MySql系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解mysql索引本质 | https://blog.csdn.net/zhenghuishengq/article/details/121027025 |
| 【二】深入理解mysql索引优化以及explain关键字 | https://blog.csdn.net/zhenghuishengq/article/details/124552080 |
| 【三】深入理解mysql的索引分类,覆盖索引(失效),回表,MRR | https://blog.csdn.net/zhenghuishengq/article/details/128273593 |
| 【四】深入理解mysql事务本质 | https://blog.csdn.net/zhenghuishengq/article/details/127753772 |
| 【五】深入理解mvcc机制 | https://blog.csdn.net/zhenghuishengq/article/details/127889365 |
| 【六】深入理解mysql的内核查询成本计算 | https://blog.csdn.net/zhenghuishengq/article/details/128820477 |
| 【七】深入理解mysql性能优化以及解决慢查询问题 | https://blog.csdn.net/zhenghuishengq/article/details/128854433 |
| 【八】深入理解innodb和buffer pool底层结构和原理 | https://blog.csdn.net/zhenghuishengq/article/details/128993871 |
| 【九】深入理解mysql执行的底层机制 | https://blog.csdn.net/zhenghuishengq/article/details/128100377 |
| 【十】深入理解mysql集群的高可用机制 | https://blog.csdn.net/zhenghuishengq/article/details/126239652 |
| 【彩蛋篇】深入理解顺序io和随机io | https://blog.csdn.net/zhenghuishengq/article/details/129080088 |
深入理解顺序io和随机io
在研究顺序io和随机io之前,先了解一下这个机械磁盘,一个机械磁盘的官方图片如下,其主要由主轴,磁头,磁盘,磁头臂等等部分组成。接下来谈一下各个组件的作用。

磁盘 :数据是存储在磁盘的盘片上面的,磁盘由多个盘片组成,主要是通过盘片的转动来让磁头读取数据的。
磁头:在需要读取数据的时候,磁头就会移到这个盘片上面读取数据,如果出现断电的情况,那么磁头就会从盘片上移开移回到原来的位置,磁头和盘片之间的距离非常的小。
磁头臂:磁头臂主要是控制这个磁头进行一个移到和旋转,让磁头去读取内容和归位。由于多个磁头都绑定在一个磁头臂上面,因此多个磁头都是一起移动的,其距离,方向等都是一模一样的。
主轴:通过主轴的转动来实现这个盘片的移动。
在磁盘内部,又对 磁盘上的每个盘片 进行了更加精确的细分。如下图,每个盘片上面都由磁道和扇区组成,磁道是由一个一个的小圆环组成,每一个圆圈又进行了一个更小的划分,被称为扇区,如下面所示,一个磁道由八个扇区组成。
现在市面上流行的基本上是这种,一个磁盘八个扇区,每个扇区存储512个字节数据,并且在磁盘中也是以页为单位存储数据,和innodb的页不同,他是八个扇区为一个页,即一页大小为4kb,在读取某一个扇区的内容时,会将一页的数据全部给读取出来,因此一般一次磁盘io出来的数据就是4kb。如innodb存储引擎,在存储数据时,innodb中的页就是16kb的,因此存满一页数据需要四次的磁盘io。
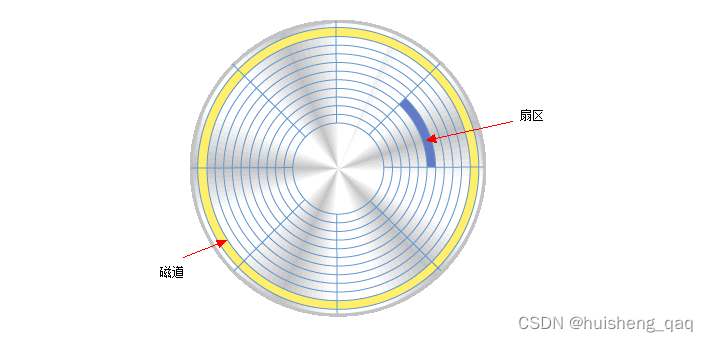
又由于一个磁盘上面存在多个盘片,而多个磁头又是固定在磁盘臂上面的,那么多个盘片就会形成如下图所示,形成一个圆柱体,多个盘片对应位置的磁道就形成了一个柱面。如下面的黄色部分,四个盘面都有这个黄色的磁道,这样黄色部分的四个磁道就形成了一个圆柱体状的柱面。因此要确定数据在哪个位置,首先得确定柱面号,即是属于黄色部分还是蓝色部分,先将这个圆柱体状的柱面找到,再确定盘片号,即数据是在哪个盘片的盘面上,最后确定扇区。
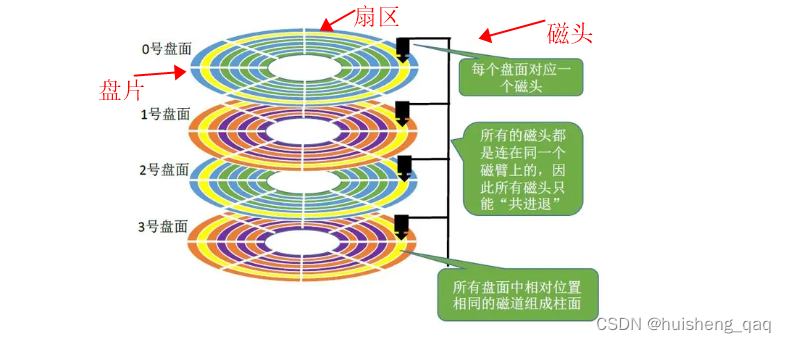
在确定数据的位置之后,就需要开始移动这个磁头,将磁头定位到具体磁道,如上图的最上面的那个磁头,在0号盘面上,其先定位到黄色部分的那个磁道;在定位到具体的磁道之后,就通过这个主轴将盘片转动,将扇区转动到磁头指向的地方,这样就可以定位到具体的扇区了,那么就可以将扇区的全部内容读取出。
在整个读取数据的过程中,主要分为三个时间:寻找磁道和盘面时间 + 盘面旋转时间 + 读取和传输数据的时间 ,就是一次磁盘的io读取数据的时间,大概在 9 - 10ms 左右。寻找磁道和盘面需要移动磁头臂,而盘面旋转找扇区的时间可以忽略不,因为现在的设备都是 5600r/s,7200r/s,转一圈的需要的时间微乎其微;从磁盘读取数据由于是按扇区直接读取,其时间也可以忽略不计;那么这个寻找磁道和盘面,就需要花费最多的时间了,因为需要来回移动磁头,这是一个很重的物理量操作。
因此这就解释了为什么要按扇区读取数据了,因为定位到具体的位置花费的时间长,所以直接读取整个扇区的数据,省的将磁头移来移去,并且在这种读取磁盘数据时,会顺便的将周围的扇区里面的值也读取出来,也是为了解决移动磁头很耗时的问题,这种方式被称为预读,如读取mysql数据,会通过预读的方式将周围的数据读取出来。
因此,磁盘读取数据的最小单位就是扇区。即使只需要读取里面的一个字节,也需要将整个扇区的内容全部读出。
在得知磁盘的底层运行原理之后,这里就知道了为啥随机io要比顺序io慢的原因了。由于在磁盘中读取数据时,盘面旋转的时间和读取数据的时间可以忽略不计,主要是这个寻找磁道和盘面要花较多的时间,即移动磁头需要花费大量的时间,那么主要是在这个地方拉开时间差的。
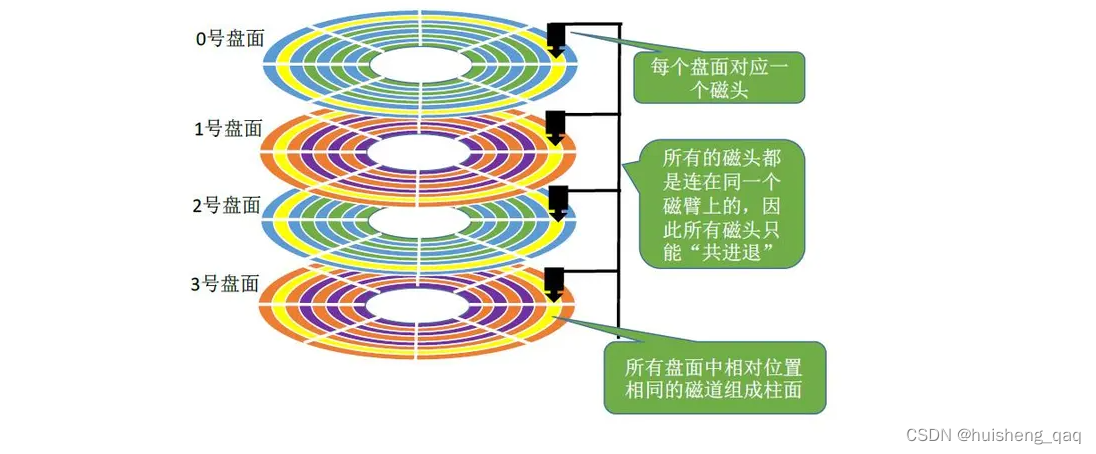
举个例子,依旧选择上面的黄色部分的磁道,那么拿顺序io来说,由于顺序io是有序的,那么如果数据只分布在一个磁道里面,那么这些数据都是连续有序的,那么读取这一个磁道的数据,顺序io和随机io可能都差不多,因为磁头不需要移动,随机io产生的时间可能比顺序io产生的时间多就是磁道旋转的次数,可能随机会多转几圈
但是,如果数据随机分布在整个盘片上,那就不一样了。依旧选择黄色部分和最外面的蓝色部分两个磁道,假设数据随机分布在两个磁道上面,旋转和读取的时间忽略不计,那么顺序io只需要磁头移动两次;而随机io就不一样了,上面八个扇区,如果第一次在这个磁道,第二次又去了那个磁道…,那么随机io的磁头移动的次数是2到16次,这样顺序io是小于或者远小于随机io的时间的
照此类推,假设要读取的数据分布在整个磁盘的随机位置,如上图假设10个磁道,那么顺序io的磁头只需要移动10次,但是随机io需要移动 10 到 80次,这样才能将数据全部读完,由于移动时间是整个时间最耗时的,因此随机io在最坏的情况下,其消耗的时间远远大于顺序io。而且上面只讨论在一个盘面,如果是在多个盘面的情况下,其随机IO的最坏时间更要远远的超出这个顺序IO的时间了。
顺序io的效率是随机io的40-400倍,当然除了顺序读,顺序写也是随机写的10-100倍,其原理一样,主要是寻道时间比较长。
磁盘在读取数据时,直接将一个扇区的数据读取出,这个行为被称为预读。不仅仅是在磁盘中,在cpu,内存,甚至在整个计算机中,预读的使用都比较频繁。和计算机中的局部性原理相关,这个原理也是在磁盘,内存,ssd盘中都会使用到这个原理。即一个数据在被读取时,其附近的的数据也通常会被使用。
在数据预读的时候,可能并不只读一个扇区,而是读连着的几个扇区,数据预读的单位是以页为单位的,一页的大小大概在4kb左右,所以操作系统在处理磁盘的数据的时候,是以页为单位将数据载入到内存中的。
看一段代码,如下
/**
* @Author: zhenghuisheng
* @Date: 2023/02/13 02:03
*/
public class ArrayTest {
public static void main(String[] args) {
int k = 10000 , p = 10000 , sum1 = 0 , sum2 = 0;
//定义一个二维数组
int data[][] = new int[k][p];
for (int i = 0; i < k; i++) {
for (int j = 0; j < p; j++) {
data[i][j] = i % 10;
}
}
long firstTime = System.currentTimeMillis();
for (int i = 0; i < k; i++) {
for (int j = 0; j < p; j++) {
//按行操作
sum1 += data[i][j];
}
}
System.out.println("按行操作消耗的时间 :"+(System.currentTimeMillis() - firstTime));
long secondTime = System.currentTimeMillis();
for (int i = 0; i < k; i++) {
for (int j = 0; j < p; j++) {
//按列操作
sum2 += data[j][i];
}
}
System.out.println("按列操作消耗的时间 :"+(System.currentTimeMillis()-secondTime));
}
}
其运行结果如下,其按列消耗的时间大概是按行消耗消耗的时间的30倍。而且这不是最坏的情况,因为随机io的时间是不确定的,但是肯定会大于顺序io。
按行消耗的时间 : 118ms
按列消耗的时间 : 3022ms
一个二维数组,其实就是由多个一维数组组成。而在一维数组中,其内存地址是一块连续的空间,那么在按行读取数据的情况下,这个二维数组也是一块连续的地址。如下面这个数组
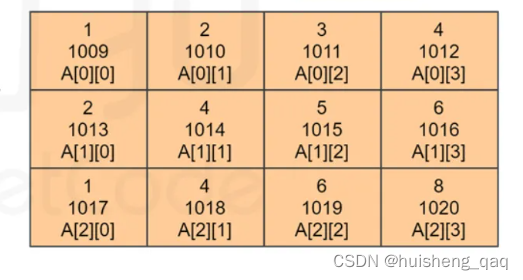
其按行读取数据的过程如下图,其就是一个内存的顺序读取数据的过程。其值从1009,一直到1020都是排好序的,因此在数组中按行读就是一个顺序读取数据的一个过程。

按列读取数据就不一样了,由于按行是顺序的连续的地址,那么按列肯定就是不连续的,随机的地址了,因此按列读取数据就是一种类似于内存的随机读取数据的过程。如下图,在读取到第一个数据后,读取第二个数据就要开始找位置了,我这里数据少,是在第5个位置,但是如果像上面的代码是10000 x 10000的情况下,那么就需要找找到第10001个数据,才是第二个数据,第三个数据在20001个位置,以此类推…。这样每个数据都需要跳来跳去的在这个连续的空间中寻找,这样查询时间就占很大一部分了。

这就解释了,为什么在计算机底层中,那么倾向于往顺序io的方向优化了。
首先磁盘通过预读的方式读取数据,有可能不仅仅是加载磁盘中一页数据,也可能是加载好几页的数据(磁盘中一页数据为8个扇区的数据,每个扇区512kb,那么一页就是4kb的数据)。所以在innodb的存储引擎中,也可能直接通过预读的方式,将innodb的一页甚至多页数据给直接的全部读取出来,innodb一页数据是16kb,和这个磁盘中的数据页本质不同。
并且在innodb的存储引擎中,其索引的本质就是一棵b+树,所有的数据都是在聚簇索引上面的,因此其内部是排好序的,如果是顺序io,那么一次就可以将当前页的数据和周围页的数据通过预读的方式给读取出来,因此B+树的有序性,也非常适应这个顺序读写,假设b+树不是顺序的,那么要读取相邻的顺序,那么就可能需要不断的来回移动这个磁头来定位,这样也是需要花费大量的时间的,所以mysql底层也是选择有序的b+树来作为索引,也是更符合顺序读写的原则。所以b+树的叶子结点为什么是顺序的,也可以从这个顺序io这个方面来解释
因此在mysql内部进行优化的时候,都是让数据进行顺序读写的,而不是随机读写的,如mysql对顺序读写有这些体现点:如MRR机制,对回表的id进行一个排序,然后进行一个顺序的查找,从而减少回表时的随机读写;还有redolog的日志,也是顺序的写,等等。其目的就是为了减少寻找磁道和扇区的时间,减少磁头移动的时间,因为磁头移动是一个机械运动,是一个重操作,需要花费大量的时间。
除了这个mysql内部对顺序读写有着一些相关的优化,还有如kafka等内部也是使用了这个顺序io的。
这里主要是了解磁盘中的随机读和顺序读,当然内存,ssd盘等都有顺序io和随机io,虽然内部实现方式和磁盘不大一样,但是顺序io的时间都是小于或者远小于随机io的时间的。
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
RSpec似乎按顺序匹配方法接收的消息。我不确定如何使以下代码工作:allow(a).toreceive(:f)expect(a).toreceive(:f).with(2)a.f(1)a.f(2)a.f(3)我问的原因是a.f的一些调用是由我的代码的上层控制的,所以我不能对这些方法调用添加期望。 最佳答案 RSpecspy是测试这种情况的一种方式。要监视一个方法,用allowstub,除了方法名称之外没有任何约束,调用该方法,然后expect确切的方法调用。例如:allow(a).toreceive(:f)a.f(2)a.f(1)