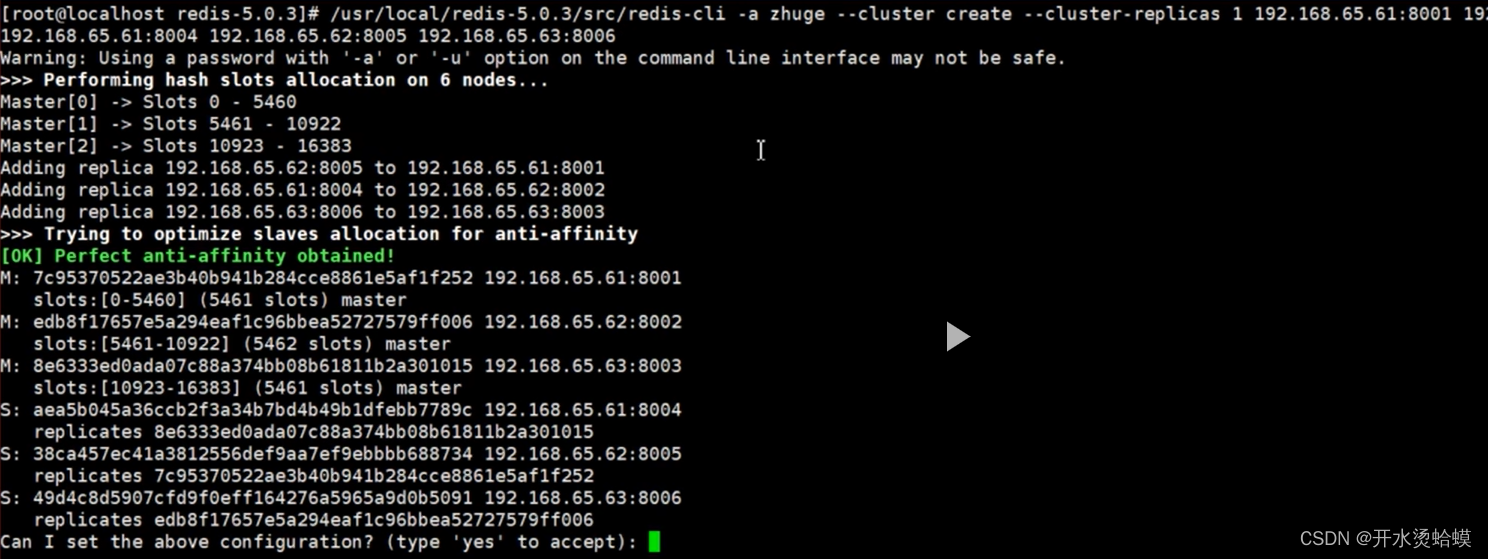
下面表示的集群分片的计划,总共有16384个逻辑分片,类似于先将你所有主节点的内存统计出来,然后分配到16384个hash slot里面,然后平均分配给各个主节点,前面M代表master,S代表slaver,只会给主节点指定槽位
第七步:验证集群:
连接任意一个客户端即可:./redis‐cli ‐c ‐h ‐p (‐a访问服务端密码,‐c表示集群模式,指定ip地址 和端口号)
如:/usr/local/redis‐5.0.3/src/redis‐cli ‐a 123456 ‐c ‐h 192.168.0.61 ‐p 800*
进行验证: cluster info(查看集群信息)、cluster nodes(查看节点列表)
进行数据操作验证
关闭集群则需要逐个进行关闭,使用命令:
/opt/module/redis‐7.0.4/src/redis‐cli ‐a 123456 ‐c ‐h 192.168.0.60 ‐p 800* shutdown
输入cluster info
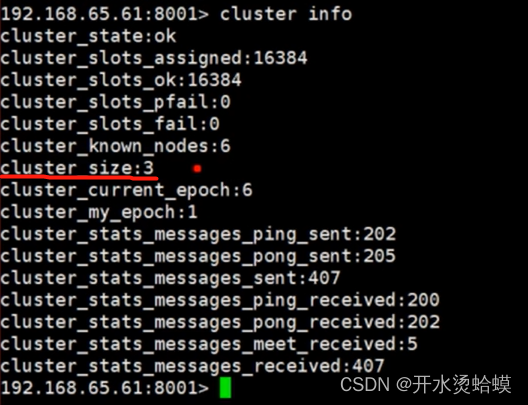
3个节点,,已知总共的节点6个,
cluster nodes

前面代表的该节点的id,根据从节点后面的id能够找到对应的主节点,这边能看到主从节点不在同一台服务器上,尽可能错峰连接,使得数据更加安全,如果主从在一个服务器上,服务器挂掉直接整个数据都会丢失

会把集群信息写到这个文件里面,之前那个命令create cluster是用来创建集群的,等你关掉之后,重新启动就不需要这个命令了,直接启动每个节点自动生成集群了,就是通过上面文件里面的信息,每次启动都会向对应服务器发送通讯,又会重新组成集群状态还原

进入客户端设置参数,可以看到定位到了8002,因为根据设置的key的hash算法结果为6783,相应分配到8002这个节点,其他节点是没有这个信息的
Redis集群原理分析
过程:
就是你先建立集群嘛,然后生成对应的分片信息以及主从节点信息,这些信息都会对应写到设置的conf里面,你设置key-value的时候就从这个文件里面读取信息,先算出slot值,然后判断是在那个范围内,对应的是哪个服务器,在Java 代码里面会将文件里面信息进行缓存
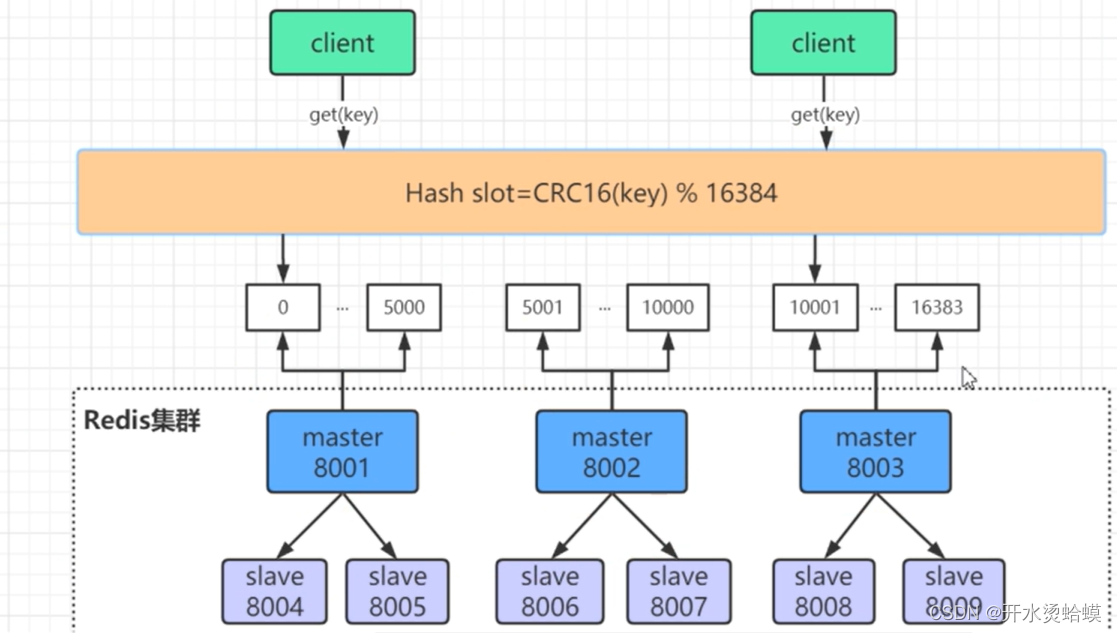
Redis Cluster 将所有数据划分为 16384 个 slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中。
当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息并将其缓存在客户端本地。这 样当客户端要查找某个 key 时,可以直接定位到目标节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
槽位定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模 来得到具体槽位。
HASH_SLOT = CRC16(key) mod 16384
跳转重定位
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客 户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。客户端收到指 令后除了跳转到正确的节点上去操作,还会同步更新纠正本地的槽位映射表缓存,后续所有 key 将使用新的槽 位映射表

Redis集群节点间的通信机制
redis cluster节点间采取gossip协议进行通信
维护集群的元数据(集群节点信息,主从角色,节点数量,各节点共享的数据等)有两种方式:集中 式和gossip
集中式:
优点在于元数据的更新和读取,时效性非常好,一旦元数据出现变更立即就会更新到集中式的存储中,其他节 点读取的时候立即就可以立即感知到;不足在于所有的元数据的更新压力全部集中在一个地方,可能导致元数 据的存储压力。 很多中间件都会借助zookeeper集中式存储元数据。
gossip:
gossip协议包含多种消息,包括ping,pong,meet,fail等等。
meet:某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信;
ping:每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping交换元数据(类似自己感知到的集群节点增加和移除,hash slot信息等);
pong: 对ping和meet消息的返回,包含自己的状态和其他信息,也可以用于信息广播和更新;
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了。
gossip协议的优点在于元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上 去更新,有一定的延时,降低了压力;缺点在于元数据更新有延时可能导致集群的一些操作会有一些滞后。
gossip通信的10000端口
每个节点都有一个专门用于节点间gossip通信的端口,就是自己提供服务的端口号+10000,比如7001,那么 用于节点间通信的就是17001端口。 每个节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几 点接收到ping消息之后返回pong消息。
网络抖动
真实世界的机房网络往往并不是风平浪静的,它们经常会发生各种各样的小问题。比如网络抖动就是非常常见 的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。
为解决这种问题,Redis Cluster 提供了一种选项clusternodetimeout,表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频 繁切换 (数据的重新复制)。
Redis集群选举原理分析
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master 可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
1.slave发现自己的master变为FAIL
2.将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST 信息
3.其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个 epoch只发送一次ack
4.尝试failover的slave收集master返回的FAILOVER_AUTH_ACK
5.slave收到超过半数master的ack后变成新Master(这里解释了集群为什么至少需要三个主节点,如果只有两 个,当其中一个挂了,只剩一个主节点是不能选举成功的)
6.slave广播Pong消息通知其他集群节点。
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待 FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票
延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)
集群脑裂数据丢失问题
redis集群没有过半机制会有脑裂问题,网络分区导致脑裂后多个主节点对外提供写服务,一旦网络分区恢复, 会将其中一个主节点变为从节点,这时会有大量数据丢失
规避方法可以在redis配置里加上参数(这种方法不可能百分百避免数据丢失,参考集群leader选举机制):
min‐replicas‐to‐write 1 //写数据成功最少同步的slave数量,这个数量可以模仿大于半数机制配置,比如 集群总共三个节点可以配置1,加上leader就是2,超过了半数
注意:这个配置在一定程度上会影响集群的可用性,比如slave要是少于1个,这个集群就算leader正常也不能 提供服务了,需要具体场景权衡选择。
集群是否完整才能对外提供服务
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从 库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中 一个挂了,是达不到选举新master的条件的。
奇数个master节点可以在满足选举该条件的基础上节省一个节点,比如三个master节点和四个master节点的 集群相比,大家如果都挂了一个master节点都能选举新master节点,如果都挂了两个master节点都没法选举 新master节点了,所以奇数的master节点更多的是从节省机器资源角度出发说的。
Redis集群对批量操作命令的支持
对于类似mset,mget这样的多个key的原生批量操作命令,redis集群只支持所有key落在同一slot的情况,如果有多个key一定要用mset命令在redis集群上操作,则可以在key的前面加上{XX},这样参数数据分片hash计 算的只会是大括号里的值,这样能确保不同的key能落到同一slot里去,示例如下:
mset {user1}:1:name zhuge {user1}:1:age 18
假设name和age计算的hash slot值不一样,但是这条命令在集群下执行,redis只会用大括号里的 user1 做 hash slot计算,所以算出来的slot值肯定相同,最后都能落在同一slot。
哨兵leader选举流程
当一个master服务器被某sentinel视为下线状态后,该sentinel会与其他sentinel协商选出sentinel的leader进行故障转移工作。每个发现master服务器进入下线的sentinel都可以要求其他sentinel选自己为sentinel的leader,选举是先到先得。同时每个sentinel每次选举都会自增配置纪元(选举周期),每个纪元中只会选择一个sentinel的leader。如果所有超过一半的sentinel选举某sentinel作为leader。之后该sentinel进行故障转移操作,从存活的slave中选举出新的master,这个选举过程跟集群的master选举很类似。哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨兵节点就是哨兵leader了,可以正常选举新master。不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个master节点类似
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
(二十二)-框架主入口main.py设计&log日志调用和生成1测试目的2测试需求3需求分析4详细设计4.1新建存放日志目录log4.1.1配置config.py中写入log的目录4.2`baseInfo.py`中加入日志4.3`test_gedit.py`中加入日志4.4主函数入口main.py中调用日志5调用日志主函数main.py源码6`baseInfo.py`源码7`test_gedit.py`源码8运行效果9目前框架结构1测试目的组织运行所有的测试用例,并调用日志模块,便于问题定位。
(1)为什么写这个话题(Why)读万卷书不如行千里路。这次搭建MQTT服务,遇到了一些误解,特此记录备忘。主要包括:(1)服务(Broker)的账户管理与网页管理平台的账户(2)与web应用的集成(Spring系)(2)ActiveMQ版本选择因为JAVA环境是JDK8,所以按兼容性考虑选择了ActiveMQ5.15的最后版本5.15.15。如果你是JDK11则可考虑ActiveMQ的最新版本5.17或5.18。ActiveMQ支持MQTTv3.1.1andv3.1。(3)ActiveMQ与web应用的集成主要介绍与Spring系的webapp集成(SpringBoot和SpringMVC)。
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
这篇文章,主要介绍如何使用SpringCloud微服务组件从0到1搭建一个微服务工程。目录一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件(2)微服务依赖1.2、搭建注册中心(1)引入依赖(2)配置文件(3)启动类1.3、搭建配置中心(1)引入依赖(2)配置文件(3)启动类1.4、搭建API网关(1)引入依赖(2)配置文件(3)启动类1.5、搭建服务提供者(1)引入依赖(2)配置文件(3)启动类1.6、搭建服务消费者(1)引入依赖(2)配置文件(3)启动类1.7、运行测试一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件这里主要是使用的SpringCloudNetflix
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我目前正在尝试搭建一个学习Ruby的开发环境。环境主要是为了掌握这门语言,但我很可能会在很长一段时间后转向使用Rails进行开发。以Web开发为目标,我想了解首选的Web服务器和数据库。我打算在虚拟机上设置环境,所以我不担心把它弄坏。因此,我愿意使用Linux发行版、OSX或Windows作为操作系统。我正从C#转向,所以我想在一定程度上被迫采用Ruby的
以太坊概论考察课更具课堂教学讲解,参考开放资料。使用所学的知识,创建项目并完成要求的内容。包含的功能和要求具体如下:一:安装并运行geth客户端1、下载安装geth首先下载geth:https://geth.ethereum.org/downloads/选择路径↓2、配置环境变量3、运行geth如下命令所示:查看geth命令。使用gethversion查看geth版本号,判断geth是否成功安装。如下命令所示:`gethversion`可以通过geth--help查看geth工具所支持的命令和相关参数,方便后期关于geth的操作。如下命令所示:geth--help运行结果如下:二:搭建get
目录一、下载Elasticsearch1.选择你要下载的Elasticsearch版本二、采用通用搭建集群的方法三、配置三台es1.上传压缩包到任意一台虚拟机中2.解压并修改配置文件(配置单台es)3.配置三台es集群4.设置后台启动和开机自启(可选)一、下载Elasticsearch1.选择你要下载的Elasticsearch版本es下载地址这里我下载的是二、采用通用搭建集群的方法集群搭建方法三、配置三台es1.上传压缩包到任意一台虚拟机中上传方式有两种第一种:使用xftp上传直接拖动过去就可以了。第二种:使用lrzsz先安装yum-yinstalllrzsz切换到要上传的位置cd/opt/