边界框回归(BBR)的损失函数对于目标检测至关重要。它的良好定义将为模型带来显著的性能改进。大多数现有的工作假设训练数据中的样本是高质量的,并侧重于增强BBR损失的拟合能力。
最初的基于回归的BBR损失定义为L2-norm,L2-norm损失主要有两个缺点:
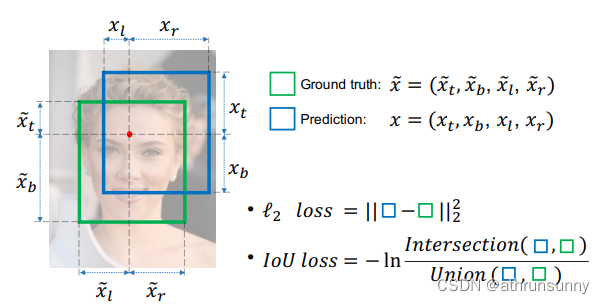
1、边界框的坐标(以xt、xb、xl、xr的形式)被优化为四个独立变量。这个假设违背了对象的边界高度相关的事实。简单的分开计算每个变量的回归loss无法反映这种相关性,它会导致预测框的一个或两个边界非常接近GT,但整个边界框是不满足条件的。
2、这种形式的损失函数并不能屏蔽边界框大小的干扰,使得模型对小目标的定位性能较差。
在目标检测任务中,使用IoU来测量anchor box与目标box之间的重叠程度。它以比例的形式有效地屏蔽了边界框大小的干扰,使该模型在使用1-IoU作为BBR损失时,能够很好地平衡对大物体和小物体的学习。
IoU loss的函数定义为:
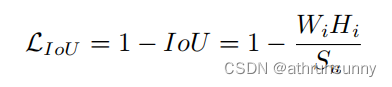
当边界框没有重叠时Liou对Wi求导会等于0,即:
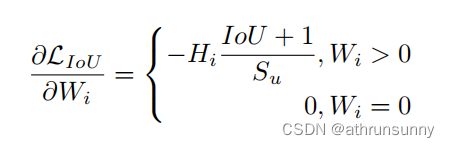
此时Liou的反向投影梯度消失,在训练期间无法更新重叠区域Wi的宽度。
IoU损失会有两个主要的缺点:
1、当预测框与真实框都没有交集时,计算出来的IoU都为0,损失都为1,但是缺失距离信息,预测框与GT相对位置较近时,损失函数应该较小。
2、当预测框和真实框的交并比相同,但是预测框所在位置不同,因为计算出来的损失一样,所以这样并不能判断哪种预测框更加准确。
现有的工作GIOU、DIOU、Focal EIOU、CIOU以及SIOU中考虑了许多与边界框相关的几何因子,并构造了惩罚项Ri来解决这个问题。现有的BBR损失遵循以下范例:
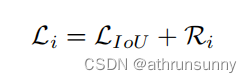
论文:《Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression》
为了解决IoU loss的第一个问题,即当预测框与真实框都没有交集的时候,计算出来的IoU都为0,损失都为1,引入了一个最小闭包区的概念,即能将预测框和真实框包裹住的最小矩形框
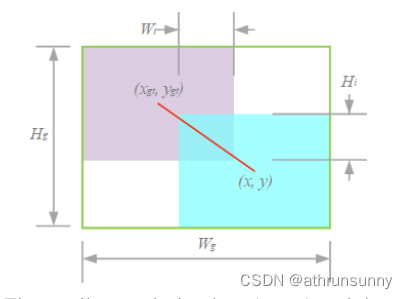
其中紫色框为GT,蓝色框为预测框,绿色的边框则为最小包围框。
GIoU的伪代码:

与IoU相似,GIoU也是一种距离度量,IoU取值[0,1],GIoU取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标。与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
但是GIoU同时也存在一些问题:
1、当预测框包裹GT时,计算的iou相同,但是质量却不同,对于预测框的中心点靠近GT中心点的情况,loss应该相对小一些
GIoU loss的定义:

论文:《Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression》
DIoU为了解决GIoU中存在的问题,作者认为好的检测回归loss应该考虑三个几何度量,预测框和GT框的重叠度、中心点距离、长宽比的一致性。于是在IoU loss和GIoU loss基础上引入预测框和GT框中心点距离作DIoU loss,在DIoU loss基础上引入了预测框的长宽比和GT框的长宽比之间的差异作CIoU loss。此外,将DIoU加入nms替代IoU,提升了nms的鲁棒性。
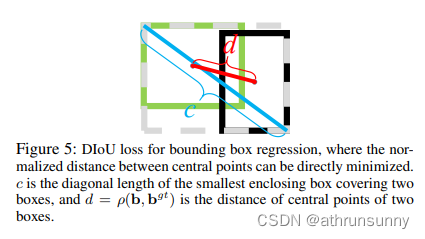
DIoU定义:
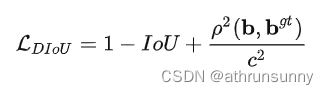
DIoU也存在一个缺点,当真实框和预测框的中心点重合时,但是长宽比不同,交并比一样,CIoU在此基础上增加一个惩罚项。
CIoU定义:
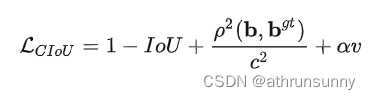
其中:

v用于计算预测框和目标框的高宽比的一致性,这里是用tan角来衡量
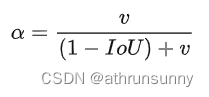
α是一个平衡参数(这个系数不参与梯度计算),这里根据IoU值来赋予优先级,当预测框和目标框IoU越大时,系数越大 。
论文:Focal and Efficient IOU Loss for Accurate Bounding Box Regression》
主要思想:
一是认为CIoU loss对于长宽比加入loss的设计不太合理,于是将CIoU loss中反应长宽比一致性的部分替换成了分别对于长和宽的一致性loss,形成了EIoU loss。
二是认为不太好的回归样本对回归loss产生了比较大的影响,回归质量相对较好的样本则难以进一步优化,所以论文提出Focal EIoU loss进行回归质量较好和质量较差的样本之间的平衡。
EIoU loss定义:
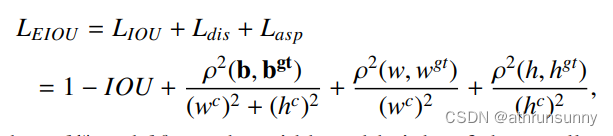
其中hc和wc为最小包围框的高和宽。
要平衡回归质量较好的样本的偏小loss和回归质量较差的样本的偏大loss,很自然的,选择和GT的IoU形成类似focal loss中的(1-p)的γ次方的权重来调节是一个很好的想法。
Focal EIoU loss定义:
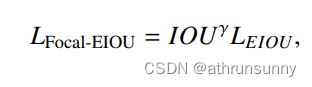
最终形式:
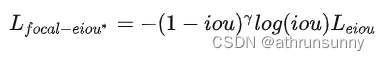
指标对比:

论文:《SIoU Loss: More Powerful Learning for Bounding Box Regression》
已有方法匹配真实框和预测框之间的IoU、中心点距离、宽高比等,它们均未考虑真实框和预测框之间不匹配的方向。这种不足导致收敛速度较慢且效率较低,因为预测框可能在训练过程中“徘徊”,最终生成更差的模型。
本文提出了一种新的损失函数SCYLLA-IoU(SIoU),考虑到期望回归之间向量的角度,重新定义角度惩罚度量,它可以使预测框快速漂移到最近的轴,随后则只需要回归一个坐标(X或Y),这有效地减少了自由度的总数。
Zhora证明了中心对准anchor box具有更快的收敛速度,并根据角度成本、距离成本和形状成本构造了SIoU。

Angle cost描述了中心点连接(图1)与x-y轴之间的最小角度,当中心点在x轴或y轴上对齐时,Λ = 0。当中心点连接到x轴45°时,Λ = 1。这一惩罚可以引导anchor box移动到目标框的最近的轴上,减少了BBR的总自由度数。
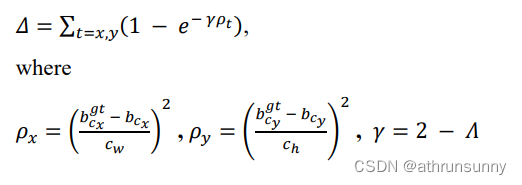
Distance cost描述了中心点之间的距离,其惩罚代价与角度代价呈正相关,当𝛼→0时,Distance cost的贡献大大降低。相反,𝛼越接近pi/4,Distance cost贡献越大。
具体来说:以X轴为例,即两框近乎平行时,a趋近于0,这样计算出来两框之间的角度距离接近于0,此时γ也接近于2,那么两框之间的距离对于整体loss的贡献变少了。而当a趋近与45°时,计算出来两框之间的角度为1,此时γ接近1,则两框之间的距离应该被重视,需要占更大的loss。
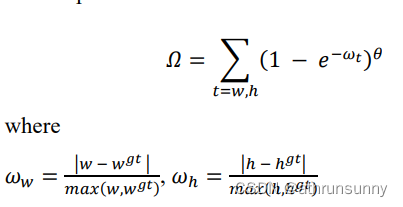
Shape cost这里作者考虑的两框之间的长宽比,是通过计算两框之间宽之差和二者之间最大宽之比(长同理)来定义的,大体思路和CIOU类似,只不过CIOU可以的考虑是两框整体形状的收敛,而SIoU是以长、宽两个边收敛来达到整体形状收敛的效果。
θ是个可调变量,来表示网络需要对形状这个,给予多少注意力,即占多少权重。实验中设置为4。
SIoU loss定义:
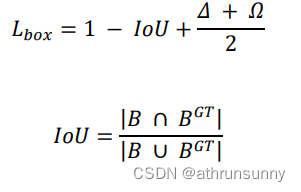
论文:《Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism》
Focal EIoU v1被提出来解决质量较好和质量较差的样本间的BBR平衡问题,但由于其静态聚焦机制(FM),非单调FM的潜力没有被充分利用,基于这一思想,作者提出了一种基于IoU的损失,该损失具有动态非单调FM,名为Wise IoU(WIoU)。
主要贡献总结如下:
提出了BBR的基于注意力的损失WIoU v1,它在仿真实验中实现了比最先进的SIoU更低的回归误差。
设计了具有单调FM的WIoU v2和具有动态非单调FM的WIoU v3。利用动态非单调FM的明智的梯度增益分配策略,WIoU v3获得了优越的性能。
对低质量的样本的影响进行了一系列详细的研究,证明了动态非单调调频的有效性和效率。
由于训练数据不可避免地包含低质量示例,几何因素(如距离和纵横比)将加重对低质量示例的惩罚,从而降低模型的泛化性能。当anchor box与目标box很好地重合时,一个好的损失函数应该会削弱几何因素的惩罚,而较少的训练干预将使模型获得更好的泛化能力。
WIoU loss定义:

其中Wg,Hg表示最小包围框的宽和高。为了防止Rwiou产生阻碍收敛的梯度,Wg和Hg从计算图中分离出来(上标*表示此操作)。因为它有效地消除了阻碍收敛的因素,所以没有引入新的度量,例如纵横比。
1、Rwiou∈[1,e),这将显著放大普通质量anchor box的LIoU。
2、Liou∈[0,1],这将显著降低高质量anchor box的Rwiou,并在anchor box与目标框重合时,重点关注中心点之间的距离。
消融实验的结果:

从消融实验的结果可以看出WIoU v3的效果最好。
上述的IoU loss的实现可以参看我的另一篇文章:yolov5增加iou loss,无痛涨点trick
原文题目:《ACompleteSurveyonGenerativeAI(AIGC):IsChatGPTfromGPT-4toGPT-5AllYouNeed?》文章链接:https://arxiv.org/abs/2303.11717https://arxiv.org/abs/2303.11717引言:随着ChatGPT的火热传播,生成式AI(AIGC,即AI生成的内容)因其分析和创造文本、图像等能力而在各地引起了轰动。在如此强烈的媒体关注下,我们几乎不可能错过从某个角度欣赏AIGC的机会。 “一个具有未来科幻感的机器人坐着,手握画笔正在创作一幅五颜六色的图画“由dalle2创作在AI从纯分析转
如何使用FPGA加速机器学习算法如何使用FPGA加速机器学习算法 当前,AI因为其CNN(卷积神经网络)算法出色的表现在图像识别领域占有举足轻重的地位。基本的CNN算法需要大量的计算和数据重用,非常适合使用FPGA来实现。上个月,RalphWittig(XilinxCTOOffice的卓越工程师)在2016年OpenPower峰会上发表了约20分钟时长的演讲并讨论了包括清华大学在内的中国各大学研究CNN的一些成果。在这项研究中出现了一些和CNN算法实现能耗相关的几个有趣的结论:①限定使用片上Memory;②使用更小的乘法器;③进行定点匹配:相对于32位定点或浮点计算,将定点计算结果精度降为16
声明主页:元存储的博客_CSDN博客依公开知识及经验整理,如有误请留言。个人辛苦整理,付费内容,禁止转载。内容摘要1.5.1核心参数1.5.1.1存储容量1.5.1.2
目标跟踪综述论文阅读心得1、目标跟踪任务是什么?目标跟踪是计算机视觉领域的一个重要分支。目标跟踪就是在一段视频序列中定位感兴趣的运动目标,得到目标完整的运动轨迹。给定图像第一帧目标的位置,预测下一帧图像中目标的位置。2、目标跟踪的主要部分:运动模型(MotionModel):如何产生众多的候选样本。 生成候选样本的速度与质量直接决定了跟踪系统表现的优劣。常见的有粒子滤波(ParticleFilter)滑动窗口(SlidingWindow)半径滑动窗口(RadiusSlidingWindow)。论文中的结论:通常情况下,运动模型对性能的影响较小。然而,在尺度变化和快速运动的情况下,正确设置参数
目录优化算法综述数学规划法精确算法(exactalgorithm)启发式VS.元启发式启发式算法元启发式算法Whatisthedifferencebetweenheuristicsandmeta-heuristics?多目标智能优化算法模拟进化算法与传统的精确算法(确定性算法)的区别优化算法分类算法介绍帝国竞争算法(ImperialistCompetitiveAlgorithm,ICA)分支定界法(BranchandBound,BB)NSGA-Ⅱ算法遗传算法(GeneticAlgorithm,GA)禁忌搜索算法(TabuSearch,TS)文化基因算法(MemeticAlgorithm,MA)
近期我国迎来了cov海啸,其实我也不知道我羊了没有,但并没有什么不舒服同时因为我没有测,那自然是没有羊,或者是薛定谔的羊。近年另外一块工作的综述,这篇科普的同时,也会包含部分有价值的信息。一.摘要:本文重点描述VSLAM与VIO的3D建图,重定位,回环与世界观,从小伙伴们最关心的工程和商用搞钱的角度进行详细分析,并从技术和实现部分详细描述各种类型SLAM在这块的差异。首先来4个基础逻辑:1.SLAM本质是数学问题,是一个科学家与工程师可以控制的数学问题,本质不是玄学,实现需要大量的数学知识与工具,需要极强的代码功底与硬软件开发能力。2.无论对SLAM系统如何分割,建图仍是位姿估计的副产品。3.
本文参考文献:基于Transformer的目标检测算法综述网络首发时间:2023-01-1915:01:34网络首发地址:https://kns.cnki.net/kcms/detail//11.2127.TP.20230118.1724.013.html在本文中约90%的文字和80%的图片来自该论文,这里只作为学习记录,摘录于此。1.摘要深度学习框架Transformer具有强大的建模能力和并行计算能力,目前基于Transformer的目标检测算法已经成为了研究的热点。为了进一步探索目标检测的新思路、新方向,对基于Transformer的目标检测算法进行归纳总结。概述多种目标检测数据集及其应
动手点关注干货不迷路1.概述1.1基本概念用一句话概括模板学习,即将原本的输入文本填入一个带有输入和输出槽位的模板,然后利用预训练语言模型预测整个句子,最终可以利用这个完整的句子导出最终需要的答案。模板学习最吸引人的关键在于其通过已有的预训练模型,定义合适的模板就能完成few-shot或者zero-shot任务,这样可以使得语言模型可以在预训练阶段利用尽可能多的信息进行训练,后续也能最大效率的发挥其作用。从数学角度来看模板学习,我们传统的监督学习解决的是P(y|x;θ)问题,训练一个模型优化其参数θ,在面对输入x时给出输出y的概率;而基于模板学习的方法希望解决的是P(x;θ)问题,即给定一个参
1、论文论文题目:《FocalandEfficientIOULossforAccurateBoundingBoxRegression》2、引言CIoULoss虽然考虑了边界框回归的重叠面积、中心点距离、高宽比。但是其公式中的v反映的是高宽的差异,而不是高宽分别与其置信度的真实差异。因此,有时会阻碍模型有效的优化相似性。针对这一问题,本文在CIoU的基础上将高宽比拆开,提出了EIoULoss,并且引入了FocalLoss聚焦优质的锚框。文章贡献:将高宽比的损失项拆分成预测的高宽分别与最小外接框高宽的差值,加快了收敛速度,提高了回归精度;引入了FocalLoss,优化了边界框回归任务中的样本不平衡
声明主页:元存储的博客_CSDN博客依公开知识及经验整理,如有误请留言。个人辛苦整理,付费内容,禁止转载。内容摘要1.6.1存储市场变化分析1.6.1.1NANDFlash向高存储密度方向持续发展1.6.1.2SSD及嵌入式存储占NAND应用超80%,DRAM扩大服务器的应用占比