 即使这种新技术会拖累 CPU 频率,相比 5800X,5800X3D 还是在游戏中获得超过 10% 的平均帧数提升,同时提高最低帧,减少卡顿。来自远古时代装机猿 ▼
即使这种新技术会拖累 CPU 频率,相比 5800X,5800X3D 还是在游戏中获得超过 10% 的平均帧数提升,同时提高最低帧,减少卡顿。来自远古时代装机猿 ▼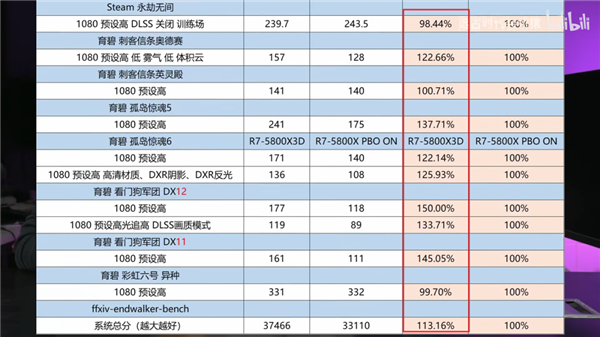 主频降低了,但是游戏帧数却提升了?没错,3D V-Cache 就是这么神奇。由于这款 CPU 的游戏性能太好,价格也很便宜,在红蓝两家的新一代处理器发布后,5800X3D 仍然长期热销。不过就在今天, AMD 正式解禁了它的 Zen4 架构继任者:锐龙 7000X3D 系列。这次提前拿到了其中的顶配款,锐龙9 7950X3D。7950X3D 同样是一款“ 划时代 ”的 CPU :在 Intel 之后,AMD 也开始拥抱“ 异构 ”的 X86 处理器。与 Intel 的“ 大小核 ”不同,它的异构表现在缓存上:在 16 个核心中,有 8 个配备了 3D V-Cache( 垂直缓存 ),频率较低;另外 8 个则是普通核心,能上到和原版 7950X 一样的 5.7GHz 高频。
主频降低了,但是游戏帧数却提升了?没错,3D V-Cache 就是这么神奇。由于这款 CPU 的游戏性能太好,价格也很便宜,在红蓝两家的新一代处理器发布后,5800X3D 仍然长期热销。不过就在今天, AMD 正式解禁了它的 Zen4 架构继任者:锐龙 7000X3D 系列。这次提前拿到了其中的顶配款,锐龙9 7950X3D。7950X3D 同样是一款“ 划时代 ”的 CPU :在 Intel 之后,AMD 也开始拥抱“ 异构 ”的 X86 处理器。与 Intel 的“ 大小核 ”不同,它的异构表现在缓存上:在 16 个核心中,有 8 个配备了 3D V-Cache( 垂直缓存 ),频率较低;另外 8 个则是普通核心,能上到和原版 7950X 一样的 5.7GHz 高频。 经过和 AMD 小伙伴的 PY,他们给我们开放了在电脑上手动分配线程的权限。所以我试了试分别在 “ 3D V-Cache核心 ” 和 “ 高频核心 ” 上各跑了一把 CineBench R23,发现 “ 高频核心 ” 的表现和普通 7950X 的得分差不多。挂载了 3D V-Cache的 “ 游戏核心 ” 则的确理论性能会有减弱,得分大概低了 10% 左右。
经过和 AMD 小伙伴的 PY,他们给我们开放了在电脑上手动分配线程的权限。所以我试了试分别在 “ 3D V-Cache核心 ” 和 “ 高频核心 ” 上各跑了一把 CineBench R23,发现 “ 高频核心 ” 的表现和普通 7950X 的得分差不多。挂载了 3D V-Cache的 “ 游戏核心 ” 则的确理论性能会有减弱,得分大概低了 10% 左右。 假如 AMD 这波调度得当的话,那么以后大概会是这么个情形:碰到游戏这种吃大缓存的程序,它就优先拿带 3D V-Cache 的核心跑;碰到单线程跑分、渲染等需要“ 硬性能 ”的任务,它就优先拿性能( 频率 )更高的普通核心跑。这样游戏党满意,生产力用户也满意,真是个天才办法!想法很美好,但是上一个这么想的友商,名声不能算是白璧无瑕。只能说是褒贬不一吧。
假如 AMD 这波调度得当的话,那么以后大概会是这么个情形:碰到游戏这种吃大缓存的程序,它就优先拿带 3D V-Cache 的核心跑;碰到单线程跑分、渲染等需要“ 硬性能 ”的任务,它就优先拿性能( 频率 )更高的普通核心跑。这样游戏党满意,生产力用户也满意,真是个天才办法!想法很美好,但是上一个这么想的友商,名声不能算是白璧无瑕。只能说是褒贬不一吧。 异构处理器的优化,Wintel 都把握不住,AMD 能搞好吗?开机看看呗。一上手托尼就发现,AMD 没搞英特尔那一套。即使是关系紧密的 Wintel 联盟,大小核调度还迟迟搞不定。AMD 和巨硬“ 勾结 ”的明显还不够,让 Windows 去调度他家的异构 CPU,搞不好得开不了机。
异构处理器的优化,Wintel 都把握不住,AMD 能搞好吗?开机看看呗。一上手托尼就发现,AMD 没搞英特尔那一套。即使是关系紧密的 Wintel 联盟,大小核调度还迟迟搞不定。AMD 和巨硬“ 勾结 ”的明显还不够,让 Windows 去调度他家的异构 CPU,搞不好得开不了机。 所以看起来 AMD 决定自力更生,在主板驱动里自己写一套调度方案。
所以看起来 AMD 决定自力更生,在主板驱动里自己写一套调度方案。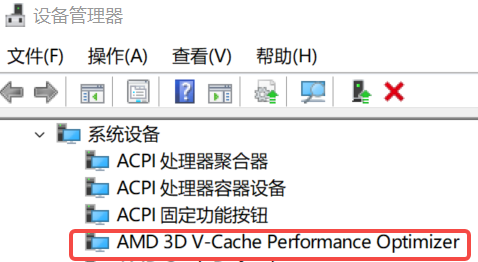 AMD 亲自调试,意味着可以自行把握优化节奏,而不必被 Windows 拖下水。不过话说回来,10% 的差异,就算分配错了估计大家也发现不了。不会吧不会吧,不会真有人开着一堆监控软件打游戏吧。托尼测试游戏时的图 ▼
AMD 亲自调试,意味着可以自行把握优化节奏,而不必被 Windows 拖下水。不过话说回来,10% 的差异,就算分配错了估计大家也发现不了。不会吧不会吧,不会真有人开着一堆监控软件打游戏吧。托尼测试游戏时的图 ▼ 虽说理论上是这样,具体能不能做好,还是要看看实际情况。老规矩,先介绍一下测试平台。13900KS 现价 5799,7950X3D 首发价 5399 ▼
虽说理论上是这样,具体能不能做好,还是要看看实际情况。老规矩,先介绍一下测试平台。13900KS 现价 5799,7950X3D 首发价 5399 ▼ 由于我们的 4090 抽奖送走了,所以挑大梁的显卡是 7900XTX。真的是一滴也没有了。
由于我们的 4090 抽奖送走了,所以挑大梁的显卡是 7900XTX。真的是一滴也没有了。 既然是测试处理器,那就首先上一个 CineBench R23 成绩,看看 7950X3D 的理论性能,到底是个什么水平。7950X 数据来自 cpu-monkey ▼
既然是测试处理器,那就首先上一个 CineBench R23 成绩,看看 7950X3D 的理论性能,到底是个什么水平。7950X 数据来自 cpu-monkey ▼ 只看核心设计的话,7950X3D 和 7950X 是一样的,单核都是 2000 多分 —— 看来内置调度器工作正常。但是整体的多核性能上却有着 7% 的降幅。emmmm 看得出来,3D V-Cache 并不是没有代价的魔法。假如 AMD 这次不搞 “ 异构 ”,那剪辑、渲染一类的 “ 非游戏工程 ”,可能真的会讨不到好。对缓存大小不太敏感的三维设计软件 Blender,也差不多是这么个情况。7950X 数据来自 Blender 官方数据库 ▼
只看核心设计的话,7950X3D 和 7950X 是一样的,单核都是 2000 多分 —— 看来内置调度器工作正常。但是整体的多核性能上却有着 7% 的降幅。emmmm 看得出来,3D V-Cache 并不是没有代价的魔法。假如 AMD 这次不搞 “ 异构 ”,那剪辑、渲染一类的 “ 非游戏工程 ”,可能真的会讨不到好。对缓存大小不太敏感的三维设计软件 Blender,也差不多是这么个情况。7950X 数据来自 Blender 官方数据库 ▼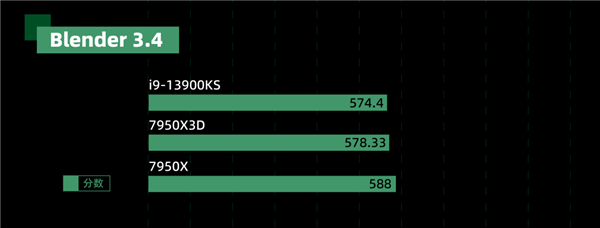 在不需要超大 3D 缓存的“ 硬算 ”方面,这款 X3D 处理器也就是和 13900KS 打个五五开,“ 异构 ”设计让它比上代 5800X3D 要强,但也就那样~然而,等到了游戏环节,这块 7950X3D 就要施展神迹了。我先说结论:牛x,非常牛x!!!先跑个新出的的霍格沃兹,毕竟大家买新 U,肯定要玩新游戏的嘛。
在不需要超大 3D 缓存的“ 硬算 ”方面,这款 X3D 处理器也就是和 13900KS 打个五五开,“ 异构 ”设计让它比上代 5800X3D 要强,但也就那样~然而,等到了游戏环节,这块 7950X3D 就要施展神迹了。我先说结论:牛x,非常牛x!!!先跑个新出的的霍格沃兹,毕竟大家买新 U,肯定要玩新游戏的嘛。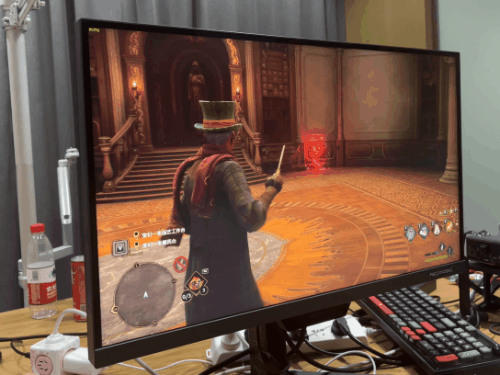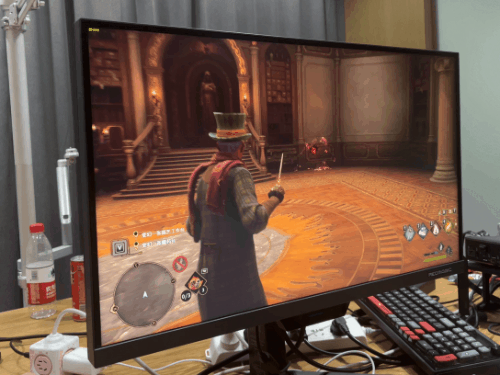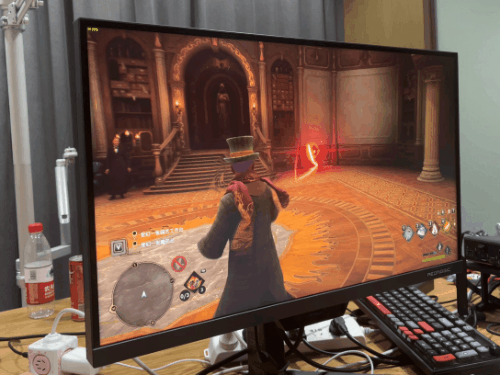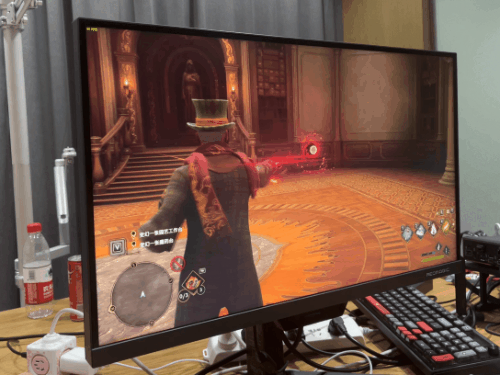 不过不得不说,霍格沃茨不愧是新一代优化黑洞,两边的 1% Low 帧都一样。不过 7950X3D 的平均帧还是比它更贵的 13900KS 高了 10 帧。
不过不得不说,霍格沃茨不愧是新一代优化黑洞,两边的 1% Low 帧都一样。不过 7950X3D 的平均帧还是比它更贵的 13900KS 高了 10 帧。 算了,我们还是换点儿大家耳熟能详的大众游戏吧。比如老牌 “ CPU Benchmark 软件 ” 。CS:GO?
算了,我们还是换点儿大家耳熟能详的大众游戏吧。比如老牌 “ CPU Benchmark 软件 ” 。CS:GO? 不出所料,7950X3D 靠着巨大的缓存, 700+ 的平均帧就不说了,我这辈子还没用过刷新率这么高的显示器。关键是 1% 低帧,这玩意是会真真切切反映在游戏卡顿上的。7950X3D 运行 CS:GO 的 1% Low 帧是……228.8!比 13900KS 高了 27%!就算是低帧,也基本是贴着 240Hz 的电竞屏飞行了。相当离谱。
不出所料,7950X3D 靠着巨大的缓存, 700+ 的平均帧就不说了,我这辈子还没用过刷新率这么高的显示器。关键是 1% 低帧,这玩意是会真真切切反映在游戏卡顿上的。7950X3D 运行 CS:GO 的 1% Low 帧是……228.8!比 13900KS 高了 27%!就算是低帧,也基本是贴着 240Hz 的电竞屏飞行了。相当离谱。 就仿佛是开胃菜一般,CS:GO 之后,潘多拉的小盒子就打开了。在 Dota 2 中,同一场 Knights 的录像,7950X3D 无论是平均帧还是低帧,都远远超过 13900KS。
就仿佛是开胃菜一般,CS:GO 之后,潘多拉的小盒子就打开了。在 Dota 2 中,同一场 Knights 的录像,7950X3D 无论是平均帧还是低帧,都远远超过 13900KS。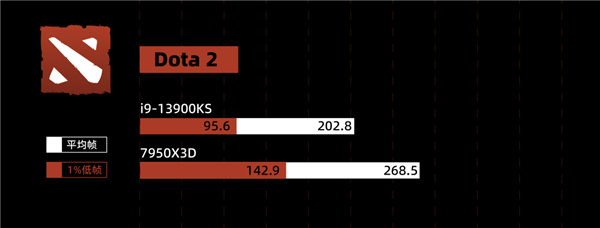 尽管论跑分、剪片,7950X3D 比 13900KS 差了百分之几。但是一到游戏环节,这玩意就彻底反杀了。这帧率高的,我一度怀疑我眼睛有问题!
尽管论跑分、剪片,7950X3D 比 13900KS 差了百分之几。但是一到游戏环节,这玩意就彻底反杀了。这帧率高的,我一度怀疑我眼睛有问题! 看了几款老牌电竞之后,我们再看个 “ 电竞新秀 ”,Apex。好吧,好像也没那么新。
看了几款老牌电竞之后,我们再看个 “ 电竞新秀 ”,Apex。好吧,好像也没那么新。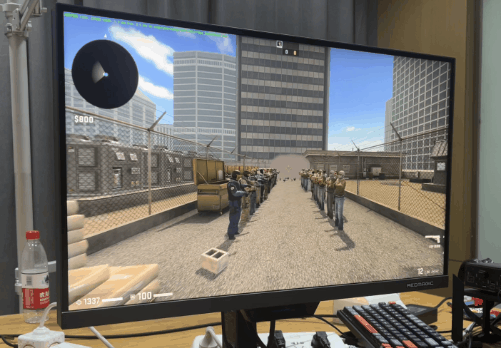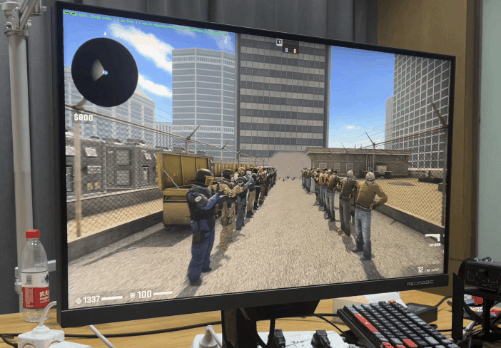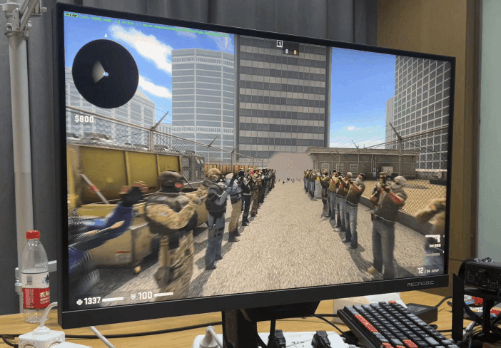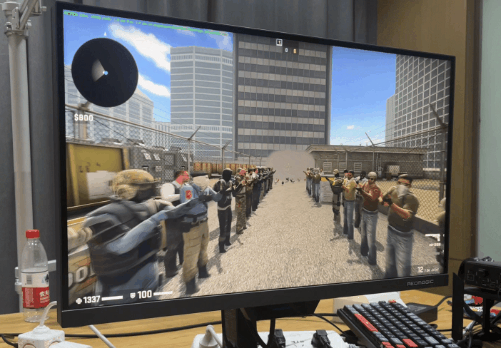 由于 Apex 锁 300 帧,所以只有 1% 低帧才有意义。我已经帮大家算完了,7950X3D 比 13900KS 高了 11%
由于 Apex 锁 300 帧,所以只有 1% 低帧才有意义。我已经帮大家算完了,7950X3D 比 13900KS 高了 11%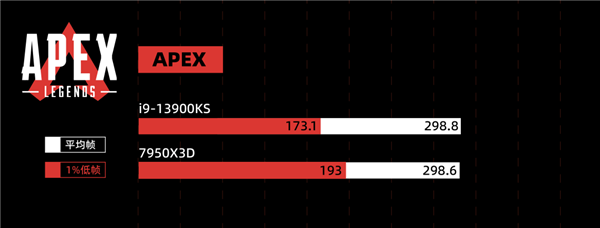 目前看下来,7950X3D 在电竞游戏里面优势,确实有点儿强。不过只说电竞还是有点儿单一了,所以评测环节的最后,我打算祭出一款 “ CPUの毁灭者,优化の反向大师 ” ——城市:天际线。我们专门下载了一个国内大神做的宜春市存档,模拟游戏后期巨大的 CPU 压力。这光,这楼,这城市规模,有没有感觉到 CPU 的心潮澎湃?
目前看下来,7950X3D 在电竞游戏里面优势,确实有点儿强。不过只说电竞还是有点儿单一了,所以评测环节的最后,我打算祭出一款 “ CPUの毁灭者,优化の反向大师 ” ——城市:天际线。我们专门下载了一个国内大神做的宜春市存档,模拟游戏后期巨大的 CPU 压力。这光,这楼,这城市规模,有没有感觉到 CPU 的心潮澎湃?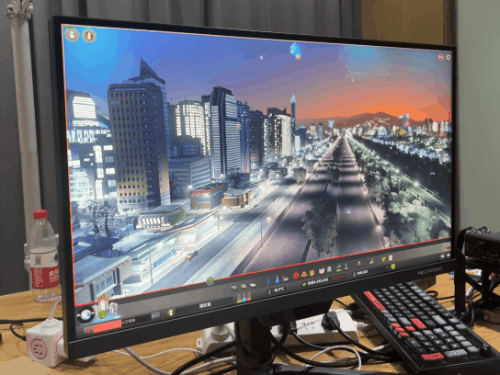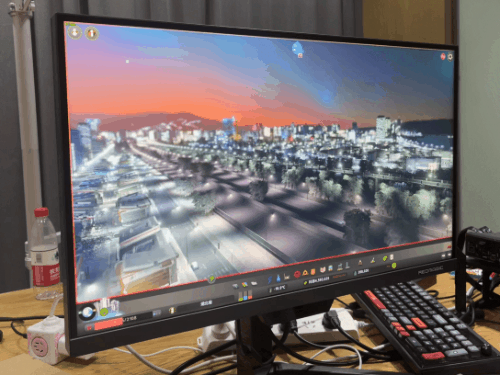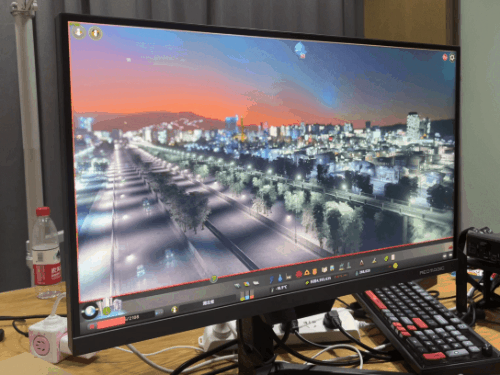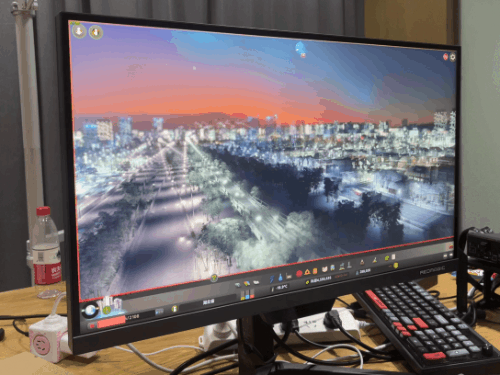 果不其然,即使是旗舰级 CPU 也干不到 60 帧。
果不其然,即使是旗舰级 CPU 也干不到 60 帧。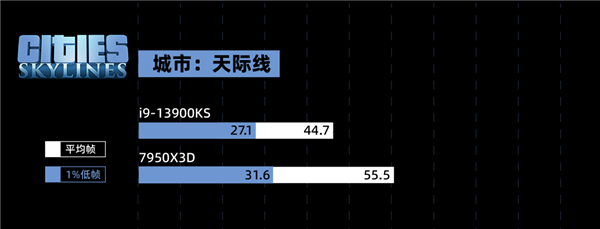 不过,AMD 的 3D V-Cache 又一次的证明了它的实力。7950X3D 再次力压 13900KS 一头。3D V-Cache NB!在讨 “ 打游戏的 ” 欢心上,红厂也开始懂了嘛。其实,本来按照我们的计划,可能还会再额外多测一些 “ 生产力 ” 环节的跑分,看看异构之后的 “ X3D ” 能不能兼任打工人的好帮手。不过由于时间有限,我们就还是先可着游戏测了 —— 目前看来,这块 U 在游戏环节稳得一批。调度器也工作正常 —— 假如异构调度翻车了,那 7950X3D 的游戏帧率早就被 13900KS 反超了。
不过,AMD 的 3D V-Cache 又一次的证明了它的实力。7950X3D 再次力压 13900KS 一头。3D V-Cache NB!在讨 “ 打游戏的 ” 欢心上,红厂也开始懂了嘛。其实,本来按照我们的计划,可能还会再额外多测一些 “ 生产力 ” 环节的跑分,看看异构之后的 “ X3D ” 能不能兼任打工人的好帮手。不过由于时间有限,我们就还是先可着游戏测了 —— 目前看来,这块 U 在游戏环节稳得一批。调度器也工作正常 —— 假如异构调度翻车了,那 7950X3D 的游戏帧率早就被 13900KS 反超了。 总而言之,7950X3D 作为苏妈的又一力作,在仅仅牺牲了一点点 “ 硬性能 ” 的情况下,就给我们端上来了一款 “ 游戏好 U ”。我们跑的这几款游戏,7950X3D 的平均帧几乎都比 13900KS 高。平均帧差不多的,7950X3D 的稳帧水平也相当离谱,1% Low 帧的水平颇有去年 12 代酷睿打 5000 系锐龙的盛况在。而且价格,官方说了,7950X3D(8+8核)要 5299,7900X3D(6+6核)要 4499。乍一看,不便宜;但是跟英特尔一比,就便宜了。不过现在英特尔在电商平台板 U 搭配的套餐卖的都挺便宜的,不知道苏妈这次 X3D 系列的板 U 套餐价格会不会也一样美丽。
总而言之,7950X3D 作为苏妈的又一力作,在仅仅牺牲了一点点 “ 硬性能 ” 的情况下,就给我们端上来了一款 “ 游戏好 U ”。我们跑的这几款游戏,7950X3D 的平均帧几乎都比 13900KS 高。平均帧差不多的,7950X3D 的稳帧水平也相当离谱,1% Low 帧的水平颇有去年 12 代酷睿打 5000 系锐龙的盛况在。而且价格,官方说了,7950X3D(8+8核)要 5299,7900X3D(6+6核)要 4499。乍一看,不便宜;但是跟英特尔一比,就便宜了。不过现在英特尔在电商平台板 U 搭配的套餐卖的都挺便宜的,不知道苏妈这次 X3D 系列的板 U 套餐价格会不会也一样美丽。 假如你现在正好还没配电脑,那我觉得这次的 7950X3D 真的可以冲 —— 它的游戏性能真的是。太感人了!不过假如你现在的电脑还没坏,只是考虑想升级下配置,那我觉得你可以再观望观望。因为据小道消息说,过一阵还会再来一款名叫 7800X3D 的小甜点。虽然是小甜点,但缓存性能据说比它这次首发的两个大哥更好。
假如你现在正好还没配电脑,那我觉得这次的 7950X3D 真的可以冲 —— 它的游戏性能真的是。太感人了!不过假如你现在的电脑还没坏,只是考虑想升级下配置,那我觉得你可以再观望观望。因为据小道消息说,过一阵还会再来一款名叫 7800X3D 的小甜点。虽然是小甜点,但缓存性能据说比它这次首发的两个大哥更好。 更何况现在的内存和固态硬盘还在跌呢,即使小道消息信不得真,但等等党也绝对不亏。Anyway,这次的苏妈,真的是 YES 了。
更何况现在的内存和固态硬盘还在跌呢,即使小道消息信不得真,但等等党也绝对不亏。Anyway,这次的苏妈,真的是 YES 了。 无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion是否有适用于这些的3d游戏引擎?
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
我对为我的RubyonRails3.1.3应用优化我的Unicorn设置的方法很感兴趣。我目前正在高CPU超大实例上生成14个工作进程,因为我的应用程序在负载测试期间似乎受CPU限制。在模拟负载测试中,每秒大约20个请求重放请求,我的实例上的所有8个内核都达到峰值,盒子负载飙升至7-8个。每个unicorn实例使用大约56-60%的CPU。我很好奇可以通过哪些方式对其进行优化?我希望能够每秒将更多请求汇集到这种大小的实例上。内存和所有其他I/O一样完全正常。在我的测试过程中,CPU越来越低。 最佳答案 如果您受CPU限制,您希望使用
假设我希望Ruby进程使用的CPU不超过15%。是否可以?怎么办? 最佳答案 您可以尝试使用Process.setrlimit来自标准核心:Setstheresourcelimitoftheprocess.这看起来只是setrlimit的包装器来自C库,因此它可能仅在Unix-ish平台上可用。setrlimit不支持CPU百分比限制,但它支持以秒为单位限制CPU时间。如果您只是想让您的Ruby进程不占用整个CPU,那么您可以尝试使用Process.setpriority来调整它的优先级。这只是libc的setpriority的包装
我们正在使用Unicorn_Rails+nginx。它在我的系统(4GBRam,Intel(R)Core(TM)2DuoCPUP8600@2.40GHz)的开发模式和生产模式下运行良好我能够在本地系统中启动10个worker,但在任何情况下都无法在生产中启动超过2个有时它可以工作,但需要等待15-20米启动unicorn_rails时一直占用99.6%的CPU英特尔(R)至强(R)CPUE5507@2.27GHz但它卡在亚马逊(m1.small实例)1.73GB内存我发现没有人在任何地方谈论使用unicorn_rails启动缓慢...... 最佳答案
我在我的Rails应用程序中运行守卫,测试套件(最小的)最近停止正常工作。如果幸运的话,它会运行所有测试一次,也许两次。在那之后,即使是一个小的测试文件被更改也需要很长时间才能响应,以至于使用gem变得徒劳无功。在测试运行时跟随top,我可以看到有一个ruby进程持续占用了超过100%的CPU。即使所有测试都已运行并且我没有对文件进行任何更改。ruby进程是:/Users/Bodacious/.rvm/gems/ruby-2.0.0-p247@MyApp/gems/rb-fsevent-0.9.3/bin/fsevent_watch--latency0.1/Users/Bodaio