文章目录
论文地址:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
code地址:https://github.com/microsoft/Swin-Transformer
Swin Transformer是2021年微软研究院发表在ICCV上的一篇文章,并且已经获得ICCV 2021 best paper的荣誉称号。
在模型详解之前,先来简单对比下 Swin Transformer 和之前的 Vision Transformer(如果不了解Vision Transformer的,可以参考:Vision Transformer)。下图是Swin Transformer文章中给出的图1,左边是本文要讲的Swin Transformer,右边是之前讲的Vision Transformer。通过对比至少可以看出两点不同:
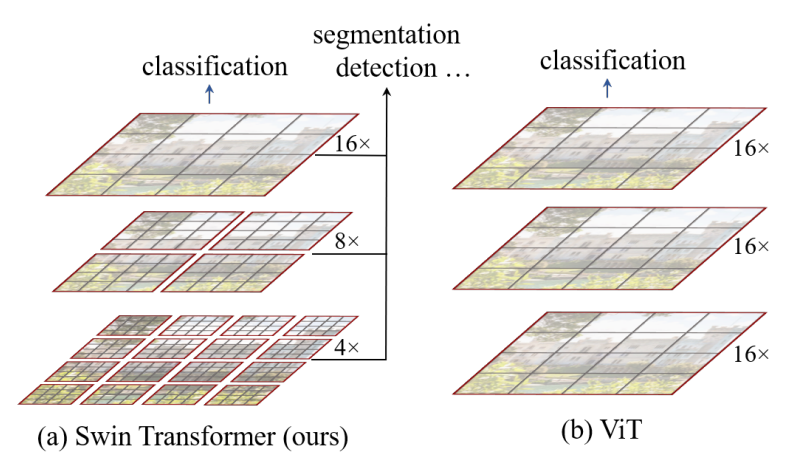
接下来,我们看下原论文中给出的关于Swin Transformer(Swin-T)网络的架构图。通过图 (a) 可以看出整个框架的基本流程如下:
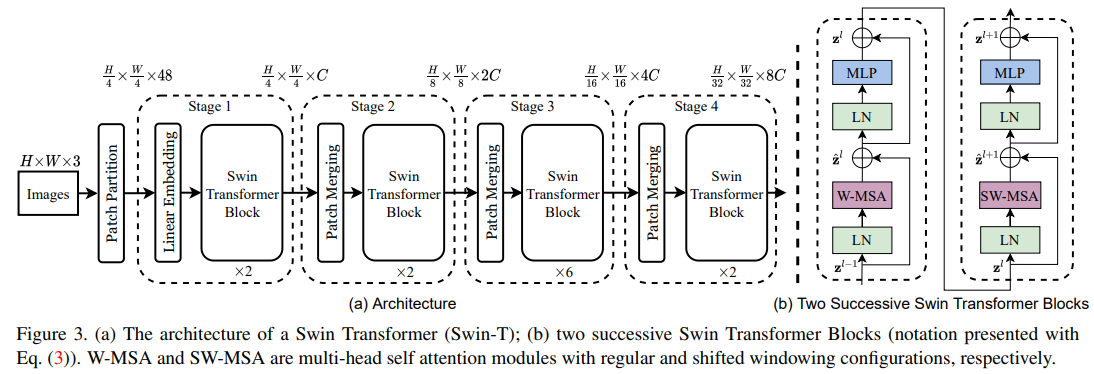
接下来,在分别对Patch Merging、W-MSA、SW-MSA以及使用到的相对位置偏执(relative position bias)进行详解。关于Swin Transformer Block中的MLP结构和Vision Transformer中的结构是一样的,可以参考:Vision Transformer。
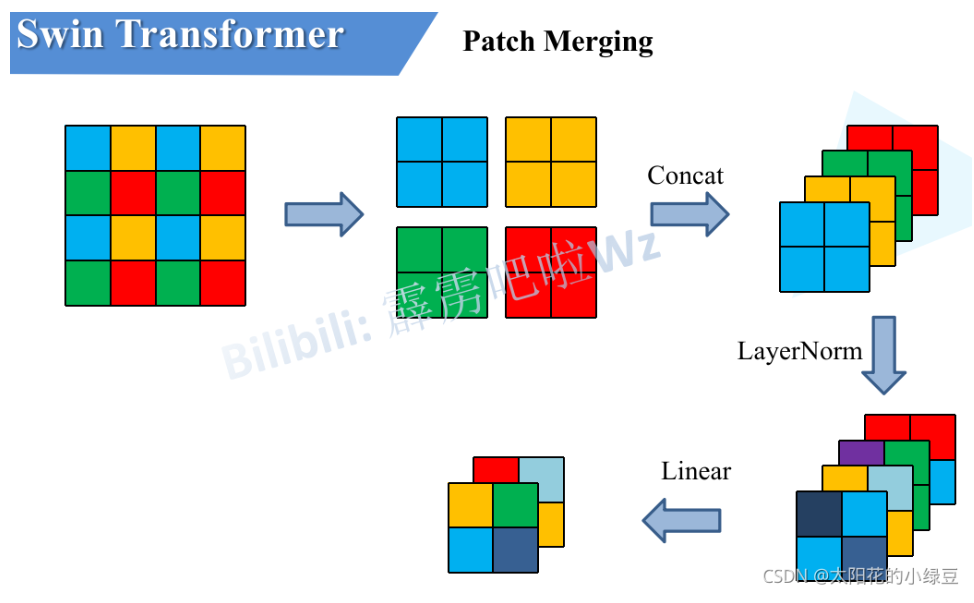
前面有说,在所有的Stage中首先要通过一个 Patch Merging 层进行下采样(Stage1除外)。如下图所示,假设输入Patch Merging的是一个4x4大小的单通道特征图(feature map),
通过这个简单的例子可以看出,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。
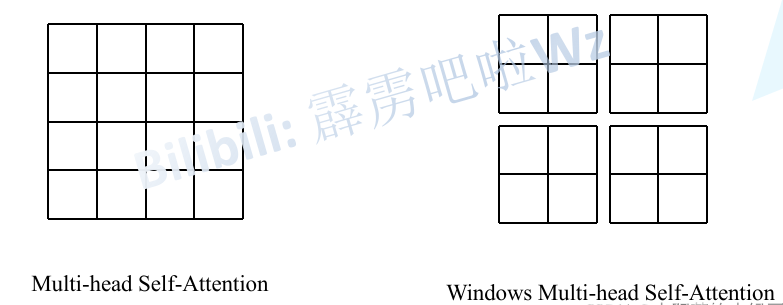
引入Windows Multi-head Self-Attention(W-MSA)模块是为了减少计算量。如下图所示,
两者的计算量具体差多少呢?原论文中有给出下面两个公式,这里忽略了Softmax的计算复杂度。

这个公式是的计算原论文中并没有细讲,这里解释一下。Self-Attention的理论需要先知道,可以参考:Transformer。

对于feature map中的每个像素(或称作token,patch),都要通过
W
q
,
W
k
,
W
v
W_q, W_k, W_v
Wq,Wk,Wv 生成对应的
q
u
e
r
y
(
q
)
query(q)
query(q),
k
e
y
(
k
)
key(k)
key(k) 以及
v
a
l
u
e
(
v
)
value(v)
value(v)。这里假设
q
,
k
,
v
q, k, v
q,k,v 的向量长度与feature map的深度
C
C
C 保持一致。那么对应所有像素生成Q的过程如下式:

根据矩阵运算的计算量公式可以得到生成Q的计算量为
h
w
×
C
×
C
hw \times C \times C
hw×C×C,生成 K 和 V 同理都是
h
w
C
2
hwC^2
hwC2 ,那么总共是
3
h
w
C
2
3hwC^2
3hwC2 。接下来 Q 和
K
T
K^T
KT 相乘,对应计算量为
(
h
w
)
2
C
(hw)^2C
(hw)2C:

接下来忽略除以
d
\sqrt d
d,以及softmax的计算量,假设得到
Λ
h
w
×
h
w
\Lambda ^{hw \times hw}
Λhw×hw ,最后还要乘以
V
V
V,对应的计算量为
(
h
w
)
2
(hw)^2
(hw)2:

那么对应单头的Self-Attention模块,总共需要
3
h
w
C
2
+
(
h
w
)
2
C
+
(
h
w
)
2
C
=
3
h
w
C
2
+
2
(
h
w
)
2
C
3hwC^2 + (hw)^2C + (hw)^2C=3hwC^2 + 2(hw)^2C
3hwC2+(hw)2C+(hw)2C=3hwC2+2(hw)2C。而在实际使用过程中,使用的是多头的Multi-head Self-Attention模块,在之前的文章中有进行过实验对比,多头注意力模块相比单头注意力模块的计算量仅多了最后一个融合矩阵
W
O
W_O
WO 的计算量
h
w
C
2
hwC^2
hwC2。

因此,上述计算量总共加起来是:
4
h
w
C
2
+
2
(
h
w
)
2
C
4hwC^2 + 2(hw)^2C
4hwC2+2(hw)2C。
对于W-MSA模块首先要将feature map划分到一个个窗口(Windows)中,假设每个窗口的宽高都是M,那么总共会得到
h
M
×
w
M
\frac {h} {M} \times \frac {w} {M}
Mh×Mw个窗口,然后对每个窗口内使用多头注意力模块。刚刚计算高为 h,宽为 w,深度为 C 的feature map的计算量为:
4
h
w
C
2
+
2
(
h
w
)
2
C
4hwC^2 + 2(hw)^2C
4hwC2+2(hw)2C,这里每个窗口的高为 M 宽为 M,带入公式得:

又因为有
h
M
×
w
M
\frac {h} {M} \times \frac {w} {M}
Mh×Mw 个窗口,则:

故使用W-MSA模块的计算量为:
4
h
w
C
2
+
2
M
2
h
w
C
4hwC^2 + 2M^2 hwC
4hwC2+2M2hwC。
假设feature map的h、w都为112,M=7,C=128,采用W-MSA模块相比MSA模块能够节省约40124743680 FLOPs:
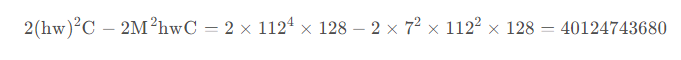
为了解决这个问题,作者引入了Shifted Windows Multi-Head Self-Attention(SW-MSA)模块,即进行偏移的 W-MSA。如下图所示,
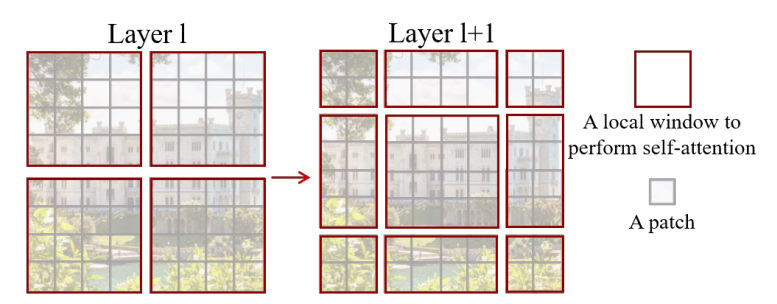
上图中,我们可以发现通过将窗口进行偏移后,由原来的4个窗口变成9个窗口了。后面又要对每个窗口内部进行MSA,这样做感觉又变麻烦了。
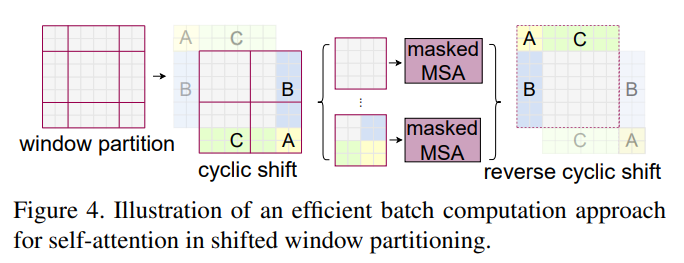
上图有些难以理解,参考:太阳花重新画的。下图左侧是刚刚通过偏移窗口后得到的新窗口,右侧是为了方便大家理解,对每个窗口加上了一个标识。
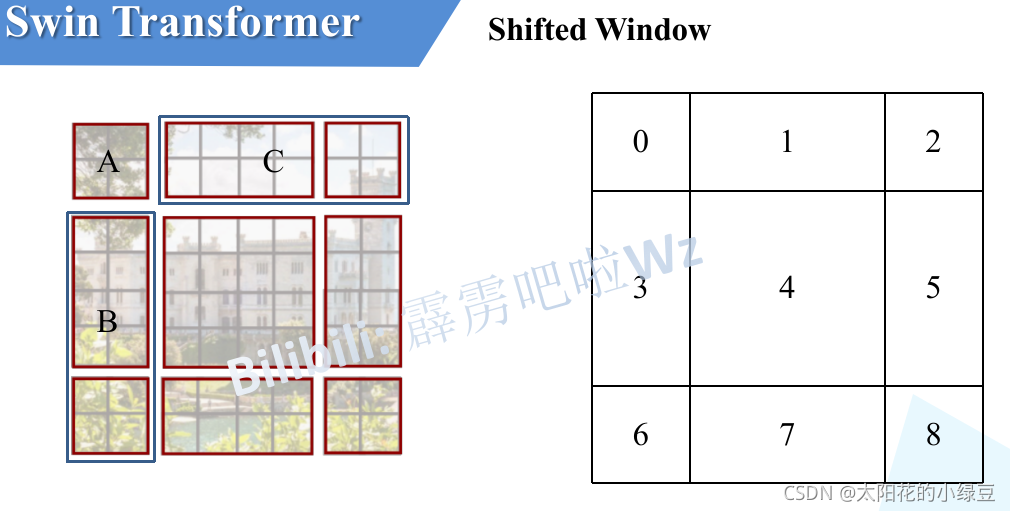
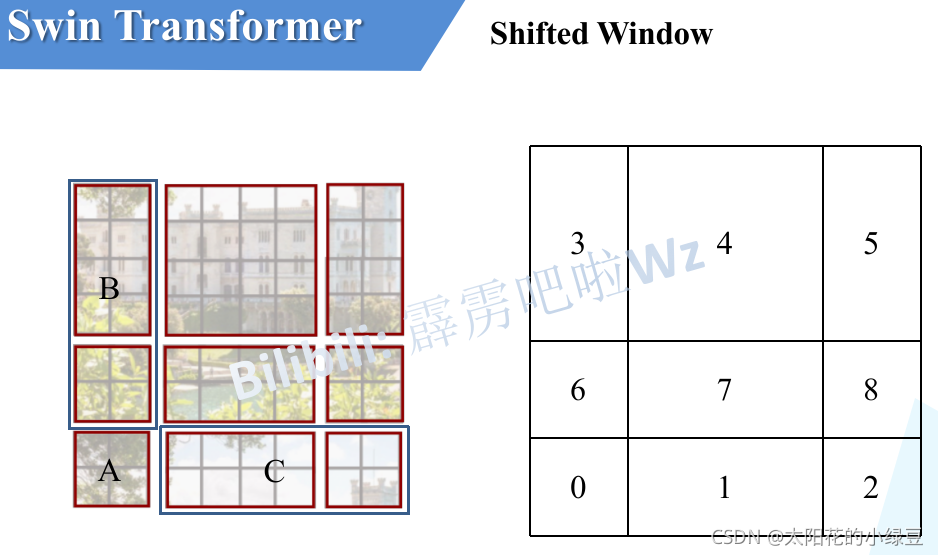
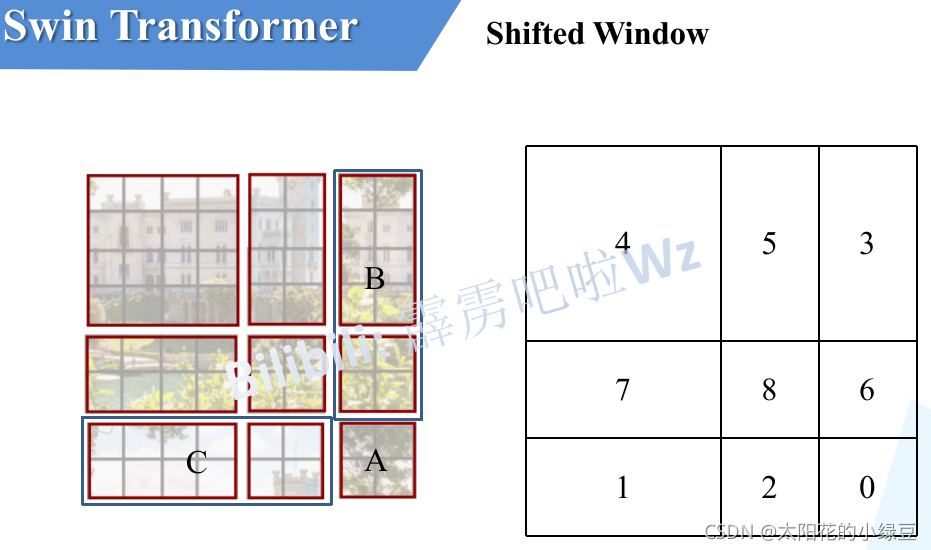
移动完后,如上图所示:
这样又和原来一样是4个4x4的窗口了,所以能够保证计算量是一样的。这里肯定有人会有疑问,把不同的区域合并在一起(比如5和3)进行MSA,这信息不就乱窜了吗?
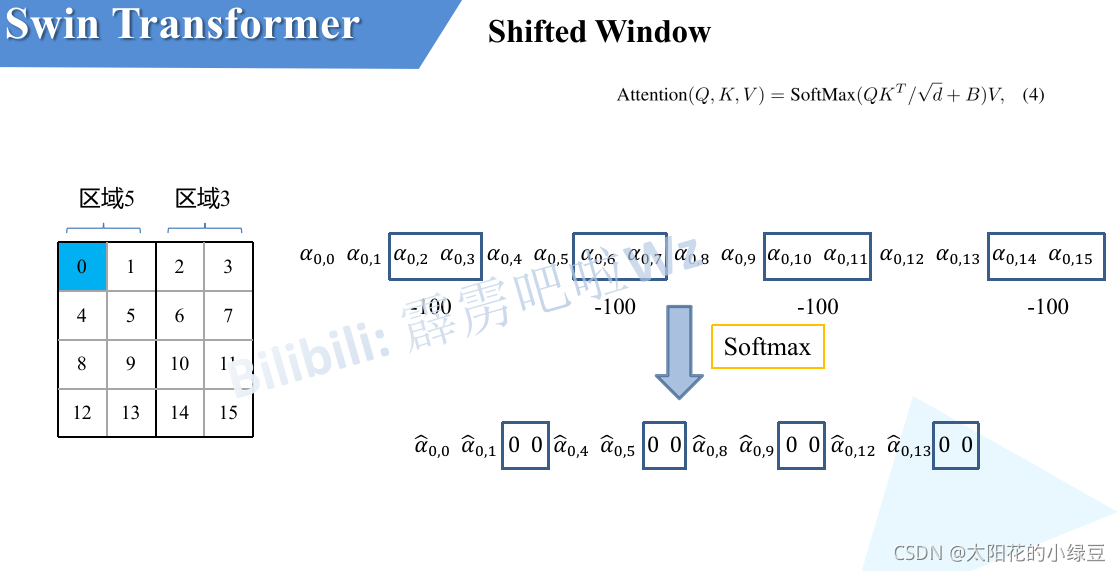
对于该窗口内的每一个像素(或称token,patch)在进行MSA计算时,都要先生成对应的query(q),key(k),value(v)。假设对于上图的像素0而言,得到 q 0 q^0 q0 后要与每一个像素的 k 进行匹配(match),假设 α 0 , 0 \alpha _{0,0} α0,0 代表 q 0 q^0 q0 与像素 0 对应的 k 0 k^0 k0 进行匹配的结果,那么同理可以得到 α 0 , 0 \alpha _{0,0} α0,0 至 α 0 , 15 \alpha _{0,15} α0,15。按照普通的MSA计算,接下来就是 SoftMax 操作了。
具体代码是怎么实现的,可以参考:其代码解析。
关于相对位置偏执,论文里也没有细讲,只说了参考的哪些论文,然后说使用了相对位置偏执后给够带来明显的提升。
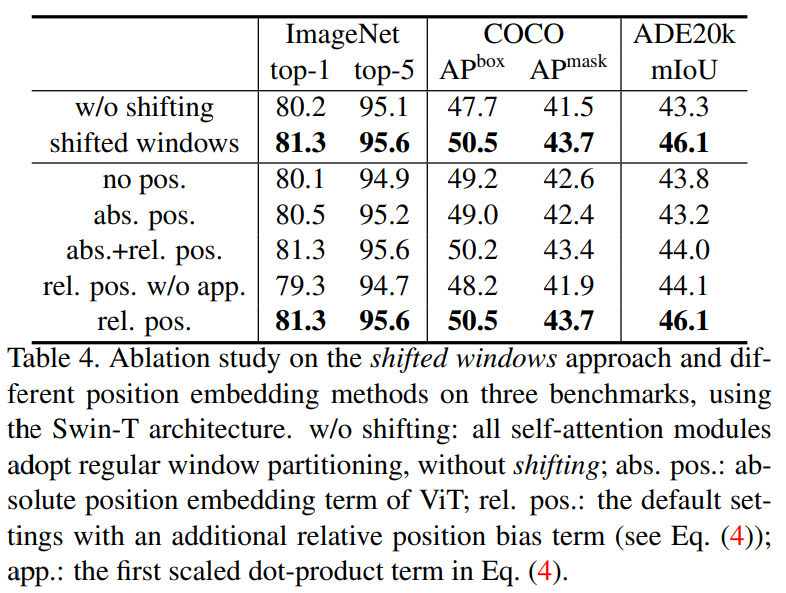
1)这个相对位置偏执是加在哪的呢?

2)什么是相对位置偏执?
论文中没有详解讲解这个相对位置偏执,这里解释一下。如下图,假设输入的feature map高宽都为2,那么首先我们可以构建出每个像素的绝对位置(左下方的矩阵),对于每个像素的绝对位置是使用行号和列号表示的。
接下来再看看相对位置索引。首先看下蓝色的像素,在蓝色像素使用q与所有像素k进行匹配过程中,是以蓝色像素为参考点。然后用蓝色像素的绝对位置索引与其他位置索引进行相减,就得到其他位置相对蓝色像素的相对位置索引。(其实这里我觉得应该是:其他位置减去蓝色元素,来得到其他位置相对于蓝色像素的相对索引。不过应该都不影响结果。)
然后我们将每个相对位置索引矩阵按行展平,并拼接在一起可以得到下面的4x4矩阵 。
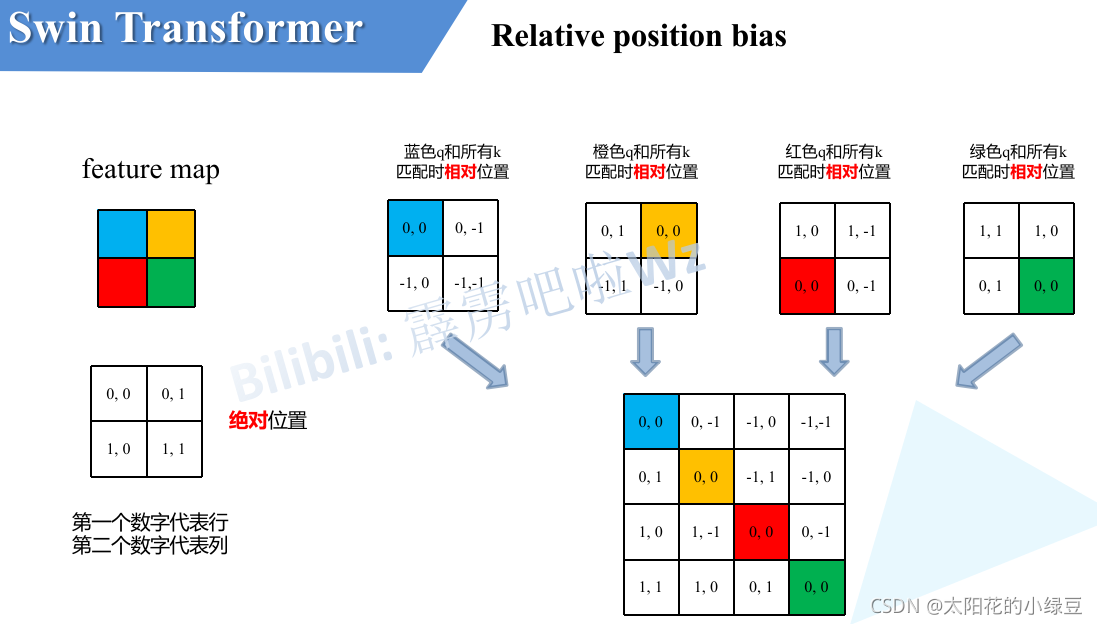
注意,这里描述的一直是相对位置索引,并不是相对位置偏执参数。因为后面我们会根据相对位置索引去取对应的参数。
其实讲到这基本已经讲完了,但在源码中作者为了方便把二维索引给转成了一维索引。
3)具体怎么转的呢,有人肯定想到,简单啊直接把行、列索引相加不就变一维了吗?
接下来我们看看源码中是怎么做的。

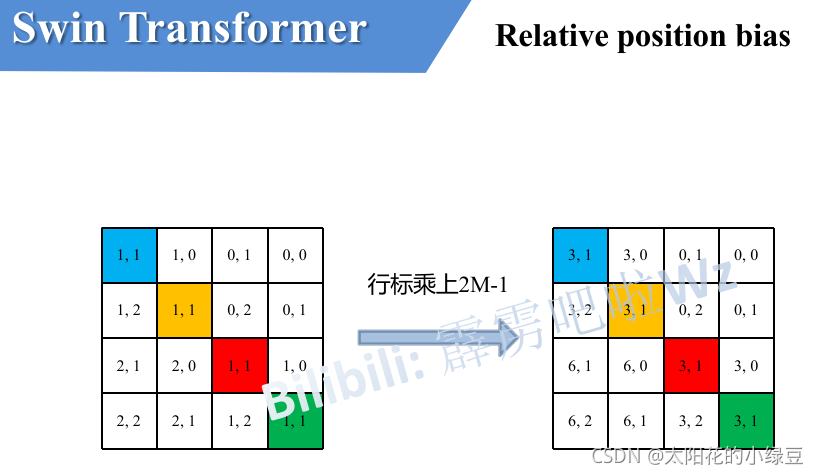
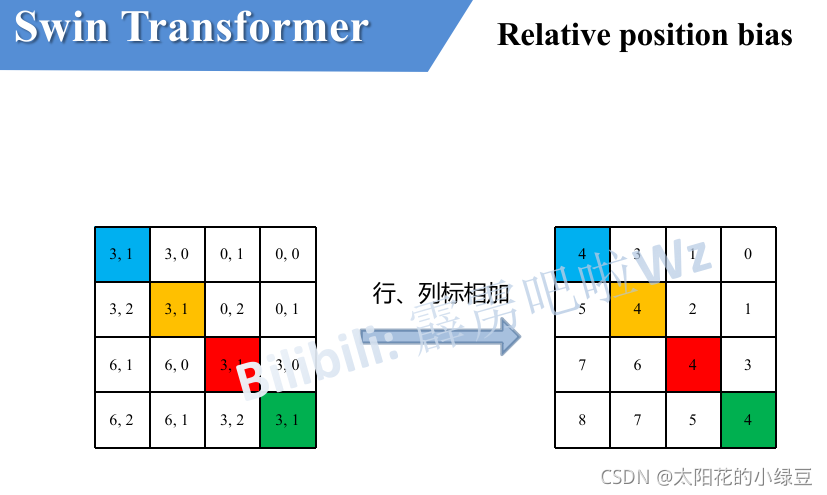
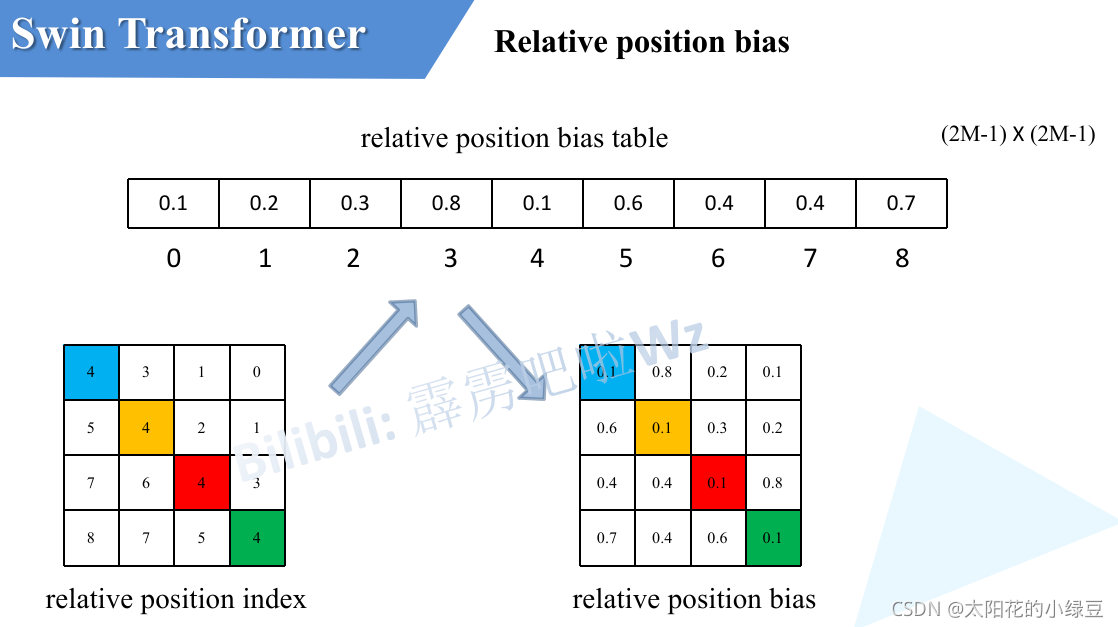
刚刚上面也说了,之前计算的是相对位置索引,并不是相对位置偏执参数。真正使用到的可训练参数 B ^ \hat{B} B^ 是保存在relative position bias table表里的,这个表的长度是等于 ( 2 M − 1 ) × ( 2 M − 1 ) (2M-1) \times (2M-1) (2M−1)×(2M−1) 的。
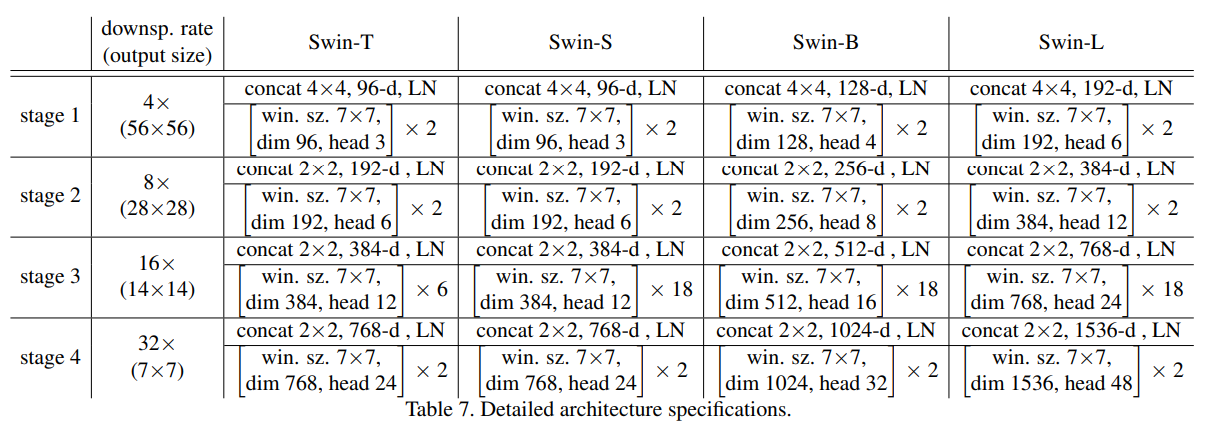
下图(表7)是原论文中给出的关于不同Swin Transformer的配置,T(Tiny),S(Small),B(Base),L(Large),其中:
【1】https://blog.csdn.net/qq_37541097/article/details/121119988
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in