目录
2.2.1 本地模式(Standalone Operation)
2.2.2 伪分布式(Pseudo-Distributed Operation)
2.2.3 完全分布式(Fully-Distributed Operation)
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群实现高速运算和存储。
Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop主要是针对大数据所设计的分布式文件存储工具,所以它有一下特点:
高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
高容错性:能够自动将失败的任务重新分配。
hadoop Common: 包括Hadoop常用的工具类,主要包括系统配置工具Configuration、远程过程调用RPC、序列化机制和Hadoop抽象文件系统FileSystem等。
Hadoop Distributed File System (HDFS): 分布式文件系统,提供对应用程序数据的高吞吐量,高伸缩性,高容错性的访问。
Hadoop YARN: 任务调度和集群资源管理。
Hadoop MapReduce: 基于YARN的大型数据集并行处理系统。是一种计算模型,用以进行大数据量的计算。
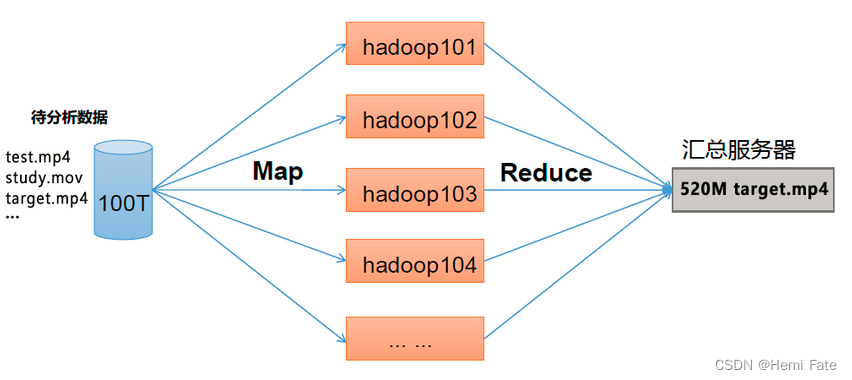
在大数据的计算中,迁移计算往往比迁移数据更有效。
该架构主要分为3个模块:NameNode、DataNode、Secondary NameNode
NameNode(NN):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
DataNode(DN):在本地文件系统存储文件块数据,以及块数据的校验和。
Secondary NameNode(2NN):每隔一段时间对NameNode元数据备份。
该架构主要分为4个模块:ResourceManager、NodeManager、ApplicationMaster、Container;
ResourceManager(RM):整个集群资源(内存、CPU等)的管理者;
NodeManager(NM):单个节点服务器资源的管理者;
ApplicationMaster(AM):单个任务运行的管理者;
Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。

该架构主要分为2个阶段:Map阶段、 Reduce 阶段
Map 阶段:并行处理输入数据
Reduce 阶段:对Map 结果进行汇总


名词解释:
Sqoop:Sqoop 是一款开源的工具,主要用于在Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop 的HDFS 中,也可以将HDFS 的数据导进到关系型数据库中。
Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据。
Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统。
Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于Hadoop 上存储的大数据进行计算。
Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
Oozie:Oozie 是一个管理Hadoop 作业(job)的工作流程调度管理系统。
Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
Hive:Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL 查询功能,可以将SQL 语句转换为MapReduce 任务进行运行。其优点是学习成本低,可以通过类SQL 语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce 应用,十分适合数据仓库的统计分析。
ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
官网:https://hadoop.apache.org
官方文档:https://hadoop.apache.org/docs
下载连接:https://hadoop.apache.org/releases.html
本文实验所需要的安装包:
jdk-18_linux-x64_bin.tar hadoop-3.2.1.tar
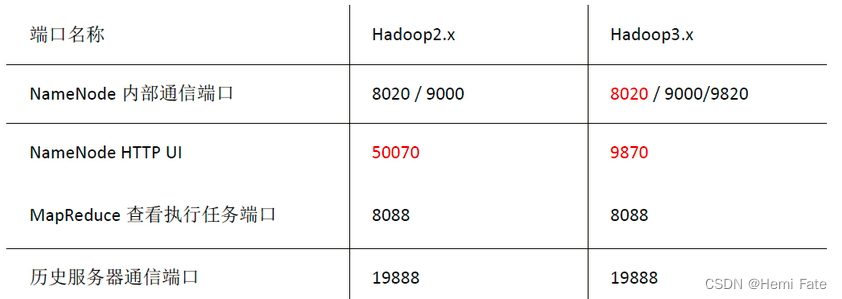
常用端口说明:
###在对应的网站下载相应的包
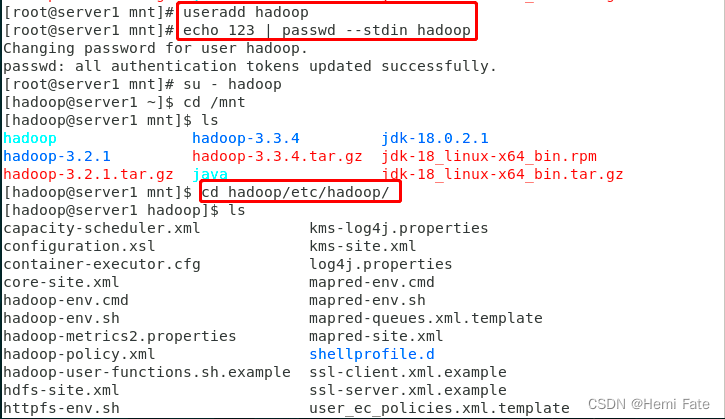
##创建指定的hadoop用户进行操作
useradd hadoop
echo hadoop | passwd --stdin hadoop
mv * /home/hadoop/
su - hadoop
##对数据包进行解压
tar zxf jdk-8u181-linux-x64.tar.gz
tar zxf hadoop-3.2.1.tar.gz
##设置相应的软连接
ln -s jdk1.8.0_181/ java
ln -s hadoop-3.2.1/ hadoop
##修改环境变量,指定Java和Hadoop的路径
vim hadoop-env.sh
-export JAVA_HOME= /home/hadoop/java
-export JAVA_HOME= /home/hadoop/hadoop
【注】创建软连接是为了更好的在版本升级时的切换。

Hadoop运行模式分为3种:本地模式 、伪分布式模式以及完全分布式模式
本地模式:单机运行,演示官方案例,生产环境一般不使用;
伪分布式模式:单机运行,具备 Hadoop集群的所有功能。一台服务器模拟一个分布式的环境 。可内部测试使用,生产环境不用。
完全分布式模式: 多台服务器组成分布式环境。 生产环境使用。
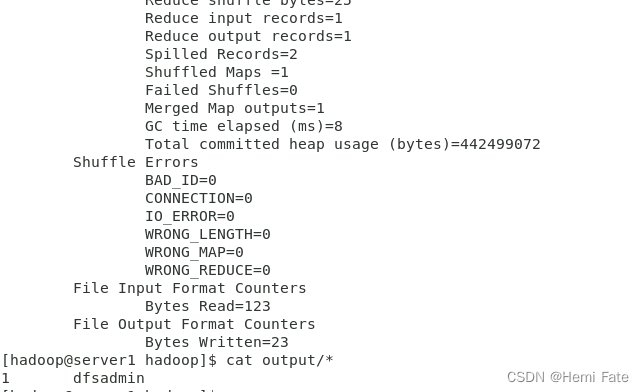
创建input目录,将默认配置文件目录中以xml文件为后缀的拷贝到input目录,使用jar命令过滤input目录文件中以dfs开头的内容,并且自动创建output目录
##在Hadoop目录下完成
##创建目录
mkdir input
##目录里输入内容
cp etc/hadoop/*.xml input
##进行目标查找
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
##查看结果
cat output/*
在单个节点上运行,其中每个Hadoop守护进程在单独的Java进程中运行
配置:
##查看本机的workers
cat etc/hadoop/workers
##修改配置文件,设置本机为master
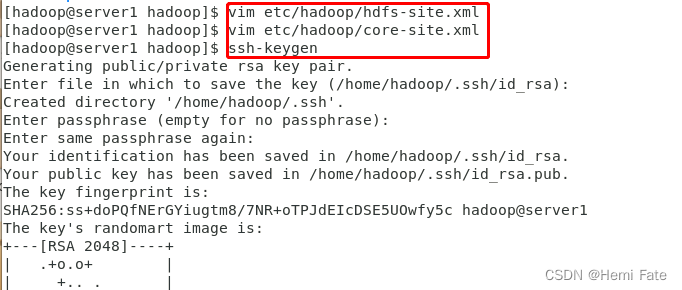
vim etc/hadoop/core-site.xml
-----------------------------
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
----------------------------
##设置副本数为1
vim etc/hadoop/hdfs-site.xml
-----------------------------
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
-----------------------------
##检查ssh的免密登录
ssh-keygen
ssh-copy-id localhost #密码则为用户hadoop的密码
ssh localhost #如果不需要密码,则免密登陆成功
exit #使用exit退出ssh,否则会叠加shell,引起错乱
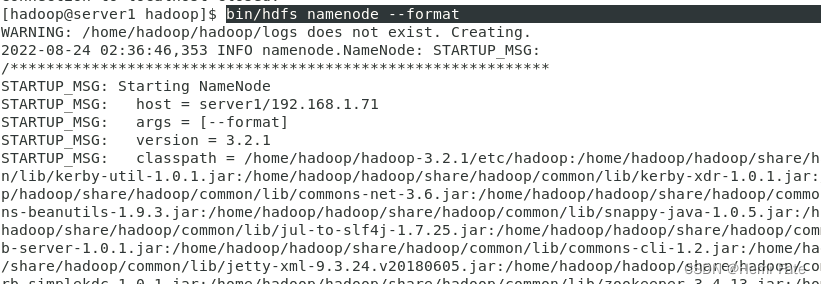
##初始化化文件系统--初始化后的文件都在tmp中,可以进行查看
bin/hdfs namenode -format
##启动NameNode守护程序和DataNode守护程序
sbin/start-dfs.sh
##使用jps查看当前进程---->jps是jdk提供的一个查看当前java进程的小工具(在java/bin)
##我们可以直接写入环境变量中
vim ~/.bash_profile
-----------------------
PATH=$HOME/java/bin
##创建分布式用户目录/user/hadoop(该子目录的名字hadoop必须与操作用户hadoop一致)
bin/hdfs dfs -mkdir /user/hadoop ---->创建完成后即可查看
##使用浏览器打开节点--->图形界面查看信息
172.25.21.1:9870
##使用命令行查看信息
bin/hdfs dfsadmin -report

使用:
##在分布式文件系统中创建input目录,输入数据
bin/hdfs dfs -mkdir input
bin/hdfs dfs -put etc/hadoop/*.xml input
##查看文件内容---web页面也可以查看
bin/hdfs dfs -ls
bin/hdfs dfs -ls input/
##测试--使用Hadoop自测的包,统计里面的数字并输出到相应的文件中
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output
bin/hdfs dfs -ls
bin/hdfs dfs -cat output/* -----此时生成的ouput目录在分布式文件系统中,与本地的output无关
master的端口为:9000
datanode的端口为:9866


【注】在文件输出时,目标文件不能存在
输入文件在web界面查看:

将NN和DN分开
##停止之前的hdfs
--sbin/stop-dfs.sh
##workers文件中指定数据节点--这里要提前做好解析
server2
server3
##server1中修改etc/hadoop/core-site.xml 文件,由于是完全分布式,必须指定ip
----------------------
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.21.1:9000</value>
</property>
</configuration>
----------------------
##修改hdfs etc/hadoop/hdfs-site.xml -----设置由两个数据节点
----------------------
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
----------------------
##安装nfs,设置开机启动--->使配置文件共享
yum install nfs-utils -y
systemctl enable --now nfs
##sever2\3创建相应的hadoop用户,使ID保持一致
useradd hadoop
id hadoop
##server1配置网络共享/home/hadoop,让hadoop用户有权力可读可写,并重启nfs服务
vim/etc/exports
--------
/home/hadoop *(rw,anonuid=1000,anongid=1000)
--------
systemctl restart nfs
showmount -e #查看文件挂载的目录
##server2 server3 分别挂载网络文件
mount 172.25.21.1:/home/hadoop/ /home/hadoop/
su - hadoop
ls
##配置完成后进入server1 初始化配置
bin/hdfs namenode -format
##开启server1上的namenode
##开启后发现server2和server3上的datenode也被打开,使用jps查看进程
jps #每个节点分别查看,可以看到相应的节点身份
##网页中也可以查看
172.25.21.1:9870(nn端)
##设置新加入节点的最基本信息
yum install -y nfs-utils.x86_64 #安装nfs
useradd hadoop ##创建hadoop用户
id hadoop #确保uid和gid都是1000
mount 172.25.21.1:/home/hadoop/ /home/hadoop/ ##挂载网络文件目录
df ##查看挂载
##配置server1中的worker文件,设置工作节点为3个
##在新加入的节点中,启动相应的数据节点
bin/hdfs --daemon start datanode
jps ##查询java进程
##在网络端查看即可在编写Ruby(客户端脚本)时,我看到了三种构建更长字符串的方法,包括行尾,所有这些对我来说“闻起来”有点难看。有没有更干净、更好的方法?变量递增。ifrender_quote?quote="NowthatthereistheTec-9,acrappyspraygunfromSouthMiami."quote+="ThisgunisadvertisedasthemostpopularguninAmericancrime.Doyoubelievethatshit?"quote+="Itactuallysaysthatinthelittlebookthatcomeswithit:themo
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
我正在尝试在配备ARMv7处理器的SynologyDS215j上安装ruby2.2.4或2.3.0。我用了optware-ng安装gcc、make、openssl、openssl-dev和zlib。我根据README中的说明安装了rbenv(版本1.0.0-19-g29b4da7)和ruby-build插件。.这些是随optware-ng安装的软件包及其版本binutils-2.25.1-1gcc-5.3.0-6gconv-modules-2.21-3glibc-opt-2.21-4libc-dev-2.21-1libgmp-6.0.0a-1libmpc-1.0.2-1libm
我正在尝试复制此GETcurl请求:curl-D--XGET-H"Authorization:BasicdGVzdEB0YXByZXNlYXJjaC5jb206NGMzMTg2Mjg4YWUyM2ZkOTY2MWNiNWRmY2NlMTkzMGU="-H"Content-Type:application/json"http://staging.example.com/api/v1/campaigns在Ruby中,通过电子邮件+apikey生成身份验证:auth="Basic"+Base64::encode64("test@example.com:4c3186288ae23fd9661c
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭8年前。Improvethisquestion我们有以下(以及更多)系统,我们将数据从一个应用推送/拉取到另一个:托管CRM(InsideSales.com)Asterisk电话系统(内部)横幅广告系统(openx,我们托管)潜在客户生成系统(自行开发)电子商务商店(spree,我们托管)工作板(本土)一些工作网站抓取+入站工作提要电子邮件传送系统(如Mailchimp,自主开发)事件管理系统(如eventbrite,自主开发)仪表板系统(大量图表和
在我的mac上安装几个东西时遇到这个问题,我认为这个问题来自将我的豹子升级到雪豹。我认为这个问题也与macports有关。/usr/local/lib/libz.1.dylib,filewasbuiltfori386whichisnotthearchitecturebeinglinked(x86_64)有什么想法吗?更新更具体地说,这发生在安装nokogirigem时日志看起来像:xslt_stylesheet.c:127:warning:passingargument1of‘Nokogiri_wrap_xml_document’withdifferentwidthduetoproto