C++ 和 C 的区别主要在8个方面:
我仅对印象不深的地方做了总结。
定义:类型& 引用变量的名称 = 变量名称
'&' 不是取地址符吗,怎么又成为引用了呢?下面将常见的 '&' 做一个区分:
C中的 '&'
c = a && b; //此处 && 是 逻辑与
c = a & b; //此处的 & 是 按位与
int *p = &a; //此处的 & 是 取地址符
int &x = a; //此处的 & 是 引用
void fun(int &a); //此处的 & 也是引用
疑问:int &fun()这个是函数的引用吗?
回答:不是函数的引用,表示函数的返回值是一个引用。
//正确用法:
int a = 10;
int &x = a;
//错误用法:
int &x = a;
int &&y = x;
int &x; //error:不存在空引用
| 引用 | 指针 |
|---|---|
| 必须初始化 | 可以不初始化 |
| 不可为空 | 可以为空 |
| 不能更换目标 | 可以更换目标 |
| 没有二级引用 | 存在二级指针 |
1、引用必须初始化,而指针可以不初始化
int &s; //error:引用没用初始化
int *p; //right:指针不强制初始化
2、引用不可以为空,指针可以为空
int &s = NULL; //error:引用不可以为空,右值必须是已经定义过的变量名
int *p = NULL; //right:可以定义空指针。
int fun_p(int *p)
{
if(p != NULL) //因为指针可以为空,所以在输出前需要判断。
{
cout << *p << endl;
}
return *p;
}
int fun_s(int &s)
{
cout << s << endl; //引用不为空,可以直接输出
return s;
}
3、引用不能改变目标,指针可以更换目标
int main()
{
int a = 20;
int b = 10;
int &s = a;
int *p = &a;
s = b; //引用只能指向初始化时的对象,如果改变,原先对象也跟着改变。
p = &b; //指针可以改变指向的对象,不改变原先对象。
cout << s << endl;
cout << a << endl;
return 0;
}
我们可以能力收缩,不可能力扩展
//error:能力扩展
int a = 10;
int& b = a; //a b c都是一个东西
const int& c = a; //常引用
b += 10;
a += 100; //可以通过a b 去修改a 和 b
//c += 100; //error:不可通过 c 来修改 a 或者 b
//能力收缩
const int a = 100;
int& b = a; //不可编译成功
//a += 100; //error:a 自身不可改变
b += 100;
int a = 100;
const int& x = a; //可以编译成功
引用可以作为函数参数
void Swap(int a, int b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 10, y = 20;
Swap(x, y); //仅仅Swap内部交换,并不能影响到实参
}
//加上引用,对a和b的改变会影响实参
void Swap(int &a, int &b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 10, y = 20;
Swap(x, y); //仅仅Swap内部交换,并不能影响到实参
}
为了解决一些频繁调用小函数消耗大量栈空间的问题,引入了inline内联函数。
inline int fun(int a ,int b)
{
return a + b;
}
处理步骤
int fun(int a,int b)
{
return a + b;
}
//普通调用
int main()
{
int a = 10;
int b = 20;
int c = fun(10,20);
}
//内联函数
int main()
{
int a = 10;
int b = 20;
int c = 10 + 20; //此处相当于直接展开函数
}
内联函数在函数的调用点直接展开代码,没有开栈和清栈的开销。普通函数有开栈和清栈的开销。
内联函数要求代码简单,不能包含复杂的结构控制语句。
若内联函数体过于复杂,编译器将自动把内联函数当成普通函数来执行。
static修饰的函数处理机制只是将函数的符号变成局部符号,函数的处理机制和普通函数相同,都有函数的开栈和清栈的开销。内联函数没有函数的开栈和清栈的开销。
inline函数是因为代码直接在调用点展开导致函数只在本文件可见。而static修饰的函数是因为函数法符号从全局符号变成局部符号导致函数本文件可见。
inline函数的处理时机是在编译阶段处理的,有安全检查和类型检查。而宏的处理是在预编译阶段处理的。没有任何的检查机制,只是简单的文本替换。
inline函数是一种更安全的宏。
代码如下:
inline int Add_Int(int x, int y)
{
return x + y;
}
int main()
{
int a = 10, b = 20;
int c = 0;
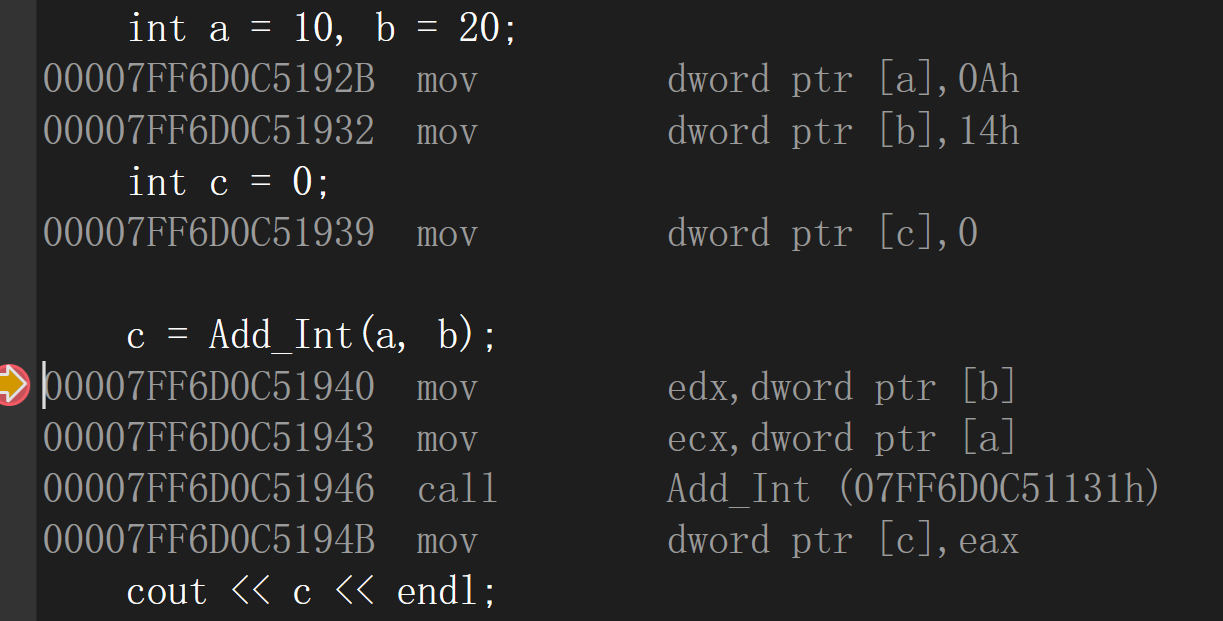
c = Add_Int(a, b);
cout << c << endl;
return 0;
}
debug版本的反汇编:仍是以函数调用的形式
release版本的反汇编:在编译时期展开
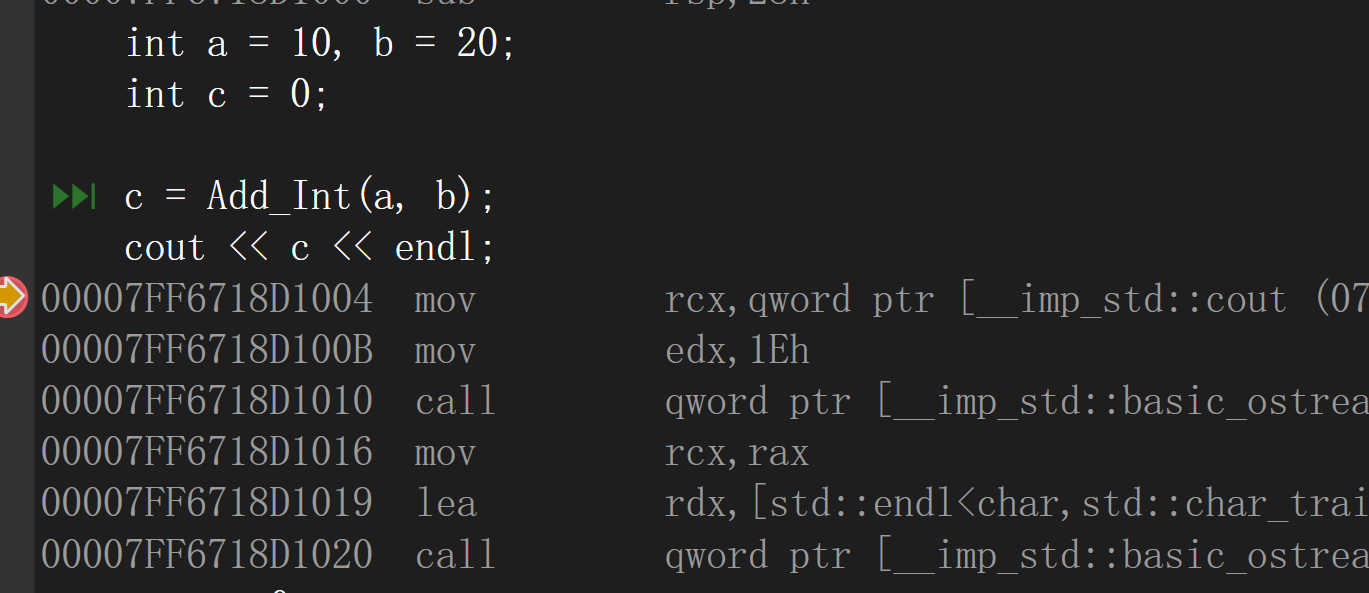
一般写在头文件中
只在release版本中生效
inline只是一个建议,是否处理由编译器决定
如果函数体内的代码比较长,使得内联将导致内存消耗代价比较高。
如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开销大。
基于实现的,不是基于声明的
int fun(int x,int y); // 函数声明
inline int fun(int x,int y) // 函数定义
{
return x+y;
}
// 定义时加inline关键字
inline void fun1(int x)
{
}
在C语言中,函数名 是 函数的唯一标识
在C++中,函数原型 是 函数的标识。
函数原型
函数原型 = 函数返回类型 + 函数名 + 形参列表(参数的类型和个数)
使用extern关键字指定为C语言编译
extern"C" int Max(int a, int b)
{
return a > b ? a : b;
}
extern"C" int fun(int a, int b)
{
return a + b;
}
int main()
{
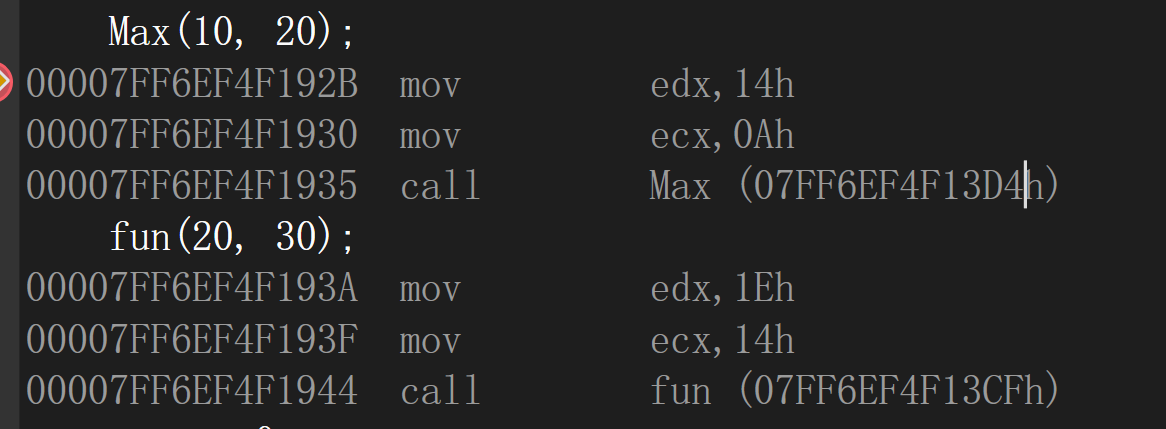
Max(10, 20);
fun(20, 30);
return 0;
}
VS2022中
以C语言编译:函数名仍是原来的函数名
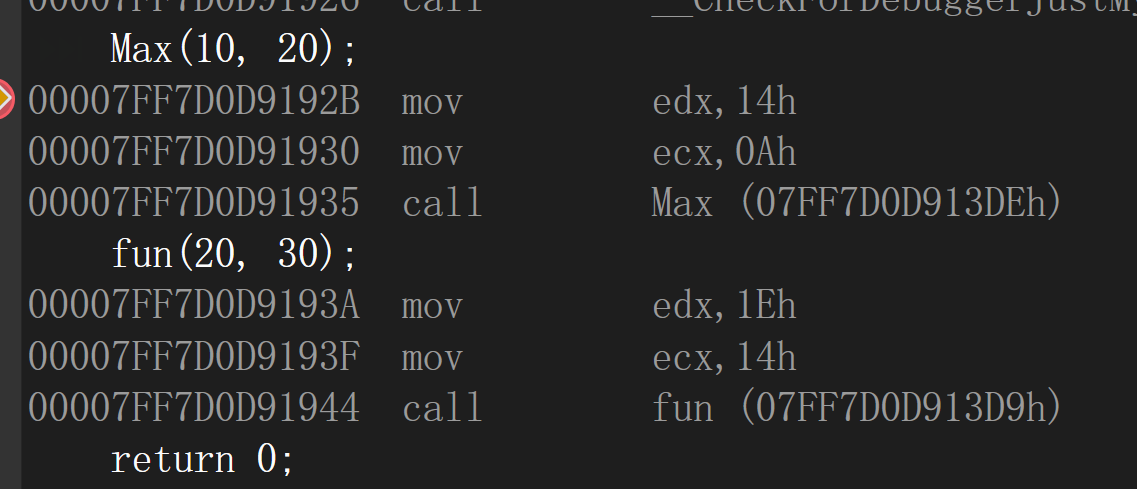
以C++编译:也是一样的情况
将函数的形参类型进行修改:
int Max(int a, int b)
{
return a > b ? a : b;
}
int Max(double a, int b)
{
return a > b ? a : b;
}
int main()
{
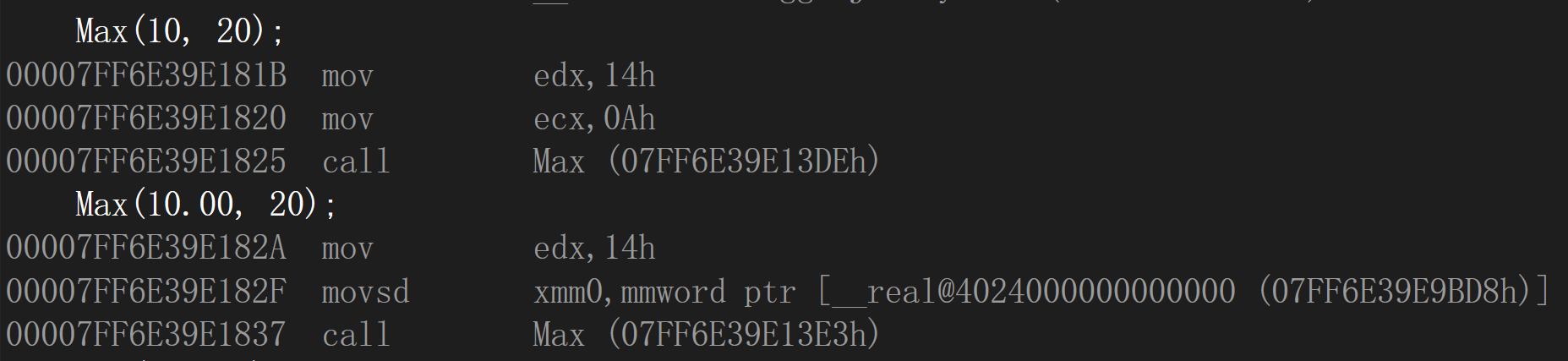
Max(10, 20); //编译正常
Max(10.00, 20); //编译正常
return 0;
}
发现函数名仍是一样,但是存放double类型的寄存器与存放int类型的寄存器不一样
再将返回值类型也进行修改:
int Max(int a, int b)
{
return a > b ? a : b;
}
double Max(double a, int b)
{
return a > b ? a : b;
}
int fun(int a, int b)
{
return a + b;
}
int main()
{
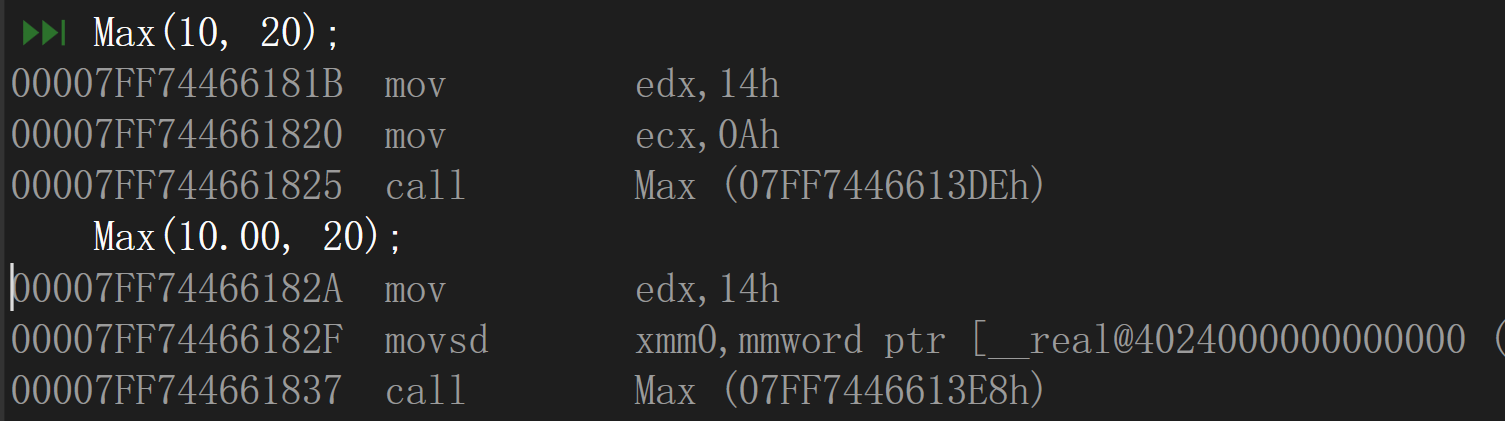
Max(10, 20); //编译正常
Max(10.10, 20); //编译正常
return 0;
}
发现并没有任何问题,调用的也并非是同一个函数
在VS2019中:
以C语言编译:函数名前加 _ ,_fun 和 _Max

以C++编译:没有下划线,与VS2022中C++编译相同
在VC6.0中:
int Max(int a, int b)
{
return a > b ? a : b;
}
double Max(double a, double b)
{
return a > b ? a : b;
}
char Max(char a, char b)
{
return a > b ? a : b;
}
int main()
{
Max(10, 20);
Max(10.0, 10.0);
Max('a','b');
return 0;
}
返回值为int 类型的Max函数:
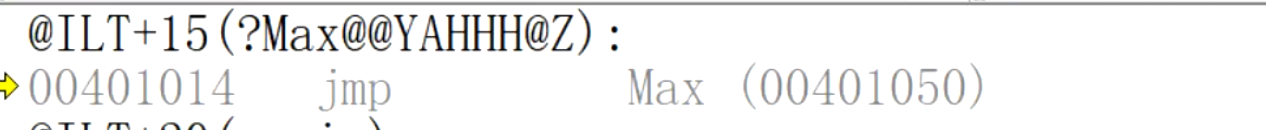
返回值为double类型的Max函数:
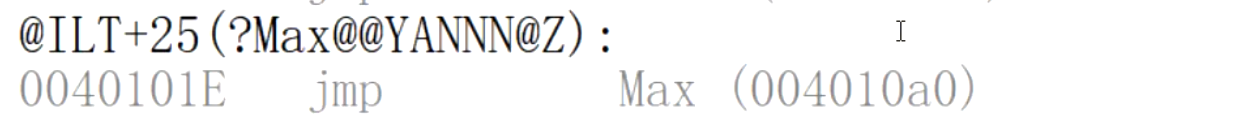
返回值为char类型的Max函数:
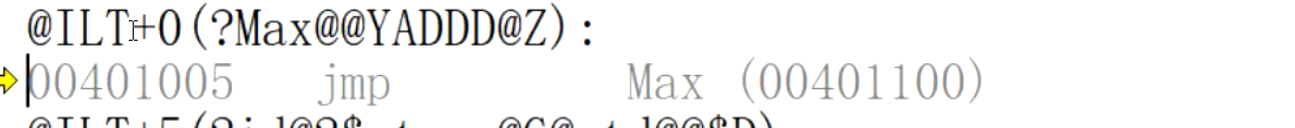
为什么函数名发生了如此大的改变?
这个就是名字粉碎技术
模板的定义:
template <模板参数名>
返回类型 函数名(形式参数表)
{
//函数体
}
<模板参数表> 尖括号中不能为空,参数可以有多个,用,隔开
template<class Type>
void Swap(Type& a, Type& b)
{
Type tmp = a;
a = b;
b = tmp;
}
注意1:<>中只能以C++的方式写,不能出现如 template <struct Type>
注意2:下面调用Swap不是简单的替换(宏替换),是重命名规则
//普通类型
template <class Type> typedef int Type;
void Swap(Type &a ,Type &b) void Swap<int>(Type &a,Type &b)
{ {
Type tmp = a; Type tmp = a;
a = b; a = b;
b = tmp; b = tmp;
} }
int main()
{
int a = 10, b = 20;
Swap(a, b); //此处的调用如同右边函数
}
//指针类型
template<class Type> typedef int Type
void fun(Type p) void fun<int *>(Type p)
{ {
Type a, b; Type a, b;
} }
int main()
{
int x = 10;
int* ip = &x;
fun(ip);
return 0;
}
注意3:编译时进行重命名,非运行时。
//C语言与C++申请空间:
int main()
{
int n = 10;
//C:malloc free
int* ip = (int*)malloc(sizeof(int) * n);
//地址空间与NULl进行对比,判断是否申请失败
if (NULL == ip) exit(1);
free(ip);
ip = NULL;
//C++:new delete
ip = new int;
*ip = 100;
delete ip;
ip = NULL;
}
//new申请连续空间
int main()
{
//new申请连续空间,要释放连续空间
ip = new int[n];
//此处的delete不是把ip删除,而是将ip指向堆区的空间换给系统
delete[]ip;
}
new申请失败时候的处理:
//错误处理:
ip = new int;
if (ip == NULL) exit(1);
delete ip;
ip == NULL;
//new 如果分配内存失败,默认是抛出异常的。
//分配成功时,那么并不会执行 if (ip == NULL)
//若分配失败,也不会执行 if (ip == NULL)
//分配失败时,new 就会抛出异常跳过后面的代码。
//正确处理1:强制不抛出异常
int *ip = new (std::nothrow) int[n];
if (ip == NULL)
{
cout << "error" << endl;
}
//正确处理2:捕捉异常
try
{
int* ip = new int[SIZE];
}
catch (const bad_alloc& e)
{
return -1;
}
仍遗留下很多问题:
0.引言在日常学习和工作中,我们经常需要进行写作,而写作不仅需要语言技巧和文学知识,还需要丰富的素材和思维的深度。随着人工智能技术的发展,ChatGPT等工具已经能够帮助我们解决这一问题。本文将介绍ChatGPT的应用场景以及如何使用它来进行写作。1.话题和题干成年人的心动有多珍贵心动是珍贵的瞬间,它推动我们追求梦想,给我们带来无限的希望。请描述一下你或他人在心动的鼓舞下所做出的努力,并论述心动对成年人生活的重要性。例如,当你爱上一个人的时候,你会有怎样的心动感受;当你为了实现梦想而奋斗时,心动会给你带来怎样的支持。题目自拟,字数800。2.写作思路描写男女邂逅的事情有可能落入俗套。所以,我们
概述BlueALSA(BluetoothAudioALSA)是一种将蓝牙音频设备连接到ALSA音频系统的桥接程序。它提供了一个蓝牙音频设备的ALSA插件,允许使用ALSAAPI直接从蓝牙音频设备读取和写入音频数据,从而使得蓝牙音频设备能够以与其他ALSA兼容设备相同的方式工作。BlueALSA的主要功能如下:ALSA插件:提供一个ALSA插件,可以将蓝牙音频设备映射到ALSA设备节点上,使其可以像其他ALSA设备一样被应用程序使用。音频格式转换:支持将蓝牙音频设备的音频格式转换为ALSA支持的格式,以便在ALSA系统中进行处理和播放。延迟控制:提供了延迟控制机制,以便在数据传输过程中进行延迟控
目录前言MySQL是什么?MySQL版本表的概念表中的列和数据类型行主键什么是SQL实践操作小结前言周所周知MySQL已成为全世界最受欢迎的数据库之一。无论你用的何种编程语言在开发系统,数据库基本上都是必不可少的。无论是小型项目开发如我们开发一个个人博客系统,还是构建那些声名显赫的网站如某宝、某讯等,MySQL都有着稳定、可靠、快速等优点。可以胜任数据存储的业务需求。我们今天就来一探MySQL,走入MySQL。MySQL是什么?数据库是以某种有组织的方式保存数据的容器,我们可以将其理解为一个文件柜。我们常见的容器有Oracle、DB2、SQLServer、Postgresql、mongodb等
谈到无人机/无人车仿真,首先想到的大概就是gazebo,但现在都快进入元宇宙时代了(手动狗头),还再继续使用gazebo这种上个时代的产品就显得不够hack,是时候了解和学习下新事物--Airsim了。Airsim是由微软开源的无人机/无人车仿真工具,其本质是UE4(虚幻引擎)的一个插件,所以Airsim可以在任何UE4的3D场景地图中运行,可以充分利用epic商城提供的免费、付费地图。在我探索Airsim的几周来,发现Airsim的优点在于:1、PX4支持,并且支持其他多种飞行模式。2、Python支持完善,官方提供大量pythondemo,可以快速进行算法可行性验证。3、开箱即用,几乎内置
说到虚拟化,大家最先联想到的几个名词应该是虚拟机,服务器。今天要介绍的虚拟化,是路由与交换技术里面的虚拟化技术。在网络上,将多个网络设备虚拟化成一个整体的逻辑设备的技术,就称为虚拟化技术。通过交换机虚拟化技术,既可以在逻辑上集成多台物理连接的交换机,实现拓宽虚拟交换机带宽、提升转发效率的目的,也可以在逻辑上将一台物理交换机虚拟为多台虚拟交换机,实现业务隔离、提升可靠性的目的。虚拟化有横向虚拟化和纵向虚拟化,其中横行虚拟化技术常用的有堆叠、m-lag,vrrp。今天我们主要了解下m-lag技术。了解m-lag之前,我们先了解下以往数据中心常用的横向虚拟化技术-堆叠。从上图我们可以看到堆叠就是将两
背景 在一些业务场景中,会有如下的一些要求:比如有用户需要将Mp4视频转为Gif动图。当然有一些小伙伴说可以使用系统截图,然后使用之前提到过的技术:GIF图像动态生成-JAVA后台生成。需要处理的素材比较少,就一两个视频,确实可以通过这种方式来处理。试想一下,如果需要处理上百个,做处理的小伙伴是不是就抓狂了,这完全是实打实的工作量。那有没有直接从Mp4转成gif动态图的技术呢?运营的小伙伴就能按时下班了。 经过一番查询,找到一些思路,Mp4视频的组成也是一帧一帧的图像组成的。如果有什么技术可以去动态获取这些数据,通过动态截取每一帧,最后再合成图片。不久解决了吗?FFmpeg变进入技
Web3.0初探一个基于区块链技术用户主导、去中心化的网络生态Web3.0:致力打造一个基于区块链技术、用户主导、去中心化的网络生态。在Web3.0中,用户为满足自身需求进行交互操作,并在交互中利用区块链技术,从而实现价值的创造、分配与流通。这样的整个用户交互、价值流通的过程就形成了Web3.0生态。相比Web2.0的平台中心化特征,Web3.0致力于实现用户所有、用户共建的“去中心化”网络生态。 Web3.0生态主要组成要素及特点:1)用户身份:传统中心化身份容易产生安全和隐私风险,web3构建了一个去中心化的身份标识,以DID作为web3的用户身份表现形式;2)组织形式:web3的核心观点
🔥一个人走得远了,就会忘记自己为了什么而出发,希望你可以不忘初心,不要随波逐流,一直走下去🎶🦋欢迎关注🖱点赞👍收藏🌟留言🐾🦄本文由程序喵正在路上原创,CSDN首发!💖系列专栏:JavaWeb从入门到实战🌠首发时间:2022年8月18日✅如果觉得博主的文章还不错的话,希望小伙伴们三连支持一下哦阅读指南一、JavaWeb介绍二、数据库相关概念三、MySQL数据库MySQL安装MySQL配置MySQL登录、退出MySQL卸载MySQL数据模型四、SQL概述SQL简介SQL通用语法SQL分类五、DDL--数据定义语言DDL--操作数据库DDL--操作表六、navicatnavicat概述navicat
夜莺初探三·Categraf采集器前言github仓库文档中对Categraf有很详细的介绍,简单重复一下就是:支持多种数据格式的remote_write;All-in-one的设计理念,指标采集只需要一个agent完成,也计划支持日志和调用链路的数据采集;Go编写,依赖少,容易分发和安装;内置一些监控大盘和告警规则,用户可以直接导入使用;开源项目并由快猫研发团队持续迭代。特殊目录结构说明input采集插件基本都位于input目录下,并且有些采集器提供了通用的大盘(alters-xxx.json)和告警(dashbord.json)配置可以导入n9e直接使用(例如监控仪表盘中更多操作的批量导入
本文目标:了解TRTC的基本概念初步运行demo调用API完成进入视频房间完成多人进入同一房间一、腾讯TRTC可能有些同学并不知道RTC的相关概念,这里先简单说一下。WebRTC(webReal-TimeCommunication)是指网站实时音视频通话技术。这项技术允许网络应用或者网络站点,在不借助任何中间媒介和第三方工具的情况下,建立浏览器之间点对点(Peer-to-Peer)的连接,实现视频流和音频流或者其他任意数据的传输,感兴趣的小伙伴可以自行搜索了解下。TRTC(TencentReal-TimeCommunication)是腾讯业务中的一项,也是WebRTC的一种实现。TRTC主要提