程序设计课学到了链表,这东西很玄学,所以自己再从头梳理一下。
如果大佬发现哪里有问题的话,希望能帮我指出,谢谢!
目录
-->1.PTA 7-1 程序设计综合实践-1.1(简单的插入)
-->2.PTA 7-4 程序设计综合实践 1.4(简单的分离)
-->3.PTA 7-5 程序设计综合实践 1.5(简单的约瑟夫环)
--> 4.PTA 7-8 特殊约瑟夫问题(双向链表约瑟夫环问题)
把数组拿出来和链表做对比,可能更容易理解链表。
1.数组的内存是连续的。但是链表一般不连续。
2.数组的元素个数是确定的(加长数组在现在的c语言标准里是没有意义的),链表可以改变。
3.数组不可以删除元素,不可以添加元素(当然,可以用算法实现类似的操作,但是不是真正意义上的删除),链表可以。
4.数组可以下标访问,链表只能遍历访问,所以说数组访问是o(1),链表访问是o(n)。
说了这么多不还是没有说什么是链表吗?
别急,下面就是链表的基本样子。
struct node {
//数据区
int data;
//指针区
struct node* next;
};
一个链表的每一个节点由这样一个结构体组成,这个结构体内部分为数据和域指针域。数据域可以是这样一个简单的data,也可以是多个数据,甚至一个结构体。
通常的单向链表是有一个指向下一个节点的指针,还有双向链表(用两个指针记录上家和下家)。
链表的结尾通常指向NULL这也是链表结尾的标志。(循环链表除外)
和数组不同,链表的每一个节点都是通过动态分配得到的,每次创建节点的时候需要调用头文件<stdlib.h>中的函数malloc的声明。malloc函数的参数是所需要申请的内存空间大小,一般使用sizeof()函数来当其参数的,增强代码的移植性。malloc函数的返回值是一个(void*)类型的指针,我们需要转换成我们需要的指针,注意如果申请失败返回NULL,在申请的时候应该判断是否申请成功。下面是申请一个新节点的函数newnode()。
struct node* newnode()
{
struct node* p = (struct node*)malloc(sizeof(struct node));
//如果返回空指针,说明内存里面找不到满足要求的地方了,及内存不足。
if (p == NULL)
printf("Error!\a\n"), exit(-1);
//返回的p指向我们申请的节点
return (p);
}
根据链表的定义,每一个节点的指针指向下一个节点。我们需要使用到一种运算符 :
它由一个减号和一个大于符号组成由一个指针使用比如
ok有了基本知识就可以开始连接节点了。这里用最简单的单数据单向链表为例。构建函数add()
void add(struct node* la, int x)
{
struct node* q = newnode();
q->data = x; //把数据输入申请的节点中
struct node* p = la;//为了不改变la
while (p->next)//只要p->next 不指向空
{
p = p->next;//往后移一个位置
}
q->next = NULL;//链表结尾是NULL
p->next = q;
}
单向链表如果有一个没有参数的头节点会让操作方便很多。所以一般创建单向链表的时候会申请一个头节点,然后再加入带节点的数据。那么这时判断链表是否为空的办法就是判断head->next是否等于NULL。
int n;
struct node* la=newnode();
la->next = NULL;
while (scanf("%d", &n) != -1)
{
add(la,n);
}
这样插入数据之后的la就是链表的头节点,之后的操作只需要传入头节点就行。
void insert(struct node* la, int x)
{
struct node* q = newnode();
q->data = x;
//查找合适的位置插入
struct node* p = la;
while (p->next && x > p->next->data)
{
p = p->next;//往后移一个位置
}
//开始插入
q->next = p->next;
p->next = q;
}
void print(struct node* la)
{
la = la->next;//跳过头节点
if (la)
{
printf("%d", la->data);
la = la->next;
}
while (la)
{
printf("->%d", la->data);
la = la->next;
}
printf("\n");
}
注意不是删除,这是销毁整个链表,使用函数free()实现,特别提醒!!链表使用完之后一定要销毁,这是一个好习惯,因为在一个工程中如果不停的malloc节点但是不释放的话,会造成内存泄漏,后果就是程序会运行到内存中没有可用内存为止。
void destory(struct node* la)
{
while (la)
{
struct node* q = la->next;
free(la);
la = q;
}
}
把一个链表的所有数据倒序重排,但是头节点是不动的。注意
void reverse(struct node* la)
{
//跳过头节点
struct node* p = la->next;
la->next=NULL;//挂上最后一个节点也就是空
while (p)//每次把 p 挂到 la 后面,所以是判断 p 是否为NULL而不是p->next
{
struct node* q = p;//用 q 记下现在 p 的位置
p = p->next;// p 向后移
q->next = la->next;//把 q 插到 la 后面
la->next = q;
}
}
连接两个带头节点的链表,前面的参数为改过的链表.
void link(struct node* start, struct node* end)
{
while (start->next != NULL)
{
start = start->next;
}
start->next = end->next;
}
删除传入的地址的下一个元素,并重新连接链表,释放删除节点。
void deleta(struct node* la)
{
struct node* p = la->next;
la->next = p->next;
free(p);
}
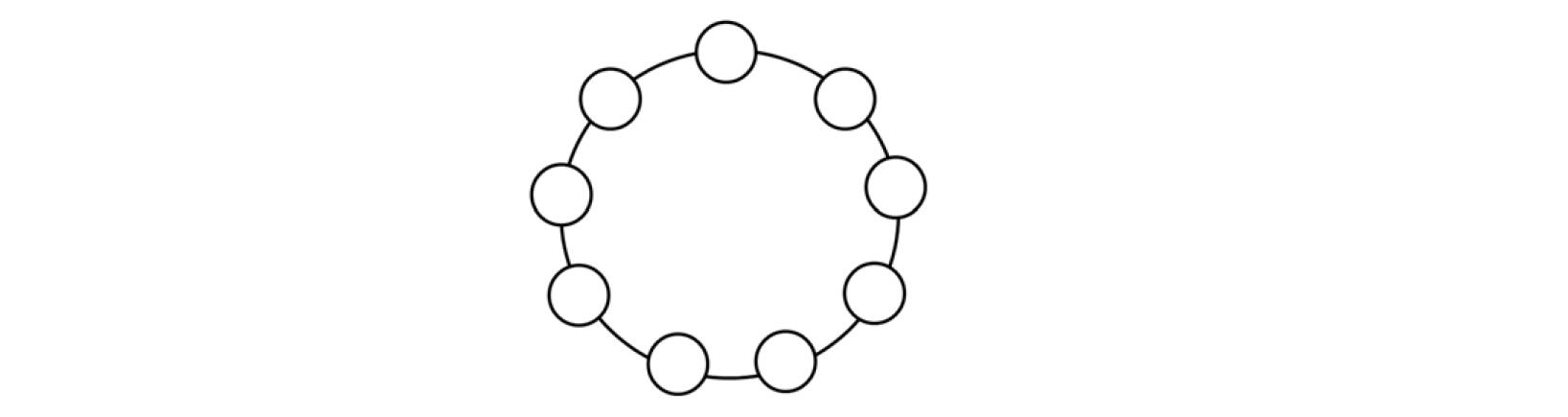
1. 什么是循环链表?(个人理解)
单向的,非循环的链表是以NULL为结尾,而循环链表是首尾相连的,它也没有头节点,最后一个节点指向的也不是NULL而是第一个节点,那么在读取链表数据的时候就会一直循环,所以叫循环链表。
这就是一个简单的循环链表,la指向第 4 个元素,然后依次链接,最后回到 4 。
2.循环链表的创建
上面说过了,循环链表是没有头节点的,只是一个指针去指向环的某一个元素就行了。我一般循环让这个指针指向尾节点,这样方便添加元素。因为添加节点需要首节点的地址,还需要尾节点的地址,但是我们现在还是用的单向链表,只能向下寻找节点,所以只有用尾节点同时找到这两个地址。如果是双向链表的话,可以直接指向第一个节点。
struct node* la = newnode();
la = NULL;
for (int i = 1; i <= n; i++)
{
la = append(la, i);//la指向最后一个人
}
struct node* append(struct node* la, int n)
{
if (!la)//空的判断第一个人需要特判,让它指向自己
{
struct node* p = newnode();
p->data = n;
p->next = p;
return p;
}
else
{
struct node* p = newnode();//新添加的节点
p->data = n;
struct node* q = la->next;//记录第一个节点的地址
la->next = p;//最后一个节点指向新加的节点,使得新的节点成为最后一个节点
p->next = q;//新的节点指向第一个节点,形成环
return p;//返回最后一个节点的地址
}
}
前面有提到过双向链表,顾名思义双向链表就是每一个节点都保存了上一个节点的地址和下一个节点的地址,使用起来会比单向链表简单,特别是在处理约瑟夫环的问题的时候。双向链表的构造和单向链表很像,这里我直接放代码了。
struct node {
int data;
struct node* last;
struct node* next;
};
typedef struct node node;//这种写法可以少敲 亿 个struct!!
//环形双向链表构造
node* append(node* la, int m)
{
node* p = newnode();
p->data = m;
if (la == NULL)
{
p->next = p;
p->last = p;
}
else
{
node* q;
q = la->next;
la->next = p;
p->last = la;
p->next = q;
q->last = p;
}
return p;
}1.PTA 7-1 程序设计综合实践-1.1(简单的插入)
1.1编写程序,建立2个带头结点单链表,输入若干整数将正整数插入第1个单链表,将负整数插入第2个单链表,插入前和插入后单链表保持递增或相等次序,显示2个单链表,最后销毁。程序不可存在内存泄漏。
输入格式:
若干整数。
输出格式:
每行显示一个链表,元素间用分隔符->分隔;共两行
输入样例:
100 2 3 -2 -8 -6 -9 -10 50 2 -1输出样例:
2->2->3->50->100 -10->-9->-8->-6->-2->-1
#include <stdio.h>
#include <stdlib.h>
struct node {
int data;
struct node* next;
};
void insert(struct node* la, int x);
struct node* newnode();
void print(struct node* la);
void destory(struct node* la);
int main()
{
int n;
struct node* zhen=newnode(), * fu = newnode();
zhen->next = NULL;
fu->next = NULL;
while (scanf("%d", &n) != -1)
{
if (n > 0)
{
insert(zhen, n);
}
else if (n < 0)
{
insert(fu, n);
}
}
print(zhen);
print(fu);
destory(zhen);
destory(fu);
return 0;
}
void insert(struct node* la, int x)
{
struct node* q = newnode();
q->data = x;
//查找合适的位置插入
struct node* p = la;
while (p->next && x > p->next->data)
{
p = p->next;//往后移一个位置
}
//插入之后
q->next = p->next;
p->next = q;
}
struct node* newnode()
{
struct node* p = (struct node*)malloc(sizeof(struct node));
if (p == NULL)
printf("Error!\a\n"), exit(-1);
return (p);
}
void print(struct node* la)
{
la = la->next;//跳过头节点
if (la)
{
printf("%d", la->data);
la = la->next;
}
while (la)
{
printf("->%d", la->data);
la = la->next;
}
printf("\n");
}
void destory(struct node* la)
{
while (la)
{
struct node* q = la->next;
free(la);
la = q;
}
}
2.PTA 7-4 程序设计综合实践 1.4(简单的分离)
1.4 编写程序,输入若干正整数,按从小到大次序建立1个带头结点单链表,设计一个实现单链表分离算法的Split函数,将原单链表中值为偶数的结点分离出来形成一个新单链表,新单链表中头结点重新申请,其余结点来自原链表,分离后,原链表中只剩非偶数值所在结点,最后显示2个单链表,在程序退出前销毁单链表。要求Split算法时间复杂性达到O(n),程序不可存在内存泄漏。
输入格式:
若干正整数。
输出格式:
每个单链表输出占一行,元素间用分隔符->分隔;初始单链表、剩余元素单链表、偶数元素单链表,共3行。
输入样例:
100 2 3 50 2 1 5 8输出样例:
1->2->2->3->5->8->50->100 1->3->5 2->2->8->50->100
#include <stdio.h>
#include <stdlib.h>
struct node {
int data;
struct node* next;
};
void insert(struct node* la, int x);
struct node* newnode();
void print(struct node* la);
void destory(struct node* la);
void link(struct node* start, struct node* end);
//返回奇数的头
void split(struct node* la,struct node*ji);
//删除下一个元素,记得释放哦!!
void deleta(struct node* la);
int main()
{
int n;
struct node *ou=newnode(),*ji=newnode();
ou->next = NULL;
ji->next = NULL;
while (scanf("%d", &n) != -1&&n!=0)
{
insert(ou, n);
}
print(ou);
split(ou,ji);
print(ji);
print(ou);
destory(ou);
destory(ji);
return 0;
}
void insert(struct node* la, int x)
{
struct node* q = newnode();
q->data = x;
//查找合适的位置插入
struct node* p = la;
while (p->next && x > p->next->data)
{
p = p->next;//往后移一个位置
}
//插入之后
q->next = p->next;
p->next = q;
}
struct node* newnode()
{
struct node* p = (struct node*)malloc(sizeof(struct node));
if (p == NULL)
printf("Error!\a\n"), exit(-1);
return (p);
}
void print(struct node* la)
{
la = la->next;//跳过头节点
if (la)
{
printf("%d", la->data);
la = la->next;
}
while (la)
{
printf("->%d", la->data);
la = la->next;
}
printf("\n");
}
void destory(struct node* la)
{
while (la)
{
struct node* q = la->next;
free(la);
la = q;
}
}
void link(struct node* start, struct node* end)
{
while (start->next != NULL)
{
start = start->next;
}
start->next = end->next;
}
//分离奇数和偶数
void split(struct node* la,struct node*ji)
{
struct node* q = la;//q酒店la的上一个
la = la->next;
while (la->next)
{
if (la->data % 2 == 1)
{
insert(ji, la->data);
la = la->next;
deleta(q);
continue;
}
q = la;
la = la->next;
}
}
void deleta(struct node* la)
{
struct node* p = la->next;
la->next = p->next;
free(p);
}3.PTA 7-5 程序设计综合实践 1.5(简单的约瑟夫环)
1.5 约瑟夫环是个经典的问题。有M个人围坐成一圈,编号依次从1开始递增,现从编号为1的人开始报数,报到N的人出列,然后再从下一人开始重新报数,报到N的人出列;重复这一过程,直至所有人出列。求出列次序。本题要求用循环单链表实现。提示:开始时将循环单链表的指针变量设为空,设计实现尾部添加一人函数Append,添加第1人时,将结点的指针域指向自己,后面新添加人员时,在循环单链表指针变量所指尾部后添加新结点,并始终将循环单链表指针变量指向新添加结点,对应M个人的循环单链表中有M个结点;报数时,报到指定数后输出对应结点里的人员编号,并将该结点从链表中删除。题目输入包括M、N两个正整数,题目要求按出队列顺序输出他们的编号。
输入格式:
正整数M、N
输出格式:
出队列次序,1行,每个数据占4位。
输入样例:
10 3输出样例:4
3 6 9 2 7 1 8 5 10 4
#include <stdio.h>
#include <stdlib.h>
struct node {
int data;
struct node* next;
};
void add(struct node* la, int x);
struct node* newnode();
void print2(struct node* la);
void destory(struct node* la);
void reverse(struct node* la);
void deleta(struct node* la);
//尾部添加元素
struct node* append(struct node* la,int n);
//开始游戏
struct node* runysf(struct node* la, int m);
int main()
{
int n, m;
scanf("%d%d", &n, &m);
struct node* la = newnode();
la = NULL;
for (int i = 1; i <= n; i++)
{
la=append(la, i);//la指向最后一个人
}
la=runysf(la, m);
destory(la);
return 0;
}
void add(struct node* la, int x)
{
struct node* q = newnode();
q->data = x;
//插在后面
struct node* p = la->next;
la->next = q;
q->next = p;
}
//申请新节点
struct node* newnode()
{
struct node* p = (struct node*)malloc(sizeof(struct node));
if (p == NULL)
printf("Error!\a\n"), exit(-1);
return (p);
}
//最小四段打印链表
void print2(struct node* la)
{
la = la->next;//跳过头节点
if (la)
{
printf("%4d", la->data);
la = la->next;
}
while (la)
{
printf("%4d", la->data);
la = la->next;
}
printf("\n");
}
//释放一个链表
void destory(struct node* la)
{
while (la)
{
struct node* q = la->next;
free(la);
la = q;
}
}
//倒序输出
void reverse(struct node* la)
{
struct node* p = la->next;
la->next = NULL;//考虑没有元素的情况
while (p)
{
struct node* q = p;
p = p->next;
q->next = la->next;
la->next = q;
}
}
//删除后一个元素
void deleta(struct node* la)
{
struct node* p = la->next;
la->next = p->next;
free(p);
}
//返回的指针指向最后一个人
struct node* append(struct node* la, int n)
{
if (!la)//空的判断
{
struct node* p = newnode();
p->data = n;
p->next = p;
return p;
}
else
{
struct node* p = newnode();
p->data = n;
struct node* q = la->next;
la->next = p;
p->next = q;
return p;
}
}
//运行游戏
struct node* runysf(struct node* la, int m)
{
struct node* p = newnode(),*q,*k=p;
p->next = NULL;
while (la)
{
for (int i = 0; i < m; i++)
{
if(i==m-1) q = la;
la = la->next;
}
add(p,la->data);
if (la->next != la)
deleta(q);//la被删除了!!q接上了la的下一个元素!!
else
{
la = NULL;
break;
}
la = q;
}
reverse(k);//因为add函数实现是倒序加入的,所以最后加一个reverse倒置链表
print2(k);
return k;
}4.PTA 7-8 特殊约瑟夫问题(双向链表约瑟夫环问题)
编号为1…N的N个小朋友玩游戏,他们按编号顺时针围成一圈,从第一个人开始按逆时针次序报数,报到第M个人出列;然后再从下个人开始按顺时针次序报数,报到第K个人出列;再从下一个人开始按逆时针次序报数,报到第M个人出列;再从下个人开始按顺时针次序报数,报到第K个人出列……以此类推不断循环,直至最后一人出列。请编写程序按顺序输出出列人的编号。
输入格式:
输入为3个正整数,分别表示N、M、K,均不超过1000。
输出格式:
输出为一行整数,为出列人的编号。每个整数后一个空格。
输入样例:
6 3 5输出样例:
5 3 1 2 4 6
#include <stdio.h>
#include <stdlib.h>
struct node {
int data;
struct node* last;
struct node* next;
};
typedef struct node node;
node* newnode();
node* append(node* la, int m);
void runysf(node* la, int m, int k,int n);
int main()
{
int n, m, k;
scanf("%d%d%d", &n, &m, &k);
node* la = newnode();
la = NULL;
for (int i = 1; i <= n; i++)
{
la=append(la, i);
}
la = la->next;//现在la是第一个数,我想让指到的那个节点为第一节点。
runysf(la, m, k,n);
}
node* newnode()
{
node* p = (node*)malloc(sizeof(node));
if (!p)
{
printf("Error!\a\n");
exit(-1);
}
return p;
}
node* append(node* la, int m)
{
node* p = newnode();
p->data = m;
if (la == NULL)
{
p->next = p;
p->last = p;
}
else
{
node* q;
q = la->next;
la->next = p;
p->last = la;
p->next = q;
q->last = p;
}
return p;
}
// m 为逆时针, k 为顺时针
void runysf(node* la, int m, int k,int n)
{
int a = 1;
while (n--)
{
if (a)
{
for (int i = 0; i < m-1; i++)
{
la = la->last;
}
printf("%d ", la->data);
node* p = la->next;
node* q = la->last;
free(la);
p->last = q;
q->next = p;
la = q;
a ^= 1;
}
else
{
for (int i = 0; i < k - 1; i++)
{
la = la->next;
}
printf("%d ", la->data);
node* p = la->last;
node* q = la->next;
free(la);
p->next = q;
q->last = p;
la = q;
a ^= 1;
}
}
}
好了,总结到此结束。感觉自己已经算是一个链表小白了呢,好耶!觉得有一点用的话,可以点一个赞哦,嘿嘿。
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺
前文,我们实现了认识了链表这一结构,并实现了无头单向非循环链表,接下来我们实现另一种常用的链表结构,带头双向循环链表。如有仍不了解单向链表的,请看这一篇文章(7条消息)【数据结构和算法】认识线性表中的链表,并实现单向链表_小王学代码的博客-CSDN博客目录前言一、带头双向循环链表是什么?二、实现带头双向循环链表1.结构体和要实现函数2.初始化和打印链表3.头插和尾插4.头删和尾删5.查找和返回结点个数6.在pos位置之前插入结点7.删除指定pos结点8.摧毁链表三、完整代码1.DSLinkList.h2.DSLinkList.c3.test.c总结前言带头双向循环链表,是链表中最为复杂的一种结
我有两个模型:store和category以及一个名为categories.stores的连接表。如何删除连接表中商店对象的所有关系数据?我可以使用其中之一吗:store.categories.destroy或category.stores.destroy注意:两个模型都是has_and_belongs_to_many(因此每个关联记录都没有标识符——只有store_id和category_id) 最佳答案 在has_and_belongs_to_many关联中,您可以使用delete_all或destroy_all。在has_ma
我的表格字段名称是小写的,而我从CSV文件中获取的字段名称是驼峰式的。无论如何我可以将哈希数组的键转换为小写吗?这是我现在的代码:CSV.foreach(file,:headers=>true)do|row|Users.create!(row.to_hash)end这是失败的,因为键是驼峰式的(我已经通过手动编辑文件使标题行全部小写来验证这一点)。附言。我也很想知道为什么Rails开始时会考虑表字段名称的大小写敏感性? 最佳答案 您可以只对CSV使用header_converters选项:CSV.foreach(file,:head
1,Camera基本工作原理答案:光线通过镜头Lens进入摄像头内部,然后经过IRFilter过滤红外光,最后到达sensor(传感器),senor分为按照材质可以分为CMOS和CCD两种,可以将光学信号转换为电信号,再通过内部的ADC电路转换为数字信号,然后传输给DSP(如果有的话,如果没有则以DVP的方式传送数据到基带芯片baseband,此时的数据格式RawData,后面有讲进行加工)加工处理,转换成RGB、YUV等格式输出。数据流是如何从sensor到APP的?上述描述结束后,在ISP处理后面的阶段,数据会进行分流,分为capture,preview,video等以供后续动作使用。例如
为了学习rubyonrails,可以构建哪些好的项目想法?有很多很棒的教程(rails3在运行,rails的敏捷web开发,railstutorial.org)但是它们都需要很长时间来浏览整本书。而且,它们为用户提供了即时的答案,而不是要求用户自己解决问题。什么是短而简单的项目,初学者可以尝试不只是遵循一个长教程?我认为一个博客和一个待办事项列表是很好的启动项目?还有什么?(项目应该让初学者接触到rest和crud) 最佳答案 一个好的开始是RailsforZombies我会去看看。如果你喜欢的话,CodeSchool有很多很棒的资
📢博客主页:https://blog.csdn.net/dxt19980308📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!📢本文由肩匣与橘编写,首发于CSDN🙉📢生活依旧是美好而又温柔的,你也是✨目录🔴线性表1.1顺序表1.1.1顺序表定义1.1.2顺序表基本操作1.2单链表1.2.1单链表节点定义1.2.2单链表基本操作1.3双链表1.3.1双链表节点定义1.3.2双链表基本操作1.4静态链表🟠栈和队列2.1栈2.1.1顺序栈2.1.2链式栈2.2队列2.2.1顺序队列2.2.2链式队列2.3应用🟡串3.1串的定义与实现3.2串的模式匹配🟢树与二叉树4.1二叉树4.1.1二叉树的概念4.1.2