Spark读取JDBC调优,如何调参
实际问题:工作中需要读取一个存放了三四年历史数据的pg数仓表(缺少主键id),需要将数据同步到阿里云
MC中,Spark在使用JDBC读取关系型数据库时,默认只开启一个task去执行,性能低下,因此需要通过设置一些参数来提高并发度。一定要充分理解参数的含义,否则可能会因为配置不当导致数据倾斜!
翻看了网络上好多相关介绍,都沾边。下边总结一下!
您是菜鸟就好好学习,您是大佬欢迎提出修改意见!
以100行数据为例(实际307983条):
CREATE TABLE IF NOT EXISTS test(
good_id STRING ,
title STRING ,
sellcount BIGINT,
salesamount Double
)COMMENT '测试表'
PARTITIONED BY (
dt STRING COMMENT '分区字段'
);
insert into test partition (dt = '202001')
values ('1001','卫衣',1,100.1),('1002','卫裤',2,101.2),('1003','拖鞋',3,10.3)...,('1100','帽子',100,19.23)
配置文件示例:
jdbc: &jdbc
options.url: "jdbc:postgresql://xxx.xxx.xxx.xxx:8000/postgres"
options.user: "xxxxxx"
options.password: "xxxxxx"
options.driver: "org.postgresql.Driver"
input:
- moduleClass: "JDBC"
<<: *jdbc
options.dbtable: "SELECT *,cast(good_id as bigint)*1%6 mo FROM test.test where dt = '202001'"
options.fetchsize: "100"
options.partitionColumn: "mo" # 分区列,一般为自增id,下边解释下为啥用mo
options.numPartitions: "6" #分区数
options.lowerBound: "0"
options.mytime: "${yyyy}-${MM}-${dd}"
options.upperBound: "6" # 该值设置为和分区列最大值差不多的值
resultDF: "df"
提交spark配置
spark-submit \
--class xx.xxx.xxx.xxx \
--master local[*] \
--num-executors 6 \
--executor-cores 1 \
--executor-memory 2G \
--driver-memory 4G \
/root/test/xxx.jar \
-p xxx/xxx.yaml -cyctime $cyctime
options.fetchsize:一次性读取的数据条数,按集群规模(例:64核128G)一次1000条;阿里云Spark集群链接不了华为云pg数仓,我开了一台独立机器(8核16G)一次100条
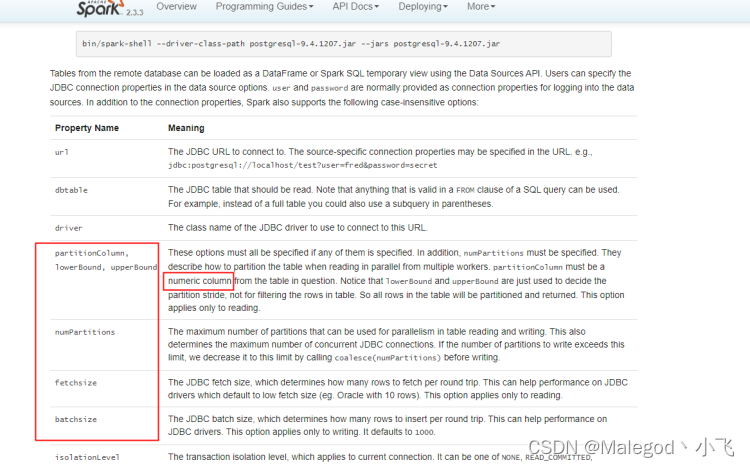
options.partitionColumn:分区列,必须是bigint类型;
options.numPartitions:设置分区数,最好和spark提交的executors数一致;上文中spark任务数为6,分区数也为6
options.lowerBound:分区开始值
options.upperBound:分区结束值;numPartitions、lowerBound、upperBound这三个必须同时设置,每个分区的数据量计算公式为:upperBound / numPartitions - lowerBound / numPartitions,任务运行时间看的是最长的那个任务,所以要尽可能保证每一个分区的数据量差不多
官方配置文档:
有的小伙伴就该思考为啥不用自增id做分区列呢?
因为实际生产环境中,一是不需要,二是创建表忽略了自增id等等。
为啥要新做一列mo,而不直接将商品id转bigint用呢?
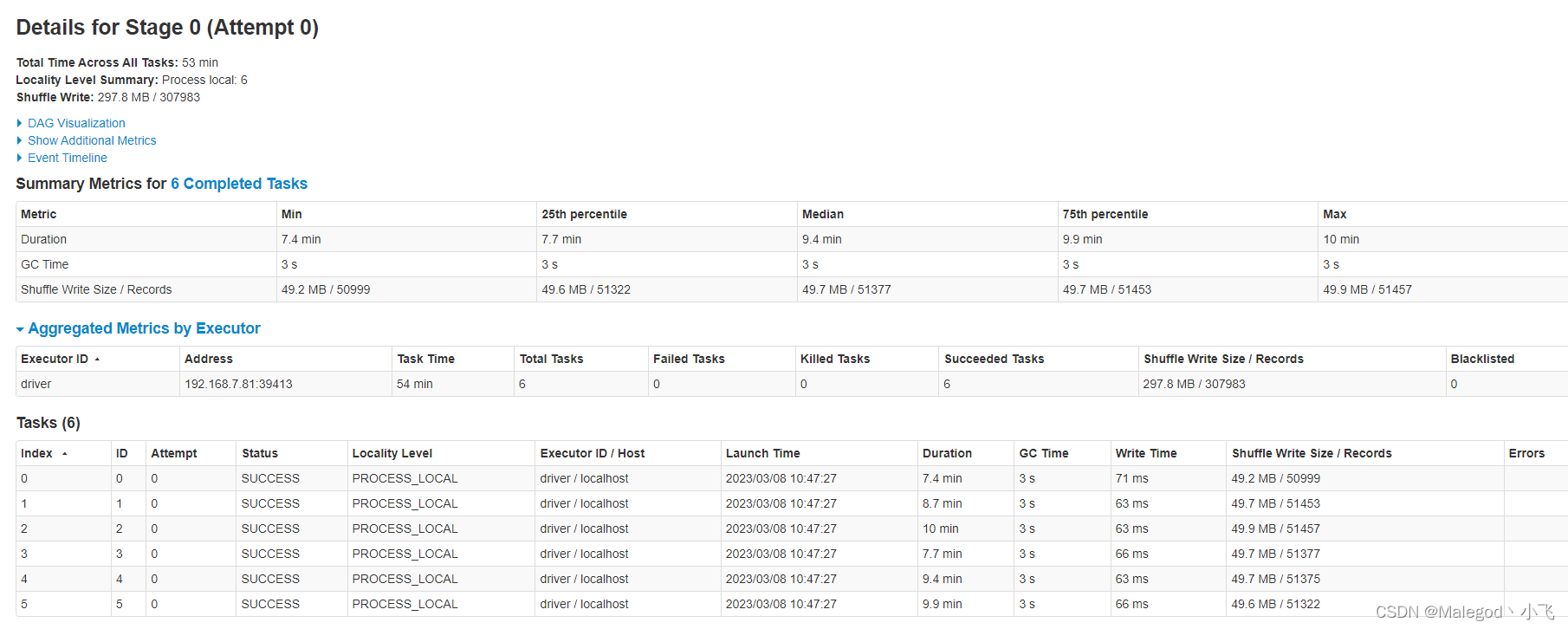
算是一个补救措施,新做一个数据列,在读取过程用mo做shuffle,mo是商品id强转为bigint后对6取膜,结果为0-5共6种可能,提高了shuffle的效率,计算分区的数据量:6 / 6 - 0 / 6 = 1;也就是说分区值为0,1,2,3,4,(大于5),对应6个任务,6个核心。
下面是运行shuffle结束后的截图,可以看到每一个task获取的数据量都比较均匀
下面来看一个错误的案例:
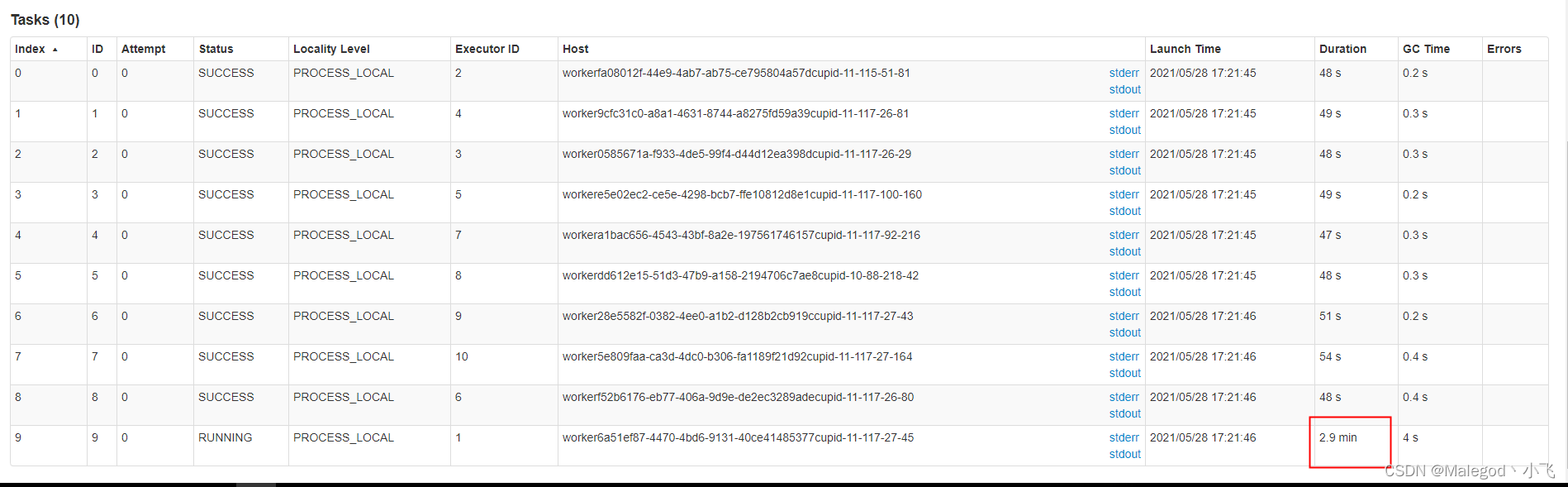
上图配置就会导致数据倾斜
numPartitions=10,
lowerBound=0,
upperBound=100,
表的数据量是1000。
根据计算公式每个分区的数据量是100/10-0/10=10,分10个区,那么前9个分区数据量都是10,但最后一个分区数据量却达到了910,即数据倾斜了,所以upperBound-lowerBound要和表的分区字段最大值差不多
有啥需要优化的欢迎评论纠正
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
s=Socket.new(Socket::AF_INET,Socket::SOCK_STREAM,0)s.connect(Socket.pack_sockaddr_in('port','hostname'))ssl=OpenSSL::SSL::SSLSocket.new(s,sslcert)ssl.connect从这里开始,如果ssl连接和底层套接字仍然是ESTABLISHED,或者它是否在默认值7200之后进入CLOSE_WAIT,我想检查一个线程几秒钟甚至更糟的是在实际上不需要.write()或.read()的情况下关闭。是用select()、IO.select()还是其他方法完成
在Ruby1.9中,我如何从ARGF中读取CSV?我尝试了以下方法,但没有打印任何内容:require'csv'CSV(ARGF).readdo|row|prowendhttp://www.ruby-doc.org/core-1.9.3/ARGF.htmlhttp://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV.html 最佳答案 如果你想偷懒你可以试试:CSV.new(ARGF.file).eachdo|row|...end来源:http://www.ruby-doc.org/std
我正在编写一个ruby程序,它应该执行另一个程序,通过stdin向它传递值,从它的stdout读取响应,然后打印响应。这是我目前所拥有的。#!/usr/bin/envrubyrequire'open3'stdin,stdout,stderr=Open3.popen3('./MyProgram')stdin.puts"helloworld!"output=stdout.readerrors=stderr.readstdin.closestdout.closestderr.closeputs"Output:"puts"-------"putsoutputputs"\nErrors:"p
我们如何从ruby脚本返回值?#!/usr/bin/envrubya="test"a我们如何在Ubuntu终端或java或c中访问'a'的值? 最佳答案 在ruby/python脚本中打印你的变量,然后可以通过示例从shell脚本中读取它:#!/bin/bashruby_var=$(rubymyrubyscript.rb)python_var=$(pythonmypythonscript.py)echo"$ruby_var"echo"$python_var"注意你的ruby/python脚本只打印这个变量(有更多复杂的方
有没有办法将RubyVM::InstructionSequence存储到文件中并稍后读取?我尝试了Marshal.dump但没有成功。我收到以下错误:`dump':no_dump_dataisdefinedforclassRubyVM::InstructionSequence(TypeError) 最佳答案 是的,有办法。首先,您需要使InstructionSequence的load方法可访问,默认情况下该方法是禁用的:require'fiddle'classRubyVM::InstructionSequence#RetrieveR