

学习人工智能?来我们的床长人工智能教程网站!全面的课程,适合任何想学习的人。基础知识到高级应用,我们都有。职场人士、学生或爱好者,都能快速提升技能水平。赶快来尝试吧!
个人名片:
🐼作者简介:一名大二在校生,喜欢编程🎋
🐻❄️个人主页🥇:小新爱学习.
🐼个人WeChat:hmmwx53
🕊️系列专栏:🖼️🐓每日一句:🍭我很忙,但我要忙的有意义!
文章目录
Ai绘画最近可谓是火到不行,它的出现让很多人感叹道时代真的变了。无数高质量的画作随着Ai绘画的出现而出现,让毫无画画基础的人也能成为绘画大师,只需要输入一个或几个关键词就能生成画作,这无疑是一件“颠覆”的事情。
就比如最近在朋友圈,抖音、快手等短视频平台上刷到一些奇特的图画,这些图画绝大部分都不是人工绘画完成的,而是通过ai完成的,只需要输入一些清晰易懂的文字tag,即可在很短的时间内得到一张同样效果不错的画面。这就是现在非常火的ai绘画。那么ai绘画究竟是什么呢?
所谓AI绘画就是“人工智能绘画”。简单来说,就是机器人画画,然而要让机器人工作,就得需要指令,用ai绘画,我们的指令就是关键词,相较于过去无论是传统手绘还是CG绘画,创作者都需要花一定的时间才能完成一张作品,但在今年引爆绘画行业的AI绘画软件,一个关键词可以生成无数张内容不一的画面!
原图:(我家宝贝,禁止盗图!!!)

根据关键词,AI绘制后:

得出结论,这AI真拉,哈哈哈,开玩笑的。
移动端/pc端输入网址draft.art即可使用,操作简单,无需下载,最重要的是免费
速度飞快,十秒内出图,免费下载
社区内海量瀑布流素材模板,各类词库随意选择,提供无限灵感创意
中英文都支持,输入关键字,随心创作,你就是“梵高”
AI绘画的算法精髓还是比较复杂的。不过简而言之所谓的AI绘画,是指利用电脑运行,使用AI(人工智能)算法来自主生成的绘画方式。具体的绘画是通过AI算法经过大量真实存在的画师作品中,进行归纳和学习来完成创作。
看到历史和一些生动的例子,是不是觉得AI生成各种内容已经就在眼前了?我们可以随便写几句话就能生成精美的图片、视频、声音满足各种需求了?但是实际操作上依然会有很多的限制。下面我们就来适当剖析一下最近较热的文本生成图片和视频技术原理,到底实现了什么功能以及相关的局限性在哪里,后面我们再针对实际游戏内容做一些demo,更贴合应用场景的了解这些局限性。
不同的AI图片生成器技术结构上会有差别,本文在最后也附上了一些重要模型的参考文献。我们在这里主要针对最近热门的Stable Diffusion和DALL-E 2做一些解读和讨论。这类的AI生成模型的核心技术能力就是,把人类创作的内容,用某一个高维的数学向量进行表示。如果这种内容到向量的“翻译”足够合理且能代表内容的特征,那么人类所有的创作内容都可以转化为这个空间里的向量。当把这个世界上所有的内容都转化为向量,而在这个空间中还无法表示出来的向量就是还没有创造出来的内容。而我们已经知道了这些已知内容的向量,那我们就可以通过反向转化,用AI“创造”出还没有被创造的内容。
Stable Diffusion的整体上来说主要是三个部分,language model、diffusion model和decoder。

Language model主要将输入的文本提示转化为可以输入到diffusion model使用的表示形式,通常使用embedding加上一些random noise输入到下一层。
diffusion model主要是一个时间条件U-Net,它将一些高斯噪声和文本表示作为模型输入,将对应的图像添加一点高斯噪声,从而得到一个稍微有噪点的图像,然后在时间线上重复这个过程,对于稍微有噪点的图像,继续添加高斯噪声,以获得更有噪点的图像,重复多次到几百次后就可以获得完全嘈杂的图像。这么做的过程中,知道每个步骤的图像版本。然后训练的NN就可以将噪声较大的示例作为输入,具有预测图像去噪版本的能力。
在训练过程中,还有一个encoder,是decoder的对应部分,encoder的目标是将输入图像转化为具有高语义意义的缩减采样表示,但消除与手头图像不太相关的高频视觉噪声。这里的做法是将encoder与diffusion的训练分开。这样,可以训练encoder获得最佳图像表示,然后在下游训练几个扩散模型,这样就可以在像素空间的训练上比原始图像计算少64倍,因为训练模型的训练和推理是计算最贵的部分。
decoder的主要作用就是对应encoder的部分,获得扩散模型的输出并将其放大到完整图像。比如扩散模型在64x64 px上训练,解码器将其提高到512x512 px。
DALL-E 2
DALL-E 2其实是三个子模块拼接而成的,具体来说:
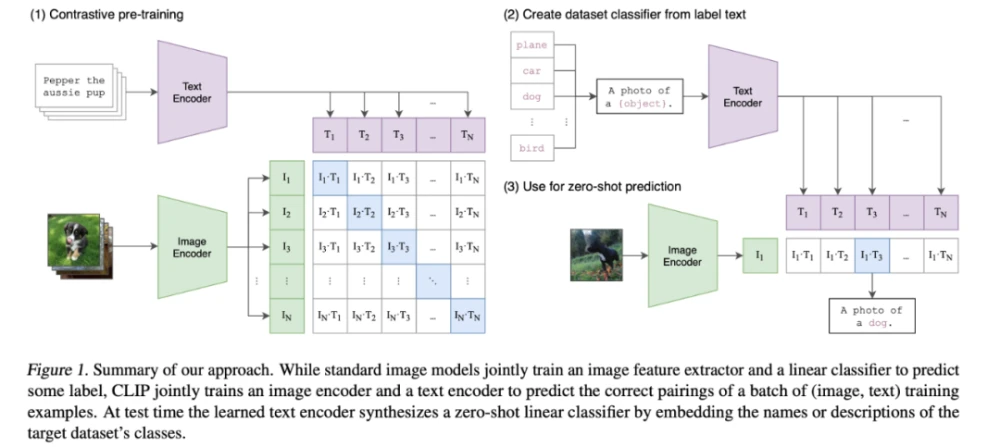
一个基于CLIP模型的编码模块,目标是训练好的文本和图像encoder,从而可以把文本和图像都被编码为相应的特征空间。
一个先验(prior)模块,目标是实现文本编码到图像编码的转换。
一个decoder模块,该模块通过解码图像编码生成目标图像。
在本篇文章开始前,希望你可以了解go的一些基本的内存知识,不需要太深入,简单总结了如下几点:
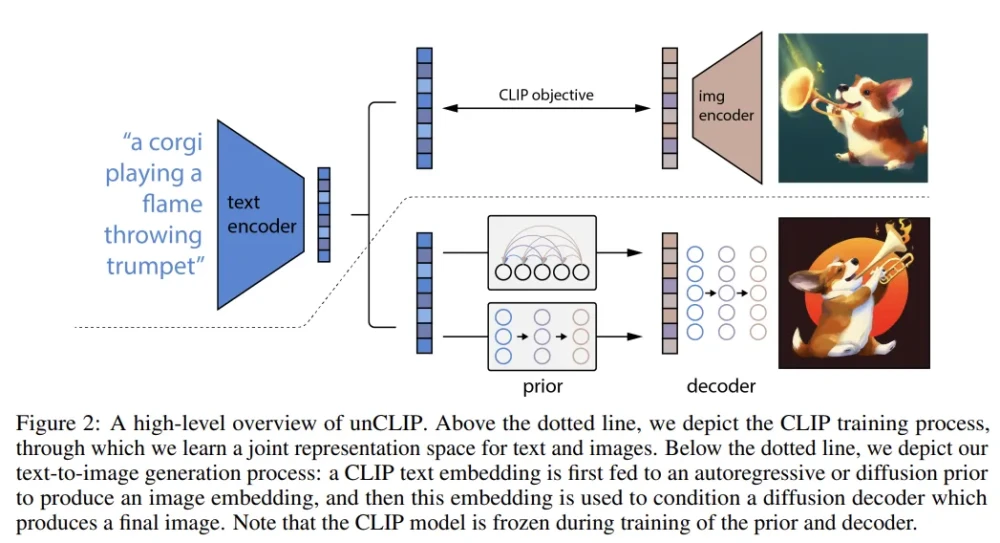
从上面的模型拆解中可以看出,DALL-E 2和Stable Diffusion的text encoder都是基于openAI提出的CLIP,图像的生成都是基于diffusion model。其中,CLIP是学习任意给定的图像和标题(caption)之间的相关程度。其原理是计算图像和标题各自embedding之后的高维数学向量的余弦相似度(cosine similarity)。
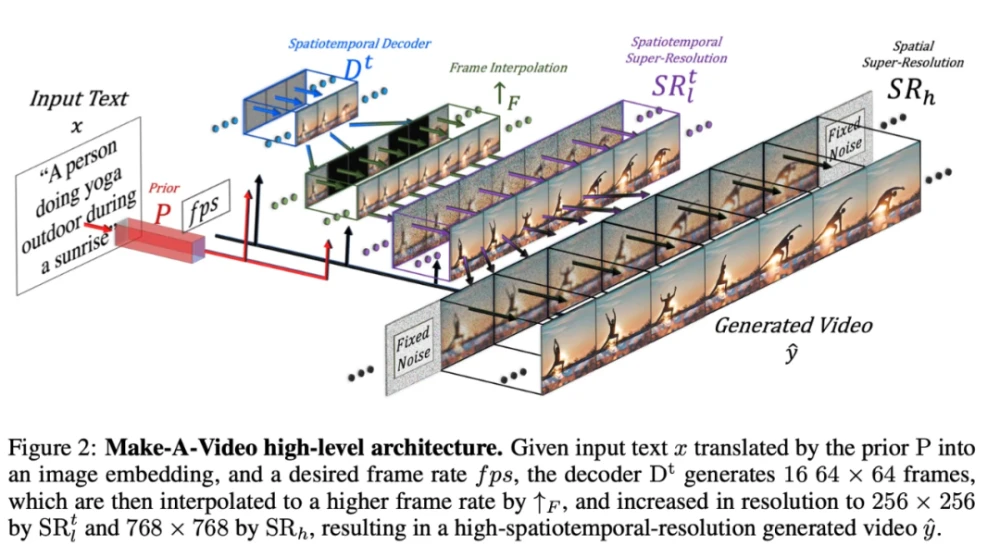
文本生成视频大概从2017年就开始有一些研究了,但一直都有很多限制。而从今年10月初Meta宣布了他们的产品Make-A-Video以及Google宣布了Imagen Video。这两款都是创新了Text-to-Video的技术场景。而这两款最新产品都是从他们的Text-to-Image产品衍生而言的,所以技术实现方式也是基于Text-to-Image的技术演变而成。
本质上来说我们可以认为静态图片就是只有一帧的视频。生成视频需要考虑图片中的元素在时间线上的变化,所以比生成照片会难很多,除了根据文本信息生成合理和正确的图片像素外,还必须推理图片像素对应的信息如何随时间变化。这里我们主要根据Make-A-Video的研究论文做一下拆解。
Make-A-Video正是建立在text-to-Image技术最新进展的基础上,使用的是一种通过时空分解的diffusion model将基于Text-to-Image的模型扩展到Text-to-Video的方法。原理很直接:
从文本-图像数据里学习描述的世界长什么样(文本生成图像)
从无文本的视频数据中学习世界的变化(图像在时间轴上的变化)
训练数据是23亿文本-图像数据(Schuhmann et al),以及千万级别的视频数据(WebVid-10M and HD-VILA-100M)。
整体上来说Make-A-Video也是有三个重要组成部分,所有的组成部分都是分开训练:
基于文本图像pair训练的基本的Text-to-Image的模型,总共会用到三个网络:
Prior网络:从文本信息生成Image特征向量,也是唯一接收文本信息的网络。
Decoder网络:从图像特征网络生成低分辨率64x64的图片。
两个空间的高分辨率网络:生成256x256和768x768的图片。
时空卷积层和注意层,将基于第一部分的网络扩展到时间维度
在模型初始化阶段扩展包含了时间维度,而扩展后包括了新的注意层,可以从视频数据中学习信息的时间变化
temporal layer是通过未标注的视频数据进行fine-tune,一般从视频中抽取16帧。所以加上时间维度的decoder可以生成16帧的图片
以及用于高帧速率生成的插帧网络
空间的超分辨率模型以及插帧模型,提高的高帧速率和分辨率,让视觉质量看起来更好。
举例:
文本描述生成的结果会有一些随机性,生成的图片大概率是很难完全按照“需求”生成,更多带来的是“惊喜”,这种惊喜在一定的层面上代表的也是一种艺术风格。所以在实际的使用中并不是很适用于按照严格要求生产图片的任务,而更多的适用于有一定的描述,能够给艺术创意带来一些灵感的迸发和参考。
文本的准确描述对于生成的图片样子是极其重要的,技术本身对文本描述和措辞有较高要求,需对脑海中的核心创意细节有较为准确的描述。
庄周

经过关键字输入:Ultra detailed illustration of a butterfly anime boy covered in liquid chrome, with green short hair, beautiful and clear facial features, lost in a dreamy fairy landscape, crystal butterflies around, vivid colors, 8k, anime vibes, octane render, uplifting, magical composition, trending on artstation

图像本身的融合变换在早几年的时候就已经有了一些研究和探索,且有了相对较为成熟的生成的样子,这里我们使用和平精英的素材尝试做一种变换风格的样子。
和平精英素材原图和星空:

更加深度的将星空的颜色和变化融合到原始图片中:

AI技术原理——原文:AI绘画火了!一文看懂背后技术原理
参考资料:
[1907.05600] Generative Modeling by Estimating Gradients of the Data Distribution
[2105.05233] Diffusion Models Beat GANs on Image Synthesis

👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
我最近与一位同事讨论了以下Ruby语法:value=ifa==0"foo"elsifa>42"bar"else"fizz"end我个人并没有看到太多这种逻辑,但我的同事指出,这实际上是一种相当普遍的Rubyism。我试着用谷歌搜索这个主题,但没有找到任何文章、页面或SO问题来讨论它,这让我相信这可能是一种非常实际的技术。然而,另一位同事发现语法令人困惑,而是将上面的逻辑写成这样:ifa==0value="foo"elsifa>42value="bar"elsevalue="fizz"end缺点是value=的重复声明和隐式elsenil的丢失,如果我们想使用它的话。这也感觉它与Ruby
您能为RubyonRails推荐好的数据网格类/gem吗?喜欢http://code.google.com/p/zend-framework-datagrid/采埃孚 最佳答案 你也可以试试datagridgem。这不仅关注带有列的网格,还关注过滤器。classSimpleReportincludeDatagridscopedoUser.includes(:group)endfilter(:category,:enum,:select=>["first","second"])filter(:disabled,:eboolean)fi
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion我正在为Rails3/ActiveRecord项目寻找一个相对简单的状态机插件。我做了一些研究并提出了以下插件:转换:https://github.com/qoobaa/transitions从旧的ActiveRecord状态机库中提取
在尝试构建Rubygem(使用Bundler)时,我倾向于使用Bundler提供的REPL测试代码——可通过bundleconsole访问。有什么方法可以重新加载整个项目吗?我最终再次加载单个(更改的)文件以测试新更改。 最佳答案 以下hack适用于我的一个相对简单的gem和Ruby2.2.2。我很想看看它是否适合你。它做出以下假设:您具有传统的文件夹结构:一个名为lib/my_gem_name.rb的文件和一个文件夹lib/my_gem_name/,其中包含任何文件/文件夹结构。您要重新加载的所有类都嵌套在您的顶级模块MyGemN
这个问题在这里已经有了答案:Nokogiri:SelectcontentbetweenelementAandB(3个答案)关闭2年前。我正在从url中抓取文本的div,并想删除具有backtotop类的段落下方的所有内容。我在stackoverflow上看到了一段遍历代码片段,看起来很有希望,但我不知道如何将它合并,所以@el只包含第一个p.backtotop之前的所有内容分区我的代码:@doc=Nokogiri::HTML(open(url))@el=@doc.css("div")[0]end遍历片段:doc=Nokogiri::HTML(code)stop_node=doc.css
今天我遇到了下面的正则表达式,想知道Ruby会用它做什么:>"#a"=~/^[\W].*+$/=>0>"1a"=~/^[\W].*+$/=>nil在这种情况下,Ruby似乎忽略了+字符。如果这是不正确的,我不确定它在做什么。我猜它没有被解释为量词,因为*没有转义并且被用作量词。在Perl/Ruby正则表达式中,有时当一个字符(例如,-)在不能被解释为特殊字符的上下文中使用时,它会被视为文字。但如果在这种情况下发生这种情况,我希望第一个匹配失败,因为左值字符串中没有+。这是对+字符的巧妙正确使用吗?以上行为是错误吗?我是否遗漏了一些明显的东西? 最佳答案
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们