SQL执行频率
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信
息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
-- session 是查看当前会话 ;
-- global 是查询全局数据 ;
SHOW GLOBAL STATUS LIKE 'Com_______';

假如说是以查询为主,我们又该如何定位针对于那些查询语句进行优化呢? 此时我们可以借助于慢查询日志。
慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有
SQL语句的日志。
MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量 slow_query_log。

若要开启慢查询日志,需要在mysql配置文件(/etc/my.cnf)中配置如下信息:
#开启MySql慢日志查询开关:
slow_query_log=1
#设置慢日志的时间为2s,SQL语句执行超过2s,就会视为慢查询,记录到慢查询日志
long_query_time=2
配置完毕之后,通过以下指令重新启动MySQL:
systemctl restart mysqld
然后,再次查看开关情况,慢查询日志就已经打开了。

执行命令:cat /var/lib/mysql/localhost-slow.log 或者执行tail -f /var/lib/mysql/localhost-slow.log查看慢查询日志信息。
执行如下SQL语句 :select count(*) from tb_user;
检查慢查询日志 :最终我们发现,在慢查询日志中,只会记录执行时间超多我们预设时间(2s)的SQL,执行较快的SQL是不会记录的。
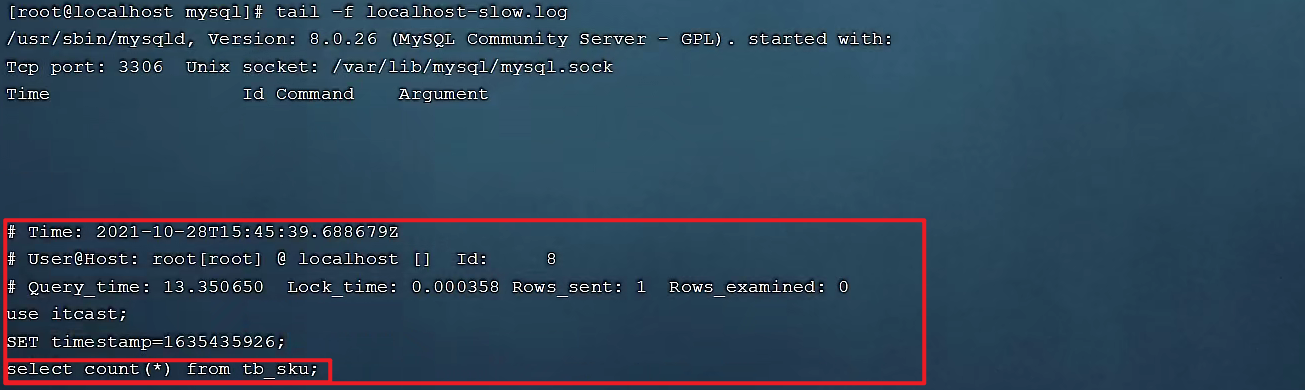
通过慢查询日志,就可以定位出执行效率比较低的SQL,从而有针对性的进行优化
profile详情
show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。通过have_profiling
参数,能够看到当前MySQL是否支持profile操作:SELECT @@have_profiling ;

可以看到,当前MySQL是支持 profile操作的,但是开关是关闭的。可以通过set语句在
session/global级别开启profiling:
SET profiling = 1;
开关已经打开了,接下来,我们所执行的SQL语句,都会被MySQL记录,并记录执行时间消耗到哪儿去
了。 我们直接执行如下的SQL语句:
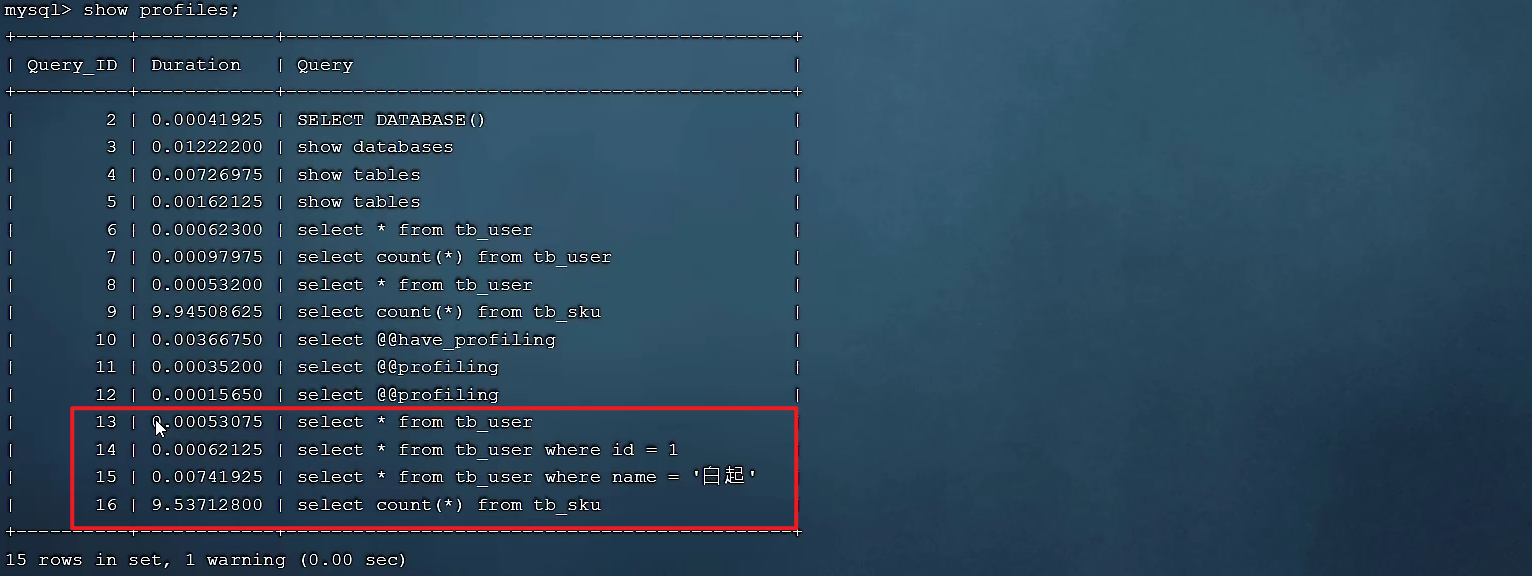
select * from tb_user;
select * from tb_user where id = 1;
select * from tb_user where name = '白起';
select count(*) from tb_sku;
执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
-- 查看每一条SQL的耗时基本情况
show profiles;
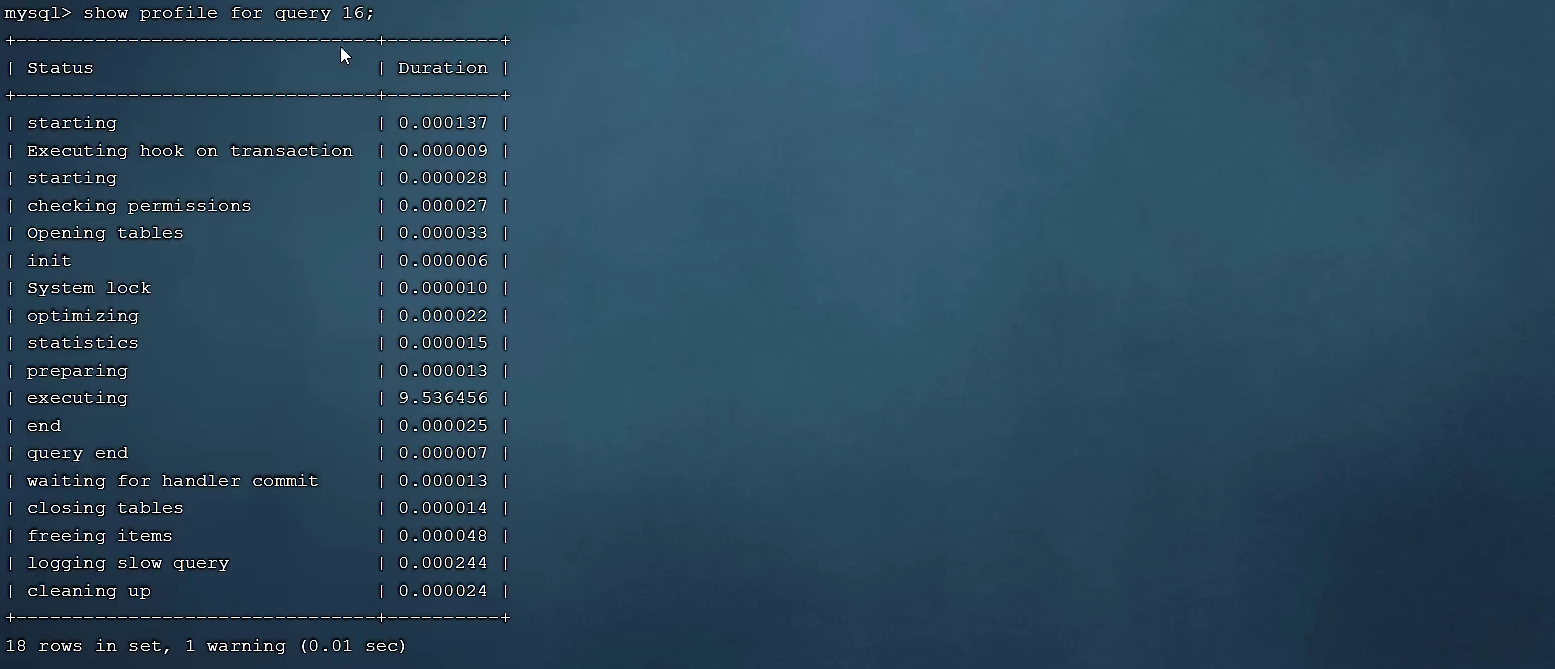
-- 查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query query_id;
-- 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;
查看每一条SQL的耗时情况:
查看指定SQL各个阶段的耗时情况 :
explain
EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行
过程中表如何连接和连接的顺序。
语法:
-- 直接在select语句之前加上关键字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 ;

Explain 执行计划中各个字段的含义:
id:select查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行)。
select_type:表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、
UNION(UNION 中的第二个或者后面的查询语句)、
SUBQUERY(SELECT/WHERE之后包含了子查询)等
type:表示连接类型,性能由好到差的连接类型为NULL、system、const、eq_ref、ref、range、 index、all 。
possible_key: 显示可能应用在这张表上的索引,一个或多个。
key: 实际使用的索引,如果为NULL,则没有使用索引。
key_len:表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下, 长度越短越好 。
rows:MySQL认为必须要执行查询的行数,在innodb引擎的表中,是一个估计值,可能并不总是准确的。
filtered: 表示返回结果的行数占需读取行数的百分比, filtered 的值越大越好。
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有
Ruby中防止SQL注入(inject)的好方法是什么? 最佳答案 直接使用ruby?使用准备好的语句:require'mysql'db=Mysql.new('localhost','user','password','database')statement=db.prepare"SELECT*FROMtableWHEREfield=?"statement.execute'value'statement.fetchstatement.close 关于ruby-防止SQL注入(inject
我正在编写一个Rails应用程序,它将监视某些特定数据库的数据质量。为了做到这一点,我需要能够对这些数据库执行直接SQL查询——这当然与用于驱动Rails应用程序模型的数据库不同。简而言之,这意味着我无法使用通过ActiveRecord基础连接的技巧。我需要连接的数据库在设计时是未知的(即:我不能将它们的详细信息放在database.yaml中)。相反,我有一个模型“database_details”,用户将使用它来输入应用程序将在运行时执行查询的数据库的详细信息。因此与这些数据库的连接实际上是动态的,细节仅在运行时解析。 最佳答案
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标